- 一 Redis的数据类型:8种
- 二 Redis穿透以及解决
- ">
- 三 Redis击穿以及解决
- 四 Redis雪崩以及解决
- 五 Redis倾斜以及解决
- 六 持久化以及区别:2种
- 七 过期策略:2种
- 八 淘汰机制
- 九 Redis集群方案:3种
- 十 Redis为什么快
- 十一 Redis和MongoDB的区别
- 十二 RedLock(红锁)分布式实现原理
- 十三 Redis的String类型的底层
- 十四 Redis的SkipList
- 十五 Redis的事务
十六 Redis的Ziplist- redis如何发现hot和big key
- redis如何实现高并发:
- redis如何实现高可用:
- redis单线程还能处理速度那么快:
- reids的好处
- 什么是redis的持久化?RDB和AOF的比较?
- redis使用场景
- 分布式缓存:
一 Redis的数据类型:8种
redis远程字典服务,由C语言编写,是一款基于key-value的NO-SQL,
基于内存存储数据库,并提供多种持久化机制,还提供了主从,哨兵,以及集群搭建,可以横向扩展,纵向扩展。
特点:
1 key-value类型
2 内存存储
3 提供持久化,主从,哨兵,集群,扩展
4开源
八大数据类型:
1 string:一个值对应一个值
2list:一个key对应一个list集合
3set:一个key对应一个set集合
4 hash:一个key对应一个map
5 sortset/zset:一个jey对应一个有序的set集合,等价于:map
另外3种数据结构:
6 geo:地理位置坐标,地点信息唯一,经纬度准确,经度(longitude):纵向,维度(latitude):横向的
7bit:位图,位(0或1),默认是0,当成数组来用,常用来统计用户信息,比如活跃粉丝和不活跃粉丝,登录,打卡等
8hyperloglog:计算近似值的,基数,数学上集合的元素个数,是 重复的,这个数据结构常用来保存用于统计微网站的UV,传统的方式是使用set保存用户的id,然后统计set中元素的数量作为判断标准,但是这种方式保存了大量的用户id,占空间且麻烦,这时候用hyperlog就比较合适了。
UV(unique vistor):是指通过互联网访问,浏览这个网页的自然人,访问的一个电脑客户端一个访客,一天内同一个访问仅被计算一次
二 Redis穿透以及解决
现象:
如果每次都去查一个“缓存和数据库都不存在的数据(如id=-1的数据)”,因为缓存中并不存在,那么每次请求都会打到DB上,从而导致缓存失去意义,在高并发的情况下可能导致数据库崩溃,这就是缓存的穿透
解决方案:
1 考虑key过滤
规范key的命名,并且统一缓存查询的入口,在入口处对key的命名格式进行检测,过滤掉不规范key的访问,这样可以过滤掉大部分的恶意攻击。如约定项目中redis缓存key的前缀都是以“公司名项目名_redis“开头,不符合这个约定的key在一开始就过滤掉
2 缓存空值
简单粗暴,如果查询db返回的数据为空,我们仍然把这个空值放到redis缓存中,只是将他的过期时间设置的很短,另外为了避免不必要的内存消耗,可以定期清理空值的key
3 加锁
根据key从缓存中获取到的value为空时,先加锁,再去查DB将数据加载到缓存,若其它线程获取失败,则等待一段时间后重试,从而避免了大量请求直接打到DB。单机可以使用synchronized或reentrant lock加锁,分布式环境需要加分布式锁,如redis分布式锁
4 布隆过滤器
如果想判断一个元素是不是在一个集合里,一般做法是将集合中所有的元素保存起来,然后通过比较确定,比如HashMap。但是随着集合中元素的增加,数据量超大时,需要的存储空间也越来越大,甚至超过服务器内存,这时就不能用HashMap等数据结构了
这时布隆过滤器就出场了,它的空间效率非常好,是一个二进制向量,每一位存放的时0或1,初始时默认为0,如图:
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
可以看出,布隆过滤器没有存放完整的数据,只是运用一系列随机映射函数计算出位置,然后填充二进制向量,所以空间效率非常好,
预先将所有的缓存数据的key存放到布隆过滤器中,当一个查询的请求过来时,先判断这个key在布隆过滤器中是否存在
如果不存在,直接返回提示,就不用区查询DB了
如果存在,则去查缓存,但是布隆过滤器的判断有一定的误判率,如果误判率针对的业务场景是可以接受的,则可以忽略;可以用guava实现布隆过滤器的指定的误判率不超过指定的值;也可以针对少部分的漏网之鱼(因为布隆过滤器可以过滤绝大多数的恶意key),在缓存层面使用功能上面说过的缓存空值或者加锁的方案。
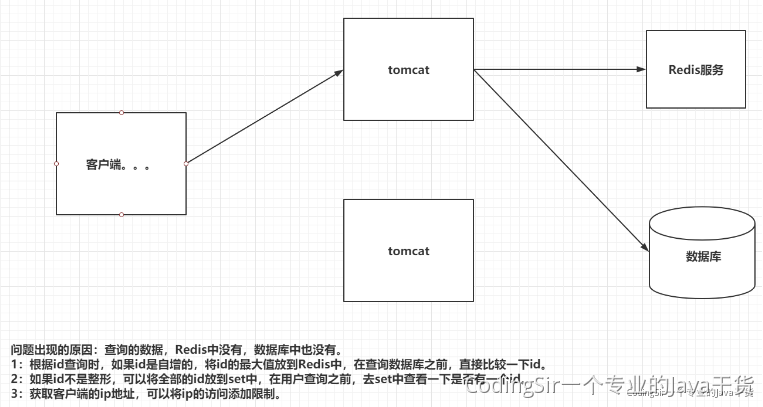
三 Redis击穿以及解决
现象:
缓存击穿和穿透是不一样的,缓存击穿是指某个热点key在失效的瞬间(一般是缓存到期),持续的大并发请求穿破缓存,直接打到数据库,就像在屏障上凿开一个洞,造成数据库压力瞬间增大,这就是缓存击穿,
热点key:某个访问非常频繁,访问量非常大的一个缓存key,叫做热点key
解决方案:
1设置热点key永不过期
2加锁,根据热点key从缓存中获取到的值为空时,先锁上,再去查DB将数据加载到缓存,若其他线程获取失败,则等待一段时间后重试,从而避免大量请求直接打到DB。单机可以使用synchronized或reretrantlock,分布式需要加分布式锁,如redis分布式锁【为了不阻塞其他key的请求,这里可以用热点key来加锁】
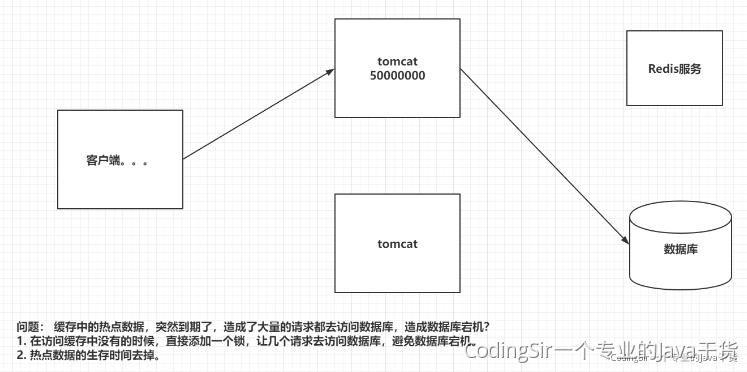
四 Redis雪崩以及解决
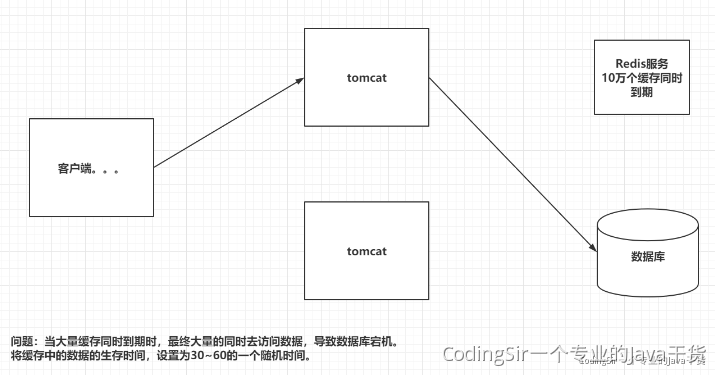
现象:
缓存雪崩是指缓存由于某些原因整体或者大量热点key失效,导致大量请求打到后端数据库,从而导致数据库崩溃,整个系统崩溃。
导致缓存整体大量失效的场景一般有:
1 缓存服务器宕机,如redis集群彻底崩溃
2 在某个集中的时间段内,系统预先加载的缓存集中失效了
解决方案:
1 保证缓存层服务器高可用性,如使用redis sentinel 和 redis cluster ,双机房部署,保证redis服务高可用
2 通过设置不同的过期时间,来错开缓存过期,从而避免缓存集中失效
五 Redis倾斜以及解决
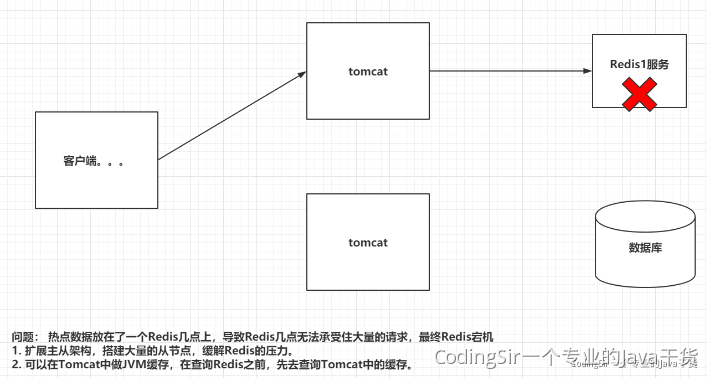
现象:
hot key ,即热点key,指在一段时间内,该key的访问量远远高于其他的redis key,导致大部分的访问流量经过proxy分片之后,都集中到某个redis实例上。hot key通常在不同业务中,存储着不同的热点信息。
比如:
- 新闻应用中的热点新闻内容;
- 系统活动中某个用户疯狂参与的活动的活动配置;
- 商城秒杀系统中,性价比最高的商品信息;
big key: 即数据量大的key,由于数据量大小远远大于其他key,导致经过分片以后,某个具体存储在这个big key的实例内存使用量远大于其他实例,造成内存不足,拖累整个集群的使用。big key 在不同业务上,通常体现为不同的数据。
比如:
- 论坛中的大型持久盖楼活动;
- 聊天室系统中热门聊天室的消息列表;
解决方案:
1 使用本地缓存
在client端使用本地缓存,从而降低redis集群对热点key的访问量,但是同时带来了两个问题:1 如果对可能成为hot key的key都进行本地缓存,那么本地缓存是否会过大,从而影响应用程序本身所需的缓存开销;2 如何保证保证本地缓存的redis集群数据的有效期的一致性
2 利用分片算法的特性,对key进行打散处理
热点key之所以是热点key,是因为只有一个key,落地到一个实例上,我们可用给热点key加上前缀或者后缀,把一个hotkey的数量变成redis实例个数的n的倍数m,从而由访问一个redis key变成nm个redis key
nm个redis key经过分片到不同的实例上,将访问量均摊到所有实例
3 对big key 进行拆分
对big key存储的数据进行拆分,变为value1,value2,…valueN
如果big key 是一个大的json,通过mset的方式,将key的内容打散到各个实例中,减小big key对数据倾斜造成的影响
如果 big value是一个大list,可以将list拆成=list1,list2…listN
其他数据的类型同理
4 既是big key 也是hot key
在开发过程中,有些key不只是访问量大,数据量也很大,这个时候就要考虑这个key使用的场景,存储在redis集群中是否是合理的,是否是使用其他组件来存储更合适;如果坚持用redis来存储,可能考虑迁移出集群,采用一主一备(或一主多备)的架构来存储
六 持久化以及区别:2种
redis提供了两种方式实现持久化:1RDB,2AOF
同时开启RDB和AOF的注意事项:如果同时开启了AOF和RDB持久化,那么再redis宕机重启之后,需要加载一个持久化文件,优先选择了AOF文件。如果优先开启了RDB,再次开启AOF,如果RDB执行了持久化,那么RDB文件中的内容会被AOF覆盖掉
1 RDB
RDB是redis默认的持久化机制
RDB持久化文件速度比较快,而且存储的是一个二进制的文件,传输起来很方便。
RDB持久化实际:
save 900 1:再900秒内,有一个key改变了,就执行RDB持久化
save 300 1:在300秒内,有10个key改变了,就执行RDB持久化
save 60 10000:在60秒内,有10000个key改变了,就执行RDB持久化
RDB无法保证数据的绝对的安全
2 AOF
AOF持久化机制默认是关闭的,redis官方推荐同时开启RDB和AOF持久化,更安全,比卖你数据丢失
AOF持久化的速度,相对RDB较慢,存储的是一个文本文件,到了后期文件会比较大,传输困难
AOF持久化时机:
appendfsync always:每次执行一个写操作,立即持久化到AOF文件中,性能比较低
appendfsync everysec:每秒执行一次持久化
appendfsync no:会根据你的操作系统不同,环境的不同,在一定时间内执行一次持久化
AOF相对RDB更安全,推荐同时开启AOF和RDB
七 过期策略:2种
key的生存时间到了,redis不会立即删除
redis有定期删除和惰性删除两种策略:
-定期删除:redis每隔一段时间就回去查看redis设置了过期时间的key,会在100ms的时间默认查看3个key
-惰性删除:如果当你区查询一个已经过了生存时间的key时,redis会先查看当前key的生存时间是否已经到了,直接删除当前的key,并且给用户返回一个空值
注意:如果一个key的有限期过了,但是一直不访问也没有被定期删除,这个时候会引起内存不足,这个时候就需要淘汰机制
八 淘汰机制
在redist内存已经存满的时候,添加一个新的数据,执行淘汰机制
volatile-lur:在内存不住时,redis会在设置过了生存时间的key中干掉一个最近最少使用的key
allkeys-lur:在内存不足时,redis会在全部的key中干掉一个最近最少使用的key
volatile-lfu:在内存不足时,redis会在设置过了生存时间的key中干掉一个最近最少频次使用的key
allkeys-lfu:在内存不足时,redis会在全部的key中干掉一个最近最少频次使用的key
volatile-random:在内存不足时,redis会在设置的过了生存时间的key中随机干掉一个
allkeys-random:在内存不足时,redis会在全部的key中随机干掉一个
volalite-ttl:在内存不足时,redis会在设置过了生存时间的key中干掉一个剩余生存时间最少的key
noeviction:(默认)在内存不足时,直接报错
指点淘汰机制的方式:maxmemory-policy具体策略,设置redis的最大内存
maxmemory字节大小
九 Redis集群方案:3种
redis有三种集群方式:主从复制,哨兵模式,集群
1 主从复制:单机版redis存在读写瓶颈的问题:
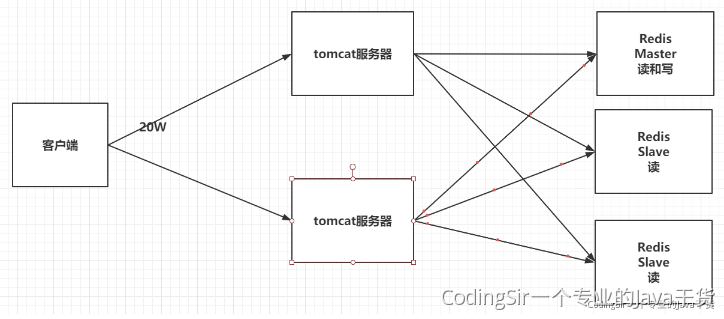
2 哨兵机制
哨兵可以帮助我们解决主从架构中的单点故障问题
3 集群多主多从
rdis-cluster
redis集群在保证主从+哨兵的基本功能之外,还能够提升redis存储数据的能力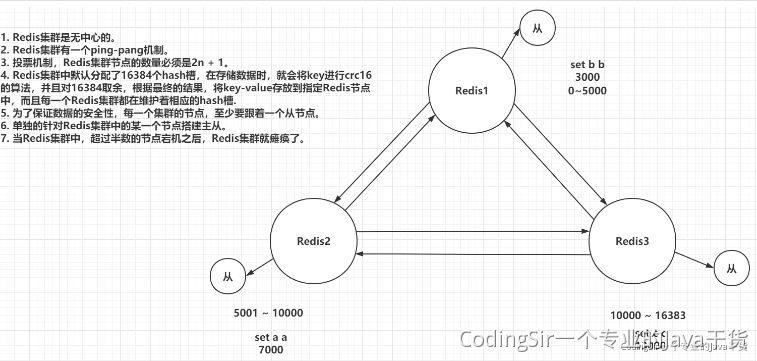
十 Redis为什么快
1 redis是纯内存数据库
一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在io上,所以读取速度非常快
2 redis使用的是非阻塞IO
IO对路复用,使用了单线程来轮询描述符,将数据库的开,关,读,写都转换成了事件,减少了线程切换时上下文的切换和竞争
3 redis内部使用文件事件处理器file event handler
这个文件事件处理器是单线程的,所以redis才叫做单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争
在redis4.0之前,redis是单线程运行的,但单线程并不代表效率低,像Nginx,Nodejs也是单线程程序,但是它们的效率并不低,但Redis在4.0以及之后的版本中引入了惰性删除(也叫异步删除),就是我们可以使用异步的方式对Redis中的数据进行删除操作,这样处理的好处是不会使Redis的主线程卡顿,会把这些操作交给后台线程来执行
4 redis全程使用hash结构,读取速度快
还有一些特殊的数据结构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。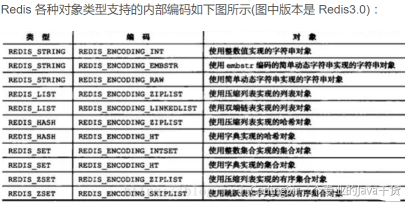
5 redis采用自己实现的事件分离器
效率比较高,内部采用阻塞的执行方式,吞吐能力比较大
十一 Redis和MongoDB的区别
MongDB更类似MySQL,支持字段所以i你,游标操作,其优势在于查询功能比较强大,擅长查询JSON数据,能存储海量数据,但是不支持事务。
redis是一个开源的,内存中的数据结构存储系统,支持多种类型的数据结构,可用作数据库,高速缓存和消息队列代理
区别
| MongDB | Redis | ||
|---|---|---|---|
| 内存管理机制 | 数据存在内存,由Linux系统mmap实现,当内存不够时,只将热点数据放入内存,其他数据存在磁盘 | 全部存在内存,定期写入磁盘,内存不够时,可以选择指定的LRU算法删除数据 | |
| 支持的数据结构 | 数据结构比较单一,但是支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富 | 支持的数据结构丰富,包括hash,set,list等 | |
| 性能 | 依赖内存,TPS较高 | redis依赖内存,TPS非常高。性能优于MongDB | redis性能优于MongDB |
| 可靠性 | mongdb从1.8以后,采用biglog方式(MySQL也采用该方式)支持持久化,增加可靠性 | redis依赖快照进行持久化;AOF增强可靠性;增强可靠性的同时,影响访问性能, | mongdb可靠性优于redis |
| 数据分析 | 内置数据分析功能(mapreduce) | 不支持 | |
| 事务支持情况 | 不支持 | 支持比较弱,只要保证事务中的每个操作连续执行 | |
| 集群 | 集群技术比较成熟 | 从3.0开始支持集群 | |
| 数据量和性能高 (内存不足) |
只要业务上能保证,冷热数据的读写比,使得热数据在物理内存中,mmap的交换较少,mongdb可以保证性能 | 用虚拟内存,需要加内存条或者换个数据库 | 当物理内存够用的时候:redis>mongdb>mysql; 当物理内存不够用的时候:redis和mongdb都会使用虚拟内存 |
十二 RedLock(红锁)分布式实现原理
RedLock是基于redis实现的分布式锁,能够保证一下特性:
互斥性:在任何时候,只能有一个客户端能够持有锁,避免死锁
当客户端拿到锁以后,即使发生了网络分区或者客户端宕机,也不会发生死锁;(利用key的存活时间)
容错性:只要多数节点的redis实例正常运行,就能够对外提供服务,加锁或者释放锁;
RedLock算法思想:是不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁,n/2+1,必须在大多数redis节点上都成功创建锁,才能算这个整体的RedLock加锁成功,避免说仅仅在一个redis实例上加锁而带来问题
十三 Redis的String类型的底层
Redis使用自己的简单动态字符串(simple dynamic string, SDS)的抽象类型。Redis中,默认以SDS作为自己的字符串表示。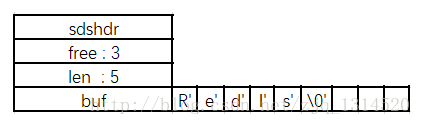
len保存了SDS保存字符串的长度;
buf[]数组用来保存字符串的每个元素;
free记录了buf数组中未使用的字节数量;
redis在内部存储string不都是用sds的数据结构实线的,在整个的redis的数据库存储过程中为了提高性能,内部做了很多优化。整体选择顺序应该是:
- int:存储字符串长度小于21且能够转化为整数的字符串;
- EmbeddedString:存储字符串长度小于44的字符串(REDIS_ENCODING_EMBSTR_SIZE_LIMIT);
- SDS 剩余的情况用SDS进行存储
embstr和sds的区别在于内存二点申请和回收
- embstr的创建只需分配一次内存,而raw为两次(一次为SDS分配对象,另一次为redisObject分配对象,embstr省去了第一次)。相对地,释放内存的次数也由两次变为1次
- embstr的redisObject和SDS放在一起,更好的利用缓存带来的优势
- 缺点:redis并未提供任何修改embstr的方式,即embstr是只读的形式。对embstr的修改实际上是先转换未raw再进行修改
十四 Redis的SkipList
当有序结合不满足使用压缩列表的条件时,就会使用 skipList 结构来存储数据。
跳跃列表(skipList)又称“跳表”是一种基于链表实现的随机化数据结构,其插入、删除、查找的时间复杂度均为 O(logN)。从名字可以看出“跳跃列表”,并不同于一般的普通链表,它的结构较为复杂,本节只对它做浅显的介绍,如有兴趣可自行研究。
在 Redis 中一个 skipList 节点最高可以达到 64 层,一个“跳表”中最多可以存储 2^64 个元素,每个节点都是一个 skiplistNode(跳表节点)。skipList 的结构体定义如下:
typedf struct zskiplist{//头节点struct zskiplistNode *header;//尾节点struct zskiplistNode *tail;// 跳表中的元素个数unsigned long length;//表内节点的最大层数int level;}zskiplist;
- header:指向 skiplist 的头节点指针,通过它可以直接找到跳表的头节点,时间复杂度为 O(1);
- tail:指向 skiplist 的尾节点指针,通过它可以直接找到跳表的尾节点,时间复杂度为 O(1);
- length:记录 skiplist 的长度,也就跳表中有多少个元素,但不包括头节点;
- level:记录当前跳表内所有节点中的最大层数(level);
跳跃列表的每一层都是一个有序的链表,链表中每个节点都包含两个指针,一个指向同一层的下了一个节点,另一个指向下一层的同一个节点。最低层的链表将包含 zset 中的所有元素。如果说一个元素出现在了某一层,那么低于该层的所有层都将包含这个元素,也就说高层是底层的子集。
通过以下示意图进一步认识 skiplist 结构。下图是一个上下共四层的跳跃列表结构: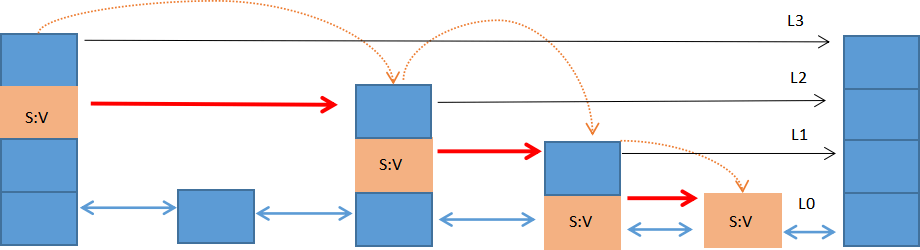
跳跃列表中的每个节点都存储着 S:V(即 score/value),示意图显示了使用跳跃列表查找 S:V 节点的过程。跳跃列表的层数由高到低依次排列,最低层是 L0 层,最高层是 L3 层,共有 4 层。
图 1 所示,首先从最高层开始遍历找到第一个S:V节点,然后从此节点开始,逐层下降,通过遍历的方式找出每一层的 S:V 节点,直至降至最底层(L0)才停止。在这个过程中找到所有 S:V 节点被称为期望的节点。跳跃列表把上述搜索一系列期望节点的过程称为“搜索路径”,这个“搜索路径”由搜索到的每一层的期望节点组成,其本质是一个列表。
十五 Redis的事务
关系型数据库的事务主要有:事务的特性,事务隔离级别两个问题。
事务特性(ACID)
- 原子性(Atomicity)
指事务内所有操作要么一起执行成功,要么都一起失败(或者说是回滚);如事务经典转账案例:A给B转账,A把钱扣了,但B没有收到;可见这种错误是不能接受的,最终会回滚,这也是原子性的重要性。 - 一致性(Consistency)
指事务执行前后的状态一致,如事务经典转账案例:A给B互相转账,不管怎么转,最终两者钱的总和还是不变; - 持久性(Durability)
指事务一旦提交,数据就已经永久保存了,不能再回滚; 隔离性(Isolation)
指多个并发事务之间的操作互不干扰,但是事务的并发可能会导致数据脏读、不可重复读、幻读问题,根据业务情况,采用事务隔离级别进行对应数据读问题处理。事务隔离级别
读未提交(Read uncommitted)
指一个事务读取到其他未提交事务的数据。可能导致数据脏读。
转账案例:A正在给B转账,本来转的1000,A多输入了个0,变成10000,但此事务还未提交,但此时B查询到转入的是10000,但A取消事务回滚之后,B又查询不到转入的数据。这种情况就是脏读- 读已提交(Read committed)
指一个事务只能读取到其他事务已提交的数据,从而解决了脏读的问题。但可能导致数据不可重复读;
转账案例:A要给B转账1000,A先查看了一下余额,有1000,然后开始给B转钱,但此时A家里电费通过开启的自动缴费功能,自动从A账户扣除200缴纳电费,并提交;当A转账准备提交,再次确认余额时,钱少了200。这样就导致同一个事务中多次查询的结果不一致,这种情况就是不可重复读; - 可重复读(Repeatable read)
指事务只要一开启,就不允许其他事务进行修改操作,从而解决了不可重复读问题。但可能导致数据幻读;
转账案例:A经常给B转账,到年底了,需要查账,然后开启了一个事务进行查询统计,刚开始查询只是10条转账记录,正准备统计时,因为紧急情况A需要给B转一笔钱应急,从而新增了一条新记录,并提交;而查账事务正在统计中,最后发现转账额和看到的10条转账记录不匹配。这种情况就是幻读 - 序列化(Serializable )
指事务之间只能串行话执行,就像队列一样,排队进行,这样就解决了幻读的问题,但是这种级别的并发性能不高,非特殊需求,这种级别一般不用。
结合关系型数据库的事务来看非关系型数据库redis中事务的不同:
redis事务是指将多条命令加入队列,一次批量执行多条命令,每条命令会按照顺序执行,事务执行过程中不会受客户端传入的命令请求影响。
redis事务相关的命令:
multi:标识一个事务的开启,即开启事务;
exec:执行事务中所有的命令,即提交;
discard:放弃事务,和回滚不一样,redis事务不支持回滚;
watch:监视key改变,用于实现乐观锁。如果监视的key值改变,事务最终会执行失败;
unwatch:放弃监视;
redis事务和关系型数据库的事务不太一样,它不保证原子性,也没有隔离级别的概念。
下面结合命令演示,
1 初始化A账户的100块,命令执行成功
星星:2>flushdb #清空数据库"OK"星星:2>set a 1000 #A账户有1000块"OK" #命令执行成功星星:2>set b 100 #B账户有100块"OK"
2 开启事务
星星:2>multi #开启事务"OK"
3事务中的命令只入队,没有实际执行
星星:2>get a #检查A账户的钱,但是命令没有执行,只是将命令加入队列"QUEUED"#加入队列成功星星:2>decrby a 800#A账户转出800"QUEUED"星星:2>incrby b 800#B账户转入800"QUEUED"星星:2>mget a b#获取A和B账户"QUEUED"
4 最后通过exec指令,事务中的命令才一一执行
星星:2>exec#执行事务,此时命令按顺序执行1) "OK"2) "1000"3) "OK"4) "200"5) "OK"6) "900"7) "OK"8) 1) "200"2) "900"9) "OK"星星:2>
如图所示,当事务开启时,事务期间的命令并没有执行,而是加入队列,只有执行exec命令时,事务中的命令才会按照顺序一一执行,从而事务间就不会导致数据脏读,不可重复读,幻读的问题,因此就没有隔离级别。
不保证原子性
如图,在通过exec执行事务时,其中命令执行失败不会影响到其他命令的执行,并没有保证同时成功和同时失败的原子操作,尽管这样,redis事务中也没有提供回滚的支持,官方提供了两个理由:
大意是:
1使用reids命令语法错误,或是将命令运用在错误的数据类型键上(如对字符串进行加减乘除等),从而导致业务数据有问题,这种情况认为是编程导致的错误,应该在开发过程中解决,避免在生成环境中发生;
2由于不用支持回滚功能,redis内部简单化,而且还比较快
在事务命令入队过程中,发现相关命令逻辑使用错误,可以进行放弃该事务;如果使用错误的redis命令,且没有放弃事务,最终也会导致事务整体执行失败,这也算是为原子性扳回一局,如下:
放弃事务
命令语法错误导致事务执行失败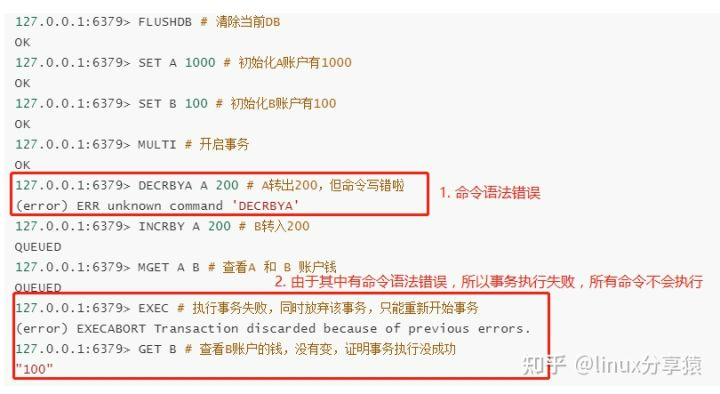
使用watch实现乐观锁
乐观锁:就是非常乐观,什么事情都往好的方向想,对于数据库操作,就认为每次操作数据的时候都认为别的草案所不会修改,所以不会加锁,而是通过类似于版本的字段来标识该数据是否修改过,在执行本次操作前先判断是否修改过,如果修改过就放弃本次操作重新再来;
悲观锁:就是非常的悲观,做什么事都觉得做不好,对于数据库操作,每次操作数据数据都会认为别的操作会修改当前数据,所以都要对其加锁,类似于表锁和行锁。
watch通过监视指定redis key ,如果没有改变,就执行成功,如果发现对应值变化,事务就会执行失败,如下图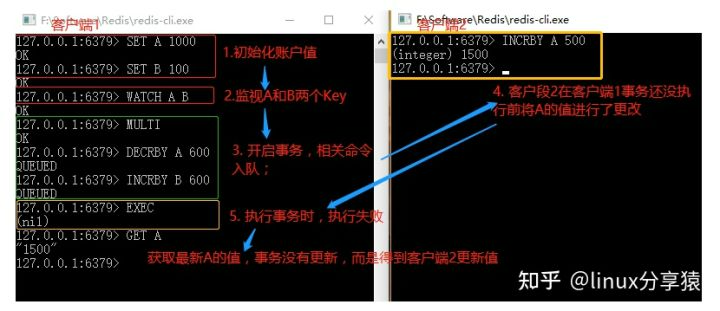
那会一直监视指定的key嘛?,答案当然是不会,以下三种方式可以取消监视;
- 事务执行之后,不管是否执行成功还是失败,都会取消对应的监视;
- 当监视的客户端断开连接时,也会取消监视;
-
redis事务的优缺点
优点:
一次性按顺序执行多个redis命令,不受其他客户端命令请求影响;
- 事务中的命令要么都执行(命令间执行失败互不影响),要么都不执行(比如中间有语法错误);
缺点:
- 事务执行时,不能保证原子性;
- 命令入队每次都需要和服务器进行交互,增加宽带;
注意:
- 当事务中命令语法使用错误时,最终会导致事务执行不成功,即事务内所有命令都不执行;
- 当事务中命令知识逻辑错误,就比如给字符串做加减乘除操作时,只能在执行过程中发现错误,这种事务执行中失败的命令不影响其他命令的执行;
十六 Redis的Ziplist
ziplist是压缩列表,压缩列表由五部分组成,如图:
上述每一部分在内存中都是紧密相邻的,并承担着不同的作用,
- zlbytes是一个无符号整数,表示当前 ziplist 占用的总字节数;
- zltail 指的是压缩列表尾部元素相对于压缩列表起始元素的偏移量。
- zllen 指 ziplist 中 entry 的数量。当 zllen 比2^16 - 2大时,需要完全遍历 entry 列表来获取 entry 的总数目。
- entry 用来存放具体的数据项(score和member),长度不定,可以是字节数组或整数,entry 会根据成员的数量自动扩容。
- zlend 是一个单字节的特殊值,等于 255,起到标识 ziplist 内存结束点的作用。
下面执行ZADD命令添加两个成员:xh(小红) 的工资是 3500.0;xm(小明) 的工资是 3200.0。
ZADD salary 3500.0 xh 3200.0 xm
上述成员在压缩列表中的布局,如下所示: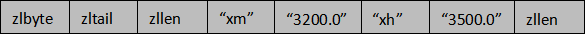
当 zset 使用压缩列表保存数据时,entry 的第一个节点保存 member,第二个节点保存 score。依次类推,集合中的所有成员最终会按照 score 从小到大排列。
redis如何发现hot和big key
1 事前-预判:在业务开发阶段,对可能变为热点 key,big key的数据进行判断,这需要你对业务的理解,对运营节奏的把握,对数据设计的经验
2 事中-监控和进行自处理
监控:
在应用程序端,对每次请求redis的操作进行收集上报,不推荐,但是在运维资源缺少的场景下可以考虑。开发可以绕过运营搞定;
在proxy层,对每个redis请求进行收集上报(推荐,改动涉及少且好维护);
对redis实例使用monitor命令统计热点key(不推荐,在高并发条件下会造成redis内存爆掉的隐患);
机器层面:redis客户端使用TCP协议与服务器进行交互,通信采用的是RESP。如果站在机器的角度,可以通过对机器上所有的redis端口的TCP数据包进行抓取完成热点key的统计,(不推荐,公司每台机器上的基本组件已经很多了,别再添乱了);
自动处理:
通过监控之后,程序获取big key,hot key,在报警的同时,程序对big key ,hot key进行自动处理。或者通知程序员利用一定的工具进行定制化处理(在程序中对特定key执行起前面提到的解决方案)
redis如何实现高并发:
redis通过一主多从,主节点负责写,从节点负责读,读写分离,从而实现高并发
redis如何实现高可用:
主备切换,哨兵集群,主节点宕机的情况下,主动选举一个从节点变成主节点,从而保证了redis集群的高可用
redis单线程还能处理速度那么快:
首先reids是单进程单线程的K-V内存行可持久化数据库
单线程还能处理速度很快的原因:
1 redis操作时基于内存的,内存的读写速度非常的快;
2 正是由于redis的单线程模式,避免了上下文切换的损耗
3 redis采用IO多路复用技术,可以很好的解决多请求并发的问题。多路代表多请求,复用代表多个请求重复使用同一个线程。
reids的好处
1速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是0(1)
2 支持丰富的数据类型,支持string,set,list,sorted set,hash
3 支持事务,操作都是原子性的,所谓原子性就是对数据的更改要么是全部执行,要么全部不执行
4丰富的特性:可用于缓存,消息,按key设置过期时间,过期后会自动删除
什么是redis的持久化?RDB和AOF的比较?
持久化就是把内存的数据写道磁盘中去,防止服务器宕机后内存数据丢失
比较:
1AOF文件比RDB更新频率高,优先使用AOF还原数据
2 AOF比RDB跟安全也更大
3 RDB性能比AOF好
4 如果两个都赔了优先加载AOF
redis使用场景
1 会话缓存/session cache
最常用二点一种使用redis的场景是会话缓存。用redis缓存会话比其他存储(如Memcached)的优势在于:redis提供持久化
2 全页缓存/FPC
除了基本的会话token之外,redis还提供简便的FPC平台,回到一致性问题,即使重启了redis的实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。
以Magento为例,Magento提供一个插件使用redis作为劝业缓存后端。
此外,对wordpress的用户来水,Pantheon有一个非常好的插件wp-redis,这个插件能帮助你以最快熟读加载你层浏览过的页面
3 队列
redis在内存存储引擎领域的一大有点事提供list和set操作,这使得redis能作为一个很好的消息队列平台来使用,redis作为队列使用的操作,就类似于本地程序语言(如python)对list的push/pop操作
4 排行榜/计数器
redis在内训中对数字进行递增或者递减的操作实现的非常好,集合set和有序集合zset也使得我们在执行这些擦欧总的时候变得非常简单,redis只是正好提供了这两种数据结构。如从排序集合中获取到排名前十的用户
5 发布/订阅
发布/订阅的使用场景非常多。在社交网络连接中使用,还可以作为基于发布/订阅的脚本触发器,甚至用redis的发布/订阅功能来建立聊天系统
数据库分类:
old-dql:传统的关系型数据库,代表有mysql,oracle,sql server ,post cure sql
核心关系:一对一,一对多,多对一,多对多
E-R图:实体关系映射图
NO-SQL:not only sql,泛指非关系型数据库
典型代表:redis,mongdb,neo4j,hbase
new-sql:各大云平台自主研发的新型数据库
典型代表:阿里云的 polarDB
国产的达梦
核心:应对高并发,海量数据
| 数据库 | 存储类型 |
|---|---|
| redis | k-v |
| Hbase | 列存储 |
| MongDB | 文档存储 |
| Neo4j | 图存储-社交类 |
分布式缓存:
硬盘上的数据,缓存在别的计算机上(非程序运行的计算机)内存上,而且可以缓存的计算机的个数不止一个,可以使用n个用户访问http服务器,然后访问应用服务器资源,应用服务器调用后端的数据库,在第一次访问的时候,直接访问数据库,然后将要缓存的内容放到memcached集群,集群规模根据缓存文件的大小而定。在第二次访问的时候就直接进入缓存读取,不需要进行数据库的操作。这个适合数据变化不频繁的场景,比如:互联网显示的榜单,阅读排行等
redis常见的性能问题和解决方案
1 master最好不要做任何持久化工作,如RDB内存快照,AOF日志文件
2 如果数据比较重要,某个salve开启AOF备份数据,策略设置为每秒同步一次
3 为了主从复制的速度和连接的稳定性,master和slave最好在同一个局域网内
4尽量避免在压力很大的主库上增加从库
5 主从复制不要用图状结构,用单向链表结构更为稳定,即Lmaster<slave1<slave2<slave3…
redis中的雪崩,击穿,穿透,倾斜都是因为并发量过大引起的,最起码是万级的请求

若有收获,就点个赞吧
0 人点赞
