HTTP 请求的场景相对复杂,对应的 HTTP 协议也是各式各样的,因此很多时候大家都认为内容太多太杂,认为学习 HTTP 协议性价比太低了。
其实我们日常开发中,经常会使用到 cookie、浏览器的缓存机制、各种形式的网络连接(比如 Websocket),这些网络请求相关的场景都跟 HTTP 协议有密切的关系。
对于前端开发来说,HTTP 协议基本上不会离开嘴边。HTTP 协议的内容很多很杂,这里我先给大家梳理一下它的设计和演变。
认识 HTTP 协议
上一讲,我们知道了网络请求的过程,当服务端建立起与客户端的 TCP 连接之后,服务端会持续监听客户端发起的请求。接下来,客户端将发起 HTTP 请求,请求内容通常包括请求方法、请求的资源等,服务端收到请求后会进行回复,回复内容通常包括 HTTP 状态、响应消息等。
可以看到,网络请求的过程包括两个步骤:客户端发送请求,服务器返回响应。这就是HTTP 协议的主要特点:遵循经典的 “客户端 - 服务端” 模型。
除此之外,HTTP 协议还被设计得简单易读。在 HTTP/2 之前,HTTP 协议是语义可读的,我们可以直观地获取其中的内容。比如:
- HTTP 请求方法:代表着客户端的动作行为(
GET-获取资源 /POST-提交资源 /PUT-修改资源 /DELETE-删除资源)。 - HTTP 状态码:代表着当前请求的状态(
1XX-提示信息 /2XX-成功 /3XX-重定向 /4XX-客户端错误 /5XX-服务端错误)。 - HTTP 消息头:客户端和服务端通过
request和response传递附加信息。
通过 HTTP 协议,我们可以看到该请求是否成功、错误原因是哪些、请求是否使用了缓存、请求和响应数据是否符合预期等。想必这些内容你多少都已经有所了解,因此这里我不再赘述。
前面我们说到,HTTP 协议在 HTTP/2 之前是语义可读的,那么 HTTP/2 之后发生了什么呢?我们可以看一下 HTTP 协议的演变过程。
HTTP 协议的演变
HTTP 协议从被创造以来,一直在不断演变着:从 HTTP/1.0、HTTP/1.1,到 HTTP/2、HTTP/3,HTTP 协议在保持协议简单性的同时,拓展了灵活性,提供越来越快、更加可靠的传输服务。
HTTP/1.0 到 HTTP/1.1,主要实现了对 TCP 连接的复用。 最初在 HTTP/1.0 中,每一对 HTTP 请求和响应都需要打开一个单独的 TCP 连接。这样的方式对资源消耗很大,因此 HTTP/1.1 中引入了持久连接的概念,通过设置Connection头部为keep-alive的方式,可以让 TCP 连接不会关闭。该功能避免了 TCP 连接的重新建立,客户端可在已建立的 TCP 连接上,长时间地对同一个服务端的发起请求。
HTTP/1.1 到 HTTP/2,主要实现了多个请求的复用。 HTTP/2 通过将 HTTP 消息拆分为独立的帧,进行交错发送,实现在同一个连接上并行多个请求,来减少网络请求的延迟。为了实现多路复用,HTTP/2 协议对 HTTP 头部进行了二进制编码,因此不再语义可读。除此之外,HTTP2 还实现了 Header 压缩、服务端主动推动、流优先级等能力。
HTTP/2 到 HTTP/3,主要实现了基于 UDP 协议、更快的传输。 HTTP/3 使用了基于 UDP 的 QUIC 协议,实现了又快又可靠的传输。由于 UDP 协议中没有错误检查内容,因此可以更快地实现通信。同时,QUIC 协议负责合并纠错、重建丢失的数据,解决了 UDP 协议传输丢包的问题。
总的来说,HTTP 协议的演变过程主要围绕着传输效率和速度上的优化,我们可以通过升级 HTTP 协议来优化前端应用。除此之外,我们在日常的工作中,同样可以借鉴 HTTP 协议的优化手段。比如,可以使用资源压缩、资源复用等技术手段,来优化前端性能。技术常常是通用的,我们在学习一些看起来不相关的内容时,会发现其实很多技术转变都是值得思考和参考的。
下面我们来看一下常见的一些 HTTP 协议场景。
HTTP Cookie
HTTP 协议是无状态的,这意味着在同一个 TCP 连接中,先后发起的请求之间没有任何关系。这给服务端带来了挑战:用户在同一个网站中进行连续的操作,服务端无法知道这些操作来自哪里。
使用 HTTP Cookie 可以解决这个问题。当服务端将 HTTP 响应返回给客户端时,通过在响应头里面添加一个Set-Cookie信息,浏览器收到带Set-Cookie信息的响应后会将 Cookie 保存,在后面发送给该服务端的每个请求中,都会自动带上 Cookie 信息。服务端根据 Cookie 信息,就能取得客户端的数据信息。
由于 Cookie 信息是被浏览器识别并自动保存和发送的,因此在默认情况下,浏览器关闭之后它就会被自动删除。但我们也可以通过指定过期时间(Expires)或者有效期(Max-Age),来让 Cookie 获得更久的有效期。
需要注意的是,某个网站在设置了 Cookie 之后,所有符合条件(有效期、域名、路径、适用站点等)的请求都会被自动带上 Cookie。这带来了一个 Web 安全隐患:服务端只知道请求来自某个用户的浏览器,却不知道请求本身是否用户自愿发出的。
利用这一漏洞,攻击者可通过一些技术手段(图片地址、超链接等)欺骗用户的浏览器访问曾经认证过的网站,并利用用户的登录态进行一些操作,可能导致用户信息泄露、资产被转移、在不知情的情况下发送信息等,带来了恶劣的后果。这便是我们常说的 Web 安全问题之一:跨站请求伪造(CSRF)。
为了应对这种情况,我们可以校验 HTTP 请求头中的Referer字段,这个字段用以标明请求来源于哪个地址。但由于该字段可能会被篡改,因此只能作为辅助校验手段。
防范跨站请求伪造攻击的有效方法,就是避免依赖浏览器自动带上的 Cookie 信息。我们可以使用其他方式校验用户登录态,比如将用户登录态保存在浏览器缓存中,在发送请求的时候添加用于标识用户的参数值,现在大多数应用也是使用 Token 来进行用户标识。
除了 HTTP Cookie 之外,浏览器中 HTTP 缓存机制也同样依赖 HTTP 协议。
HTTP 缓存
缓存常常被用作性能优化的技术方案之一,通过缓存我们可以有效地减少资源获取的耗时,减少用户的等待时长,从而提升用户的体验。
其中,我们可以通过 HTTP 协议,设置浏览器对 HTTP 响应资源进行缓存。使用浏览器缓存后,当我们再发起 HTTP 请求时,如果浏览器缓存发现请求的资源已经被存储,它会拦截请求并返回该资源的副本,不需要再去请求服务端获取资源,因此减少了 HTTP 请求的耗时,同时也能有效地缓解服务端压力。
一般来说,HTTP 缓存只能存储 GET 请求的响应内容,对于这些响应内容可能会存在两种情况:
- 不缓存内容,每次请求的时候都会从服务端获取最新的内容;
- 设置了缓存内容,则在有效期内会从缓存获取,如果用户刷新或内容过期则去服务端获取最新的内容。
那么,要如何给 GET 请求设置缓存呢?在浏览器中,便是依靠请求和响应中的头信息来控制缓存的。根据缓存的行为,我们可以将它们分为强制缓存和协商缓存两种。
强制缓存, 在规定有效期内,直接使用缓存。可以通过以下的方式使用强制缓存:
- 服务端通过设置
Expires和Cache-Control,和客户端约定缓存内容的有效时间; - 若符合缓存条件,浏览器响应
HTTP 200(from cache)。
- 服务端通过设置
协商缓存, 与服务端协商是否使用缓存。可以通过以下的方式使用协商缓存:
- 服务端通过设置
If-Modified-Since和If-None-Match,和客户端约定标识协商缓存的值; - 当有效期过后,浏览器将缓存信息中的 Etag 和 Last-Modified 信息,分别使用 If-None-Match 和 If-Modified-Since 请求头设置,提交给服务端。
- 若符合缓存条件,服务端则响应
HTTP 304,浏览器将从缓存读数据。
- 服务端通过设置
若以上缓存条件均不符合,服务端响应HTTP 200,返回更新后的数据,同时通过响应头更新 HTTP 缓存设置。整个过程可以用下面的流程图来表示:
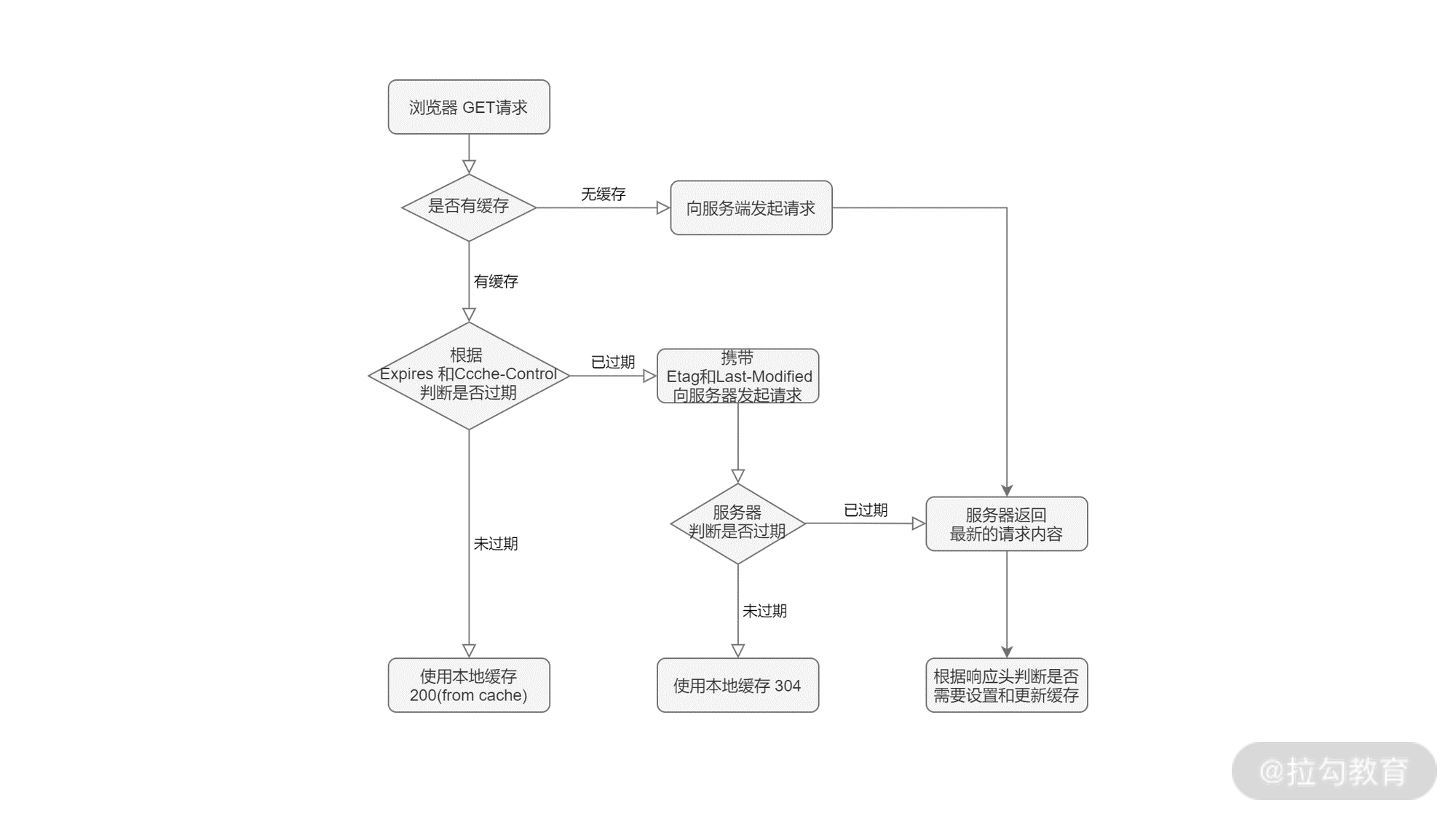
浏览器会在第一次请求完服务端后得到响应,通过适当地设置响应头信息,我们可以使用更多的缓存资源,从而提升网站的响应速度和性能,给到用户更好的体验。
除了常见的 Cookie 和 GET 请求的缓存,客户端和服务端在实现双向通信的时候,同样会依赖 HTTP 协议来完成。
客户端服务端双向通信
客户端和服务端的通信方式有很多种,大多数场景下都是由客户端主动发送数据给服务端,但在特定的场景下(如多人协作、在线游戏)客户端还需要和服务端保持实时通信,此时需要使用双向通信。
常见的双向通信方式包括 HTTP 短轮询(polling)、HTTP 长轮询(long-polling)、XHR Streaming、Server-Sent Events、Websocket 等。
其中,最简单粗暴的莫过于 HTTP 短轮询,客户端每隔特定的时间(比如 1s)便向服务端发起请求,获取最新的资源信息。该方式会造成较多的资源浪费,尤其当服务端内容更新频率低于轮询间隔时,就会造成服务端资源、客户端资源的浪费。除此之外,过于频繁的请求也会给服务端造成额外的压力,当服务端负载较高的时候,甚至可能导致雪崩等情况发生。
HTTP 长轮询解决了短轮询的一些问题,长轮询实现特点主要为当客户端向服务端发起请求后,服务端保持住连接,当数据更新响应之后才断开连接。然后客户端会重新建立连接,并继续等待新数据。此技术的主要问题在于,在重新连接过程中,页面上的数据可能会过时且不准确。
相比 HTTP 长轮询,XHR Streaming 可以维护客户端和服务端之间的连接。但使用 XHR Streaming 过程中,XMLHttpRequest对象的数量将不断增长,因此在使用过程中需要定期关闭连接,来清除缓冲区。
SSE(Server-Sent Events)方案思想便是 XHR Streaming,主要基于浏览器中EventSourceAPI 的封装和协议。它会对 HTTP 服务开启一个持久化的连接,以text/event-stream格式发送事件, 会一直保持开启直到被要求关闭。
最后我们来介绍 WebSocket,它实现了浏览器与服务端全双工通信。前面我们提到,HTTP 短轮询、长轮询都会带来额外的资源浪费,因此 Websocket 在实现实时通信的同时,能更好地节省服务端资源和带宽。
Websoctet 是如何实现全双工通信的呢?Websocket 建立在 TCP 协议之上,握手阶段采用 HTTP 协议,但这个 HTTP 协议的请求头中,有以下的标识性内容。
Connection: Upgrade、Upgrade: websocket:表示这个连接将要被转换为 WebSocket 连接。Sec-WebSocket-Key:向服务端提供所需的信息,以确认客户端有权请求升级到 WebSocket。Sec-WebSocket-Protocol:指定一个或多个的 WebSocket 协议。Sec-WebSocket-Version:指定 WebSocket 的协议版本。
如果服务端同意启动 WebSocket 连接,会在握手过程中的 HTTP 协议中返回包含Sec-WebSocket-Accept的响应消息,接下来客户端和服务端便建立 WebSocket 连接,并通过 WebSocket 协议传输数据。
由于不再需要通过 HTTP 协议通信,省去请求头等内容设置,Websocket 数据格式会更加轻量,通信更加高效,性能开销也相应地降低。除此之外,不同于 HTTP 协议,Websocket 协议没有同源限制,因此客户端可以与任意服务端通信。
以上这些,都是客户端和服务端双向通信的一些解决方案,我帮你简单整理成思维导图:
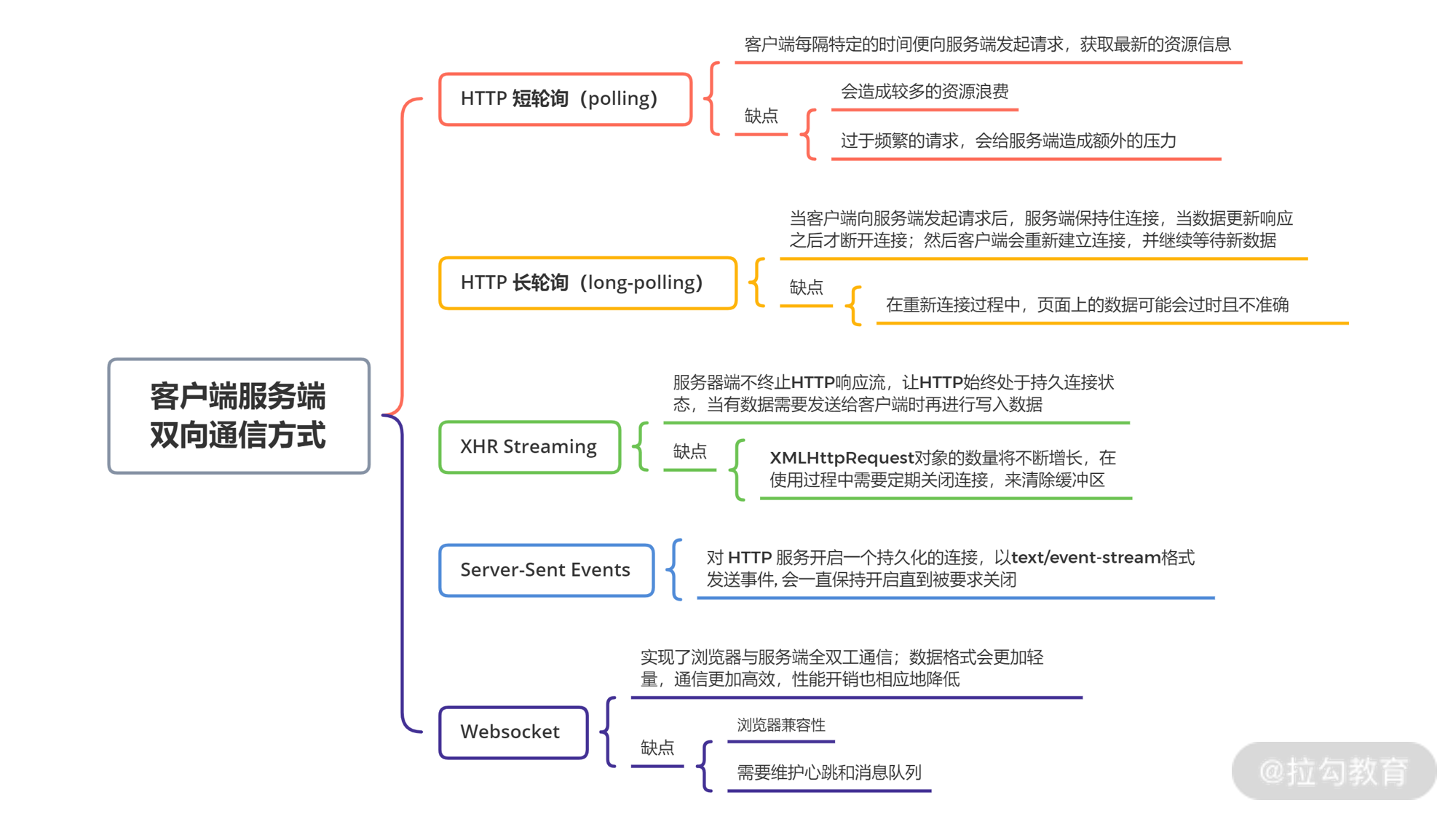
在依赖双向通信的场景中,这些方案并没有绝对的最优解,更多时候都是不同场景和架构设计下的选择。
如果你去仔细研究在线协作的办公工具,比如谷歌文档、石墨文档、金山文档、腾讯文档,你会发现它们的双向通信都分别使用了不同的解决方案。
小结
今天,我主要介绍了 HTTP 协议相关的内容,同时介绍了较常见的一些 HTTP 协议的应用场景,包括 HTTP Cookie、HTTP 缓存、客户端和服务端双向通信。
关于 HTTP 缓存过程想必你也应该掌握了,那你知道当我们在浏览器中分别使用F5和ctrl + F5快捷键刷新页面的时候,HTTP 的缓存过程又是怎样呢?把你的想法写在留言区~
我们在日常开发中就会经常遇到网络请求失败、调试异常等情况,如果不了解 HTTP 协议会极大地影响调试效率。因此对 HTTP 协议的掌握,对于前端的联调和开发过程中是必不可少的。

若有收获,就点个赞吧
0 人点赞
