在这篇在线文章中,Gunther博士深入UNIX内核,了解负载平均值(”LA Triplets”)是如何计算的,以及它们作为容量规划指标有多合适。出于对儒勒-凡尔纳和他的小说《海底两万里》的歉意,我同样可以把这篇文章命名为 “壳下两万行”。
你有没有想过在UNIX®负载平均(LA)报告中出现的那三个小数字是如何计算的?
这篇TeamQuest论文解释了如何以及如何重组负载平均数(LA)来做更好的容量规划。但首先,请尝试用 “LA triplets”测验测试你的知识。
在这两部分系列中,我想探讨一下平均数在性能分析和容量规划中的应用。平均数有很多表现形式,例如,算术平均数(常用的)、移动平均数(经常用于财务规划)、几何平均数(用于SPEC CPU基准)、谐波平均数(用得不多),仅此而已。
更重要的是,我们将研究随时间变化的平均数或随时间变化的平均数。这种随时间变化的平均值的一个特殊例子是出现在某些 UNIX 命令中的负载平均值指标。在第一部分中,我将研究什么是负载平均数以及它是如何被计算出来的。在第二部分,我将把它与其他平均技术进行比较,因为它们适用于容量规划和性能分析。本文并不假定你对 UNIX 命令很熟悉,所以我将首先回顾那些显示负载平均指标的命令。然而,到了第 4 节,我将会潜入做所有工作的 UNIX 内核代码中。
1. UNIX命令
实际上,负载平均值不是传统意义上的 UNIX 命令。相反,它是一个嵌入式指标,出现在其他 UNIX 命令的输出中,如 uptime 和 procinfo。这些命令通常被 UNIX 系统管理员用来观察系统资源消耗。
1.1 经典输出
通用的ASCII文本格式出现在各种 UNIX Shell 命令中。下面是一些常见示例。
Uptime
uptime shell 命令产生以下输出。
[pax:~]% uptime

它显示了自系统最后一次启动以来的时间,活动用户进程的数量和一个叫做平均负载的东西。
Procinfo
在 Linux 系统上,procinfo 命令产生以下输出:
[pax:~]% procinfoLinux 2.0.36 (root@pax) (gcc 2.7.2.3) #1 Wed Jul 25 21:40:16 EST 2001 [pax]Memory: Total Used Free Shared Buffers CachedMem: 95564 90252 5312 31412 33104 26412Swap: 68508 0 68508Bootup: Sun Jul 21 15:21:15 2002 Load average: 0.15 0.03 0.01 2/58 8557...
负载平均值显示在此输出的左下角。
W
w(ho) 命令产生以下输出:
[pax:~]% w9:40am up 9 days, 10:35, 4 users, load average: 0.02, 0.01, 0.00USER TTY FROM LOGIN@ IDLE JCPU PCPU WHATmir ttyp0 :0.0 Fri10pm 3days 0.09s 0.09s bashneil ttyp2 12-35-86-1.ea.co 9:40am 0.00s 0.29s 0.15s w...

请注意,输出的第一行与运行时间命令的输出相同。
Top
top 命令是最近加入UNIX 命令集的一个命令,它根据进程所消耗的CPU时间进行排名。它产生以下输出:
➜ Administrator toptop - 11:27:34 up 13 min, 0 users, load average: 0.52, 0.58, 0.59Tasks: 6 total, 1 running, 5 sleeping, 0 stopped, 0 zombie%Cpu(s): 6.9 us, 3.4 sy, 0.0 ni, 89.2 id, 0.0 wa, 0.5 hi, 0.0 si, 0.0 stMiB Mem : 16163.3 total, 4231.3 free, 11708.0 used, 224.0 buff/cacheMiB Swap: 18750.0 total, 18378.8 free, 371.1 used. 4324.7 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND1 root 20 0 9788 528 484 S 0.0 0.0 0:00.07 init8 root 20 0 9808 312 252 S 0.0 0.0 0:00.00 init9 ubuntu 20 0 19604 3552 3504 S 0.0 0.0 0:00.18 zsh12 root 20 0 18396 2348 2320 S 0.0 0.0 0:00.01 su13 root 20 0 20184 4008 3952 S 0.0 0.0 0:00.26 zsh94 root 20 0 18920 2148 1528 R 0.0 0.0 0:00.05 top
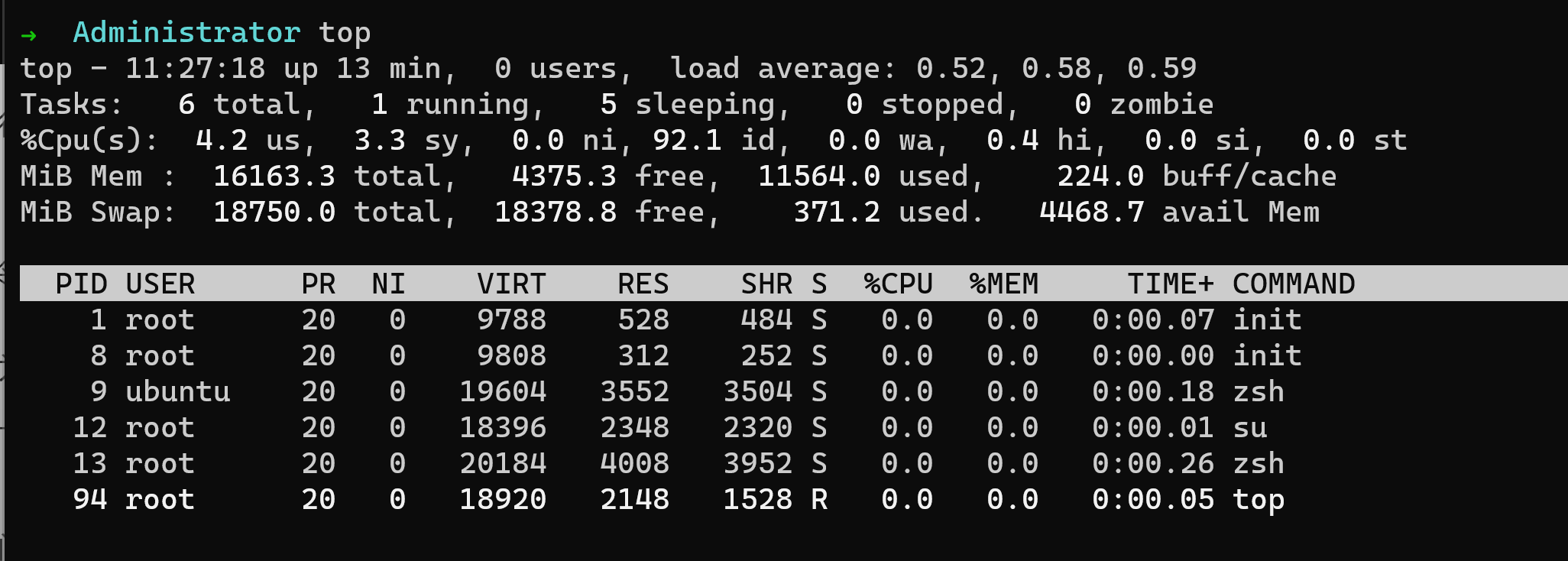
在每个命令中,请注意,作为负载均衡输出的一部分,有三个数字报告。通常,这些数字显示从左到右的下降顺序。但是,偶尔会出现上升顺序,例如,如上面顶部输出中显示的升序。
1.2 GUI 输出
负载平均值也可以显示为时间序列,例如此处显示的来自 ORCA 的工具的某些输出。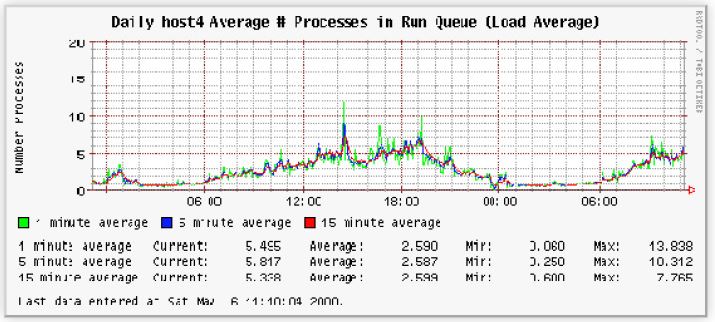
虽然这样的视觉辅助工具可以帮助我们看到绿色曲线比红色曲线更尖锐,有更多的变化,而且它可以让我们看到完整的一天的数据,但不清楚这对容量规划或性能分析有多大作用。我们需要更多地了解负载平均指标是如何定义和计算的。
2. 那是什么?
那么,所有这些不同的命令所报告的称为平均负载的东西到底是什么呢?
让我们看看 UNIX 的官方文档。
2.1 The man Page
➜ Administrator man "load average"

哎呀! 没有人名页! 负载平均指标是一个嵌入在其他命令中的输出,所以它没有自己的手册条目。好吧,让我们看一下uptime 命令的手册页,比如说,看看我们是否可以通过这种方式了解更多。
➜ Administrator man uptime
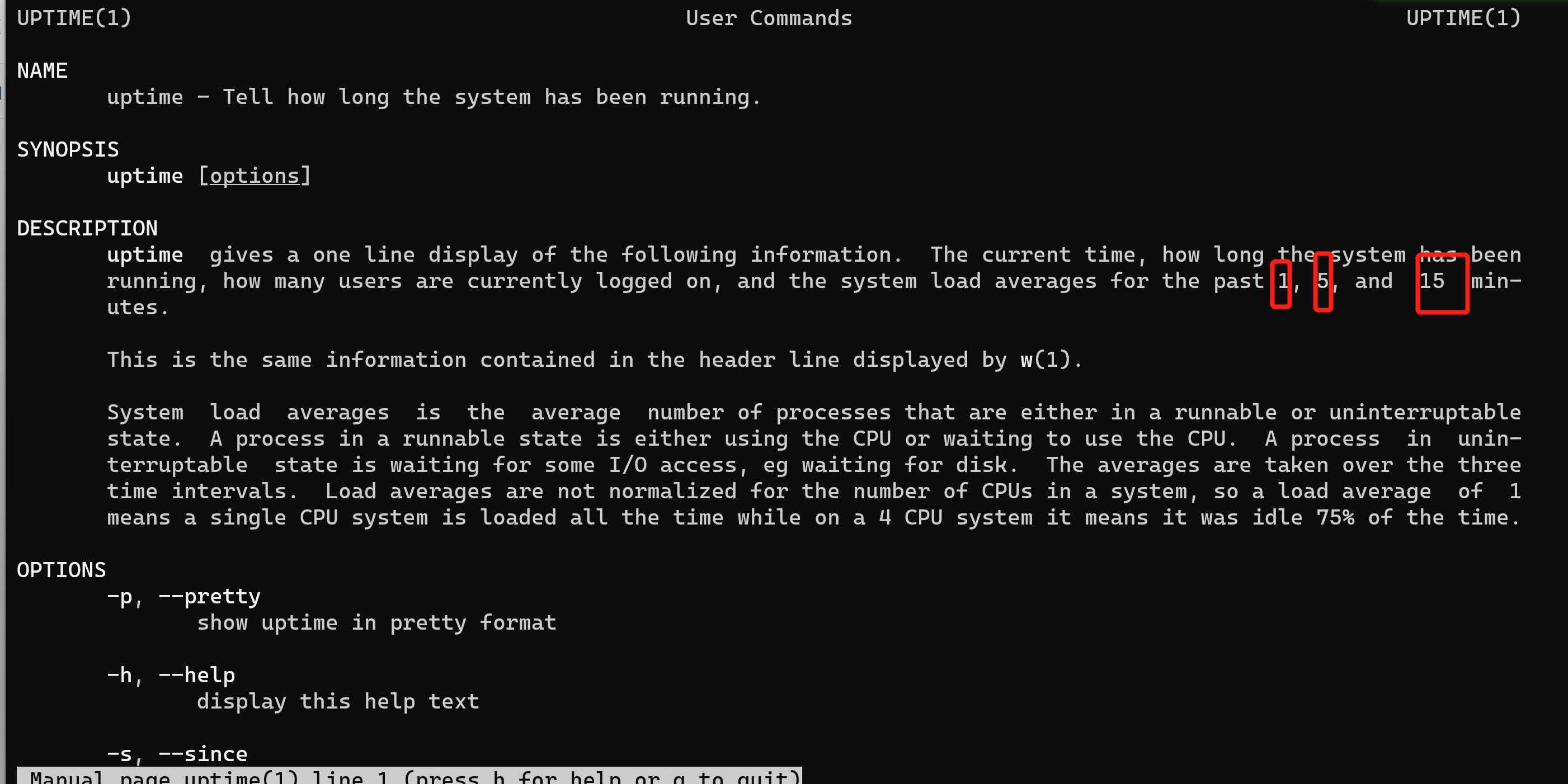
因此,这解释了三个指标。他们是”…过去 1、5 和 15 分钟的负载平均值。分别是图1中的绿色、蓝色和红色曲线。不幸的是,这仍然引出了一个问题:”什么是负载?
2.2 UNIX专家门的说法
让我们转向一些 UNIX 热点人物以获得更多启迪。
Tim O’Reilly 和团队
UNIX Power Tools[POL97]一书在第726页告诉我们,CPU。
负载平均值试图测量任何时候的活动进程的数量。作为CPU利用率的衡量标准,负载平均值很简单,定义也很差,但远非无用。
这是令人鼓舞的! 无论如何,它确实有助于解释被测量的内容:活动进程的数量。在第720页39.07检查系统负载:正常运行时间它继续……
… 高负荷平均数通常意味着系统被大量使用,响应时间也相应较慢。
响应时间相应较慢。
什么是高?理想情况下,你希望平均负载在3以下,比如说,3, … 最终,”高 “意味着足够高,以至于你不需要正常运行时间来告诉你系统已经过载。
嗯…… “3 “这个数字是怎么来的?以及他们指的是三个平均数(1、5、15分钟)中的哪一个?
关于Solaris的Adrian Cockcroft
在Sun Performance and Tuning [Coc95]中,在第97页题为:理解和使用负载平均值的章节中,Adrian Cockcroft指出。
负载平均值是运行队列长度和当前在CPU上运行的作业数之和。在Solaris 2.0和2.2中,负载平均值不包括正在运行的作业,但这个错误在Solaris 2.3中得到了修复。
因此,即使是Sun公司的 “大男孩 “也会弄错。尽管如此,负载平均值与CPU运行队列相关的想法是一个重要的观点。
O’Reilly等人还注意到使用负载平均值的一些潜在问题……
……不同的系统在相同的负载平均值下会有不同的表现。……运行一个单一的cpu绑定的后台作业….,即使负载平均数仍然很低,也会使响应变得很慢。
正如我将证明的那样,这取决于你什么时候看。如果CPU绑定的进程运行足够长的时间,它将推动负载平均值上升,因为它总是在运行或可运行。晦涩难懂源于这样一个事实,即负载平均值不是你平均的那种平均值。正如我们在上面的介绍中提到的,它是一个与时间相关的平均数。不仅如此,它还是一个有阻尼的随时间变化的平均值。为了了解更多,让我们做一些控制实验。
3. 性能实验
本节中描述的实验涉及在单 CPU Linux 盒的后台运行一些工作负载。测试有两个阶段,持续时间为 1 小时:
- CPU在2100秒内被挂起,然后进程被杀死。
- CPU 在剩余的 1500 秒内保持静止。
Perl 脚本使用 uptime 命令每 5 分钟对负载平均值进行采样。以下是详细信息。
3.1 测试负载
在一个单 CPU 的 Linux 盒子上,两个热循环作为后台任务被启动。该测试有两个阶段:
- CPU 被这些任务占用了
2,100秒。 - 在剩下的
1,500秒内,CPU(相对)处于静止状态。
1 分钟的平均值在测试的 300 秒左右达到 2 的数值。5分钟的平均值在测试进行到 1200 秒左右达到2,15 分钟的平均值将在 3600 秒左右达到 2,但是进程在 35 分钟后(即2100秒)被杀死。
3.2 过程采样
正如作者 [BC01] 解释的 Linux 内核,因为我们的两个测试过程都受 CPU 约束,它们将处于 TASK_RUNNING 状态。这意味着它们要么是:
- 正在运行的,即目前在CPU上执行的
- 可运行,即在
run_queue等待 CPU
Linux 内核还检查是否有任何任务处于短期睡眠状态,称为TASK_UNINTERRUPTIBLE。如果有,它们也会被包括在平均负载样本中。在我们的测试负载中没有。
下面的源码片段揭示了更多关于如何做到这一点的细节。
/* Nr of active tasks - counted in fixed-point numbers*/static unsigned long count_active_tasks (void){struct task struct *p;unsigned long nr = ;read_lock (&tasklist_lock);for_each_task(p) {if ( (p->state == TASK_RUNNING | |(p->state & TASK_UNINTERRUPTIBLE ) ) )nr += FIXED_;}read_unlock(&tasklist_lock);return nr;}
因此,正常运行时间每 5 秒采样一次,这是Linux内核更新负载平均计算的内在时间基础。
3.3 测试结果
这些实验的结果被绘制在图 2 中。注意:这些颜色与图 1 那样的 ORCA 图中使用的颜色不一致。
尽管工作负载是瞬间启动的,后来在2100秒时突然停止,但负载的平均值必须追上瞬间状态的变化。1分钟的样本追踪得最快,而15分钟的样本则滞后得最远。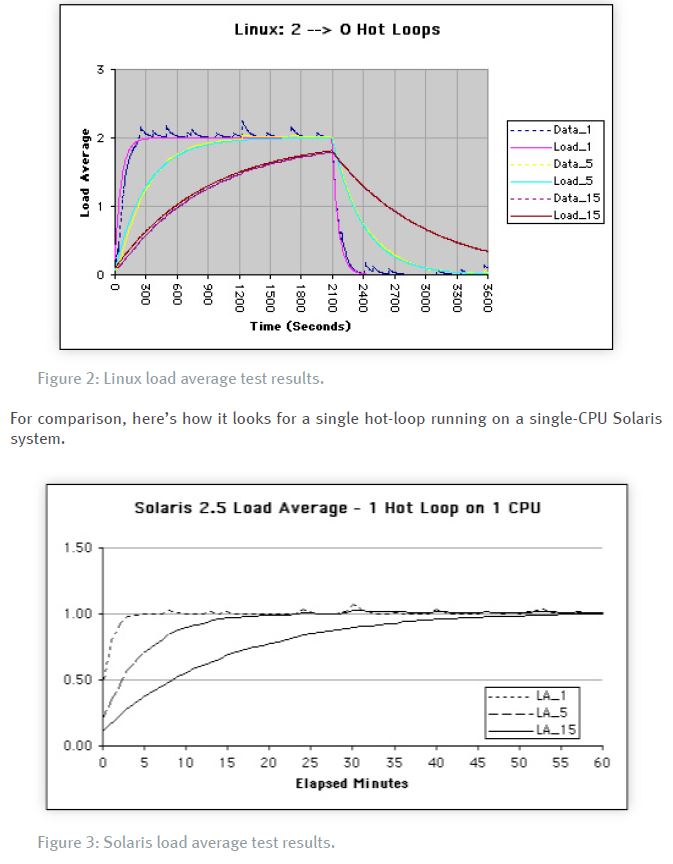
你会被原谅,认为 “负载 “与 CPU 利用率是同一回事。正如 Linux 的结果所显示的,当两个热进程运行时,单个CPU的最大负载是两个(而不是一个)。所以,负载并不等同于CPU利用率。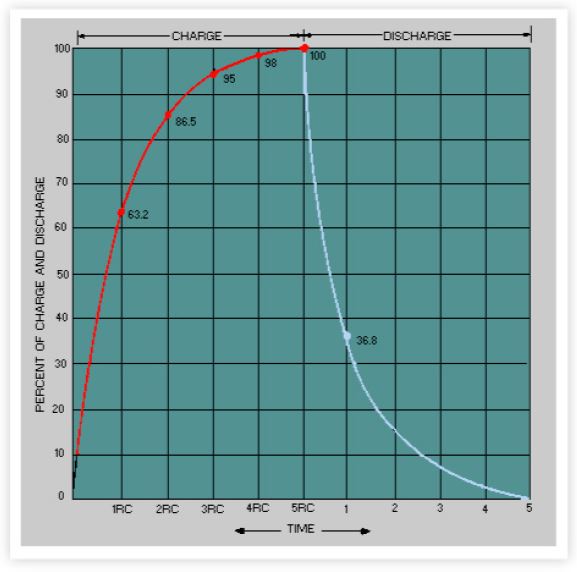
4. Kernal Magic
现在让我们进入Linux内核,看看它在做什么来产生这些负载平均数字。
unsigned long avenrun[3];static inline void calc_load(unsigned long ticks){unsigned long active_tasks; /* fixed-point */static int count = LOAD_FREQ;count -= ticks;if (count > 0) {count += LOAD_FREQ;active_tasks = count_active_tasks( );CALC_LOAD(avenrun[0], EXP_1, active_tasks);CALC_LOAD(avenrun[1], EXP_5, active_tasks);CALC_LOAD(avenrun[2], EXP_15, active_tasks);}}
倒计时超过 5 HZ 的LOAD_FREQ。多久一次?
1 HZ = 100 ticks5 HZ = 500 ticks1 tick = 10 miliseconds500 ticks = 5000 miliseconds (or 5 seconds)
因此,5 HZ 意味着 CALC_LOAD 每5秒被调用一次。
4.1 Magic Numbers
函数 CALC_LOAD 是 sched.h 中定义的一个宏
extern unsigned long avenrun[ ]; /* Load averages */#define FSHIFT 11 /* nr of bits of precision */#define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */#define LOAD_FREQ (5*HZ) /* 5 sec intervals */#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */#define EXP_5 2014 /* 1/exp(5sec/5min) */#define EXP_15 2037 /* 1/exp(5sec/15min) */#define CALC_LOAD(load,exp,n) \load *= exp; \load += n*(FIXED_1-exp);\load >>= FSHIFT;
一个值得注意的好奇心是这些神奇数字的外观:1884年,2014年,2037年。它们是什么意思?如果我们查看我们学习的代码的序言,
/** These are the constant used to fake the fixed-point load-average* counting. Some notes:* — 11 bit fractions expand to 22 bits by the multiplies; this gives a* load-average precision of 10 bits integer + 11 bits fractional* — if you want to count load-averages more often, you need more* precision, or rounding will get you. With 2-second counting freq,* the EXP_n values would be 1981, 2034 and 2043 if still using only* 11 bit fractions.*/
这些神奇的数字是使用固定点(而不是浮点)表示的结果。
以1分钟的采样为例 转换为 11 位精度的
转换为 11 位精度的base-2的过程是这样的。

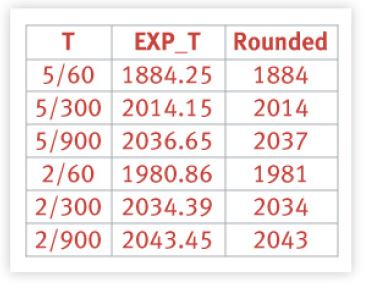
这些数字与上述内核评论中提到的数字完全一致。由于这些计算是在内核空间而不是用户空间进行的,所以使用定点表示法可能是出于效率的考虑。
然而,有一个问题仍然存在。像 这样的比率是怎么来的?
这样的比率是怎么来的?
4.2 魔法揭晓
以1分钟的平均值为例,CALC_LOAD与数学表达相同:
如果我们考虑 的情况,公式(3)变成简单的:
的情况,公式(3)变成简单的:
如果我们迭代公式(4),在 和
和 之间,我们得到:
之间,我们得到:
这是纯指数衰减,正如我们在图2中看到的 和
和 之间的时间。
之间的时间。
相反,当 时,就像我们实验中的情况一样,负载平均值被第二项所支配,这样:
时,就像我们实验中的情况一样,负载平均值被第二项所支配,这样:
这是一个单调的增加功能, 就像在图 2 之间  和
和  。
。
5. 摘要
那么,我们学到了什么?LA三联体中那三个看起来无害的数字背后有着令人惊讶的深度。
这个三联体的目的是为你提供某种信息,说明在最近(1分钟)、过去(5分钟)和遥远的过去(15分钟),系统上做了多少工作。
如果你试过洛杉矶三胞胎的测验,你会发现有一些问题:
- 负载 “不是利用率,而是总队列长度。
- 它们是三个不同时间序列的点样本。
- 它们是指数阻尼的移动平均数。
- 它们的顺序是错误的,不能代表趋势信息。
如果你试图将其用于容量规划,这些固有的限制是很重要的。我将在下一个在线专栏《负载平均数第二部分:不是你的平均数》中对这些内容有更多的阐述。
原文链接
https://www.helpsystems.com/resources/guides/unix-load-average-part-1-how-it-works

若有收获,就点个赞吧
0 人点赞
