常见损失函数
CrossEntropyLoss

表示样本
被正确分类的概率
MSELoss

用于回归任务
HingeLoss

FocalLoss

其中  和
和  都是大于 0 的。
都是大于 0 的。 越大难分样本的相对权重就越大,但是此时整体的损失的就会越小。
越大难分样本的相对权重就越大,但是此时整体的损失的就会越小。
样本不平衡的措施
- 上下采样
- 对不同类别的数据产生 loss 赋予不同的权值
- 数据增强,增加样本
样本不平衡时好的指标:ROC 和 AUC、F 值、G-Mean;不好的指标:Precision、Recall
样本少解决措施
- 采用简单的方法完成任务,人工设计特征
- 采用迁移学习,利用预训练模型进行微调
GAN 的 Loss
TODO其它重要函数
交叉熵
https://www.yuque.com/muyetingfeng/qsvec8/wng6ng
信息量:一个事件 的信息量定义为
的信息量定义为 
相对熵(KL散度):设p(x)、q(x)是X中取值的两个概率分布,则有
信息熵:信息量的期望
交叉熵:定义为
往往 p 表真实分布,q 表示预测分布
常见指标
P-R 曲线
p: precision 查准率 
r: recall 查全率 
根据设置不同的阈值(预测概率大于某个阈值则预测为正类),可以得到不用的 p-r 值,从而形成一条曲线,即为 p-r 曲线
AUC
auc 可以换种方式进行理解:任取一对正负样本,正样本预测 score 大于负样本预测 score 的概率 -> 转换为样本统计问题了。
area under curve,即为 p-r 曲线下面区域对应的面积大小。AUC 越大则模型的效果越佳。
优化器
SGD
随机梯度下降算法,随机的意思是指,每次在样本中随机进行样本的采集然后更新模型参数。理论上是将数据一下全部送入模型才能得到全局最优解的。
动量
每次不直接根据梯度来更新参数,而是引入一个动量,每次向更新动量,然后利用动量来更新参数:
Adam
https://www.jianshu.com/p/aebcaf8af76e
卷积神经网络
经典网络
- AlextNet:引起热潮
- VGG:使得 AlexNet 更加规范化,简单化 -> 堆叠 conv-conv-maxpool,并采用 3x3 卷积使网络更深
- GoogLeNet:引入并行的分支结构,采用不同大小的 kernel 进行特征的提取
- ResNet:引入残差连接,使得网络能够做得非常深
- NiN:引入 1x1 进行降维和通道整合
之后引入了注意力机制:
- SE-Net:在 channel 维度进行加权
- CBAM:SE-Net 的扩展,在 channel 和 spatial 维度进行加权
- SK-Net:SE-Net 的扩展,采用两种不同的卷积核得到两张 feature map,然后进行相加,在相加的 feature map 上计算两个 channel attention 作为前面两张 feature map 的加权值,最后两个 feature map 进行综合
- ResNetst:在 ResNet 中引入 Split Attention
再之后就是 VIT 了
- ViT,将图像分为不同的 patch,将每个 patch 作为一个 Token,然后按照 NLP 中的 方式进行处理
Swin-transformer,为了提取层次信息,同时考虑局部信息和全局信息,将图像分为不同的窗口,每个窗口内部不同 patch 采用自注意机制进行计算;为了融和不同窗口的信息,采用 shift window 层进行窗口信息的交互
卷积中的一些概念
感受野
一个像素对应到原图中区域的大小。
比如网络一直单独采用 kxk 卷积,那么第 i 层卷积输出结果中的某个像素的感受野为 (k-1) x (i-1) + k
k -> k + k-1 -> k + k-1 + k-1 -> …
在比如网络采用( kxk 卷积 + kxk maxpool stride=2)进行,那么第 i 层操作之后某个像素的感受野
k -> 2xk + k-2 -> 2xk + k-2 + k-1 -> 2x(2xk + k-2 + k-1) + k-2 -> …
空洞卷积
反卷积
组卷积
是为了降低计算量,在卷积过程中,并不会融合所有通道的信息,而是将通道进行分组,在组内进行卷积。但是分组之后卷积的输出通道必须是组数的倍数。
激活函数
tanh,relu,sigmoid 等。relu 用得比较多,因为它比较简单,而且不像 sigmoid 和 tanh 在两端可能出现梯度消失。relu 改进版 -> lekeyrelu(relu 将负数值的梯度直接置为 0)
循环神经网络
循环神经网络是为了处理时序信息而引入的。在时序信息中,当前的状态会和历史信息相关联也即是说  。如果直接考虑这种依赖关系模型会非常复杂,所以引入了隐状态来解决这个问题。隐状态
。如果直接考虑这种依赖关系模型会非常复杂,所以引入了隐状态来解决这个问题。隐状态  可以编码历史信息。
可以编码历史信息。
RNN
rnn 结构非常简单,公式如下所示:
如果多层的话?多几个隐藏层即可!
但是这种模型不能处理较长的信息,并且容易产生梯度消失的问题。
GRU
GRU 对 RNN 进行了改进,引入了两个门控单元:重置门和更新门,来控制当前历史信息和当前信息对当前隐状态的的影响大小。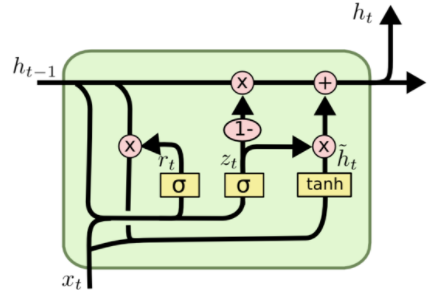

和
都是权值,
是 softmax 函数;
表示 element-wise product
的值是没有被约束的
LSTM
LSTM 和 GRU 很类似,但是它有三个门:遗忘门、记忆门和输出门。结构相对复杂,难以记忆,但是和 GRU 很类似,此处略过。
编码器解码器架构
注意力机制
对于多对多的任务都是采用编码器解码器架构的,例如 seq2seq 的翻译模型。编码器和解码器都可以利用 RNN 进行构建。而在这种任务中人们提出了注意力机制来解决长依赖问题,使得模型能够关注到更加全局的信息。
CV 里面也有注意力机制,但是有的和 NLP 中的注意力机制是不一样的。比如 CBAM 和 SE 它更像是对不同响应值的筛选过程,而不是像 NLP 中来获取全局关联
对于编码器我们可以得到不同时刻的隐状态  ,解码器以
,解码器以  作为初始化的隐状态,以
作为初始化的隐状态,以  ,上一时刻预测的
,上一时刻预测的  将作为当前时刻的输入。由于
将作为当前时刻的输入。由于  在迭代过程中会有信息损失,可以将所有的
在迭代过程中会有信息损失,可以将所有的  利用起来,解决长依赖问题。
利用起来,解决长依赖问题。 映射之后产生
映射之后产生  ,解码器预测的输出作为
,解码器预测的输出作为  进行查询得到向量
进行查询得到向量  ,
, 与解码器隐状态进行连接之后通过输出层得到输出。
与解码器隐状态进行连接之后通过输出层得到输出。
transformer
transformer 利用了全注意力机制,结构
编码器:embedding + positional encoding + mutil-head attention + add&norm + FFN + add&norm
解码器:embedding + positional encoding + masked multi-head attention + add&norm + mutil-head attention(借助于编码器) + add&norm + FFN + add&norm
- multi 类似于卷积中的通道
- layernorm 可以控制在哪几个维度进行 norm。设输入为[B, T, D],如果在 [T, D] 进行 norm,那么可学习参数为 2x(TxD) (均值和方差)
- bn 的话参数应该是 2xC
语言模型数据处理
- 句子分为词元(例如单词或者字符)
- 统计词元频率,并进行排序,排序结果作为每个词的 id(形成词典 vocab)
训练模型或者用其它方法将 id 进行嵌入(词嵌入),转变为向量
nn.embedding 等,嵌入是使得相似单词在单词空间中更近
-
GAN
目标检测
目标检测最开始的时候采用滑动窗口 + 分类器的架构,比如 Hog 特征提取 + SVM 分类的方式。
Fast RCNN
- 采用 selective search 算法生成检测框
- 检测框映射到 feature map(检测框点的映射关系)产生 ROI
- 为了统一 ROI 大小,改进了 RCNN 里面的 resize 方法,提出了 ROI Pooling
- 每次选取 N 张图片,然后每张图片采集 R 个 ROIs 进行训练
-
Faster RCNN
针对 Fast RCNN 仍旧采用传统方法进行检测框的生成,提出了 RPN 来自动产生 Region Proposals
- Region Proposals 事实上就是一个粗的检测框检测和类别分类的网络(一阶段的网络都是以此作为输出的)
- RPN 还需要预测每个 Proposal 是正负样本的概率,直接一个映射即可,信息对应到 channel 维度
- 对于锚框:特征图上每一个像素点映射回原图,对于与一个 16 x 16 的图像块,每个图像块的中心将预定义 9 个锚框,RPN 回归出相对于预定义锚框的偏移量
-
Mask-RCNN
Mask-RCNN 在模型训练时引入多任务,同时进行目标检测和风,提高了模型的稳定性。其另一个改进是 ROI Align,因为 ROI Pooling 在映射过程中会产生两次取整过程,这样会造成偏差,所以作为引入了插值来代替取整,从而去除因取整带来的误差。
-
SSD
结构比较简单,骨干网络采用 VGG-16 的前几层,后面不断进行卷积和下采样,利用不同尺度的 feature map 进行目标的预测。(锚框和前面所述相似,每个类别都对应于一个检测框,不同层产生的预测锚框数量不同)

FPN
受 U-Net 启发,采用特征金字塔结构,先下采样再上采样;上采样和下采样过程中的对应层进行信息交互;最后利用上采样的多层进行目标的预测
RetinaNet
与 FPN 结构类似,同样是单阶段的网络,主要贡献是提出了 focal loss。值得注意的是单阶段模型通常来说不会将类别预测和检测框预测分开(直接融合在通道维度),RetinaNet 则对类别预测和检测框的预测分开进行。
YOLOV1
无 Anchor 预定义
- 直筒网络
- 网络输出
 ,其中
,其中
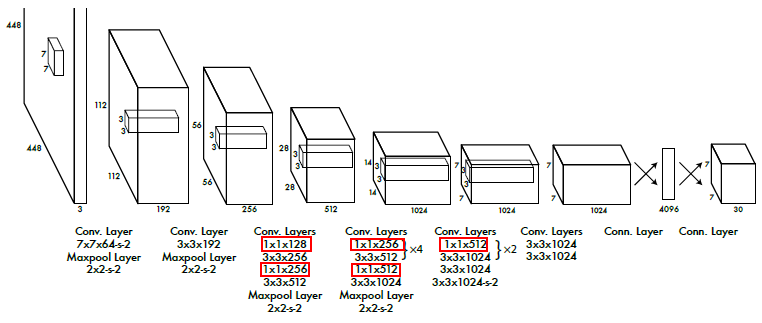

YOLOv2
- 引入了 Anchor 机制,每个中心预测 5 个框
- S 增大为 13,类别扩大为 9000
- 引入了不同尺度信息进行融合
- 输入图像为多尺度
-
YOLOv3
引入了残差结构
-
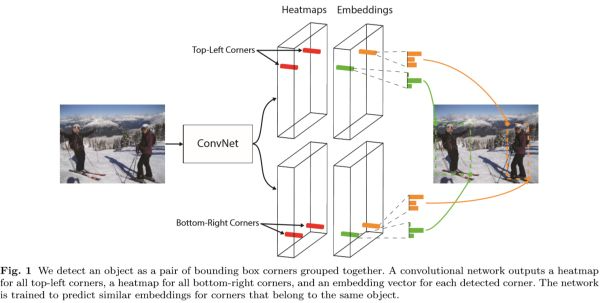
CornerNet
Anchor Free 的方法
- 预测检测框的左上角和右下角的坐标
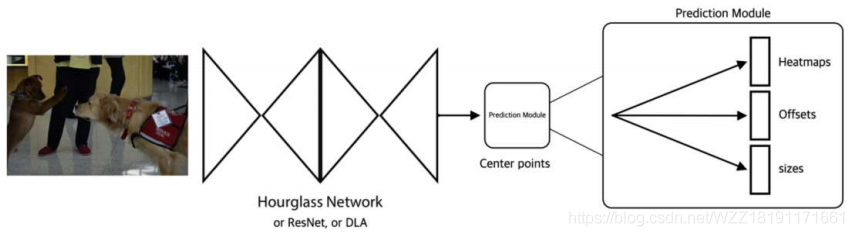
CenterNet
- 预测目标的中心
- 在中心的基础上预测出检测框和类别

若有收获,就点个赞吧
0 人点赞
