hive本身是一个单机程序。转在哪里都行,相对于hadoop来说就是一个hdfs的客户端和yarn的客户端,放在哪一台linux机器都无所谓,只要能链接上hadoop集群就可以,hive本身没有负载,无非就是接收一个sql然后翻译成mr,提交到yarn中去运行。
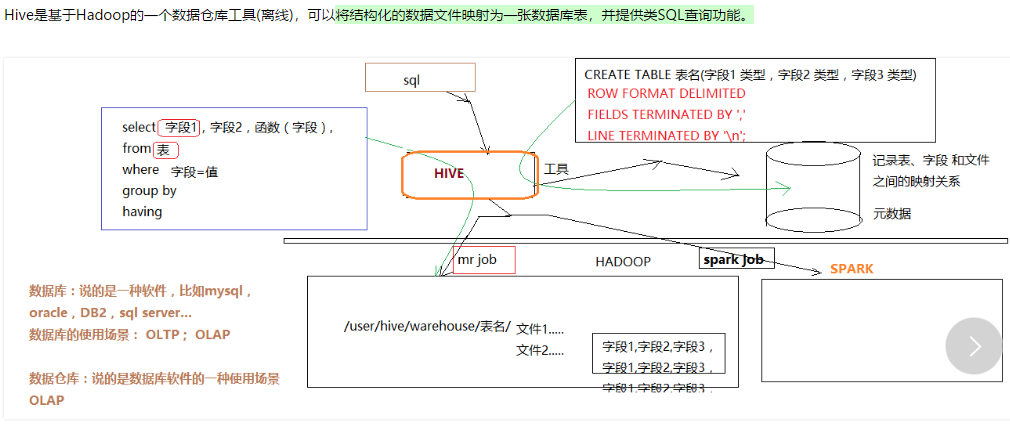
hive数据分析系统(数据仓库,像一个仓库一样,存放着很多数据,而且可以做各种查询、统计和分析,将结果放入新生的表中),的正常使用,需要mysql 和hadoop集群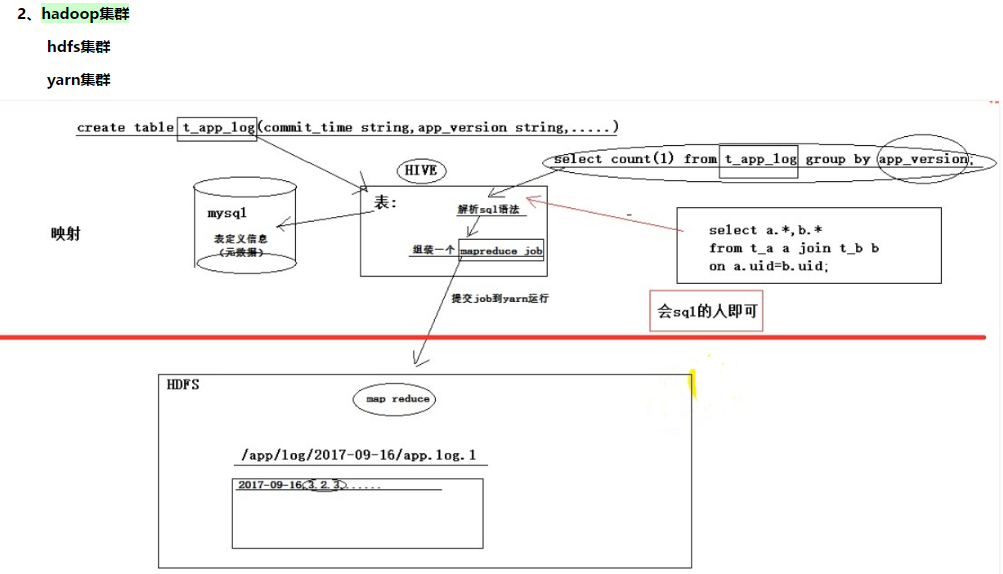
应用场景
- 直接使用hadoop所面临的问题
- 人员学习成本太高
- 项目周期要求太短
- MapReduce实现复杂查询逻辑开发难度太大
- 为什么要使用Hive
- 操作接口采用类SQL语法,提供快速开发的能力。
- 避免了去写MapReduce,减少开发人员的学习成本。
- 功能扩展很方便。

若有收获,就点个赞吧
0 人点赞
