标签 python相关的工作岗位有开发工程师,运维工程师,机器学习,架构师等。python的应用领域有网络爬虫,web 程序开发,桌面程序开发,人工智能等。
- Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
- Python 是交互式语言: 这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
- Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
计算机语言,特点简洁。缺点性能差。
Python 特点
- 1.易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
- 2.易于阅读:Python代码定义的更清晰。
- 3.易于维护:Python的成功在于它的源代码是相当容易维护的。
- 4.一个广泛的标准库:Python的最大的优势之一是丰富的库,跨平台的,在UNIX,Windows和Macintosh兼容很好。
- 5.互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片断。
- 6.可移植:基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台。
- 7.可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
- 8.数据库:Python提供所有主要的商业数据库的接口。
- 9.GUI编程:Python支持GUI可以创建和移植到许多系统调用。
- 10.可嵌入: 你可以将Python嵌入到C/C++程序,让你的程序的用户获得”脚本化”的能力。
标识符
- 第一个字符必须是字母表中字母或下划线 _ 。
- 标识符的其他的部分由字母、数字和下划线组成。
- 标识符对大小写敏感。
注释
Python中单行注释以 # 开头,多行注释可以用多个 # 号,还有 ‘’’ 和 “””
**
字面量和变量
字面量就是一个个的值,如’1’,’2’,’3’,’hello’,所表示的意思就是字面量的值,可以直接在程序中使用。
变量可以用来保存字面量,且变量中字面量是不定的。变量本身没有任何意思,会据不同字面量表示不同的意思。
变量赋值
Python 中的变量赋值不需要类型声明。
每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
Python 保留字符
下面的列表显示了在Python中的保留字。这些保留字不能用作常数或变数,或任何其他标识符名称。
所有 Python 的关键字只包含小写字母。
| and | exec | not |
|---|---|---|
| assert | finally | or |
| break | for | pass |
| class | from | |
| continue | global | raise |
| def | if | return |
| del | import | try |
| elif | in | while |
| else | is | with |
| except | lambda | yield |
行与缩进
python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} 。
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。实例如下:
实例(Python 3.0+)
if True:
print (“True”)
else:
print (“False”)
以下代码最后一行语句缩进数的空格数不一致,会导致运行错误:
if True:
print (“Answer”)
print (“True”)
else:
print (“Answer”)
print (“False”) # 缩进不一致,会导致运行错误
以上程序由于缩进不一致,执行后会出现类似以下错误:
File “test.py”, line 6
print (“False”) # 缩进不一致,会导致运行错误
^
IndentationError: unindent does not match any outer indentation level
多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠()来实现多行语句,例如:
total = item_one + \
item_two + \
item_three
在 [], {}, 或 () 中的多行语句,不需要使用反斜杠(),例如:
total = [‘item_one’, ‘item_two’, ‘item_three’,
‘item_four’, ‘item_five’]**
多个变量赋值
Python允许你同时为多个变量赋值。例如:
a = b = c = 1
以上实例,创建一个整型对象,值为 1,从后向前赋值,三个变量被赋予相同的数值。
您也可以为多个对象指定多个变量。例如:
a, b, c = 1, 2, “runoob”
以上实例,两个整型对象 1 和 2 的分配给变量 a 和 b,字符串对象 “runoob” 分配给变量 c。
数据类型
数据类型指的就是变量的值的类型,
Python3 中有六个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
Number(数字)
Python3 支持 int、float、bool、complex(复数)。
在Python 3里,只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
像大多数语言一样,数值类型的赋值和计算都是很直观的。
内置的 type() 函数可以用来查询变量所指的对象类型
此外还可以用 isinstance 来判断:
实例
a = 111
>>> isinstance(a, int)True
isinstance 和 type 的区别在于:
- type()不会认为子类是一种父类类型。
- isinstance()会认为子类是一种父类类型。
String(字符串)
Python中的字符串用单引号 ‘ 或双引号 “ 括起来,同时使用反斜杠 \ 转义特殊字符。
字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
加号 + 是字符串的连接符, 星号 * 表示复制当前字符串,紧跟的数字为复制的次数。实例如下:
实例
#!/usr/bin/python3
str = ‘Runoob’
print (str) # 输出字符串
print (str[0:-1]) # 输出第一个到倒数第二个的所有字符
print (str[0]) # 输出字符串第一个字符
print (str[2:5]) # 输出从第三个开始到第五个的字符
print (str[2:]) # 输出从第三个开始的后的所有字符
print (str * 2) # 输出字符串两次
print (str + “TEST”) # 连接字符串
执行以上程序会输出如下结果:
Runoob
Runoo
R
noo
noob
RunoobRunoob
RunoobTEST
Python 使用反斜杠()转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串:
print(‘Ru\noob’) Ru oob print(r’Ru\noob’) Ru\noob
另外,反斜杠()可以作为续行符,表示下一行是上一行的延续。也可以使用 “””…””” 或者 ‘’’…’’’ 跨越多行。
注意,Python 没有单独的字符类型,一个字符就是长度为1的字符串。
实例
word = ‘Python’
print(word[0], word[5])
P n
print(word[-1], word[-6])
n P
与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如word[0] = ‘m’会导致错误。
注意:
1、反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
2、字符串可以用+运算符连接在一起,用*运算符重复。
3、Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。
4、Python中的字符串不能改变。
格式化字符串
字符串间可以进行加法运算,如将两字符串相加会拼接成一个字符串。但不能与其他类型进行加法运算
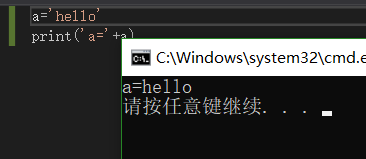
此写法不常见,一般用print(‘a=’a,)
创建字符串时,可在字符串中指定占位符
%s 在字符串中可以表示任意字符
%f 浮点数占位符
%d 整数占位符
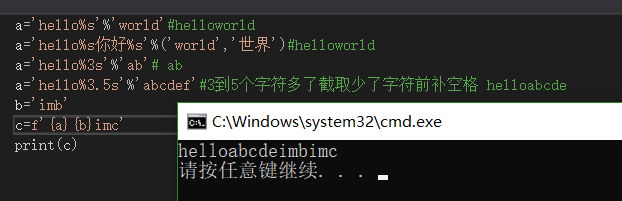
格式化字符串,可以通过在字符串前加一个f来创建一个格式化字符串
在格式化字符串中可以直接嵌入变量
name=’sun’
字符串赋值

布尔值
主要用做逻辑判断True,False
布尔值实际上属于整型,True相当于1,False相当于0
print(False+0)输出0
None(空值)
类型检查
type()用来检查值的类型,改函数会将检查结果通过返回值,可以通过变量来来接收函数返回值
对象
Python是一门面向对象的语言
程序运行时,数据是先存在内存中然后再运算的。
对象就是内存中专门用来储存指定数据的一块区域
对象实际上就是一个容器,专门用来储存数据
对象的结构
对象中都必须要保存的三种数据
1.id标识
用来识别对象的唯一性,每一个对象都有唯一的id
可以通过id()查看对象id
id由解析器生成的,再CPython中,id就是对象的内存地址
对象一旦创建,id永不可更改
2.type类型
标识当前对象所属的类型
类型决定了对象有哪些功能
通过type()查看对象类型
Python是一门强类型语言,对象一旦创建类型不可修改
3.value值
值就是对象中储存的具体数据
对于某些对象值可改变
对象分位两大类:可变对象,不可变对象
可变对象的值可改变,不可变对象的值不可改变,如前面介绍的数据类型
类型转换
所谓的类型转换是将一个类型的对象转换为其他对象,实质是开辟新内存空间,重新赋值不管类型都一样,同值不开辟新内存。
类型转换的四个函数 int() float() bool() str()
将变量传入函数内可转换,int()转换浮点数时舍去小数,不四舍五入。
运算符
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 位运算符
- 成员运算符
- 身份运算符
- 运算符优先级
三元运算符:
语法:语句1 if 条件表达式 else 语句2 表达式为真时执行语句1返回执行结果,为假时执行语句2返回执行结果流程控制语句
Python缩进一般用TAB或者空格(四个),代码块以缩进为始,直到代码块恢复到之前的缩进
Python代码在执行的时候是自上而下执行的
条件判断语句,循环语句
Python程序语言指定任何非0和非空(null)值为true,0 或者 null为false。条件判断语句 if
Python 编程中 if 语句用于控制程序的执行,基本形式为:
if 判断条件:
__执行语句……
else__:
__执行语句……
if 语句的判断条件可以用>(大于)、<(小于)、==(等于)、>=(大于等于)、<=(小于等于)来表示其关系。
当判断条件为多个值时,可以使用以下形式:
if 判断条件1:
执行语句1__……
elif 判断条件2:
执行语句2__……
elif 判断条件3:
执行语句3__……
else__:
执行语句4__……
input函数用于接收用户输入,且能停顿操作循环语句
| 循环类型 | 描述 | | —- | —- | | while 循环 | 在给定的判断条件为 true 时执行循环体,否则退出循环体。 | | for 循环 | 重复执行语句 | | 嵌套循环 | 你可以在while循环体中嵌套for循环 |
循环控制语句
循环控制语句可以更改语句执行的顺序。Python支持以下循环控制语句:
| 控制语句 | 描述 |
|---|---|
| break 语句 | 在语句块执行过程中终止循环,并且跳出整个循环 |
| continue 语句 | 在语句块执行过程中终止当前循环,跳出该次循环,执行下一次循环。 |
| pass 语句 | pass是空语句,是为了保持程序结构的完整性。 |
while循环
语法:while** **条件表达式 :
代码块
循环的三个要素:1.初始化表达式,通过初始化表达式初始化一个变量
2.条件表达式,表达式用来设置循环执行条件
3.更新表达式,修改初始化变量的值
num=int(input(‘输入整数’)) i=2 flag=True while num>i : if num%i==0: flag=False i+=1 if flag==True: print(num,’是质数’) else: print(num,’不是质数’)
Python求用户输入判断质数如上,将循环内信息传递到外部,可以传如一个变量值为True的变量,通过布尔值更改将循环内信息传递到外部**。**
计算代码执行效率(时间)链接
from time import*
time()
代码块
time()
可将time值赋给变量,如何进行变量计算得出代码块耗时
_
for 循环语句
Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串。
语法:
for循环的语法格式如下:
for iterating_var in sequence: statements(s)
循环使用 else 语句
在 python 中,for … else 表示这样的意思,for 中的语句和普通的没有区别,else 中的语句会在循环正常执行完(即 for 不是通过 break 跳出而中断的)的情况下执行,while … else 也是一样。
序列
序列是计算机的一种基本数据结构,数据结构指数据的储存方式。序列用于保存一组有序的数据,所有的数据在序列当中都有一个唯一的位置(索引)并且序列中的数据会按照添加的顺序来分配索引
序列分类:可变(列表),不可变(字符串,元组)
List(列表)
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [] 之间、用逗号分隔开的元素列表。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
列表截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
加号 + 是列表连接运算符,星号 * 是重复操作。如下实例:
实例
#!/usr/bin/python3
list = [ ‘abcd’, 786 , 2.23, ‘runoob’, 70.2 ]
tinylist = [123, ‘runoob’]
print (list) # 输出完整列表
print (list[0]) # 输出列表第一个元素
print (list[1:3]) # 从第二个开始输出到第三个元素
print (list[2:]) # 输出从第三个元素开始的所有元素
print (tinylist * 2) # 输出两次列表
print (list + tinylist) # 连接列表
以上实例输出结果:
[‘abcd’, 786, 2.23, ‘runoob’, 70.2]
abcd
[786, 2.23]
[2.23, ‘runoob’, 70.2]
[123, ‘runoob’, 123, ‘runoob’]
[‘abcd’, 786, 2.23, ‘runoob’, 70.2, 123, ‘runoob’]
与Python字符串不一样的是,列表中的元素是可以改变的:
实例
a = [1, 2, 3, 4, 5, 6] a[0] = 9 a[2:5] = [13, 14, 15] a [9, 2, 13, 14, 15, 6] a[2:5] = [] # 将对应的元素值设置为 [] a [9, 2, 6]
List 内置了有很多方法,例如 append()、pop() 等等,这在后面会讲到。
注意:
1、List写在方括号之间,元素用逗号隔开。
2、和字符串一样,list可以被索引和切片。
3、List可以使用+操作符进行拼接。
4、List中的元素是可以改变的。
Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
如果第三个参数为负数表示逆向读取,以下实例用于翻转字符串:
实例
def reverseWords(input):
# 通过空格将字符串分隔符,把各个单词分隔为列表
inputWords = input.split(" ")
# 翻转字符串
# 假设列表 list = [1,2,3,4],
# list[0]=1, list[1]=2 ,而 -1 表示最后一个元素 list[-1]=4 ( 与 list[3]=4 一样)
# inputWords[-1::-1] 有三个参数
# 第一个参数 -1 表示最后一个元素
# 第二个参数为空,表示移动到列表末尾
# 第三个参数为步长,-1 表示逆向
inputWords=inputWords[-1::-1]
# 重新组合字符串
output = ' '.join(inputWords)
return output
if name == “main“:
input = ‘I like runoob’
rw = reverseWords(input)
print(rw)
输出结果为:
runoob like I
in 和 not in用来检查元素是否在列表中,其返回值为布尔值
Python列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素 |
| 2 | len(list) 列表元素个数 |
| 3 | max(list) 返回列表元素最大值 |
| 4 | min(list) 返回列表元素最小值 |
| 5 | list(seq) 将元组转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序 |
修改列表中的元素
直接通过索引来修改元素list[index]=
通过del 删除元素del list[index]
Tuple(元组)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。
元组中的元素类型也可以不相同:
实例
#!/usr/bin/python3
tuple = ( ‘abcd’, 786 , 2.23, ‘runoob’, 70.2 )
tinytuple = (123, ‘runoob’)
print (tuple) # 输出完整元组
print (tuple[0]) # 输出元组的第一个元素
print (tuple[1:3]) # 输出从第二个元素开始到第三个元素
print (tuple[2:]) # 输出从第三个元素开始的所有元素
print (tinytuple * 2) # 输出两次元组
print (tuple + tinytuple) # 连接元组
以上实例输出结果:
(‘abcd’, 786, 2.23, ‘runoob’, 70.2)
abcd
(786, 2.23)
(2.23, ‘runoob’, 70.2)
(123, ‘runoob’, 123, ‘runoob’)
(‘abcd’, 786, 2.23, ‘runoob’, 70.2, 123, ‘runoob’)
元组与字符串类似,可以被索引且下标索引从0开始,-1 为从末尾开始的位置。也可以进行截取(看上面,这里不再赘述)。
其实,可以把字符串看作一种特殊的元组。
实例
tup = (1, 2, 3, 4, 5, 6) print(tup[0]) 1 print(tup[1:5]) (2, 3, 4, 5) tup[0] = 11 # 修改元组元素的操作是非法的 Traceback (most recent call last): File “”, line 1, in TypeError: ‘tuple’ object does not support item assignment
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
string、list 和 tuple 都属于 sequence(序列)。
注意:
1、与字符串一样,元组的元素不能修改。
2、元组也可以被索引和切片,方法一样。
3、注意构造包含 0 或 1 个元素的元组的特殊语法规则。
4、元组也可以使用+操作符进行拼接。
元组的解包
解包就是指将元组当中的每一个元素赋值给一个变量
可实现数据互换如下
a=1
b=2
a,b=b,a #(右边为元组)
==和is区别
==为值value,类型type相同,is为对象id相同(对象拥有的三种数据物理地址id,类型type,值value)
字典(dict)链接
- 字典是一种新的数据结构,称为映射
- 其作用于列表类似,都是用来储存对象的容器
- 列表储存数据性能很好,但查询数据性能很差
- 字典中每一个对象有对应的唯一名字,称为键(key),而每个对象称为值(value),所有字典也称键值对结构
- 每个字典可以有多个键值对,而每一个键值我们称为一项(item)
- 字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
- 值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
一个简单的字典实例:
dict = {‘Alice’: ‘2341’, ‘Beth’: ‘9102’, ‘Cecil’: ‘3258’}
也可如此创建字典:
dict1 = { ‘abc’: 456 }
dict2 = { ‘abc’: 123, 98.6: 37 }
使用dict()创建字典,每一个参数都是一个键值对,参数名就是键,参数名就是值(这种方式创的字典,key都是字符串):
d=dict(name=’python’,age=’18’)
也可以将一个包含有双值子序列的序列转换为字典
双值子序列,指序列中只有两个值,[1,2] (a,b) ‘ab’
子序列,如果序列中的元素也是序列,那么我们称此元素为子序列,如[(1,2),(3,4)]
Set(集合)链接
集合和列表非常相似
不同点:
1.集合中只能储存不可变对象
2.集合中储存的对象是无序的
3.集合中不能出现重复的元素
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,…}
或者
set(value)
实例
#!/usr/bin/python3
student = {‘Tom’, ‘Jim’, ‘Mary’, ‘Tom’, ‘Jack’, ‘Rose’}
print(student) # 输出集合,重复的元素被自动去掉
set可以进行集合运算
a = set(‘abracadabra’)
b = set(‘alacazam’)
print(a)
print(a - b) # a 和 b 的差集
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素
以上实例输出结果:
{‘Mary’, ‘Jim’, ‘Rose’, ‘Jack’, ‘Tom’}
Rose 在集合中
{‘b’, ‘a’, ‘c’, ‘r’, ‘d’}
{‘b’, ‘d’, ‘r’}
{‘l’, ‘r’, ‘a’, ‘c’, ‘z’, ‘m’, ‘b’, ‘d’}
{‘a’, ‘c’}
{‘l’, ‘r’, ‘z’, ‘m’, ‘b’, ‘d’}
Dictionary(字典)
字典(dictionary)是Python中另一个非常有用的内置数据类型。
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
实例
#!/usr/bin/python3
dict = {}
dict[‘one’] = “1 - 菜鸟教程”
dict[2] = “2 - 菜鸟工具”
tinydict = {‘name’: ‘runoob’,’code’:1, ‘site’: ‘www.runoob.com’}
print (dict[‘one’]) # 输出键为 ‘one’ 的值
print (dict[2]) # 输出键为 2 的值
print (tinydict) # 输出完整的字典
print (tinydict.keys()) # 输出所有键
print (tinydict.values()) # 输出所有值
以上实例输出结果:
1 - 菜鸟教程
2 - 菜鸟工具
{‘name’: ‘runoob’, ‘code’: 1, ‘site’: ‘www.runoob.com’}
dict_keys([‘name’, ‘code’, ‘site’])
dict_values([‘runoob’, 1, ‘www.runoob.com’])
构造函数 dict() 可以直接从键值对序列中构建字典如下:
实例
dict([(‘Runoob’, 1), (‘Google’, 2), (‘Taobao’, 3)]) {‘Taobao’: 3, ‘Runoob’: 1, ‘Google’: 2} {x: x**2 for x in (2, 4, 6)} {2: 4, 4: 16, 6: 36} dict(Runoob=1, Google=2, Taobao=3) {‘Runoob’: 1, ‘Google’: 2, ‘Taobao’: 3} 另外,字典类型也有一些内置的函数,例如clear()、keys()、values()等。 注意: 1、字典是一种映射类型,它的元素是键值对。 2、字典的关键字必须为不可变类型,且不能重复。 3、创建空字典使用 { }。 Python数据类型转换 有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。 以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。 函数 描述 int(x [,base]) 将x转换为一个整数 float(x) 将x转换到一个浮点数 complex(real [,imag]) 创建一个复数 str(x) 将对象 x 转换为字符串 repr(x) 将对象 x 转换为表达式字符串 eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象 tuple(s) 将序列 s 转换为一个元组 list(s) 将序列 s 转换为一个列表 set(s) 转换为可变集合 dict(d) 创建一个字典。d 必须是一个 (key, value)元组序列。 frozenset(s) 转换为不可变集合 chr(x) 将一个整数转换为一个字符 ord(x) 将一个字符转换为它的整数值 hex(x) 将一个整数转换为一个十六进制字符串 oct(x) 将一个整数转换为一个八进制字符串
函数
- 函数也是一个对象
- 对象是内存中专门用来存储数据的一块区域
- 函数可以用来保存一些可执行的代码,并且在可需要时,对这些语句进行多次的调用
- 创建函数:
def 函数名([形参1,形参2,形参3]): (函数名必须符号标识符规范)
代码块
- 函数中代码不会立即执行,我们需要调用函数
- 调用函数:函数名(参数)
函数的参数:
- 在定义的函数中,可以在函数名后的()定义数量不同的形参,多个形参用 ,隔开
- 形参(变量名),定义形参就相当于在函数内部声明了变量,但不赋值
- 实参(实际值)
如果定义函数时,指定了形参,那么在调用函数时也必须传递实参,实参会赋值个对应的形参,简单来说有几个形参就有几个实参
4.定义参数时,可以为形参指定默认值,如果用户传递了参数则默认值不生效
在定义参数时,在前面加一个,这样这个参数可以获取所有的实参,它会将所有实参保存到一个元组(装包)
在传递参数时,在序列类型的参数前加一个,会自动将序列中的元素依次作为参数传递,这里要求序列中元素与形参一致,将序列中元素拆出来传递称解包,通过对字典进行解包**
返回值(return)
- 返回值就是函数执行结果后返回的结果,返回值也可以是一个函数
- 仅仅写一个return或者不写则返回空值none
- 在函数中,return后的代码都不会执行,return一旦执行,函数自动结束
fn和fn()区别
print(fn) fn是函数对象,打印fn实际是打印函数对象本身
print(fn()) fn()是在调用函数,打印fn()实际上是在打印fn()函数的返回值
文档字符串
- 在定义函数时,可在函数内部编写字符串来注释函数,用于协助开发,通过和help()函数配合使用
- 通常用两个’’’(注释写’’’间隔行内)
作用域
Python一共两种作用域:全局作用域和函数作用域
全局作用域
全局作用域在程序执行时创建,在程序执行结束时销毁
所有函数以外的区域都是全局作用域
在全局作用域中定义的变量,都属于全局变量,全局变量可以在程序任意位置访问
函数的作用域
函数作用域在函数创建时产生,在调用结束时销毁
函数每调用一次会产生一个新的函数作用域
函数作用域中定义的变量,都是局部变量,只能在函数内部访问
变量的查找
当我们使用变量时,会优先在当前作用域中寻找变量,如果有则使用
如果没有则向上一级作用域寻找,有则使用,如果依然没有继续向上一级查找
若查找到全局作用域仍没有,则抛出异常
命名空间(namespace)
命名空间指的是变量的储存位置,每一个变量都需要储存到指定的命名空间中
每一个作用域都有一个它对应的命名空间
全局命名空间,用来保存变量,函数命名空间用来保存函数中的变量
命名空间实际上是一个字典,是一个专门用来储存变量的字典
locals()用来获取当前作用域的命名空间,返回结果为字典
递归
递归是解决问题的一种方式,它和循环很像
它的整体思想是,将一个大问题分解成一个个小问题,直到无法分解,再去解决问题
递归式函数的两个要件:
1.基线条件:问题可以被分解为的最小问题,当满足基线条件时,递归就不再执行了
2.递归条件:将问题继续分解的条件(基线条件中)
def factorial(n):
if n==1:#基线条件的判断
return 1
return n*factorial(n-1)#递归条件,返回结果进行基线判断循环
print(factorial(10))
#做一个任意数的幂运算
def power(n,i):
if i==1: #基线条件
return n
return n*power(n,i-1) #递归条件
print(power(2,8)) #结果为256
#判断是否为回文字符串
def hui_wen(n):
if len(n)<2:
return True
elif n[0]!=n[-1]:
return False
return hui_wen(n[1:-1])
print(hui_wen('12321')) #结果返回True,list[::-1]返回倒序列表
高阶函数
在Python中,函数都是一等对象,一等对象一般都有如下特点:
- 对象是在运行时创建的,
- 能赋值给变量或者作为数据结构中的元素
- 能作为参数传递
- 能作为返回值返回
高阶函数至少要符合两个以下特点中的一个:
- 接收一个或多个函数作为参数
- 将函数作为返回值返回
filter()可以从序列中过滤出符号条件的元素,保存到一个新序列中
参数:
函数,据该函数来过滤序列(可迭代结构)
需要过滤的序列
返回值:
过滤后的新序列(可迭代的结构)
匿名函数(lambda)
lambda函数专门用于创建一些简单的函数,它是函数创建的又一种方式
语法:lambda 参数列表:返回值
其一般用来作参数使用(由于其返回值不能复杂)
map函数
用法:map(function, iterable, …)
可以对迭代对象中所有元素进行指定操作,然后将其添加到一个新对象中返回
sort()
该方法用于对列表中元素进行排序
sort()默认是对直接比较列表中元素
在sort()中可以传入一个关键字参数key,key需要一个函数作为参数,当设置了函数作为参数,每次都会以列表中的一个元素作为参数来调用函数,并使用函数返回值来比较元素的大小
sort()方法语法:
list.sort( key=None, reverse=False)
参数
- key — 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse — 排序规则,reverse = True 降序, reverse = False 升序(默认)。
sorted用法与sort一致,但sorted可以对任意序列进行排序,并且使用sorted排序不会影响原来的对象,而是返回一个新对象
闭包
闭包是由函数及其相关的引用环境组合而成的实体(即:闭包=函数+引用环境)(想想Erlang的外层函数传入一个参数a, 内层函数依旧传入一个参数b, 内层函数使用a和b, 最后返回内层函数)
形成闭包的条件:
1.函数嵌套
2.将内部函数作为返回值返回
3.内部函数必须用到外部函数变量
def make_averager():
nums=[]
def averager(n):
nums.append(n)
return sum(nums)/len(nums)
return averager
averager=make_averager()
print(averager(10))
print(averager(12))
print(averager(14)) #确保数据安全
装饰器
装饰器(Decorators)是 Python 的一个重要部分。简单地说:他们是修改其他函数的功能的函数。他们有助于让我们的代码更简短,也更Pythonic(Python范儿)。
def add(a,b): #定义一个有参函数 返回值为r
r=a+b
return r
def fn(): #定义一个无参函数 其返回值是None
print('这是fn函数')
def new_fn(old): #定义一个能传任意参数函数
def new_fn0(*args,**kwargs):
print('开始')
result=old(*args,**kwargs)
print('结束')
return result
return new_fn0
f0=new_fn(fn)
f1=new_fn(add)
r=f0()
r1=f1(123,123)
print(r)
输出结果:

像new_fn这样的函数属于装饰器,通过装饰器我们可以通过不修改原函数的清况下进行扩展,开发中,我们都使用装饰器来进行函数的扩展,在定义函数时,可以通过@装饰器来使用指定装饰器来装饰当前函数,一个函数可以使用多个装饰器,这样函数会按照从内向外装饰
类与对象
对象就是内存中专门用来存放数据的一块区域,由三部分组成:对象的标识(id),对象的类型(type),对象的值(value)
Python是面向对象的语言,所谓面向对象指的就是语言中所有操作都通过对象来进行的
对象的创建流程
对象创建:对象名=类名()
可以向对象中添加变量,对象中变量称为属性
语法:对象.属性名=属性值
**
定义类
用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
使用 class 语句来创建一个新类,class 之后为类的名称并以冒号结尾:
定义一个简单的类,使用class关键字来定义,语法与函数类似
class 类名(基类1,基类2,基类3,…):
代码块
isinstance()用来检查一个对象是否是一个类的实例
在类的代码块中,我们可以定义变量和函数
在类中我们定义的变量,将会成为所有实例的公共属性
所有都可以访问这些变量
class Person:
name='李白'
p1=Person()
p2=Person()
print(p1.name)
print(p2.name)#输出结果为:李白
# 李白
在类中也可以定义函数,类中的定义函数称为方法,其成为该类实例的公共方法
方法也可以通过该类的所有实例来访问
调用方法,对象.方法名()
方法调用与函数区别在于,函数调用时传几个参数就会有几个实参,但方法,默认传递一个参数,所以方法中至少要有一个参数(方法调用时,第一个参数由解析器自动传递,所以定义方法时,至少定义一个参数,一般取名self)
class Person:
name='李白'
def say_hello(self): #去除self(自定义参数)会报错
print('你好')
p1=Person()
p1.say_hello() #输出结果:‘你好’
属性和方法的查找流程
当我们调用一个对象的属性时,解析器会先在当前对象中寻找是否含有该属性
如果有,则直接返回当前的对象的属性值
如果没有 ,则去当前对象的类中寻找,如果有则返回类对象的属性值
如果没有则报错
例子
class Person:
name='李白'
def say_hello(self):
print('你好')
p1=Person()
p1.name='杜甫'
print(p1.name) #输出:‘杜甫’
方法每次调用时,解析器都会自动传递第一个实参
第一个参数,就是调用方法的对象本身
如果是p1调用,那么第一个参数就是p1对象
如果是p2调用,那么第一个参数就是p2对象
一般我们将此参数命名为self
class Person:
def say_hello(self):
print('你好%s'%self.name) #在方法中不能直接访问类中的属性,即%后不能直接跟name
p1=Person()
p2=Person()
p1.name='杜甫'
p2.name='李白'
p1.say_hello()
p2.say_hello()
#输出结果:你好杜甫
#你好李白
类的特殊方法init(构造方法,关键字)
在类中可以定义特殊方法,特殊方法都是以开头结尾的方法,在对象创建时自动调用
init可以用来向新创建的对象中初始化属性
class Person:
def __init__(self,name): #传入name参数,创建对象时也必须传参数
self.name=name #通过self向新建对象中初始化属性
def say_hello(self):
print('你好%s'%self.name)
p1=Person('李白') #如果不传参数会报错提示缺少一个位置参数
p1.say_hello() #输出结果:你好李白
封装
封装是面向对象的三大特性之一
封装指的是隐藏对象中一些不希望被外部所访问到的属性或方法
如何隐藏一个对象中的属性?
将对象的属性名,修改成外部不知道的名字
如何获取(修改)对象中的属性
需要提供一个getter和setter方法使外部可以访问到属性
getter获取对象中的指定属性(一般取名get属性名)
setter用来设置对象的指定属性(一般取名set属性名)
使用封装,确实增加了类的定义的复杂程度,但它也确保了数据的安全性
1.隐藏了属性名(就是修改属性名,知道修改后名也直接能改属性),使调用者无法随意修改对象中的属性
2.增加getter和setter方法,很好的控制属性是否是只读的
如果希望属性是只读的,可以删除setter方法
如不希望属性不能被外部访问.可以删除getter方法
def get_shuxingming(self): #get_shuxingming为自定义getter方法
return self.xiugaiming #返回属性值
def set_shuxingming(self,shuxingming):
self.xiugaiming=shuxingming
如例增加数据安全
class Dog:
def __init__(self, name):
self.hidden_name=name
def jiao(self):
print('%s叫'%self.hidden_name)
def get_name(self):
return self.hidden_name
def set_name(self,name):
self.hidden_name=name
d1=Dog('土狗')
d1.set_name('野狗') #更改属性为‘野狗’
d1.jiao() #输出结果:野狗叫
以双下划线开头的的属性是假隐藏属性,实际名为_类名属性,不过一般属性代替_属性用于私有属性
例如
class Person:
def __init__(self,name):
self.__name=name
def get_name(self):
return self.__name
def set_name(self,name):
self.__name=name
p=Person('李白')
p._Person__name='礼拜' #_Person__name就是__name
print(p.get_name()) #输出结果:礼拜
property装饰器
用来将一个get方法,转换为对象的属性
添加为property装饰器以后,可以像调用属性一样使用get方法
用法:在方法前行@property**
类的继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
派生类可以直接继承基类中的所有属性和方法
派生类中可以自定义方法属性
如果派生类中有和基类同名的方法,通过派生类实例会先调用派生类的方法,由内到外的原则调用方法
继承语法
class 派生类名(基类名):
...
super()可以获取当前类的基类方法,并通过super()返回对象调用基类方法时,不需要传递self
语法:super().方法(参数)
**
`
类名.base这个属性可以用来获取当前类的所有基类
Python当中支持多重继承,即一个类可以有多个基类,在类名的()内添加多个类名,实现多重继承,(前边基类同名方法会覆盖后面基类的同名方法),从而获取多个基类中的方法和属性
在开发中尽量避免多重继承,会使代码过于复杂
如下例,class D(A,B,C),D继承自A,B,C类,而C继承自A,B类,那么D获取基类方法时,会先从A中找,如果没有则向A基类中,直到Object类,如果没有则向B中找,直到Object类,然后向C找,因为A,B已找过,所以会自动忽略C的基类A,B中查找。
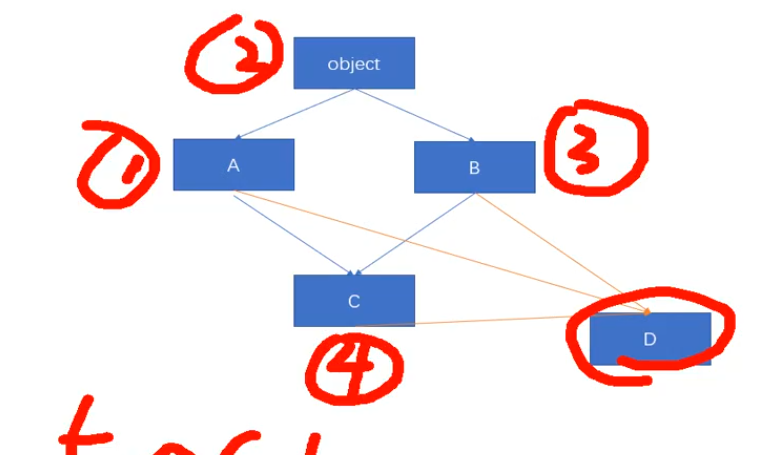
多态
多态是面向对象的三大特征之一
多态从字面上理解是多种形态,一个对象可以以不同的形态去呈现
特征:
1、只关心对象的实例方法是否同名,不关心对象所属的类型;
2、对象所属的类之间,继承关系可有可无;
3、多态的好处可以增加代码的外部调用灵活度,让代码更加通用,兼容性比较强;
4、多态是调用方法的技巧,不会影响到类的内部设计。
例子:
class A:
def __init__(self,name):
self._name=name
def get_name(self):
return self._name
def set_name(self,name):
self._name=name
class B:
def __init__(self,name):
self._name=name
def get_name(self):
return self._name
def set_name(self,name):
self._name=name
a=A('小猴') #传入字符串参数
b=B(10) #传入整型参数
def say_hello(obj):
print('你好%s'%obj.get_name())
say_hello(a)
say_hello(b) #输出结果:你好小侯
# 你好10
属性与方法
类属性,可以直接在类中定义的是类属性(语法:类名.属性名=value)
类属性可以通过类或类的实例访问到
但是类属性只能通过类对象来修改,无法通过类的实例对象修改
实例属性,通过实例对象添加的属于实例属性
实例属性只能通过实例对象来访问和修改,类对象无法访问修改
实例方法
在类中定义,以self为第一个参数的方法都是实例方法
实例方法调用时,Python会将调用对象作为self传入
当通过类调用时,不会自动传递self,此时我们必须手动传递self
class A(object):
count=1
def __init__(self): #两个都为实例方法
self.name='小猴'
def test(self):
print('这是test方法')
a=A() #A实例化的对象a
A.count=100 #修改A的类属性count
print('A,',A.count)
print('a,',a.count) #输出结果:A,100
# a,100
a.test()
A.test(a) #两个方法一样,下面的必须传入A实例对象参数
类方法
在类的内部使用@classmethod来修饰的方法属于类方法
类方法的第一个参数是cls,会被自动传递,cls就是当前的类对象
类方法和实例方法的区别,实例方法的第一个参数是self(规范取名为self),而类方法第一个参数是cls(规范取名为cls)
类方法可用通过类去调用,也可以通过实例调用,没有区别。类名.方法() #()里cls会自动传递
静态方法
在类中使用@staticmethod来修饰的方法属于静态方法
静态方法不需要指定任何的默认参数,静态方法可以通过类和实例去调用
静态方法,基本上是一个和当前类无关的方法,它只是一个保存到当前类的函数
静态方法一般都是一些工具方法,和当前类无关
垃圾回收
Python程序运行中,没有被引用的对象会被自动垃圾回收,即垃圾对象从内存中删除
class A:
def __init__(self):
self.name='A类'
def __del__(self): #__del__特殊方法用于在对象被垃圾回收前调用
print('A()对象被删除了',self)
a=A()
b=a
#b=None
#a=None 时a会被回收
print(a.name)
input('回车键退出')#输出结果:A类
特殊方法
特殊方法都是以__开头和结尾的
一般不用手动调用
模块化
模块化就是将一个完整程序分解为一个一个小的模块
通过将模块组合,来搭建一个完整的程序
模块化特点:
- 方便维护
- 方便开发
- 模块可复用
在Python中一个py文件就是一个模块,要想创建模块,实际上就是创建一个python文件
注意:模块名要符合标识符的规范
在一个模块中引入外部模块
import 模块名(模块名就是python文件名,注意不要.py后缀)
可以多次引入模块,但模块实例只会创建一个
import 模块名 as 模块别名(防止模块重名)
每一个模块内都有一个name属性,通过此属性获取模块名, name属性值为main的模块是主模块,一个程序中只会有一个主模块,主模块就是我们直接通过Python执行的模块
包package
包也是一个模块
当我们模块中代码过多时,或者一个模块需要被分解为多个模块时,这时需要使用到包
普通模块就是一个py文件,而包是一个文件夹
包中必须含有一个一个init.py文件,这个文件可以含有包中的主要内容
pycache是模块的缓存文件
py代码在执行前,需要被解析器先转换为机器码,然后再执行
为了提高程序运行的性能,python会将编译一次后的代码保存到一个缓存文件中,这样下次再加载这个模块(包)时,就可以不用重新编译直接加载缓存中编好的代码
Python3标准库 链接
提供预制的py文件(文件夹)(模块,包)用于简化用户编程
异常和文件 链接
处理异常:程序运行出现异常,目的不是让我们程序直接终止
Python是希望出现异常时,我们可以编写代码来对异常进行处理
try语句
try:
代码块(可能出现错误的语句)
except:
代码块(出现错误以后的处理方式)
else:
代码块(没出错时要执行的语句)
finally:
代码块(该代码总会执行)
try是必须的,else有没有都行
异常传播
当在函数中出现异常时,如果在函数中对异常进行了处理,则异常不会继续传播
如果函数中没有对异常进行处理,则异常会继续向函数调用处传播
如果函数调用处处理了异常,则不再传播,如果没有处理则向调用处传播
当程序运行过程中出现异常后,所有的异常信息会被保存到一个专门的异常对象中
例如:ZeroDivisionError类的对象专门用来表示除0的异常
NameError类的对象专门用来处理变量错误的异常
自定义异常对象
raise用于向外部抛出异常,后边可以跟一个异常类,或异常类的实例
语法:raise Exception(‘信息’) #Exception是一个类,可以创建自定义异常类
文件
通过Python程序来对计算机中的各种文件进行增删改查的操作
又叫I/O(Input/Output)
操作文件的步骤:
- 打开文件
- 对文件进行各种操作(读,写)然后保存
- 保存文件
用open (文件名) #(路径)打开文件,如果目标文件和当前文件在同一级目录下,则直接使用文件名即可
在windows系统使用路径时,因为反义字符,可以使用/来代替\,或者\来代替\,或者也可以使用原始字符串
表示路径,可以使用..来返回上一级目录,如果目标文件离当前文件较远,可以使用绝对路径(绝对路径应该从磁盘根目录开始书写)
用open()来打开一个文件,可以将文件分成两种类型
一种,是纯文本文件(使用utf-8等编码编写的文本文件)
一种,是二进制文件(图片,mp3,ppt等这些文件)
open()**打开文件时,默认是以文本文件的形式打开的,但是open()默认的编码为None
所以处理文本文件时,必须要指定文件的编码
read()方法**,用来读取文件中的内容,它会将内容全部保存为一个字符串返回,直接调用read()会将文本文件的所有内容加载到内存中,容易导致内存泄漏,因此可以read()里传数(size值,字符数量),例如file_obj.read(5)读取5个字符,如果继续调用则向下读取字符
关闭文件
调用close()**方法来关闭文件
file_obj.close()
with…as语句
with open(file_name) as file_obj:
在with语句中可以直接使用file_obj来做文件操作
此时这个文件只能在with中使用,一旦with结束则文件会自动close()
例:with open(file_name,’rb’) as file_obj #表示以二进制读取名为文件file_name,其在调用时以file_obj名为称 ,去除b表示以默认方式读取文件
readline()用于读取一行内容
readlines()用于一行一行的读取内容,它会一次性将读取到的内容封装到一个列表中返回
write()来向文件中写入内容
如果操作的是一个文本文件的话,则write()需要传递一个字符串作为参数
该方法可以分多次向文件中写入内容
写入完成以后,该方法会返回写入字符的个数
seek()可以修改当前读取位置,括号内需传递两个参数,切换的位置和计算位置的方式
计算位置的方式为:
0 从头计算,默认值
1 从当前位置计算
2 从最后位置计算
tell()方法用来查看当前读取的位置

若有收获,就点个赞吧
0 人点赞
