1. 初识Partition
数据分区在 Flink 中叫作 Partition 。本质上来说,分布式计算就是把一个作业切分成子任务 Task, 将不同的数据交给不同的 Task 计算。
StreamPartitioner是 Flink 中的数据流分区抽象接口,决定了在实际运行中的数据流分发模式, 将数据切分交给 Task 计算,每个Task 负责计算一部分数据流。所有的数据分区器都实现了ChannelSelector 接口,该接口中定义了负载均衡选择行为。
在分布式存储中, Partition 分区的概念就是把数据集切分成块,每一块数据存储在不同的机器上。同样 ,对于分布式计算引擎,也需要将数据切分,交给位于不同物理节点上的Task计算。
2. 分区接口
// ChannelSelector接口定义public interfaceChannelSelector<T extends IOReadablewritable> {//下游可选 Channel 的数量void setup (intnumberOfChannels);//选路方法int selectChannel (T record);//是否向下游广播boolean isBroadcast();}
在该接口中可以看到,每一个分区器都知道下游通道数量,该通道在一次作业运行中是固定的,除非修改作业的并行度,否则该值不会改变。
3. 分区策略
目前 Flink 支持8种分区策略的实现,数据分区体系如下图: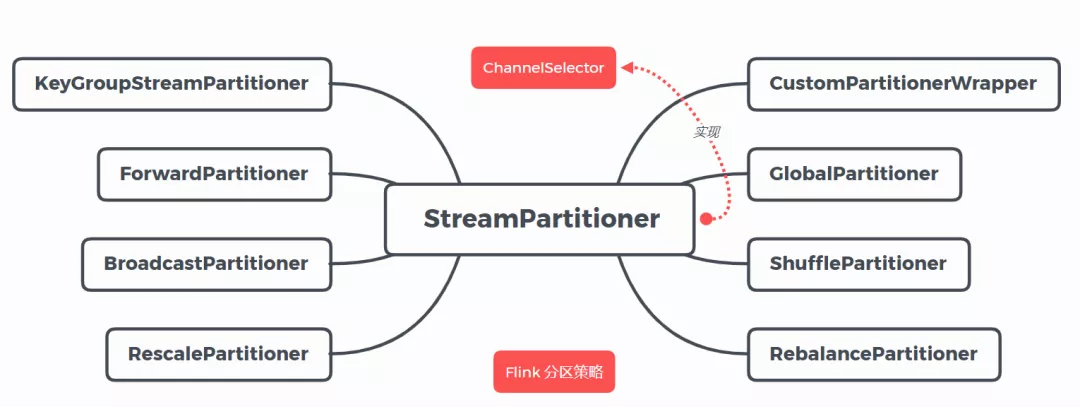
3.1 GlobalPartitioner
数据会被分发到下游算子的第一个实例中进行处理。
3.2 ForwardPartitioner
在API层面上ForwardPartitioner应用在 DataStream上,生成一个新的 DataStream。
该Partitioner 比较特殊,用于在同一个 OperatorChain 中上下游算子之间的数据转发,实际上数据是直接传递给下游的,要求上下游并行度一样。
3.3 ShufflePartitioner
随机的将元素进行分区,可以确保下游的Task能够均匀地获得数据,使用代码如下:
dataStream.shuffle();
3.4 RebalancePartitioner
以Round-robin 的方式为每个元素分配分区,确保下游的 Task 可以均匀地获得数据,避免数据倾斜。
dataStream.rebalance()
3.5 RescalePartitioner
根据上下游 Task 的数量进行分区, 使用 Round-robin 选择下游的一个Task 进行数据分区,如上游有2个 Source.,下游有6个 Map,那么每个 Source 会分配3个固定的下游 Map,不会向未分配给自己的分区写人数据。这一点与 ShufflePartitioner 和 RebalancePartitioner 不同, 后两者会写入下游所有的分区。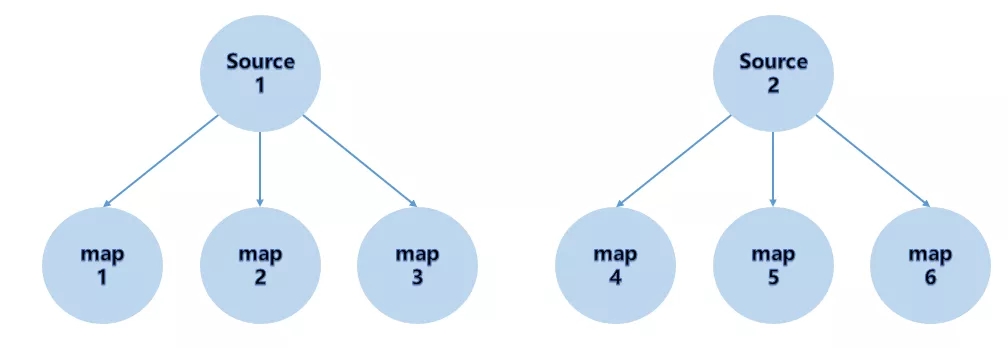
dataStream.rescale();
3.6 BroadcastPartitioner
将该记录广播给所有分区,即有N个分区,就把数据复制N份,每个分区1份。
dataStream.broadcast();
3.7 KeyGroupStreamPartitioner
在API层面上,KeyGroupStreamPartitioner应用在 KeyedStream上,生成一个新的 KeyedStream。
KeyedStream根据keyGroup索引编号进行分区,会将数据按 Key 的 Hash 值输出到下游算子实例中。该分区器不是提供给用户来用的。
KeyedStream在构造Transformation的时候默认使用KeyedGroup分区形式,从而在底层上支持作业Rescale功能。
3.8 CustomPartitionerWrapper
用户自定义分区器。需要用户自己实现Partitioner接口,来定义自己的分区逻辑。
static class CustomPartitioner implements Partitioner<String> {@Overridepublic int partition(String key, int numPartitions) {switch (key){case "1":return 1;case "2":return 2;case "3":return 3;default:return 4;}}}
出处:原文

若有收获,就点个赞吧
0 人点赞
