一 SQL语句的分类:6类
数据库:存储数据的仓库,软件专门用来存储数据;
OLD-SQL—-关系型数据库;
NO-SQL—-非关系型数据库;
NEW-SQL—-云数据库;
SQL:结构化查询语言;
SQL的分类:
1,DDL—数据库定义语言;
关键字:create,drop,alter
2,DML:数据库操作语言
关键字:insert,update,delete
3,DQL:数据库查询语言;
select
4,DCL:数据控制语言
关键字:grant,revoke
5 TPL:数据事务语言;
关键字:begin,transaction,commit,rollback
6 CCL:指针控制语言
关键字:cursor 游标
二 Mysql的存储引擎:InnoDB和Myisma
三 事务的理解
事务:保证多个sql语句DML执行具有一致性,要么都成功,要么都失败;
事务具有A(atomicity)原子性:—事务是最小的执行单位,事务执行过程中任何失败都将导致事务所作的所有修改失效;
C(consistency)一致性:同生共死,当事务执行失败时,所有被该事务影响的数据搜应该恢复代事务执行前的状态;
I(isolation)隔离性:表示在事务执行的过程中对数据的修改,在事务提交之前对其他事务不可见,保证数据库安全,对应隔离级别—防止:涨读,幻读,不可重复读;
D(durability)持久性 :表示已提交的数据在事务执行失败时,数据的状态都应该正确;永久的存储
开启事务start
提交事务:commit
回滚事务:rollback
如果一个方法中涉及到了多个SQL语句,必须添加事务;
事务的处理放在业务逻辑层;
四 胀读、幻读、不可重复读
脏读(dirty read):一个事务读取了另一个事务尚未提交的数据;
不可重复读(non-repeatable read):一个事务的操作导致另一个事务前后两次读取到不同的数据;——修改
幻读(phantom read):一个事务的操作导致另一个事务前后两次查询的结果数据量不同—-增删
五 事务的隔离级别
isolation:设置隔离级别
default:这是一个plat from transactionmanger默认的隔离级别,使用数据库默认的事务隔离级别。
读未提交:脏读,不可重复读,幻读(虚读)都有可能被发生;
读已提交:避免脏读,但是不可重复度和幻读都有可能发生;
可重复读:避免脏读和不可重复读,但是幻读有可能发生
串行化:避免以上所有的问题;
MySQL数据库默认事务隔离级别:可重复度;
Oracle默认事务隔离级别:读已提交
| 隔离级别 | 脏读 | 不可重复度 | 幻读 |
|---|---|---|---|
| 读未提交/read uncommitted | √ | √ | √ |
| 读已提交/read commintted | × | √ | √ |
| 可重复读/repeatable read | × | × | √ |
| 可串行化/serializable | × | × | × |
六 隔离级别是如何解决不可重复读?
七 索引的分类
八 B+Tree
九 最佳左匹配
十 聚簇索引、覆盖索引
十一 SQL优化
十二 索引的生效和失效情况
十三 常用函数
十四 sql语句执行顺序
十五 设计范式:3大范式和6大范式
三大范式:
第一范式:数据表的每一列都要保持它的原子特性,也就是列不能再被分割。
这张表就不符合第一范式规定的原子性,不符合关系型数据库的基本要求,在关系型数据库中创建这个表的操作就不能成功。不得不将数据表设计为如下形式。
第二范式:属性必须完全依赖于主键。
下面这张表不满足第二范式的要求:
缺点:
- 表中的第一行数据都存储了系名,系主任,数据冗余太大;
- 如果有一个新的系还没有开始找到学生,那么不能讲该系的信息添加到数据表中去,从数据表中看不到该系的存在
- 如果将某个系的学生信息全部删除,那么这个系在数据表里也就不存在了,但这个系还存在。
- 如果某个人要转系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据
依赖:
在数据表中,属性(属性组)X确定的情况下,能完全退出来属性Y完全依赖于X
完全依赖:
在数据表中,属性(属性组)X确定的情况下,能完全退出来属性Y完全依赖于X。
部分依赖:
一组属性X中的其中一个或几个属性能推出Y就说Y部分依赖于X。
候选码:
当一个属性或者属性组确定的情况下,这张表的其余所有属性就能确定下来,这个属性或者属性组就叫做或候选码。
一张表可以有多个候选码
一般只选一个候选码作为主键
从表中找到两个属性:学号和课程
学号可以推出姓名、系名、系主任。
课程可以推出成绩。
将它们两个设置为联合主键
存在的部分依赖:
- 姓名对学号存在部分依赖
- 系名对学号存在部分依赖
- 系主任对学号存在部分依赖
这显然不符合第二范式的要求,做出修改:
- 表一中分数完全依赖于学号和课程的属性
表二中姓名、系名、系主任完全依赖于学号的属性
第二范式消除了第一范式的部分依赖第三范式:
概念:所有的非主属性不依赖于其他的非主属性
传递函数依赖
设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。
在改进后的学生表中:
主属性:学号
非主属性:姓名、系名、系主任
知道系名可以推出系主任,所以非主属性系主任对主属性学号存在传递函数依赖,这不符合非主属性不依赖于其它的非主属性的设计要求。将该数据表改进如下:
第三范式消除了第二范式的传递函数依赖
BC 范式
主属性不能对候选码存在部分函数依赖或者传递函数依赖
这张表不存在部分函数依赖于传递函数依赖,属于第三范式
表中的依赖关系
- 仓库名—————>管理员
- 管理员—————>仓库名
- 物品名—————>数量
主属性:仓库名、管理员、物品名
非主属性:数量
存在的问题
- 先新添加一个仓库,但尚未存放任何物品,不可以为该仓库指派管理员,因为物品名也是主属性,根据实体完整性的要求,主属性不能为空
- 某仓库被清空后,该仓库的信息也被清空
- 当需要更新仓库管理员,该仓库存放了多少物品,就要修改多少条信息。
在这个问题中就是存在了主属性对于候选码的部分依赖,也就是仓库名对于管理员和物品名的部分依赖。
修改为
仓库(仓库名,管理员)
库存(仓库名、物品数、数量)
范式的目的
- 减小数据的冗余性
- 提高效率
六大范式:
关系数据库中的关系满足一定的要求:满足不同程度要求的为不同的范式。
满足最低要求的叫第一范式,简称1NF;
在第一范式的基础上满足进一步要求的称为第二范式,简称2NF,
其余范式以此类推。对于各种范式之间有如下关系:
- 第一范式 1NF、
定义: 属于第一范式关系的所有属性都不可再分,即数据项不可分。
理解:第一范式强调数据表的原子性,是其他范式的基础。如下图所示数据库就不符合第一范式:
上表将商品这一数据项又划分为名称和数量两个数据项,故不符合第一范式关系。改正之后如下图所示:
这就符合第一范式关系。
但日常生活中仅用第一范式来规范表格是远远不够的,依然会存在数据冗余过大、删除异常、插入异常、修改异常的问题,此时就需要引入规范化概念,将其转化为更标准化的表格,减少数据依赖。
规范化: 一个低一级的关系模式通过模式分解可以转化为若干个高一级范式的关系模式的集合,这个过程叫做规范化。
2. 第二范式 2NF
定义:若某关系R属于第一范式,且每一个非主属性完全函数依赖于任何一个候选码,则关系R属于第二范式。
此处需要理解非主属性、候选码和完全函数依赖的概念。
候选码:若关系中的某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为候选码。若一个关系中有多个候选码,则选定其中一个为主码。—-所有候选码的属性为主属性
如在学生表中,学号和姓名都可以唯一标识一个元组,故该表的候选码为学号和姓名,主码我们可以随便选定其中一个,则选学号为主码。
主属性:所有候选码的属性称为主属性。不包含在任何候选码中的属性称为非主属性或非码属性。
在上面的学生表中,学号和姓名就是该关系的主属性,年龄和性别就是非主属性。
【函数依赖: 设R(U)是属性集U上的关系模式,X、Y是U的子集。若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称Y函数依赖于X或X函数确定Y。
完全函数依赖: 设R(U)是属性集U上的关系模式,X、Y是U的子集。如果Y函数依赖于X,且对于X的任何一个真子集X’,都有Y不函数依赖于X’,则称Y对X完全函数依赖。记作:如果Y函数依赖于X,但Y不完全函数依赖于X,则称Y对X部分函数依赖。】===这个不会
理解: 第二范式是指每个表必须有一个(有且仅有一个)数据项作为关键字或主键(primary key),其他数据项与关键字或者主键一一对应,即其他数据项完全依赖于关键字或主键。由此可知单主属性的关系均属于第二范式。
判断一个关系是否属于第二范式:
- 找出数据表中的所有码;
- 找出所有主属性和非主属性;
- 判断所有的非主属性对码的部分函数依赖。
第二范式:只能有一个主键
3. 第三范式 3NF
定义: 非主属性既不传递依赖于码,也不部分依赖于码。
理解: 第三范式要求在满足第二范式的基础上,任何非主属性不依赖于其他非主属性,即在第二范式的基础上,消除了传递依赖。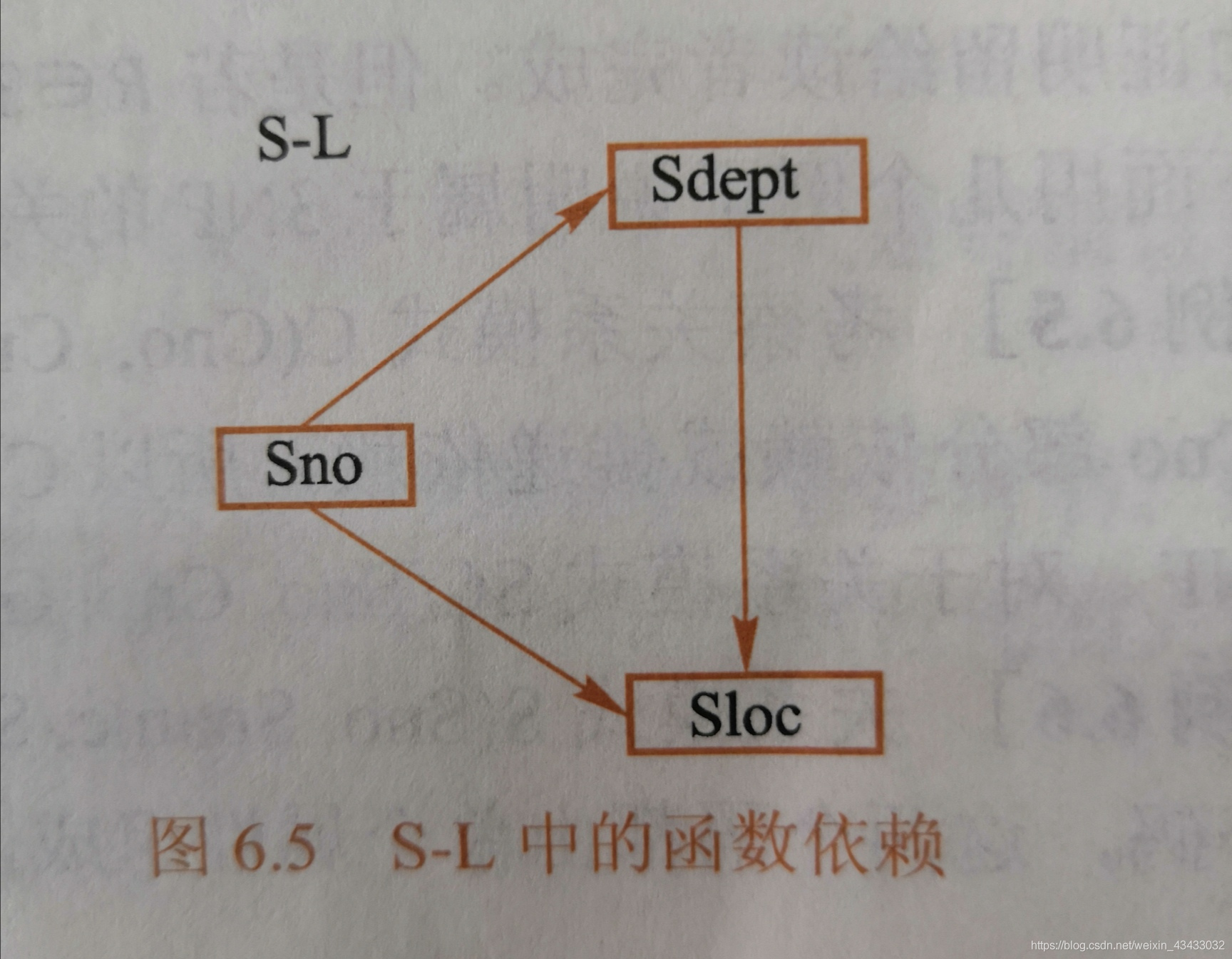
4. BC范式 BCFN
定义: 关系模式R
理解: 根据定义我们可以得到结论,一个满足BC范式的关系模式有:
- 所有非主属性对每一个码都是完全函数依赖;
- 所有主属性对每一个不包含它的码也是完全函数依赖;
- 没有任何属性完全函数依赖于非码的任何一组属性。
5. 第四范式 4NF
定义: 限制关系模式的属性之间不允许有非平凡且非函数依赖的多值依赖
理解: 显然一个关系模式是4NF,则必为BCNF。也就是说,当一个表中的非主属性互相独立时(3NF),这些非主属性不应该有多值,若有多值就违反了4NF。6. 第五范式 5NF
第五范式有以下要求:
(1)必须满足第四范式;
(2)表必须可以分解为较小的表,除非那些表在逻辑上拥有与原始表相同的主键。
第五范式是在第四范式的基础上做的进一步规范化。第四范式处理的是相互独立的多值情况,而第五范式则处理相互依赖的多值情况。十六 数据分片:垂直分片和水平分片
十七 存储过程(Oracle)

若有收获,就点个赞吧
0 人点赞
