What is quantization-aware training (QAT)?
Different from post-training quantization (or “offline quantization”), quantization-aware training needs to simulate the influence of quantization operation in training, and make the model learn and adapt to the error caused by quantization operation through training, thus improving the quantization accuracy. QAT means that that this model is aware that it will be converted into a quantized model during training.
How to use QAT in MNN
Start with a float model that’s been trained by other DL frameworks, such as TensorFlow and PyTorch. In this case, you can convert the float model into MNN model format through MNNConvert. And then, an int8 inference model is directly quantified using the offline quantization tool provided by MNN. If the accuracy of this model does not meet the requirements, the accuracy of the quantization model can be improved by QAT.
Steps to use QAT in MNN:
- First, obtain the original float model through other DL frameworks;
- Compile MNNConvert model conversion tool;
- Use MNNConvert to convert the float model into MNN model format. We recommend that you keep the operators used during training such as BN and Dropout, this can be achieved through the
--forTrainingoption of MNNConverter; - Refer to
MNN_ROOT/tools/train/source/demo/mobilenetV2Train. The MobilenetV2TrainQuant demo in cpp implements the training quantization function. The following takes the training quantization of MobilenetV2 as an example to see how to read and convert the model into a training quantization model. - Observe the change of accuracy, and the model saved by the code is the quantitative inference model. ```cpp // mobilenetV2Train.cpp
// Reads the converted MNN float model. auto varMap = Variable::loadMap(argv[1]); if (varMap.empty()) { MNN_ERROR(“Can not load model %s\n”, argv[1]); return 0; } // Specifies the bit width of quantization. int bits = 8; if (argc > 6) { std::istringstream is(argv[6]); is >> bits; } if (1 > bits || bits > 8) { MNN_ERROR(“bits must be 2-8, use 8 default\n”); bits = 8; } // Gets the inputs and outputs. auto inputOutputs = Variable::getInputAndOutput(varMap); auto inputs = Variable::mapToSequence(inputOutputs.first); auto outputs = Variable::mapToSequence(inputOutputs.second);
// Scans the whole model and converts the inference model into a trainable model.
// The model obtained here is a trainable float model.
std::shared_ptr
<a name="E73VK"></a># MNN QAT basicsThe basic principle of MNN QAT is shown in the following figure.<br />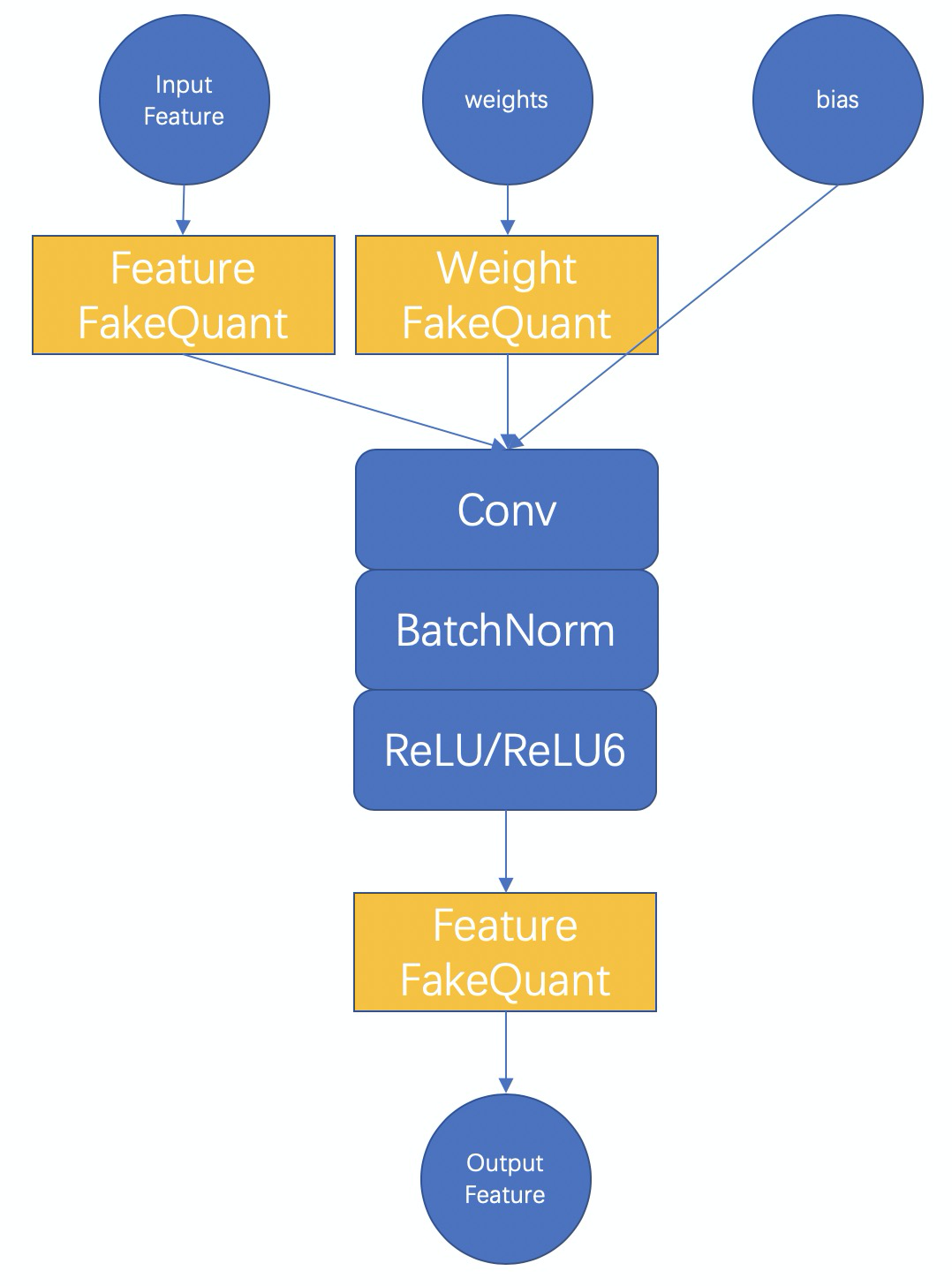<br />Taking int8 quantization as an example, we should first understand the whole process of full int8 inference. Full int8 inference means that the feature should be quantified to int8, and the weight and bias should also be quantified to int8, the output can be float or int8, depending on the next op of the convolution module. The essence of training quantization is to simulate the influence of quantization operation in the training process, and to make the model learn and adapt to this influence through training, so as to improve the accuracy of the final quantization model.<br />Therefore, in the two FakeQuant modules, our main calculation is<br />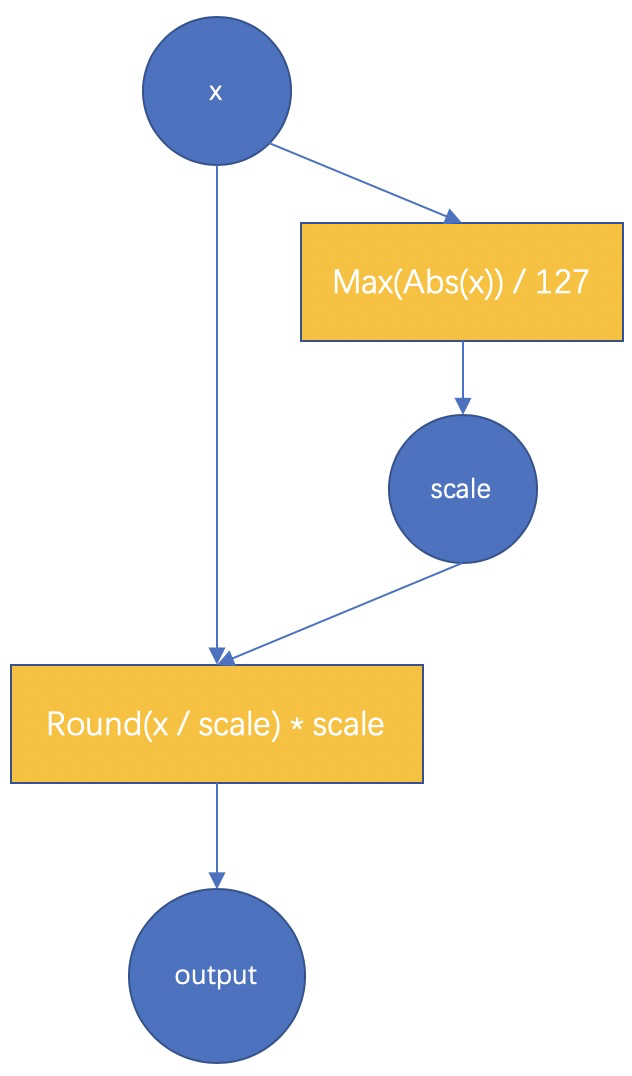<br />The fake-quant for weight and feature is basically the same as that shown in the above figure. The difference is that the range of the feature changes dynamically with the input, in the final int8 model, a scale value for input features must be fixed. Therefore, we have cumulatively updated each scale calculated from the previous direction, for example, using sliding average, or directly take the maximum value of each time. For the scale of the weight, there is no average, because the weight after each update is a better result after learning, and there is no state retention.<br />In addition, for features and weights, we provide scale statistics methods for PerChannel or PerTensor, which can be used according to the effect.The above is the calculation process during the training phase. In the test phase, we will Combine BatchNorm into the weight, Quantize the features and weights by using the feature scale obtained in the training process and the scale of the weights at this time (obtained by each recalculation), and call_FloatToInt8 and_Int8ToFloat in MNN to conduct inference, so as to ensure that the results obtained from the test are consistent with the results of the entire int8 inference model finally converted.When the model is saved at last, the model in the test phase will be automatically saved and some redundant operators will be removed. Therefore, the full int8 inference model will be saved directly.<a name="twKi8"></a># Training quantization resultsAt present, we have tested Lenet,MobilenetV2, and some internal face models, and achieved good results. Here are some detailed data of MobilenetV2| | Accurary / Model Size || --- | --- || Original Float Model | 72.324% / 13M || Int8 model after MNN QAT | 72.456% / 3.5M || Int8 model after TF QAT | 71.1% / 3.5M (Original model 71.8% / 13M) |The above data is obtained by training 100 iterations with the batchsize of 32, that is, only 3200 images are used for training quantization, and 50 thousand images in the ImageNet validation set are tested. It can be seen that the accuracy of the int8 quantization model is even higher than that of the float model, while the size of the model drops by 73%. At the same time, the inference speed gain can be obtained.[Note] the float model used here is the model officially provided by TensorFlow, but the official accuracy data is 71.8%. Our model has slightly higher accuracy because of some subtle differences in the pre-processing code.<a name="mMwAl"></a># Some suggestions for using QAT1. During model conversion, retain the operators used in training such as BatchNorm and Dropout. These operators are helpful for QAT.1. Use the training parameters of the original model close to the convergence. Incorrect training parameters will lead to unstable quantization training.1. The learning rate should be decreased.1. We only implement training quantization for the convolution layer. Therefore, if you use MNN to build a model from scratch and then use QAT, or you want to continue QAT after finetune, then we need to use the convolution layer to implement the full connection layer to train and quantize the full connection layer. The sample code is as follows```cpp// Use conv layer to implementation a 1280 input/ 4 output FC layer.NN::ConvOption option;option.channel = {1280, 4};mLastConv = std::shared_ptr<Module>(NN::Conv(option));
Configuration options for training quantization
See MNN_ROOT/tools/train/source/module/PipelineModule.hpp for details.
// Stat method for feature scales.enum FeatureScaleStatMethod {PerTensor = 0, // Per-tensor quantiztion for the features.PerChannel = 1 // Per-channel quantization for the features};// Update method for feature scales.enum ScaleUpdateMethod {Maximum = 0, // Uses the maximum value for the scale in each calculationMovingAverage = 1 // Uses the moving average};// Specifies the bit width, stat method for feature scales and update method for features scales.void toTrainQuant(const int bits = 8, NN::FeatureScaleStatMethod featureScaleStatMethod = NN::PerTensor,NN::ScaleUpdateMethod scaleUpdateMethod = NN::MovingAverage);

若有收获,就点个赞吧
0 人点赞
