自然语言处理流水线的各个阶段可以看作是层,就像前馈神经网络中的层一样。深度学习就是通过在传统的两层机器学习模型架构(特征提取+建模)中添加额外的处理层来创建更复杂的模型和行为。神经网络通过将模型错误从输出层反向传播回输入层,从而帮助完成跨层传播学习的过程。
《自然语言处理实战:利用Python理解分析和生成文本》中文PDF+英文PDF+代码
《自然语言处理实战利用Python理解分析和生成文本》中文PDF,原版带目录,455页;英文PDF,545页;配套源代码。
下载: https://pan.baidu.com/s/1GNEVqkfQ5RkkFay0Ku83ag
提取码: hyhf
在NLP 中,分词(tokenization,也称切词)是一种特殊的文档切分(segmentation)过程。而文档切分能够将文本拆分成更小的文本块或片段,其中含有更集中的信息内容。文档切分可以是将文档分成段落,将段落分成句子,将句子分成短语,或将短语分成词条(通常是词)和标点符号。将文本分割成词条的过程,这个过程称为分词。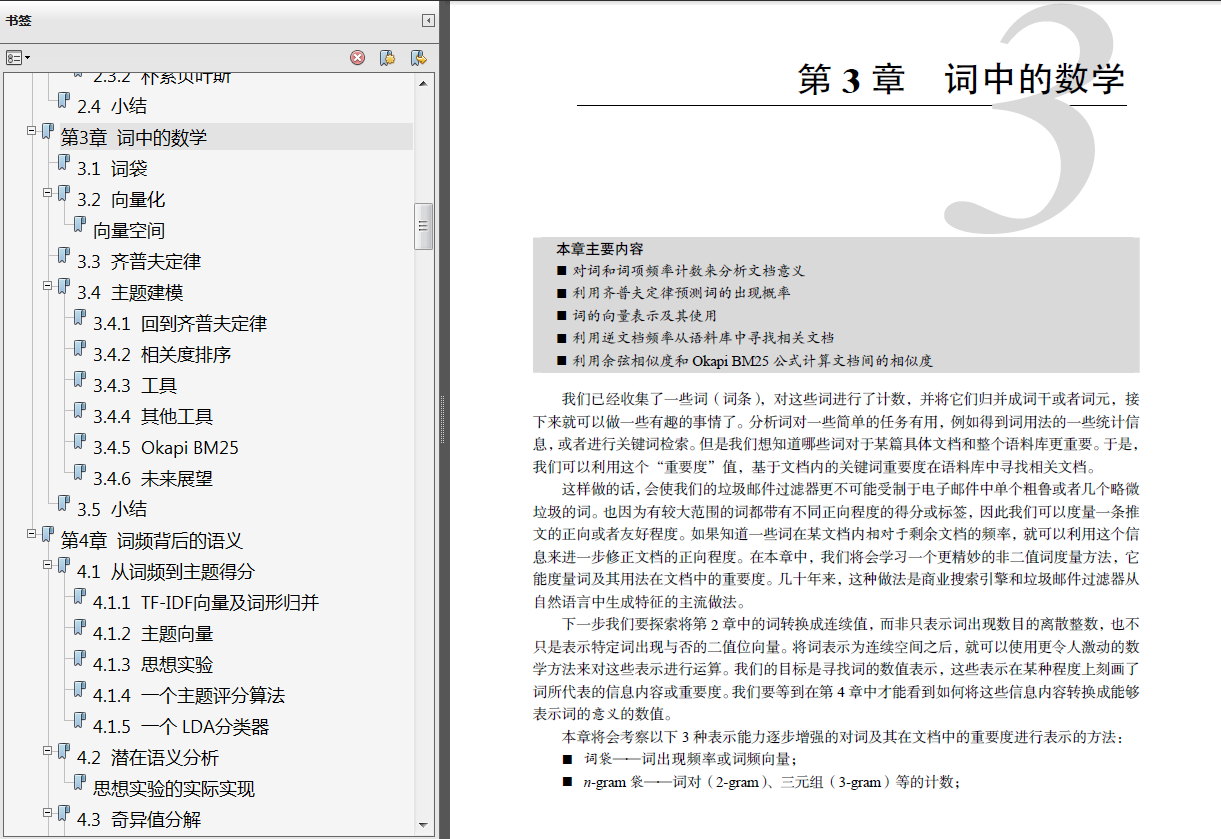
NLP 已成为深度学习的核心应用领域,而深度学习是NLP 研究和应用中的必要工具,分为3 部分:第一部分介绍NLP 基础,包括分词、TF-IDF 向量化以及从词频向量到语义向量的转换;第二部分讲述深度学习,包含神经网络、词向量、卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆(LSTM)网络、序列到序列建模和注意力机制等基本的深度学习模型和方法;第三部分介绍实战方面的内容,包括信息提取、问答系统、人机对话等真实世界系统的模型构建、性能挑战以及应对方法。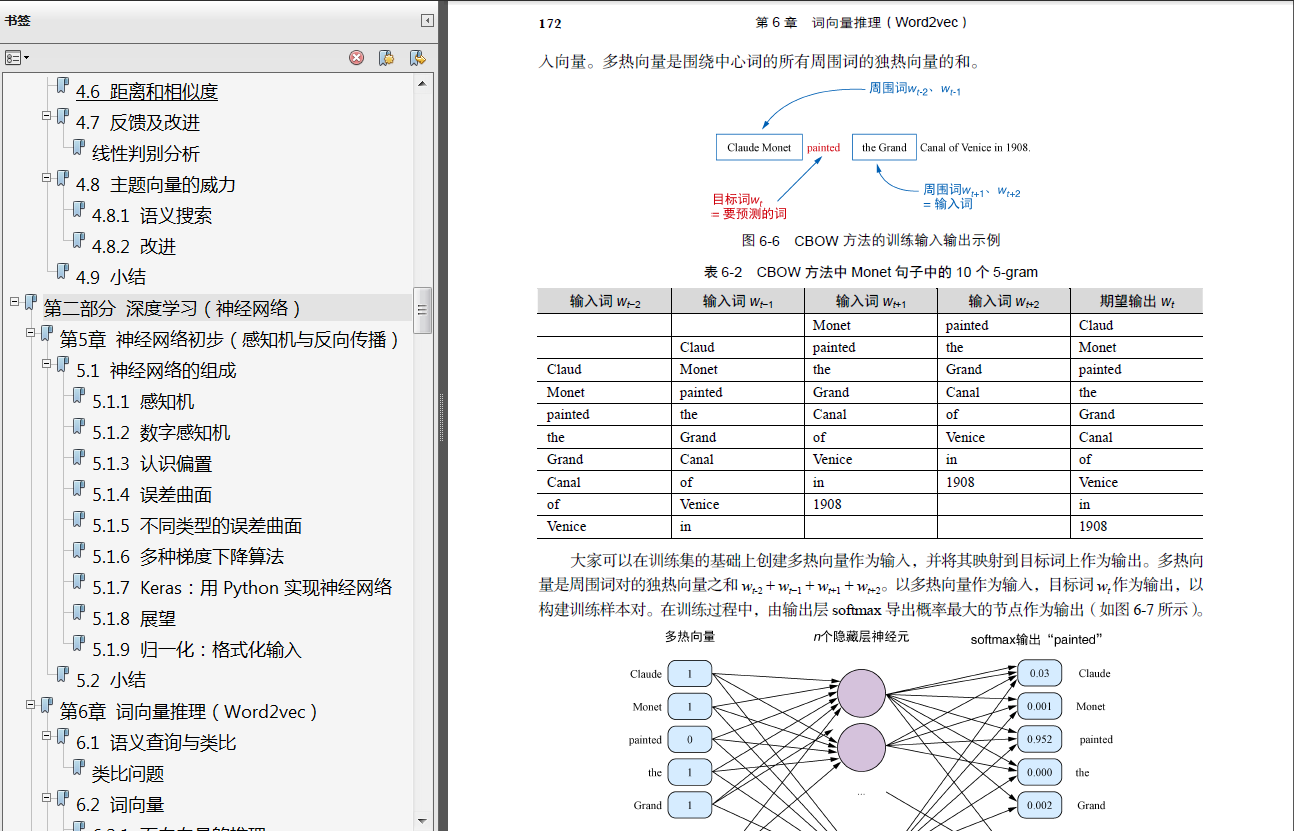
第一部分的各章会讨论使用自然语言的逻辑,并将其转换为可以搜索和计算的数字。这种对词的“拦截和处理”在信息检索和情感分析等应用中会带来很好的效果。一旦掌握了基本知识,大家就会发现有一些非常简单的算法,通过循环反复计算,就可以解决一些重要的问题,如垃圾邮件过滤。大家将在第2 章到第4 章中学到的这种垃圾邮件过滤技术,正在将全球电子邮件系统从混乱和停滞中拯救出来。大家将学习如何使用20 世纪90 年代的技术来构建一个精确率超过90%的垃圾邮件过滤器——只需要通过计算词的数目并对这些数目计算一些简单的平均值即可。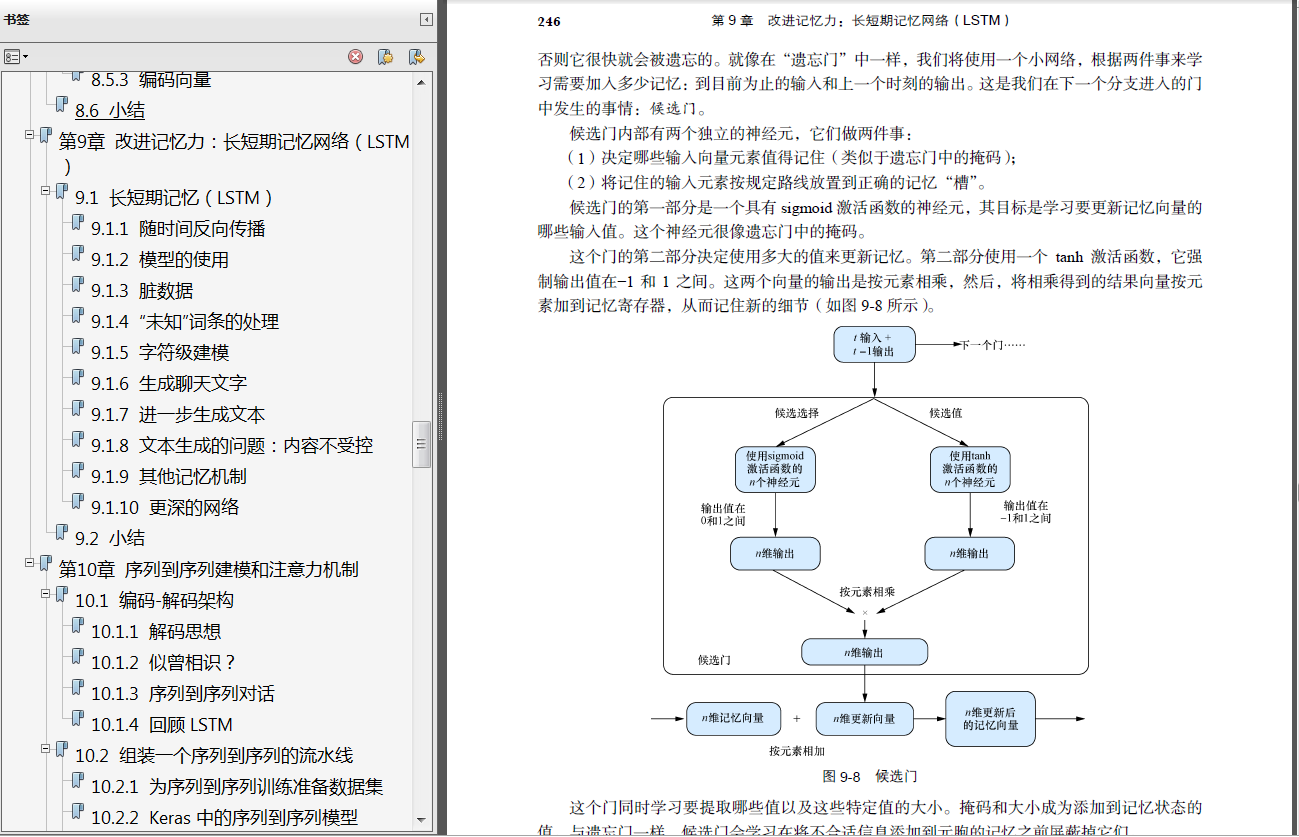
这些文字上的数学运算听起来可能很乏味,但实际上却非常有趣。很快,大家就可以构建出能够对自然语言做出决策的算法,而且可能比你自己做出的更好、更快。这可能是大家人生中第一次以这样的视角来充分欣赏语言反映和赋予你思考的方式。词和思想的高维向量空间视图将让你的大脑进入不断自我发现的循环。
第二部分将是学习的高潮。这部分的核心是探索神经网络中复杂的计算和通信网络。在一个具有“思维”的网络中,小型逻辑单元之间相互作用的网络效应使机器能够解决一些过去只有聪明的人类才能解决的问题,例如类比问题、文本摘要和自然语言翻译。是的,大家还会学到词向量,别担心,不过确实还有很多。大家将掌握对词、文档和句子进行可视化,并将它们置于一个由相互关联的概念组成的云中,这些概念远远超出了大家可以轻松掌握的三维空间。大家会把文档和词想象成“龙与地下城”的角色表,里面有无数随机选择的特征和能力,它们随着时间的推移而进化和成长,当然这些只发生在我们的头脑中。
对词及其含义的理解将是第三部分“进入现实世界”的基础,在这里大家将学习如何构建能够像人类一样交谈和回答问题的机器。
《自然语言处理Python进阶》中文PDF+英文PDF+源代码+陈钰枫
《自然语言处理Python进阶》中文PDF,375页,有目录,文字可复制;英文PDF,301页,有目录,文字可复制;配套源代码。作者: 克里希纳巴夫萨 译者:陈钰枫
下载: https://pan.baidu.com/s/1zV3NZLOJtG_Q-s7in8PthA
提取码: 3krk
自然语言处理任务包括自然语言理解、自然语言处理和句法分析等。学习NLP意味着我们要学会如何理解语言、处理句子及各种歧义现象;学会如何有效地使用NLTK来进行文本分类、分词及词性标注等多个任务;学会如何分析词汇和句子结构,并掌握句法分析、语义分析、语用分析以及深度学习技术的应用。NLTK是处理NLP任务的主要Python平台,自然语言处理应用了计算机程序设计来处理大规模的自然语言数据。
了解NLTK提供的各类可利用的语料资源,以及如何使用WordNet。学习如何处理原始文本,比如HTML、RSS、PDF和Word文档等。如何利用分词、词干提取和拼写检查等方式对原始文本进行预处理,并学会利用正则表达式实现。了解正则表达式在文本分析中的基本匹配模式。学会使用和编写词性标注器与文法。学会如何实现命名实体抽取和句法分析,比如递归下降句法分析器、shift-reduce分析器和线图分析器等。使用LSTM技术基于莎士比亚著作生成文本。使用BABI数据集和LSTM技术对情景记忆建模。使用深度学习开发生成式聊天机器人。
从一个实用的角度从头开始理解和实现NLP解决方案,将从访问内置数据源和创建自己的数据源,可以编写复杂的NLP解决方案,包括文本规范化、预处理、词性标注、句法解析等。

若有收获,就点个赞吧
0 人点赞
