第一部分的各章会讨论使用自然语言的逻辑,并将其转换为可以搜索和计算的数字。这种对词的“拦截和处理”在信息检索和情感分析等应用中会带来很好的效果。一旦掌握了基本知识,大家就会发现有一些非常简单的算法,通过循环反复计算,就可以解决一些重要的问题,如垃圾邮件过滤。
LSTM《自然语言处理实战:利用Python理解、分析和生成文本》PDF+代码
《自然语言处理实战:利用Python理解分析和生成文本》中文PDF+英文PDF+代码
《自然语言处理实战利用Python理解分析和生成文本》中文PDF,原版带目录,455页;英文PDF,545页;配套源代码。
下载: https://pan.baidu.com/s/1GNEVqkfQ5RkkFay0Ku83ag
提取码: hyhf
大家将在第2 章到第4 章中学到的这种垃圾邮件过滤技术,正在将全球电子邮件系统从混乱和停滞中拯救出来。大家将学习如何使用20 世纪90 年代的技术来构建一个精确率超过90%的垃圾邮件过滤器——只需要通过计算词的数目并对这些数目计算一些简单的平均值即可。
在NLP 中,分词(tokenization,也称切词)是一种特殊的文档切分(segmentation)过程。而文档切分能够将文本拆分成更小的文本块或片段,其中含有更集中的信息内容。文档切分可以是将文档分成段落,将段落分成句子,将句子分成短语,或将短语分成词条(通常是词)和标点符号。将文本分割成词条的过程,这个过程称为分词。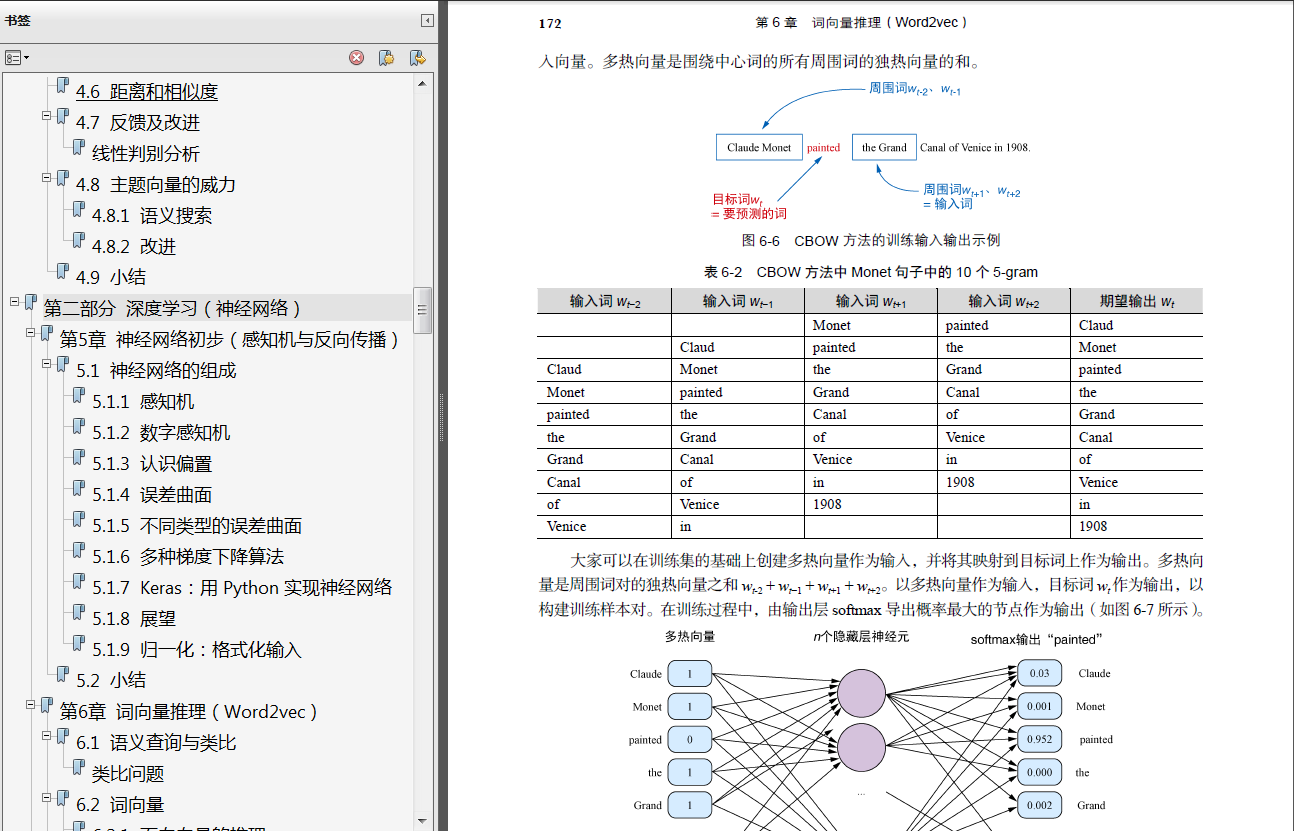
自然语言处理流水线的各个阶段可以看作是层,就像前馈神经网络中的层一样。深度学习就是通过在传统的两层机器学习模型架构(特征提取+建模)中添加额外的处理层来创建更复杂的模型和行为。神经网络通过将模型错误从输出层反向传播回输入层,从而帮助完成跨层传播学习的过程。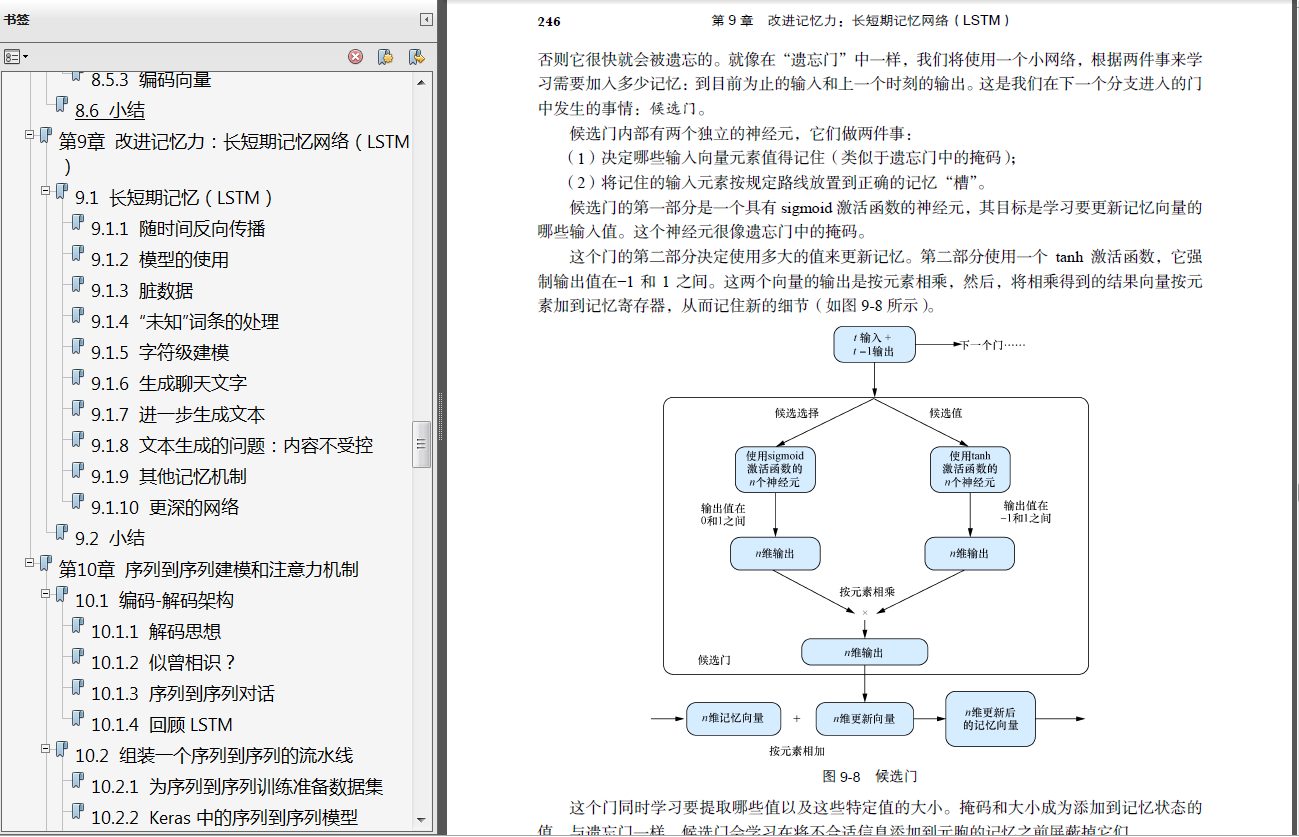
NLP 已成为深度学习的核心应用领域,而深度学习是NLP 研究和应用中的必要工具,分为3 部分:第一部分介绍NLP 基础,包括分词、TF-IDF 向量化以及从词频向量到语义向量的转换;第二部分讲述深度学习,包含神经网络、词向量、卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆(LSTM)网络、
序列到序列建模和注意力机制等基本的深度学习模型和方法;第三部分介绍实战方面的内容,包括信息提取、问答系统、人机对话等真实世界系统的模型构建、性能挑战以及应对方法。

若有收获,就点个赞吧
0 人点赞
