1. 基本转换算子
1.1 map
package com.nkong.blink.transform;import org.apache.flink.api.common.functions.FilterFunction;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;/*** @author nkong* @time 2022/2/7 15:55*/public class MyTransform {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> dataStream = env.fromCollection(Lists.newArrayList("flink", "java", "mysql", "blink"));// mapdataStream.map(new MapFunction<String, Integer>() {@Overridepublic Integer map(String value) throws Exception {return value.length();}}).print("map");env.execute();}}
1.2 flatMap
package com.nkong.blink.transform;import org.apache.flink.api.common.functions.FilterFunction;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;/*** @author nkong* @time 2022/2/7 15:55*/public class MyTransform {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> dataStream = env.fromCollection(Lists.newArrayList("flink", "java", "mysql", "blink"));// flatMapdataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {out.collect(value.toLowerCase());}}).print("flatMap");env.execute();}}
1.3 filter
package com.nkong.blink.transform;import org.apache.flink.api.common.functions.FilterFunction;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;/*** @author nkong* @time 2022/2/7 15:55*/public class MyTransform {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> dataStream = env.fromCollection(Lists.newArrayList("flink", "java", "mysql", "blink"));// filterdataStream.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String value) throws Exception {return value.contains("k");}}).print("filter");env.execute();}}
2. 多流转换算子
2.1 union
将多条流连接为一条流。
源码:
@SafeVarargspublic final DataStream<T> union(DataStream<T>... streams) {List<Transformation<T>> unionedTransforms = new ArrayList<>();unionedTransforms.add(this.transformation);for (DataStream<T> newStream : streams) {if (!getType().equals(newStream.getType())) {throw new IllegalArgumentException("Cannot union streams of different types: "+ getType()+ " and "+ newStream.getType());}unionedTransforms.add(newStream.getTransformation());}return new DataStream<>(this.environment, new UnionTransformation<>(unionedTransforms));}
注:元素类型要保持一致。<br />使用示例:
package com.nkong.blink.transform;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @author nkong* @time 2022/2/8 9:42*/public class JoinJob {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> dataStream1 = env.fromCollection(Lists.newArrayList("flink", "java", "flink"));DataStream<String> dataStream2 = env.fromCollection(Lists.newArrayList("flink", "python"));DataStream<Tuple2<String, Integer>> dataStream3 = env.fromCollection(Lists.newArrayList(new Tuple2<>("flink", 1),new Tuple2<>("blink", 2)));DataStream<String> union = dataStream1.union(dataStream2);union.print("union");env.execute();}}
输出:
union> flinkunion> javaunion> flinkunion> flinkunion> python
2.2 join
作用于两条流,只返回匹配到的结果,形成一条新的流。相当于MySQL里的内连接。
语法: dataStream.join(otherStream)
.where(0) .equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new CoGroupFunction () {…});
2.2.1 join执行流程分析:
public <T2> JoinedStreams<T, T2> join(DataStream<T2> otherStream) {return new JoinedStreams<>(this, otherStream);}
1. 调用join方法,返回JoinedStreams<T, T2>对象,该对象提供where方法:
public <KEY> Where<KEY> where(KeySelector<T1, KEY> keySelector) {requireNonNull(keySelector);final TypeInformation<KEY> keyType =TypeExtractor.getKeySelectorTypes(keySelector, input1.getType());return where(keySelector, keyType);}
2. 调用where方法,返回Where<KEY>对象,该对象提供equalTo方法:
public EqualTo equalTo(KeySelector<T2, KEY> keySelector) {requireNonNull(keySelector);final TypeInformation<KEY> otherKey =TypeExtractor.getKeySelectorTypes(keySelector, input2.getType());return equalTo(keySelector, otherKey);}
3. 调用equalTo方法,返回window对象。
public <W extends Window> WithWindow<T1, T2, KEY, W> window(WindowAssigner<? super TaggedUnion<T1, T2>, W> assigner) {return new WithWindow<>(input1,input2,keySelector1,keySelector2,keyType,assigner,null,null,null);}
使用示例:
package com.nkong.blink.transform;import org.apache.flink.api.common.functions.JoinFunction;import org.apache.flink.api.java.functions.KeySelector;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;import org.apache.flink.streaming.api.windowing.time.Time;import org.apache.flink.streaming.api.windowing.triggers.CountTrigger;/*** @author nkong* @time 2022/2/8 9:42*/public class JoinJob {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> dataStream1 = env.fromCollection(Lists.newArrayList("flink", "java", "flink"));DataStream<String> dataStream2 = env.fromCollection(Lists.newArrayList("flink", "python"));DataStream<Tuple2<String, Integer>> dataStream3 = env.fromCollection(Lists.newArrayList(new Tuple2<>("flink", 1),new Tuple2<>("blink", 2)));DataStream<String> join = dataStream2.join(dataStream3).where(new KeySelector<String, String>() {@Overridepublic String getKey(String value) throws Exception {return value;}}).equalTo(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}}).window(ProcessingTimeSessionWindows.withGap(Time.seconds(100))).trigger(CountTrigger.of(1)).apply(new JoinFunction<String, Tuple2<String, Integer>, String>() {@Overridepublic String join(String first, Tuple2<String, Integer> second) throws Exception {return "first:" + first + " " +"second:" + second.f0 + " ";}});join.print("join");env.execute();}}
输出:
join> first:flink second:flink
2.3 coGroup
将两个数据流/集合按照key进行group,然后将相同key的数据进行处理,但是它和join操作稍有区别,它在一个流/数据集中没有找到与另一个匹配的数据还是会输出。执行流程类似join。
语法: dataStream.coGroup(otherStream)
.where(0) .equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new CoGroupFunction () {…});
使用示例:
package com.nkong.blink.transform;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger;
import org.apache.flink.util.Collector;
/**
* @author nkong
* @time 2022/2/8 9:42
*/
public class JoinJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<String> dataStream1 = env.fromCollection(Lists.newArrayList("flink", "java", "flink"));
DataStream<String> dataStream2 = env.fromCollection(Lists.newArrayList("flink", "python"));
DataStream<Tuple2<String, Integer>> dataStream3 = env.fromCollection(Lists.newArrayList(
new Tuple2<>("flink", 1),
new Tuple2<>("blink", 2)));
DataStream<String> coGroup = dataStream1.coGroup(dataStream2).where(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
return value;
}
}).equalTo(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
return value;
}
}).window(ProcessingTimeSessionWindows.withGap(Time.seconds(100))).trigger(CountTrigger.of(1)).apply(new CoGroupFunction<String, String, String>() {
@Override
public void coGroup(Iterable<String> first, Iterable<String> second, Collector<String> out) throws Exception {
StringBuilder stringBuffer = new StringBuilder();
for (String s : first) {
stringBuffer.append("first:").append(s).append(" ");
}
for (String o : second) {
stringBuffer.append("second:").append(o).append(" ");
}
out.collect(stringBuffer.toString());
}
});
coGroup.print("coGroup");
env.execute();
}
}
输出:
coGroup> first:flink
coGroup> first:java
coGroup> first:flink first:flink
coGroup> first:flink first:flink second:flink
coGroup> second:python
2.4 connect
connect提供了和union类似的功能,用来连接两个数据流。
它与union的区别在于:
- connect只能连接两个数据流,union可以连接多个数据流。
- connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。
两个DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
语法: DataStream<Integer> someStream = //… DataStream<String> otherStream = //… ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);
使用示例: ```java package com.nkong.blink.transform;
import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.shaded.guava18.com.google.common.collect.Lists; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.CoMapFunction;
/**
- @author nkong
@time 2022/2/8 9:42 */ public class JoinJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStream<String> dataStream1 = env.fromCollection(Lists.newArrayList("flink", "java", "flink")); DataStream<String> dataStream2 = env.fromCollection(Lists.newArrayList("flink", "python")); DataStream<Tuple2<String, Integer>> dataStream3 = env.fromCollection(Lists.newArrayList( new Tuple2<>("flink", 1), new Tuple2<>("blink", 2))); DataStream<String> connect = dataStream1.connect(dataStream3).map(new CoMapFunction<String, Tuple2<String, Integer>, String>() { // 处理流1 @Override public String map1(String value) throws Exception { return value; } // 处理流2 @Override public String map2(Tuple2<String, Integer> value) throws Exception { return value.f0; } }); connect.print("connect"); env.execute();}
}
输出:
```java
connect> flink
connect> java
connect> flink
connect> flink
connect> blink
3. 聚合算子
3.1 keyBy
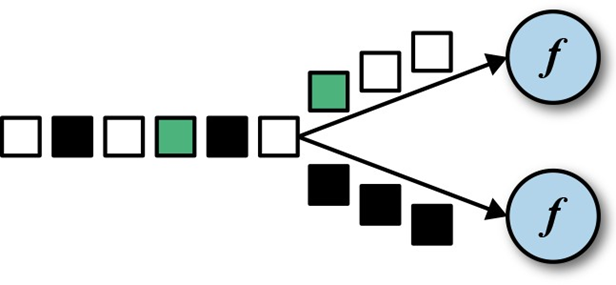
DataStream→ KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同 key的元素, 在内部以 hash的形式实现的。
1、KeyBy会重新分区;
2、不同的key有可能分到一起,因为是通过hash原理实现的;
package com.nkong.blink.transform;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author nkong
* @time 2022/2/7 15:55
*/
public class MyTransform {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> dataStream = env.fromCollection(Lists.newArrayList("flink", "java", "mysql", "flink"));
dataStream.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
return value;
}
});
env.execute();
}
}
3.2 Rolling Aggregation
这些算子可以针对KeyedStream的每一个支流做聚合。
- sum()
- min()
- max()
- minBy()
- maxBy() ```java package com.nkong.blink.start;
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector;
/**
- @author nkong
@time 2022/02/08 14:38 */ public class SumTransformJob {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> text = env.socketTextStream("127.0.0.1", 9000); DataStream<Tuple2<String, Integer>> dataStream = text.flatMap(new MyFlatMap()) .keyBy(new MyKeySelector()) // 滚动时间窗口 .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .sum(1); dataStream.print(); env.execute("SumTransformJob");}
private static class MyFlatMap implements FlatMapFunction
@Override public void flatMap(String inStr, Collector<Tuple2<String, Integer>> collector) throws Exception { String[] tokens = inStr.toLowerCase().split("\t", -1); for (String token : tokens) { if (token.length() > 0) { collector.collect(new Tuple2<String, Integer>(token, 1)); } } }}
private static class MyKeySelector implements KeySelector
@Override public Object getKey(Tuple2<String, Integer> stringIntegerTuple) throws Exception { return stringIntegerTuple.f0; }}
}
<a name="HU9iG"></a>
### 3.3 reduce
**KeyedStream**→ **DataStream**: 一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
```java
package com.nkong.blink.transform;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author nkong
* @time 2022/2/8 15:55
*/
public class ReduceJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> dataStream = env.fromCollection(Lists.newArrayList("flink,1", "java,2", "mysql,3", "flink,4"));
DataStream<Tuple2<String, Integer>> streamOperator = dataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = s.split(",", -1);
collector.collect(new Tuple2<String, Integer>(split[0], Integer.valueOf(split[1])));
}
});
KeyedStream<Tuple2<String, Integer>, String> keyedStream = streamOperator.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});
DataStream<Tuple2<String, Integer>> reduce = keyedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
/**
*
* @param value1 上次聚合计算保存的结果状态数据
* @param value2 本次流入的数据
* @return 聚合计算后的结果
* @throws Exception
*/
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<>(value1.f0 + value2.f0, value1.f1 + value2.f1);
}
});
reduce.print();
env.execute();
}
}
输出:
10> (flink,1)
10> (mysql,3)
2> (java,2)
10> (flinkflink,5)

若有收获,就点个赞吧
0 人点赞
