人体姿态估计
数据集
MPII, CrowPose, Human3.6, MSCOCO等
性能评价
目前主要用的是 AP 或者 mAP
根据 oks(object keypoint similarity) 计算关键点的相似度,根据相似度以及阈值来计算 AP
 pred 和 GT 的欧式距离
pred 和 GT 的欧式距离-
单人人体姿态估计
DeepPose
首个利用深度学习进行人体关键点估计的论文。
直接回归关键点
-
CPM
级联优化(感受野不断增大)
- 中继监督(防止梯度消失)
- 回归的是 heatmap
 人体尺寸因子
人体尺寸因子
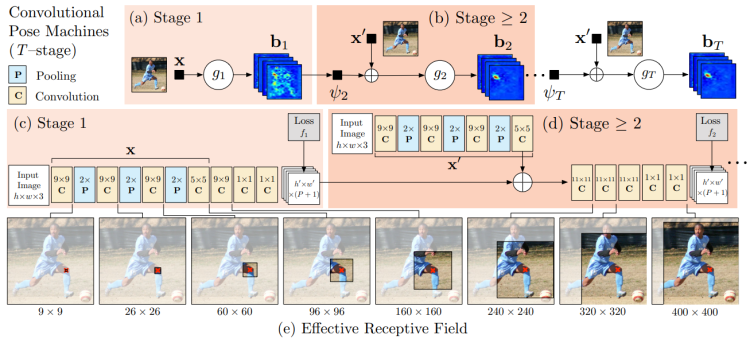
Stacked Hourglass Network
- 中继监督
- 级联优化
- 沙漏模型
单个沙漏先进行下采样,然后进行上采样;前后对称层之间有 short cut。
- 上采样采用了插值上采样的方式
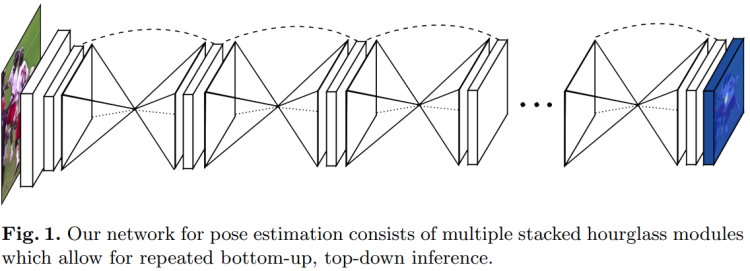
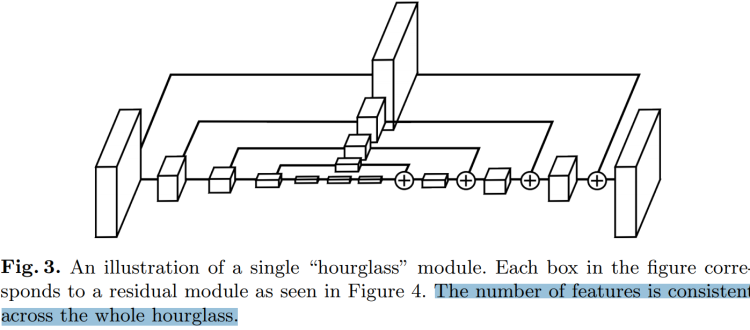
多人人体姿态估计
top-down vs bottom-up:
- top-down 先进行人体检测,然后进行单人人体姿态估计;精度高,但是速度慢
bottom-up 先进行关键点检测,然后进行关键点的聚类;速度慢,但是精度低
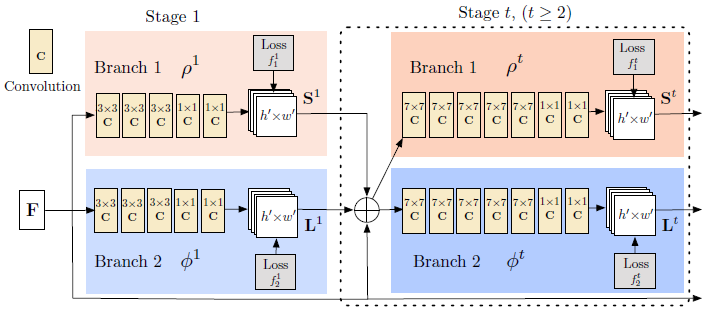
openpose
其网络结构如下图所示:
 是通过 VGG-19 前 10 层提取的特征
是通过 VGG-19 前 10 层提取的特征- branch 1 提取的是 confidence maps,即关键点的 heatmaps

- 同一类型的关键点在同一张 map 上面;所有人体有几个关键点就有几张 map
- branch 2 提取的是向量场 PAFs,里面保存的是一系列和关节点对相关的向量
- 同一类型的关节点对在同一张 map 上面;所以人体有几个关键点对就有几张 map
- 网络采用多阶段和中继监督的策略,特征
 不断被重用
不断被重用

- 损失函数:
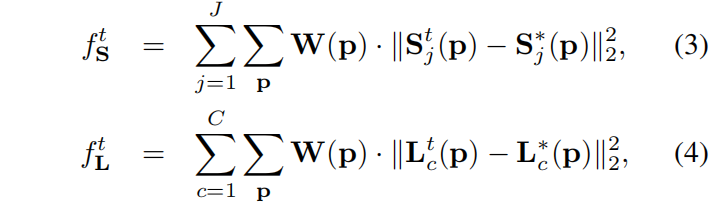
- 其中
 是 binary mask,不将为标注的关键点考虑进来
是 binary mask,不将为标注的关键点考虑进来
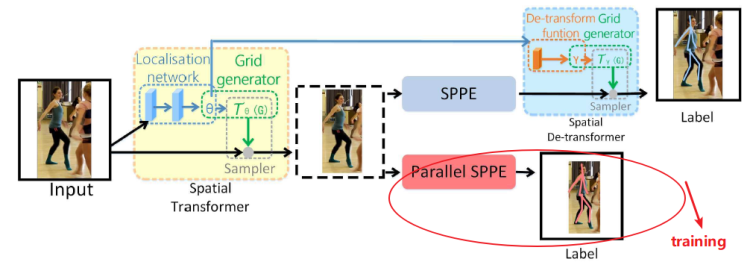
alphapose
alphapose 的出发点:准备的人体目标检测可以得到更加准确的人体关键点估计结果
三个模块:
SSTN:对称空间变换网络
- 人体目标的平移居中,提前会对检测的 bounding-box 进行扩展,缓解人没有被完全检测出来的问题
- 训练中有一个 P-SPPE,相当于一个中继监督,为的就是实现 SPPE 前面的图片目标居中
p-NMS:姿态 NMS
- 但是如果采用 top-down 方法的话,大部分重复检测会在目标检测的 NMS 中被去除
- 首先选取置信度最大的姿态,如果两个姿态相似度太高,则去掉置信度低的姿态
PGPG:用于姿态增强
- 代码实现:yolo-v3 进行人体目标检测,检测之后输入 ResNet 改的模型(下采样,然后上采样)中进行 heatmaps 回归
simple baseline
采用简单的架构,没有加入其它 tricks,利用 ResNet 到 C5 的层进行特征提取,然后进行上采样得到 heatmaps 估计。
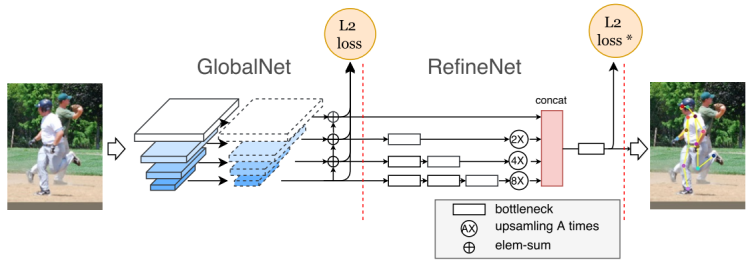
Cascaded Pyramid Network
出发点:人体的关键点有两类,一类是易于检测的,另一类是难以检测的(也即是难点)。所以作者提出了级联网络来解决难点检测问题。
- GlobalNet 检测简单关键点
- RefineNet 检测难点,在 GlobalNet 基础上进行精细化
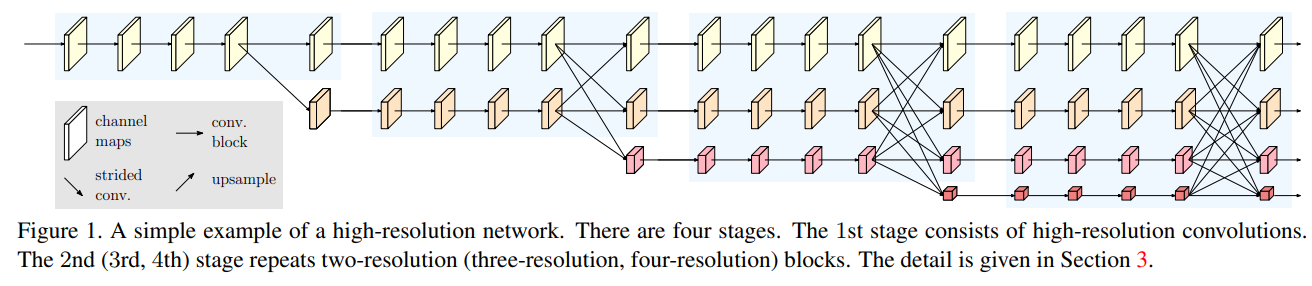
hrnet
出发点:高分辨率能够提高人体关键点检测的准确性。
- 将高分辨率和低分辨率并联(之前的网络都是串联)
- 高分辨率一直保留
- 高低分辨率之间进行信息的交互
- 每 4 层都会产生一个下采样的分支
图卷积神经网络
图卷积
st-gcn
最原始的版本
- 利用物理连接构建临接矩阵

- st-gcn 分为两部分: gcn 和 tcn
- gcn:1x1 卷积之后汇聚临接节点的信息
- tcn:在时间维度进行 cnn 卷积
-
as-gcn
在物理连接的基础上,学习 actional links,对物理连接进行补充
2s-agcn
同时考虑了关节和关节点(关节的连接关系和关节点连接关系相同)
临接矩阵分为了三部分:物理连接
 ,可学习的
,可学习的  ,以及关节点相似度计算产生的
,以及关节点相似度计算产生的 
ctrgcn
之前的考虑临接矩阵都是各个 channel 共享的,本文对不同 channel 给出不同的邻居矩阵
N,C,T,V,M 去掉 M -> N,C,T,V
-
posec3d
-
其它动作识别方法
双流法
图像 CNN 支路
- 单帧图像
- 光流 CNN 支路
- 多帧光流

若有收获,就点个赞吧
0 人点赞
