
这节主要讲了很多体系结构
本章的第一节和第二节是中重点,第一节主要讲了architecture style 第二节主要讲了system architecture
第二节重点在讲具体怎么实现架构
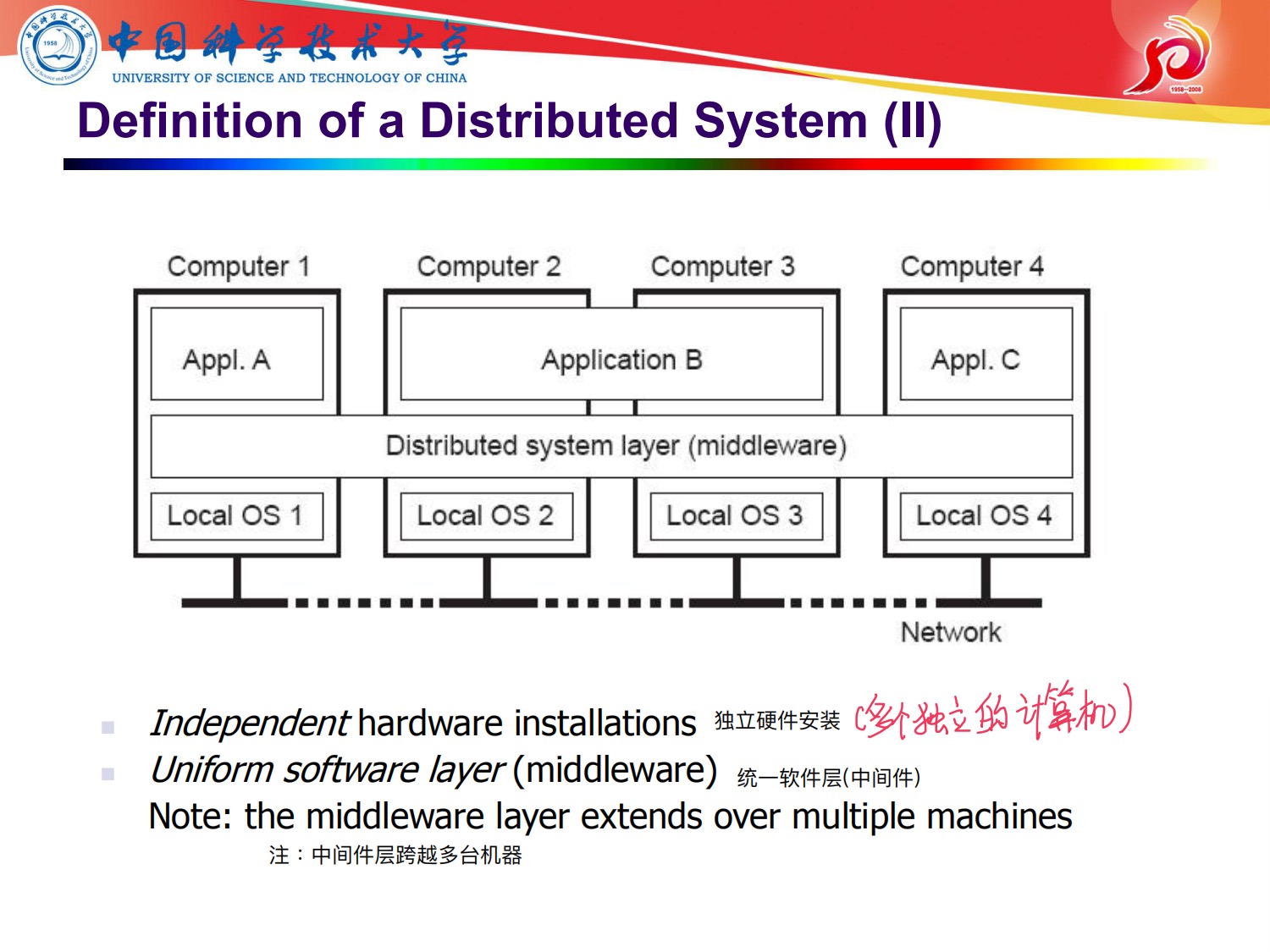
这里 回顾了一下 分布式系统的定义
architecture style 由两部分组成,定义也是说architecture style将不同的component给connect
1,component
2,connector

architecture style的分类:
1,分层体系结构(也是目前用的最多的架构)
2,基于对象的体系结构
3,以数据为中心的体系结构
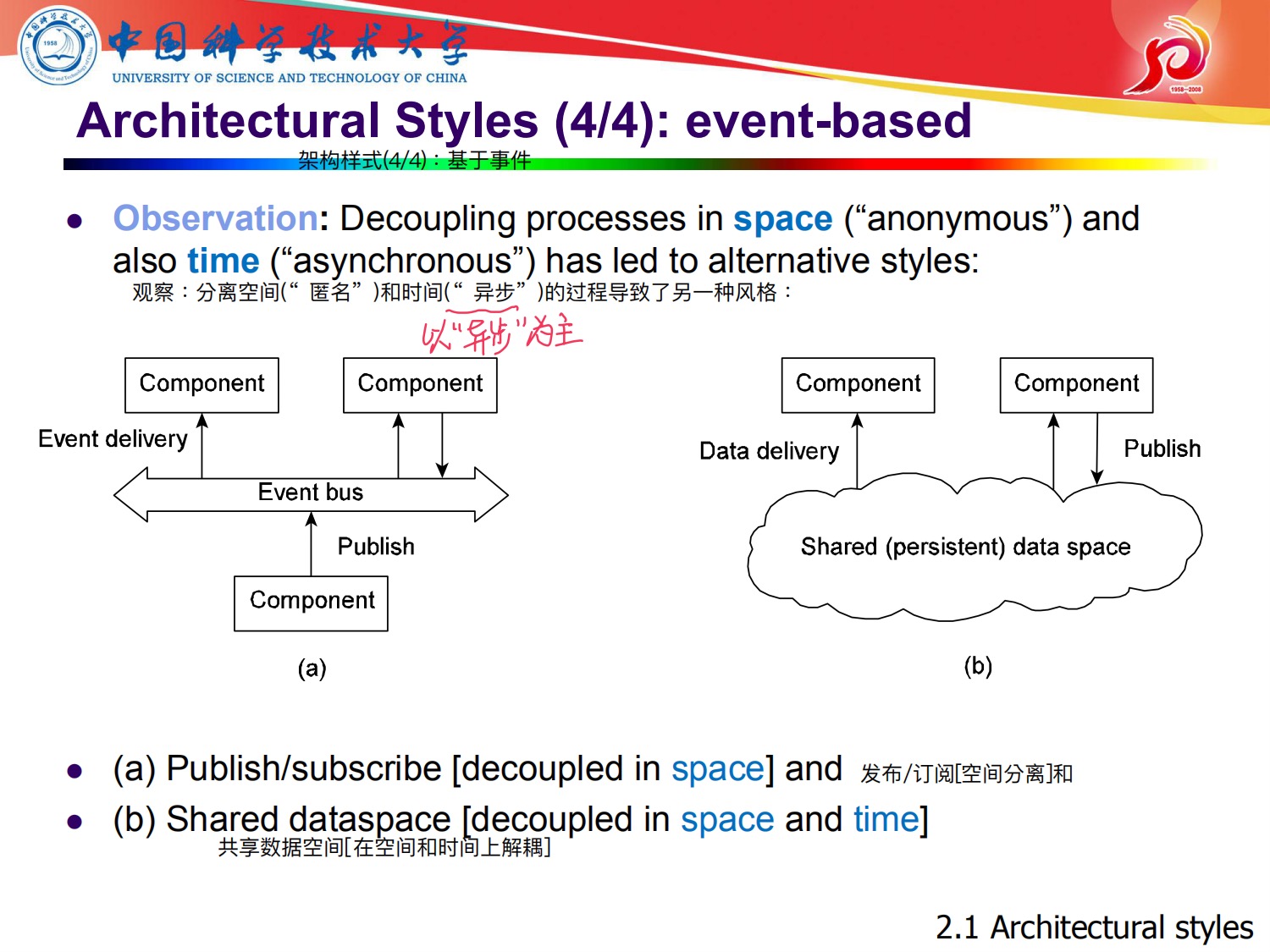
4,基于事件的体系结构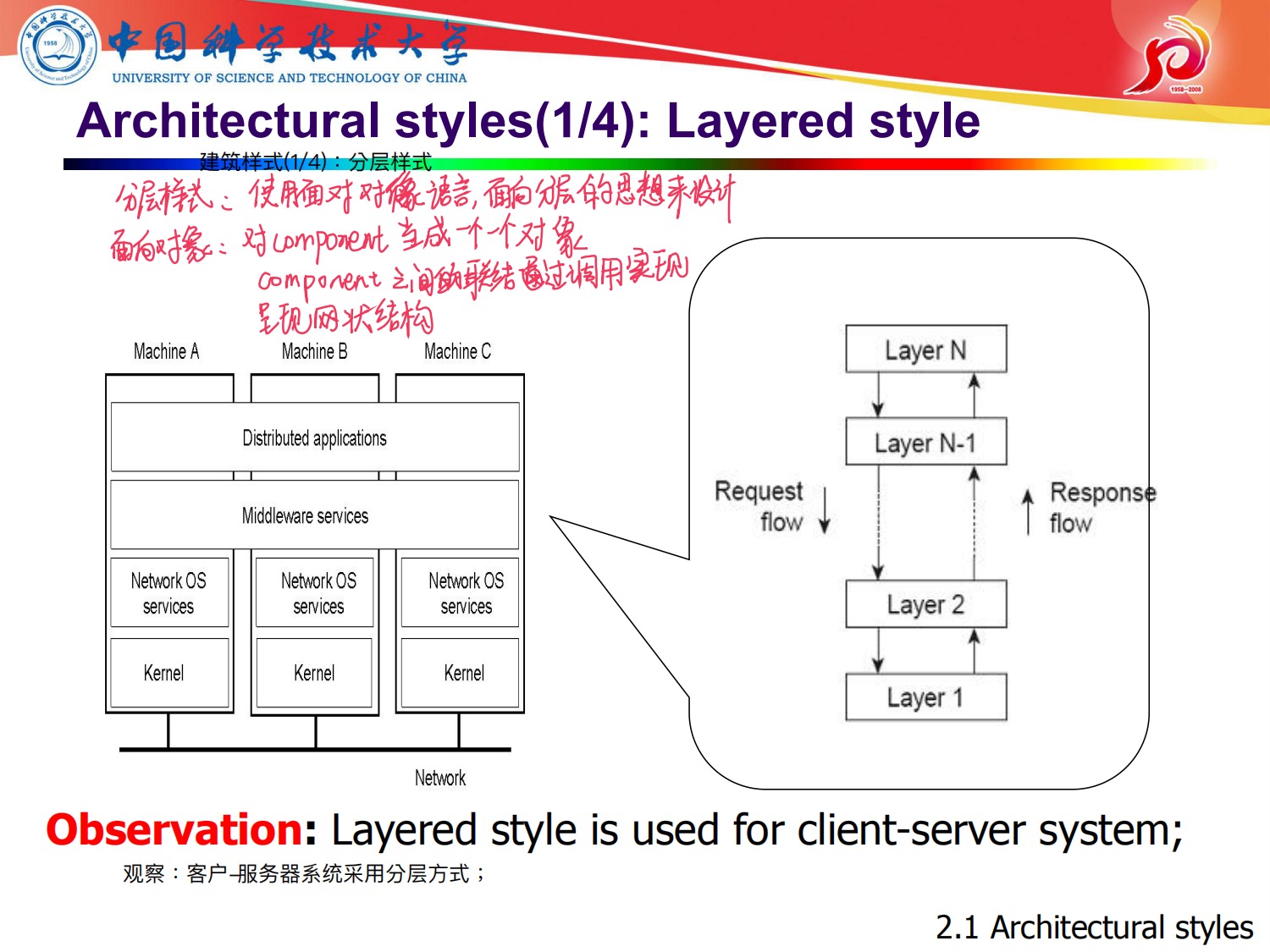
对照传统的计网里的7层,来相应设计分布式系统,这里注意与基于对象的分布式系统的区别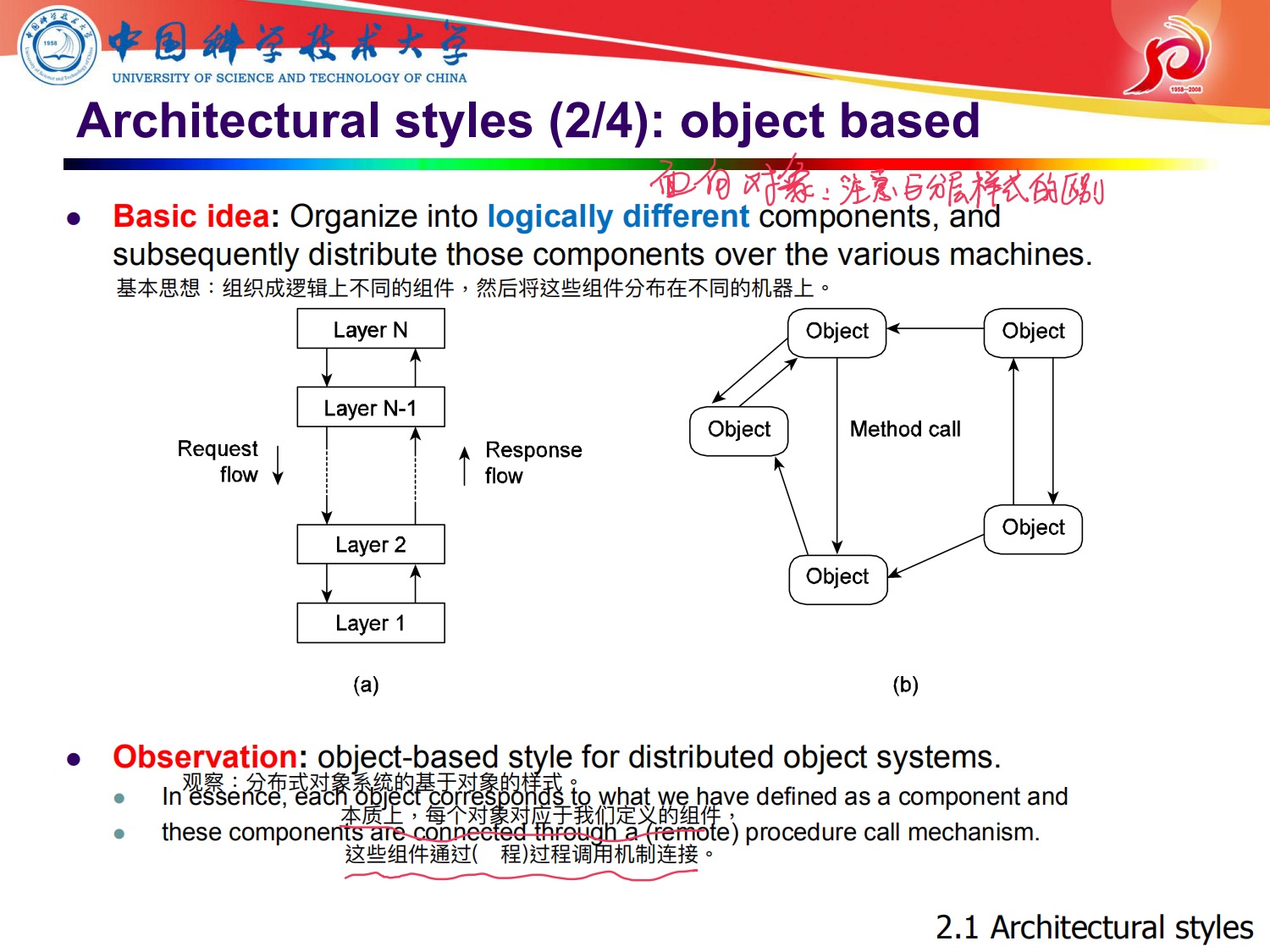



系统架构的定义:系统架构决定了软件组件,组件的联系,以及组件的位置
系统架构的分类:
1,集中式体系结构
2,分散式体系结构
3,混合式体系结构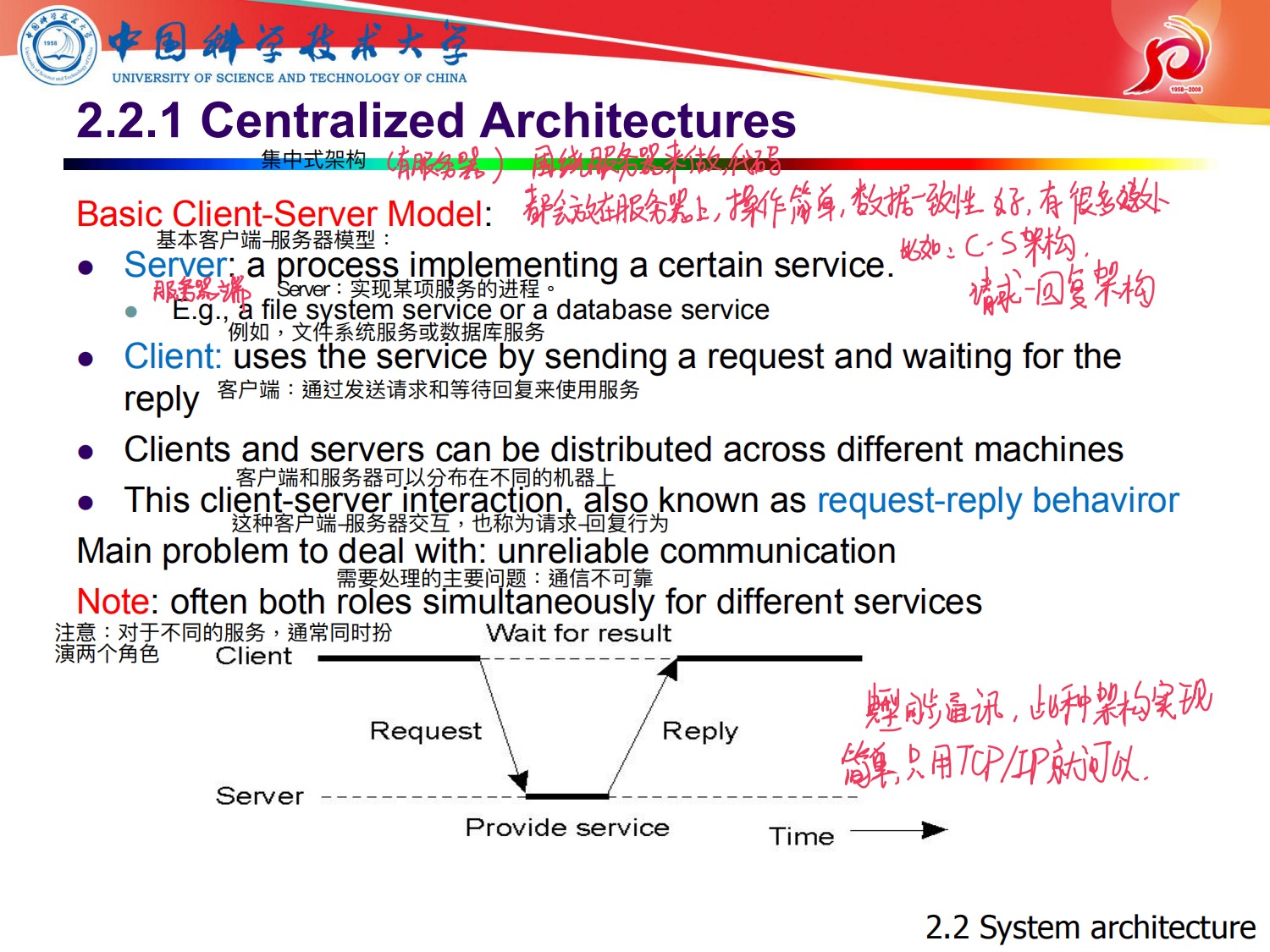
系统架构的分类:
1,集中式体系结构
具体描述:是有服务器结构,整个系统也是围绕着服务器来做的,
优点:简单,易于实现
缺点:造成缺失异常操作时,不知道在哪个地方出问题,如下所示
举例:C/S架构啊






现在来说分散式体系结构
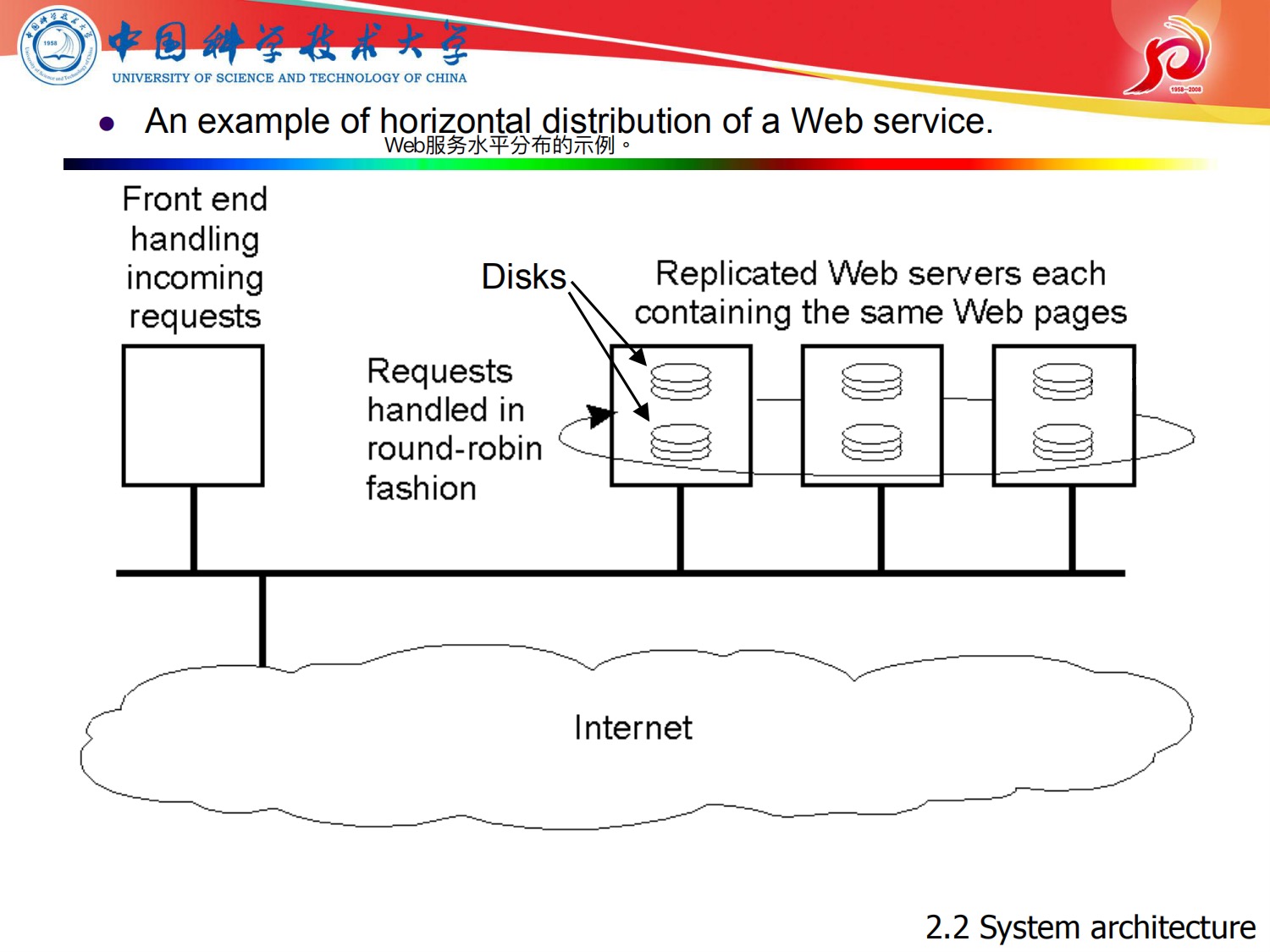
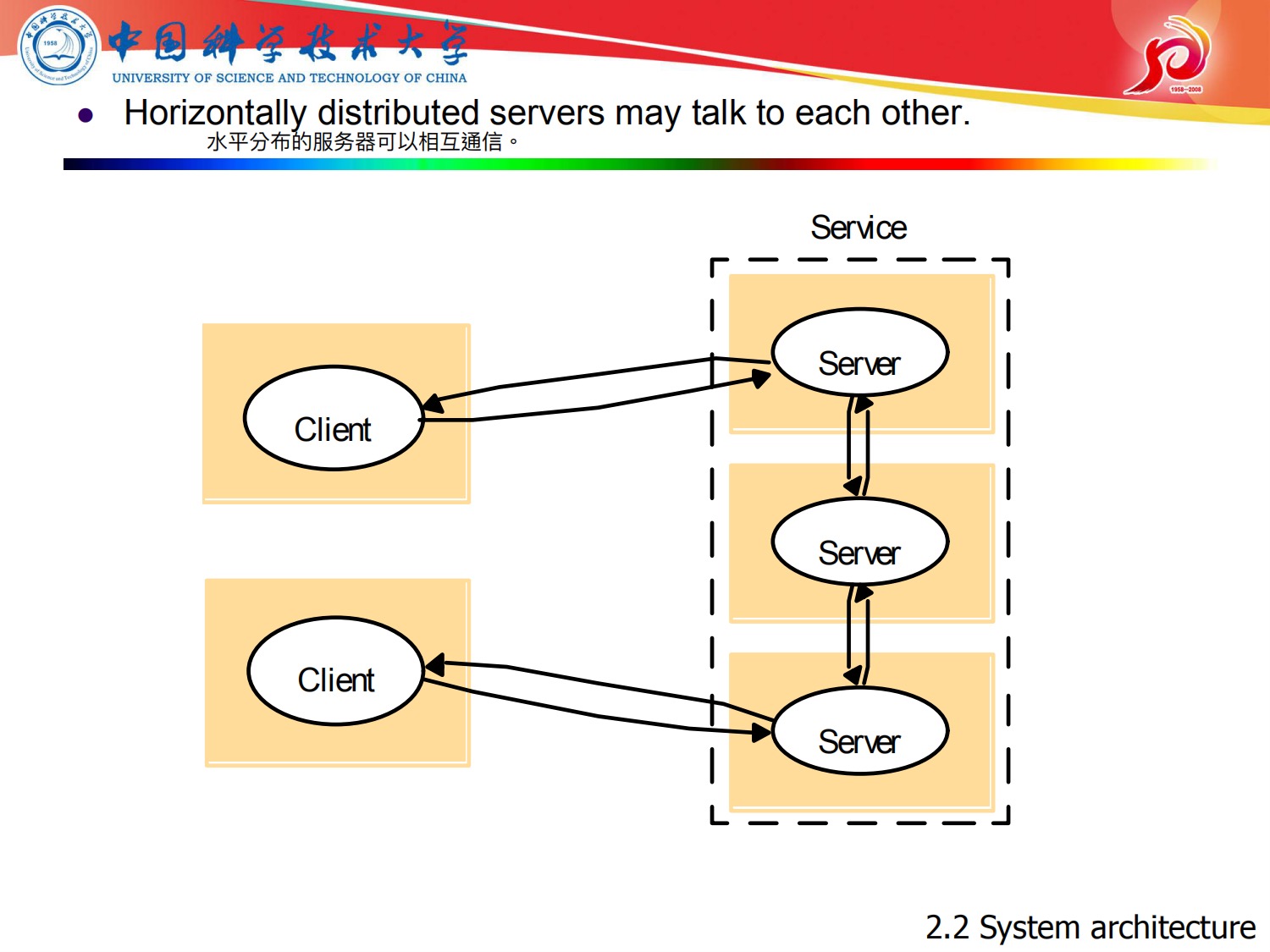


在这里呢 因为讲到了分散式体系结构(p2p),就用了另外一个ppt


这里介绍分散式体系结构的发展历史
介绍了p2p发展早期的
1,Napster
2,Gunutella
3,chord
4,bitTorrent(PS:总算知道迅雷下片的原理了。。。也总算知道为啥,迅雷下到99%的时候,后面1%最难下)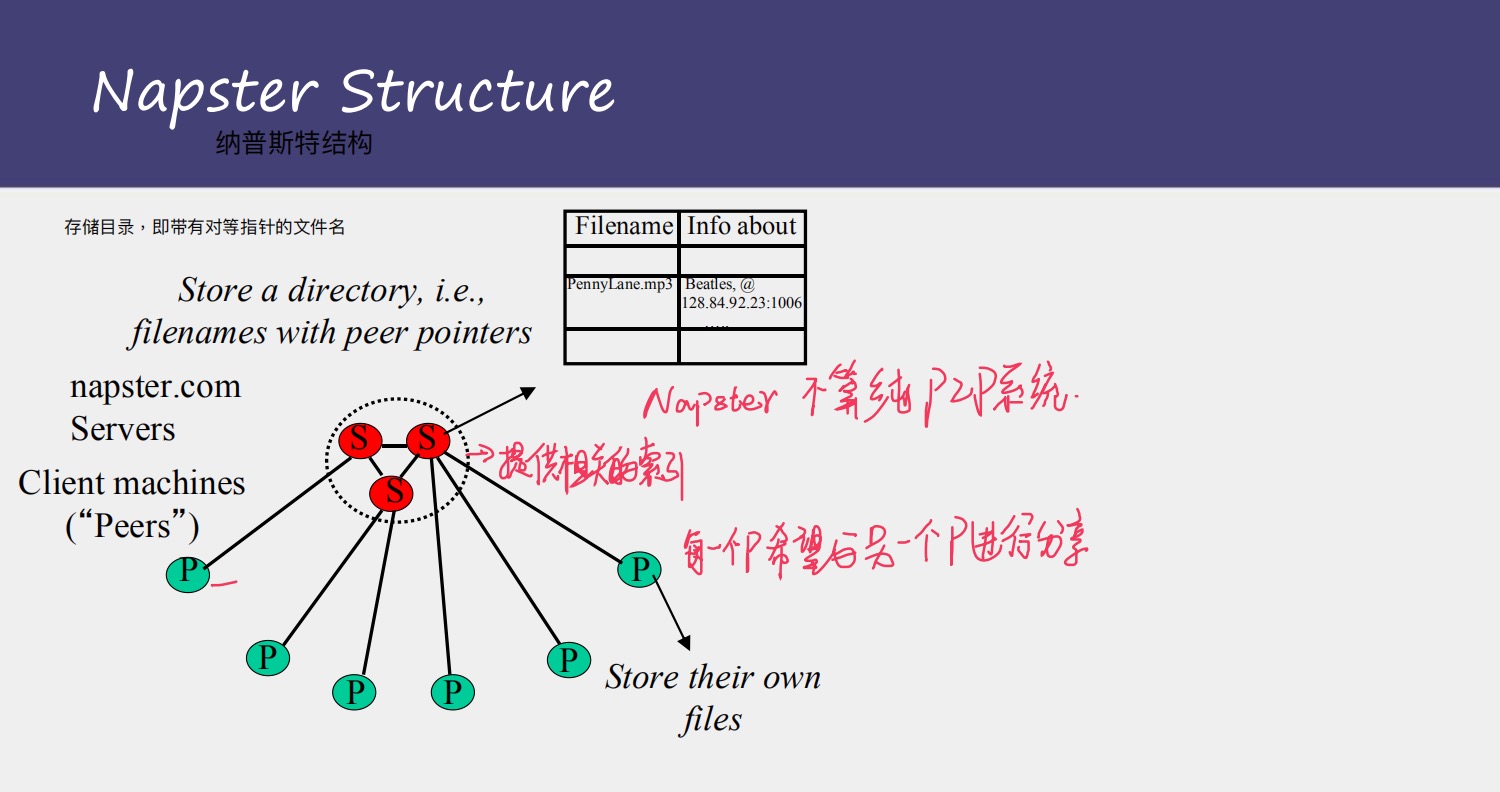


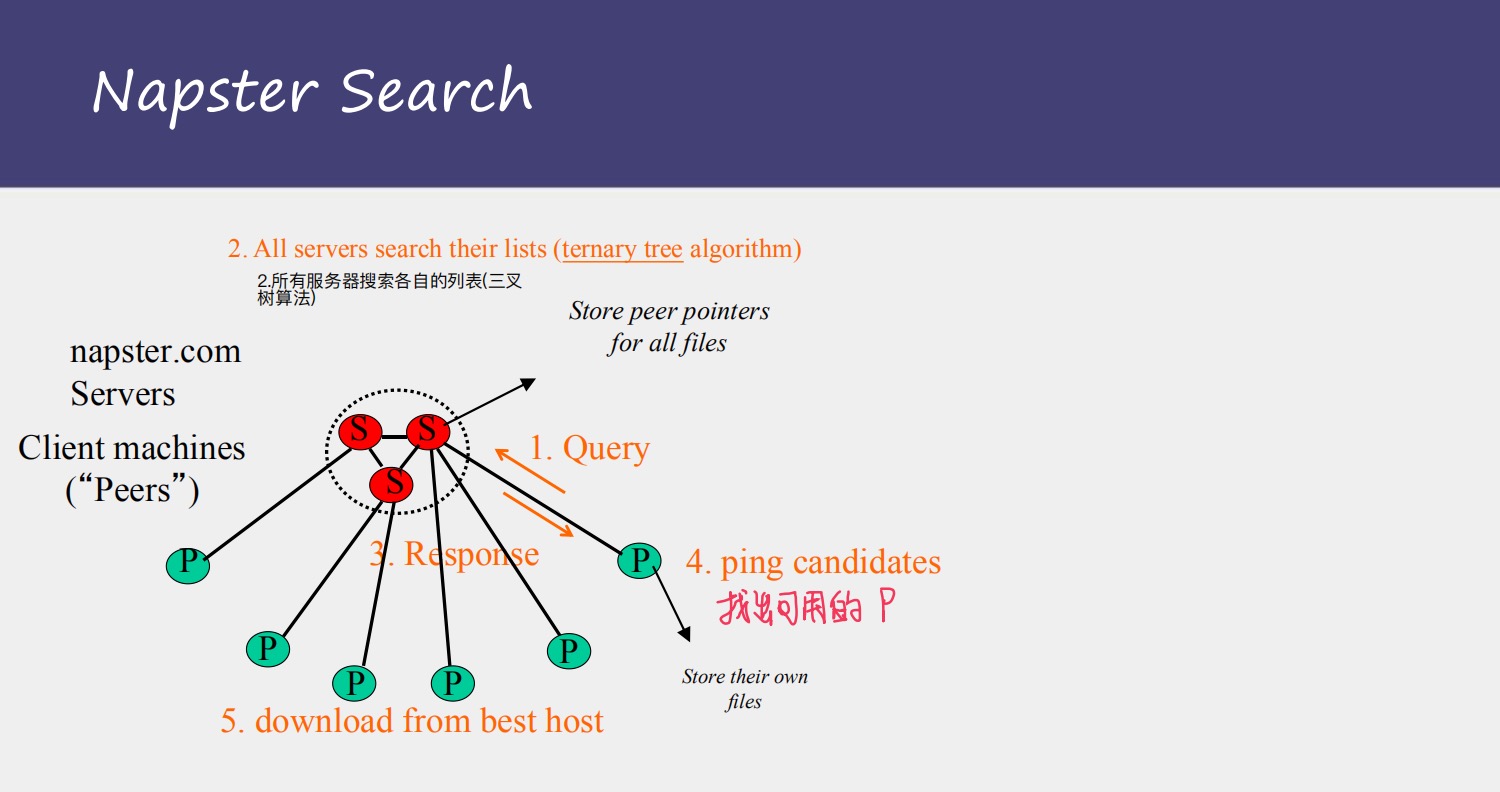
这里介绍分散式体系结构的发展历史:1,Napster
Napster是一个音乐分享系统
工作原理是:
注册过程:a,客户机连接服务器 b,上传key-value对 c,服务器维护索引
搜索下载过程:a,客户机在服务器查找曲目 b,服务器返回有主机列表元组 c,客户机进行ping速率,找到最快传输主机 d,进行传输
Napster不算是真正意义上的p2p,因为在Napster系统中依然有集中式服务器的存在
所以有集中式架构的那些缺点,传输错误、容易阻塞。。。
但是又不同于以往的集中式架构,因为客户机不是从服务器上下载音乐


这里介绍分散式体系结构的发展历史:2,Gnutella
Gnutella是真正意义上的第一个p2p系统(分散式体系结构)
这里提前说明一下
无结构的p2p系统:结点的邻居是随便选的
有结构的p2p系统:结点的邻居是有规则选的,按照一定的规则进行选择邻居结点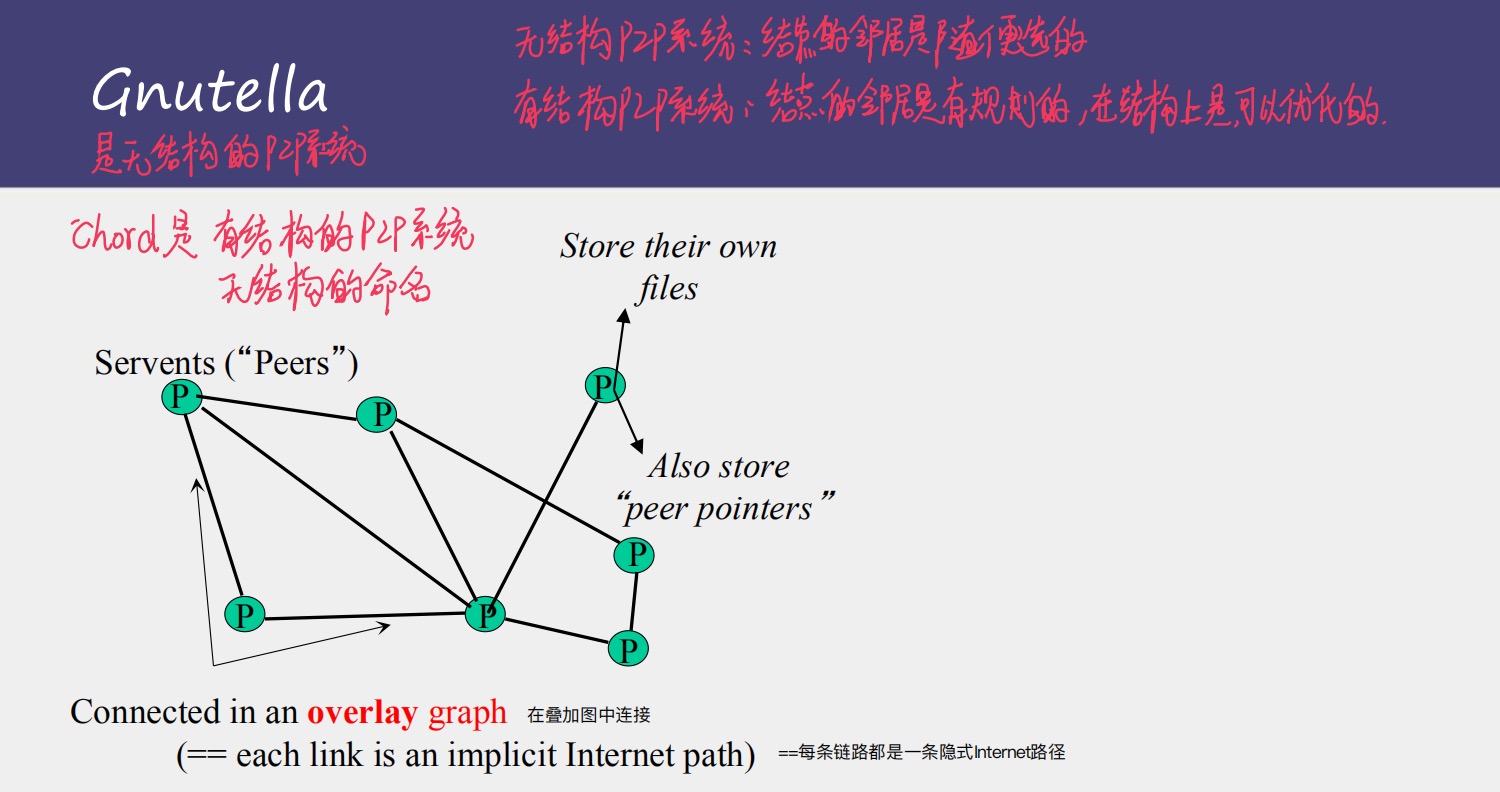

为什么Gnutella是无结构的p2p系统呢?
当在做搜索时,Gnutella是以flooding的方式发出Querry请求,只等待queryhit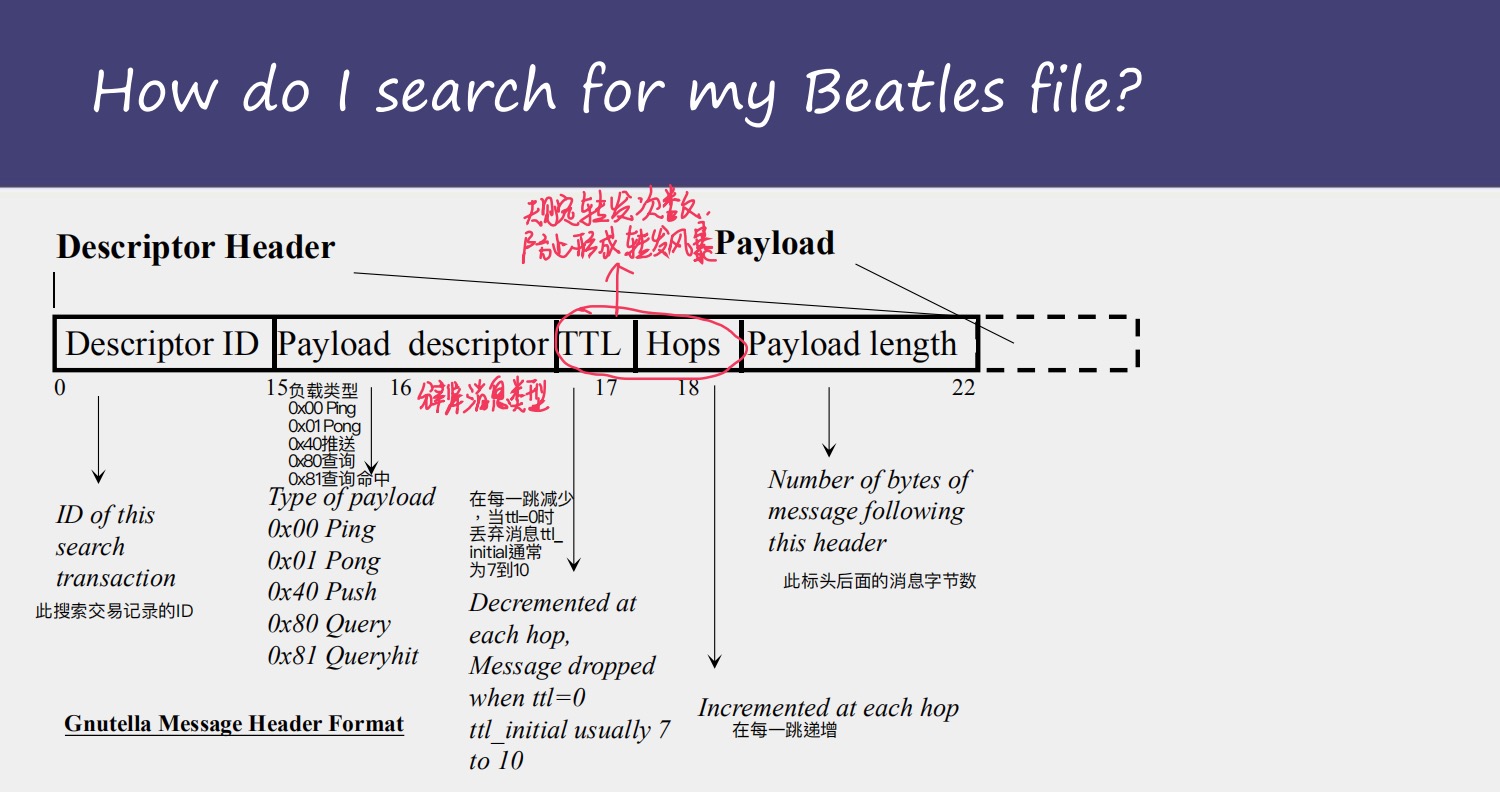
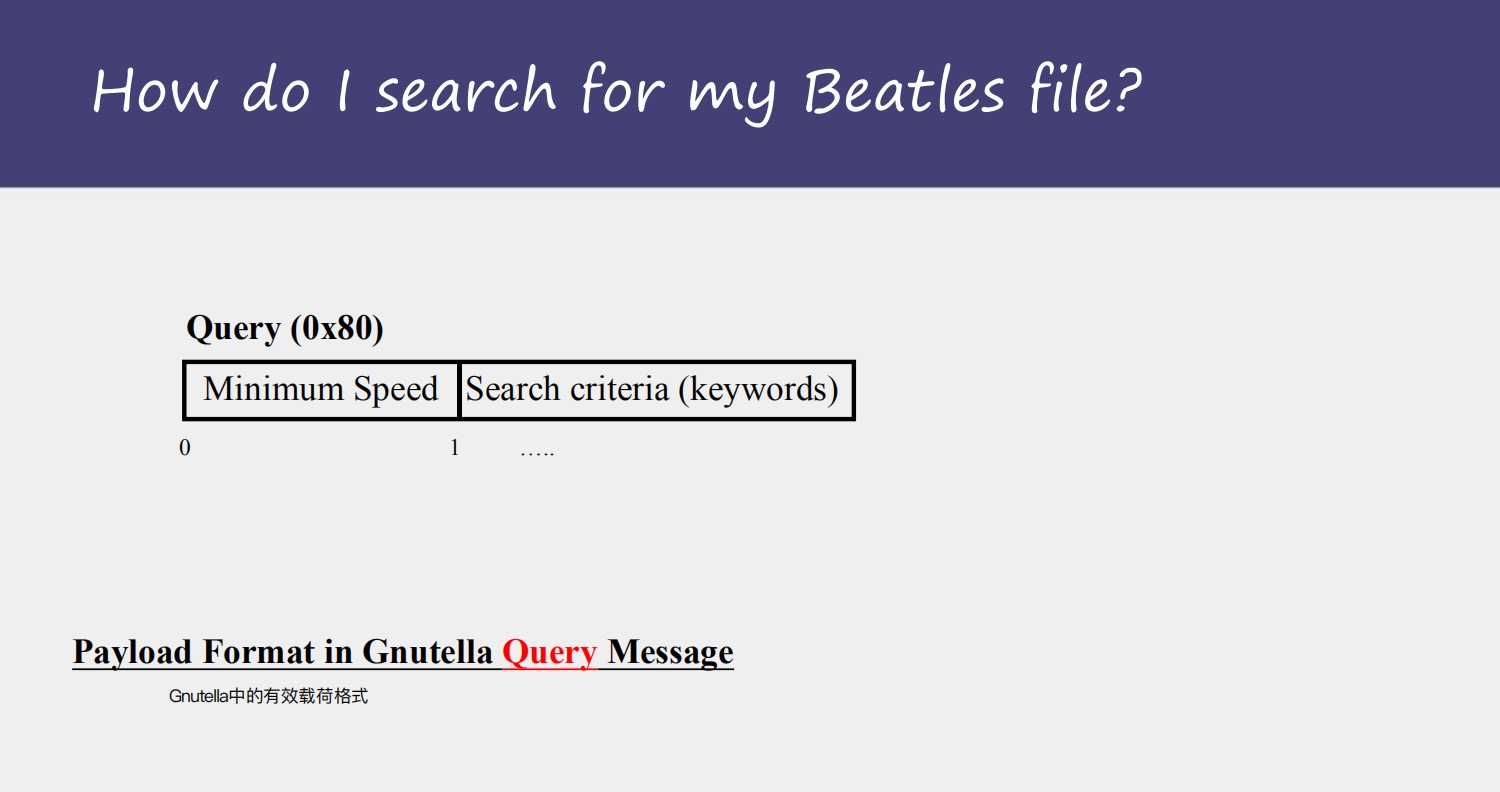
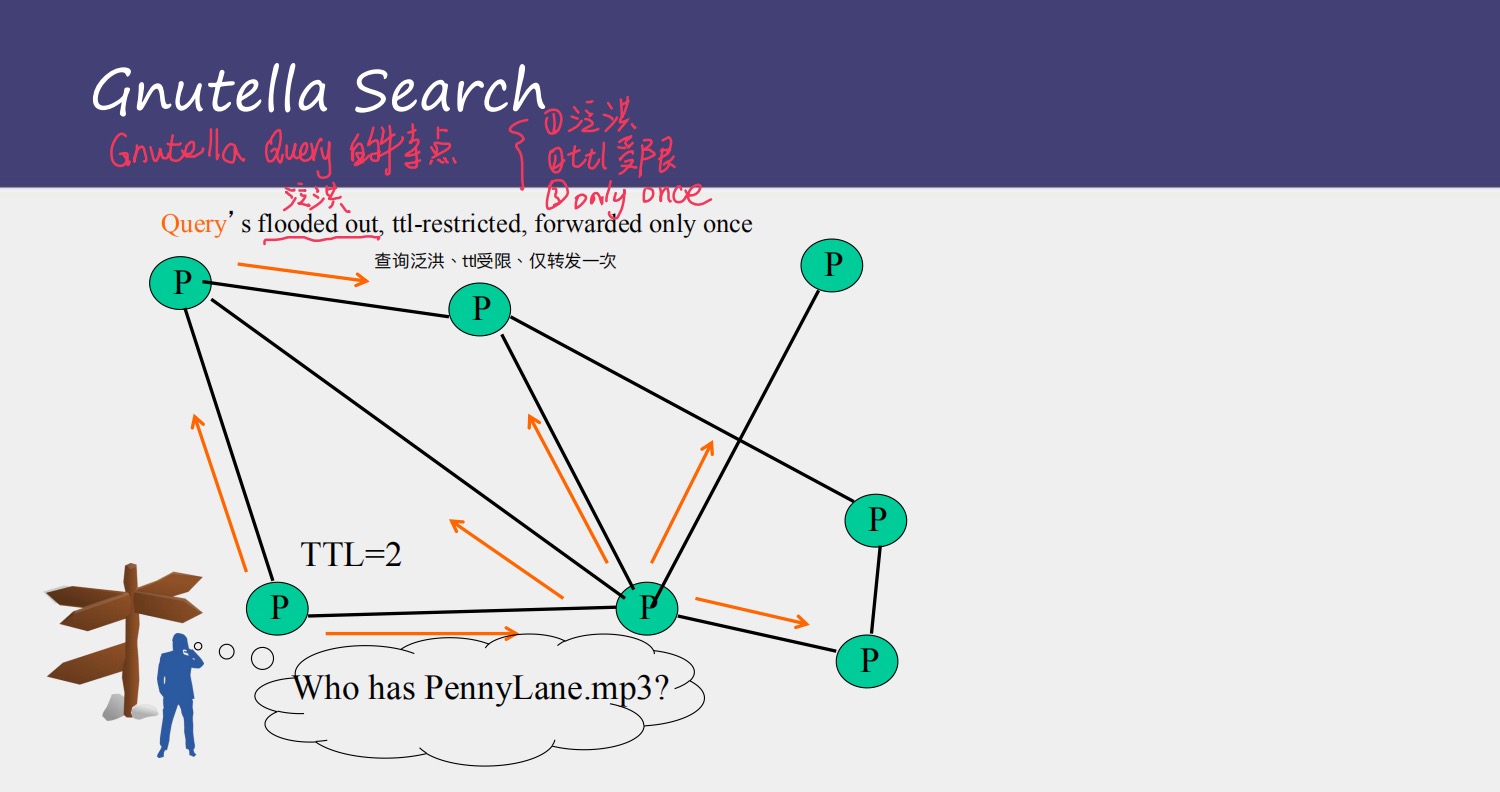
Gnutella的query的特点
1,泛洪 flooding
2,ttl受限
3,每个query 在每个结点中只会被转发only one
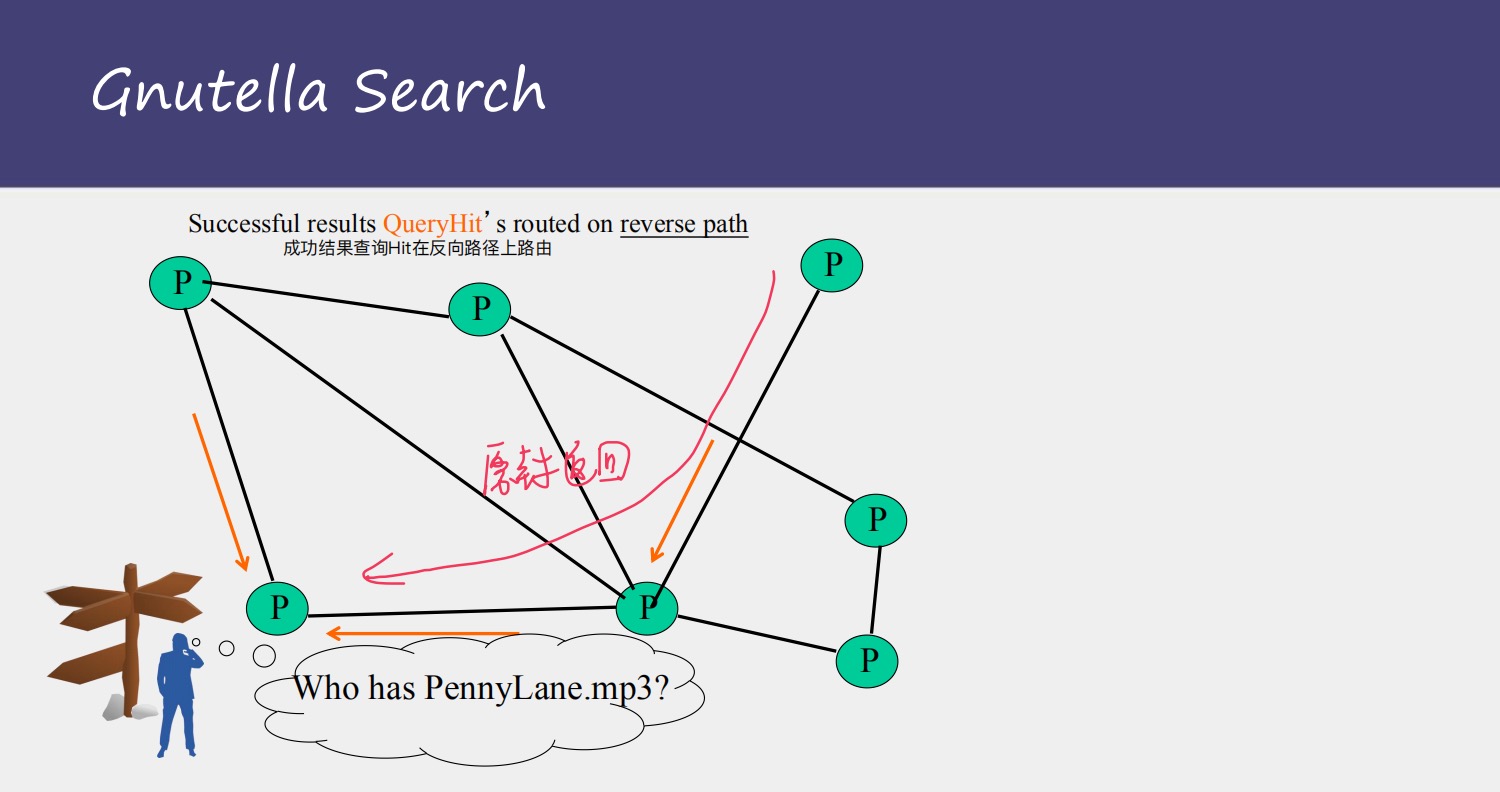


在收到多个queryhit后,会再次进行比对,找出其中的最佳选择


但是Gnutella也有大量问题,就是50%的时间都是用来做ping、pong操作,用来探知周围结点的变化,进行更新自己的维护列表,导致效率不高
提前说下chord系统,是有结构的p2p系统(但是是无结构的命名)这种查找结点的邻居方法是有规律的,有点像二分查找,所以把查找的时间复杂度降到O(logn),还是挺不错的!
这个下面讲的详细
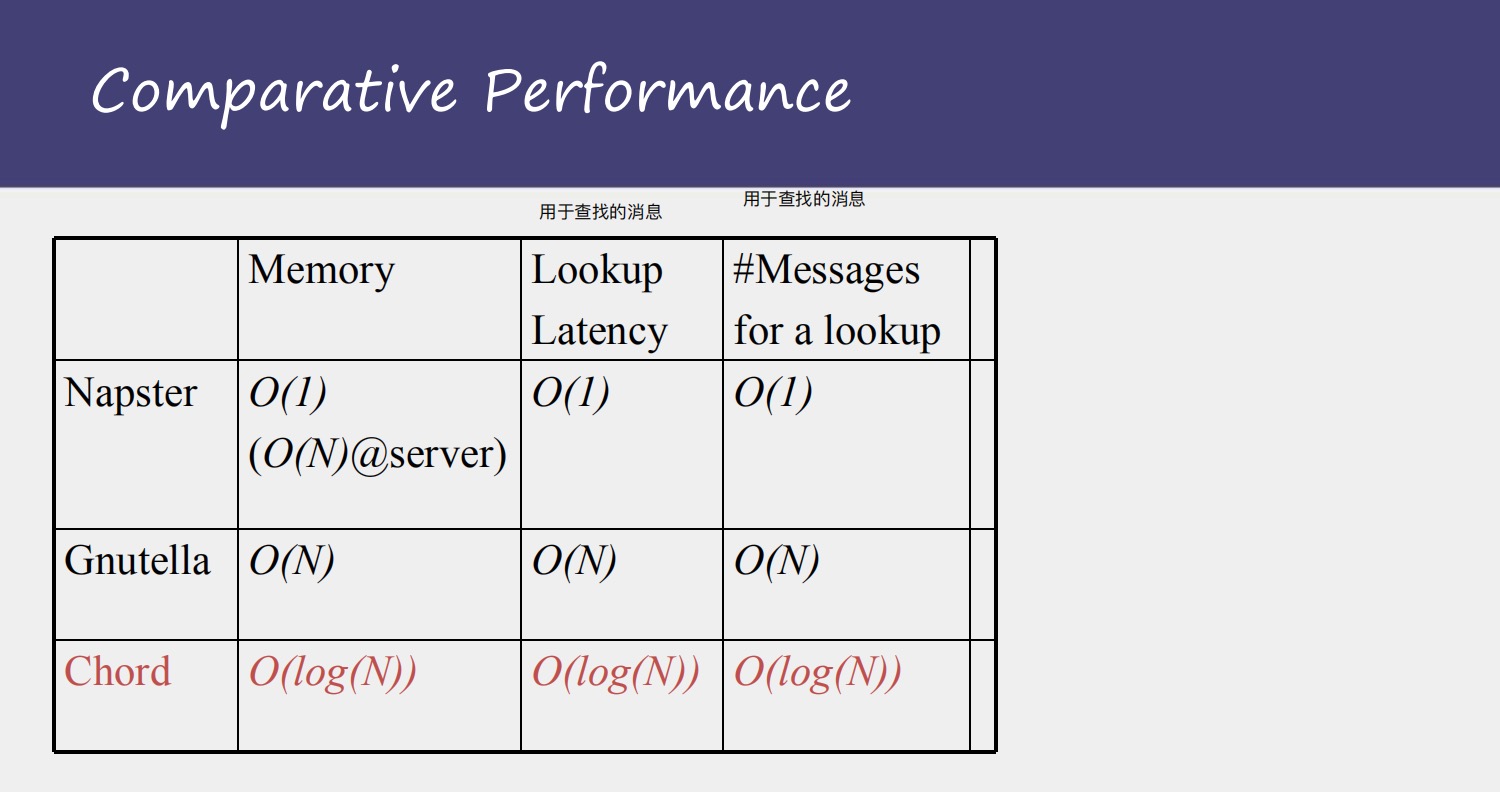


chord系统怎么是有结构的p2p系统,这个在命名那章会讲,也是因为DHT的使用

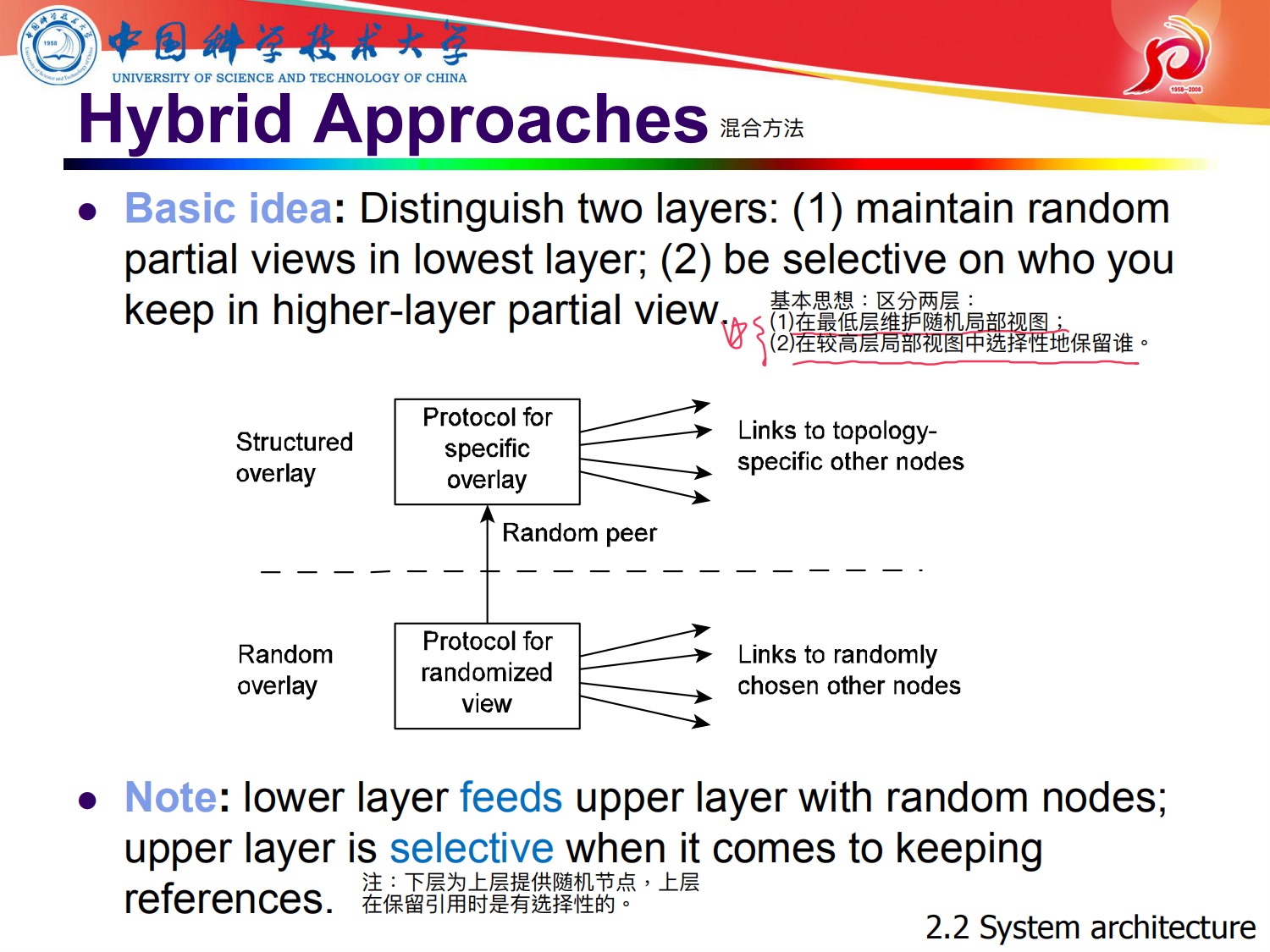

混合式p2p,bittorrent
1,客户端先到web上找到torrent文件
2,客户端解析torrent文件,得到很多的track,选择一个track server 上 里面有很多的Node iP
3,再选择一个IP进行,进行文件共享









若有收获,就点个赞吧
0 人点赞
