
这节有点难。。。
这一章 主要讲的是
(1)时钟同步
(2)相互排斥
(3)节点的全局定位
(4)超级节点
花了很大时间在(1)(2)两节

之前在在分布式系统简介里提到(DS-CH1-introduction)
decentralized algorithm的4条原则里:
1,没有一个节点知道整个系统的信息
2,节点决策仅仅依靠局部信息
3,一台机器故障不会影响系统
4,没有全局时钟的概念
那如果时钟同步很重要(这是很明显的)
那在分布式系统中,我们应该怎么做?














分布式系统时钟同步问题:
(1)Chritian算法
(2)Berkeley算法
这个就是典型一个集中式服务器,把时间当成一个信息,想知道时间,就去time server上去请求一下,
优点:简单,好部署,集中式服务器的特点都有
但是有缺点:信息传输过程中是有延迟的!!!发过来的时间不是当前时间啊!!







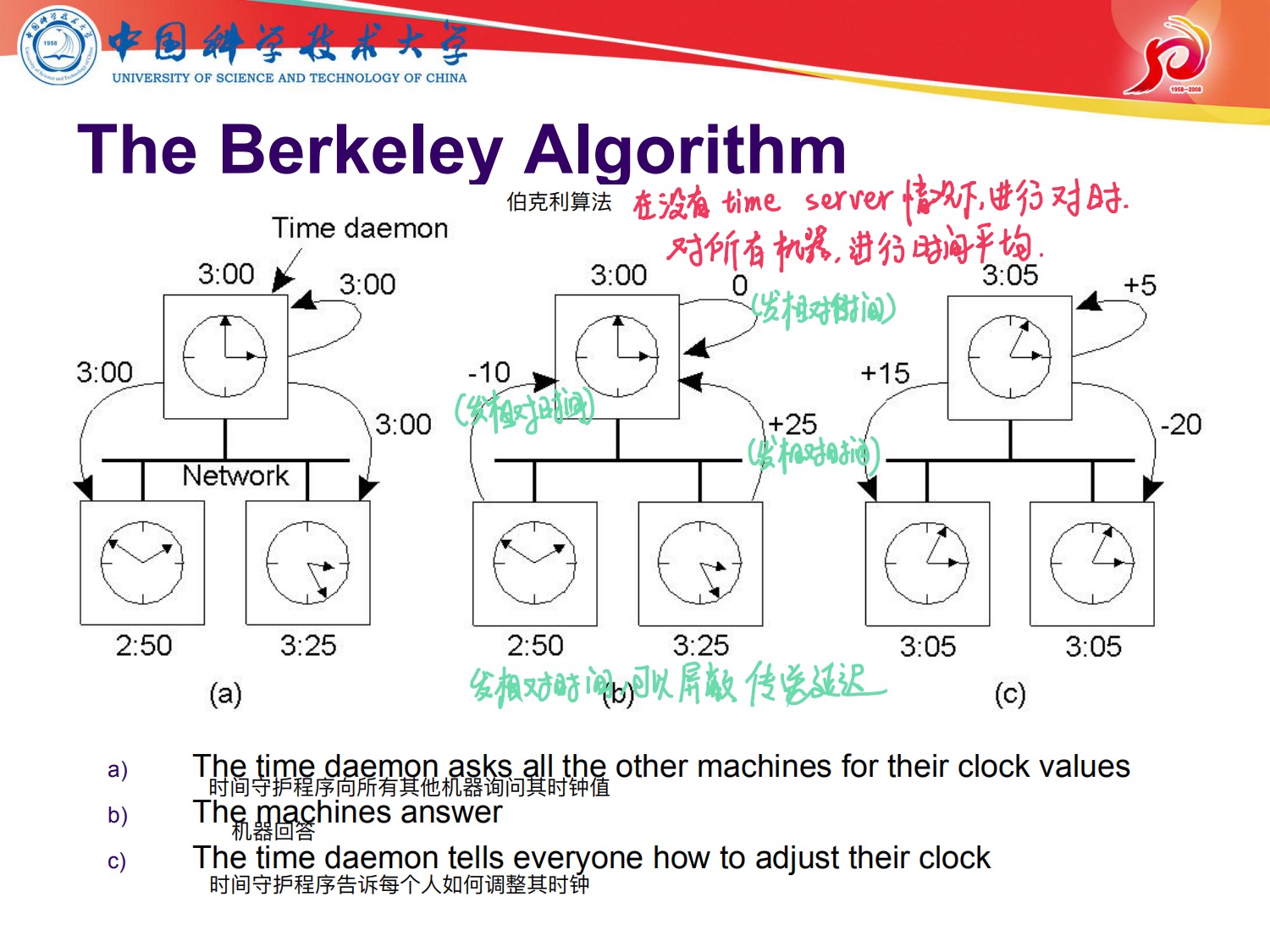
Berkeley算法是没有time server的
看上面步骤
(a)
(b)
(c)
在分布式系统中进行物理时钟同步的代价很高,
因为每一个节点,都有自己的物理时钟,分布式系统里的节点数太大了,去同步成一个时钟,不太可能
所以那既然这样
对每次的操作前,对操作的参与节点,标上逻辑前后顺序关系,这样做,是不是就是很简单了呢!!!
使用happen-before来表示这种逻辑关系
如果e1发生在e2之前,就叫e1 happen before e2 记做
也正如前面所说的操作参与了,才能标记逻辑顺序
如果两个节点没有信息交互,此时就没有顺序而言,标记顺序也没有用,所有这也是物理时钟同步代价高的原因,没必要进行大量无意义的时钟同步
如果两个事件没有先后顺序,就称a与b并发 a||b
上面简单的描述了一下 happen-before关系

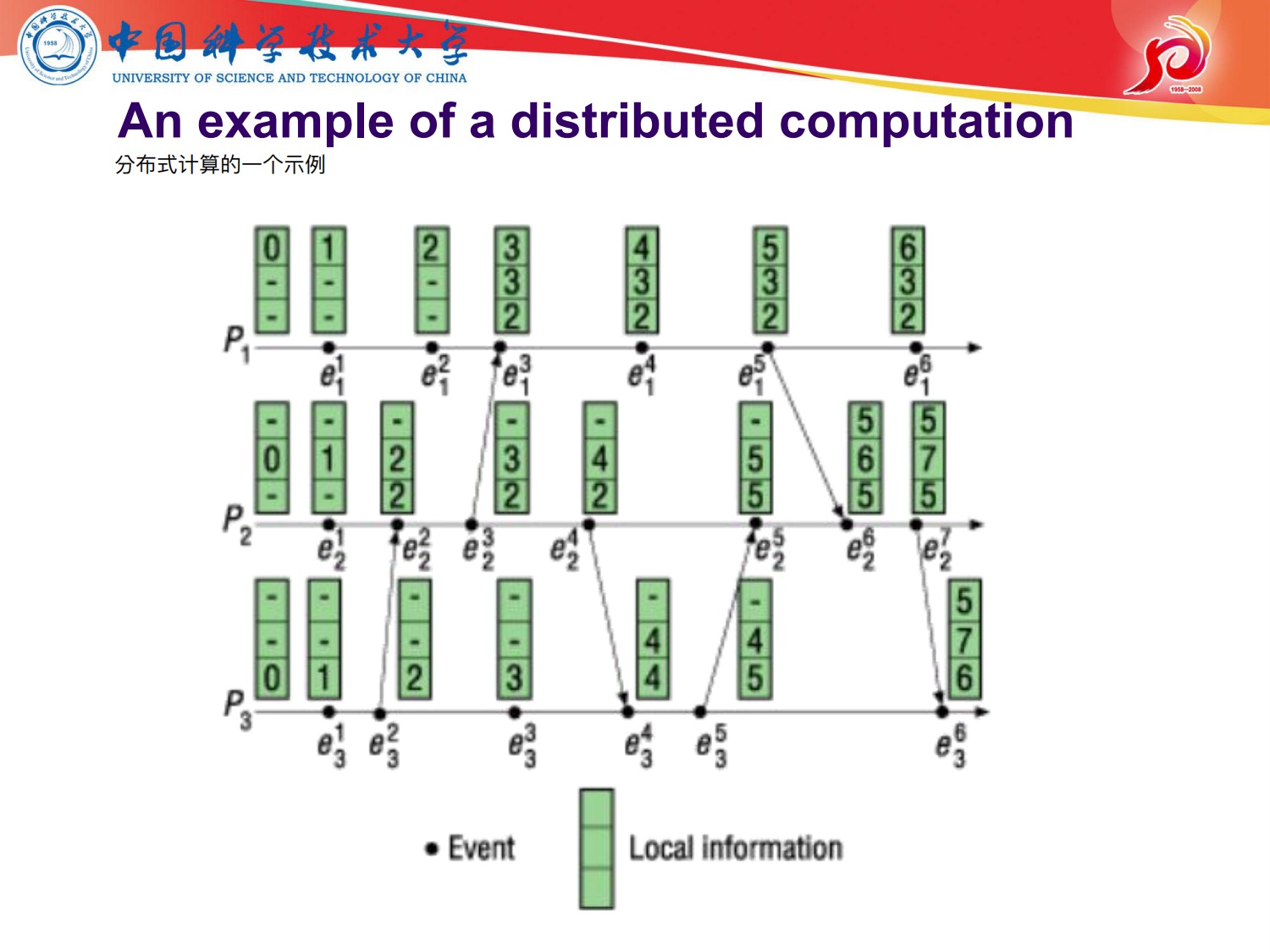
进一步优化
增加一个timestamp 如果 ,则C(e1)
进程本身的事件好维护,每发生一个事件,逻辑时钟+1
产生进程间通信也好维护,就直接把让接收消息的进程进行逻辑时钟调max+1,细节如下



对排序按时间的严格性分为
全序更新:全部事件都要排序
因果序更新:有因果关系才排序
FIFO:有先后顺序的才排序
这里在逻辑时钟(lamport时钟)就有疑问了,对于数据库和备选数据库来说,update1和update2两个操作是并发的,不好来规定逻辑时钟,但是这两操作必须要有先后顺序,不然不能保证两个数据库的数据一致,
解决方案如下:
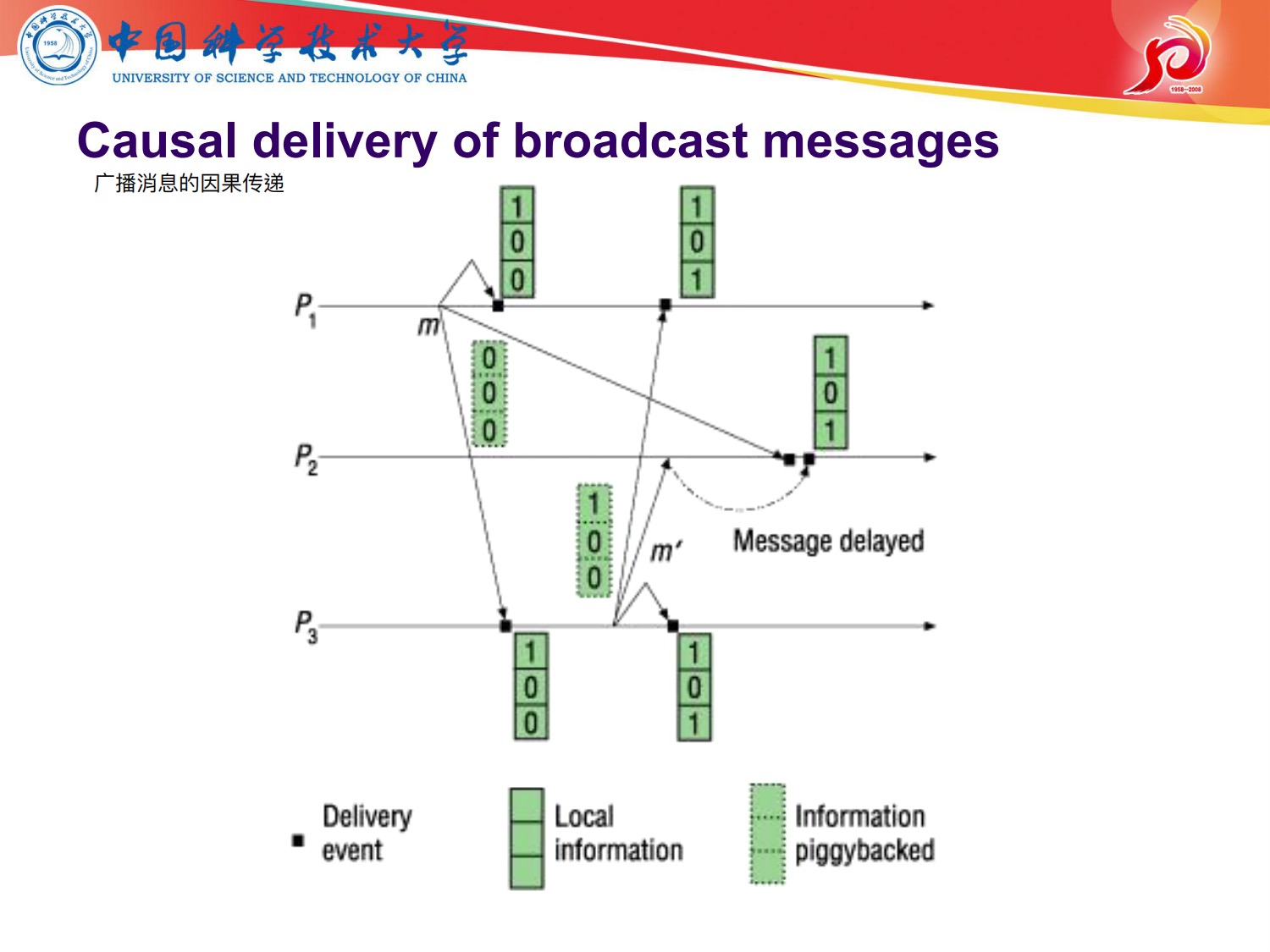
这里介绍使用逻辑时钟实现全序多播的方案:



Vector Clock 记录进程所发生的的事件数
看下面的演示







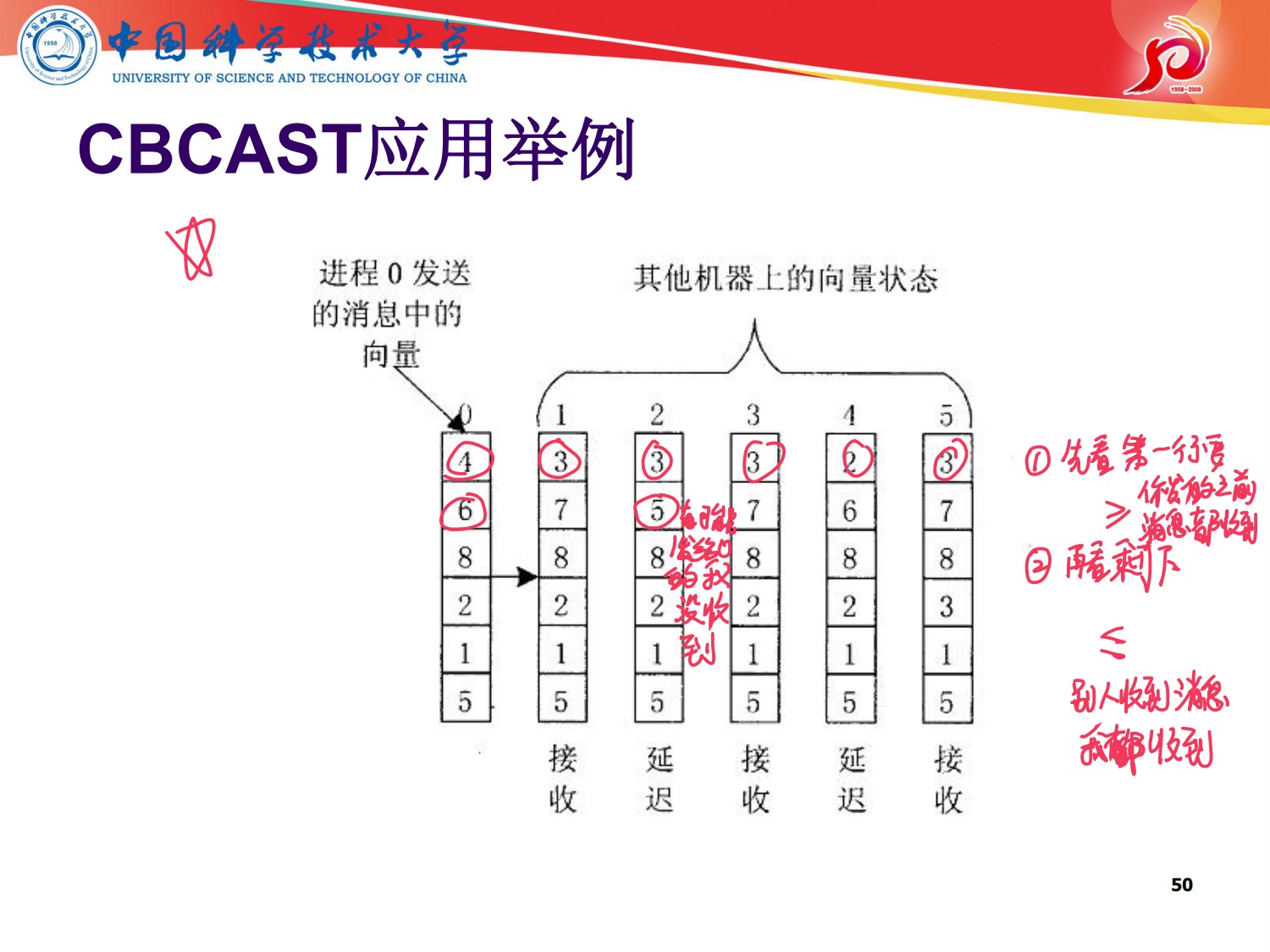
怎么根据消息的矢量戳和本身的矢量戳来决定是否延迟
(1)先看第一行,第一行应该是小于1,表示,前面你发的我都收到了
(2)再看剩下的,表示0号进程收到的其他消息,我这个进程也都接收到


回顾一下,操作系统的临界区问题

评价分布式系统的时候增加两个指标
MC:每个CS条目进程交换的信息数
SD:经过多少个消息才进入临界区

本节Mutual exclusion主要讲在分布式系统中,怎么协调多节点对资源的访问
分为
(1)集中式
(2)分散式
(3)分布式
集中式互斥访问,把集中式的服务器当成老城管了;
优点:容易部署,简单
缺点:容易阻塞,节点崩溃
分散式互斥访问算法:
增加协调器,进行多数表决




看下面的分布式互斥访问算法方式:
(1)0号,2号都想要访问资源,所以0号,2号都要把访问资源时间发出去,1号不想访问资源,就不用发送时间戳
(2)1号接收别人请求资源的消息且自己不需要访问资源,就都回了个OK,
(3)2号因为访问资源的时间戳比0号小,所以就给0号发送OK,说0号节点,你先访问
(4)0号节点在都收到其他节点的OK后,就去访问资源,并且也记下了2号也是访问资源的,所以在访问完资源后,就对2号发送OK,叫2号节点去访问资源


a token ring算法,就是把资源在节点环上循环,不想访问丢给下一家,想访问就去访问
比较适合大家都想访问的那种资源,比较公平且高效












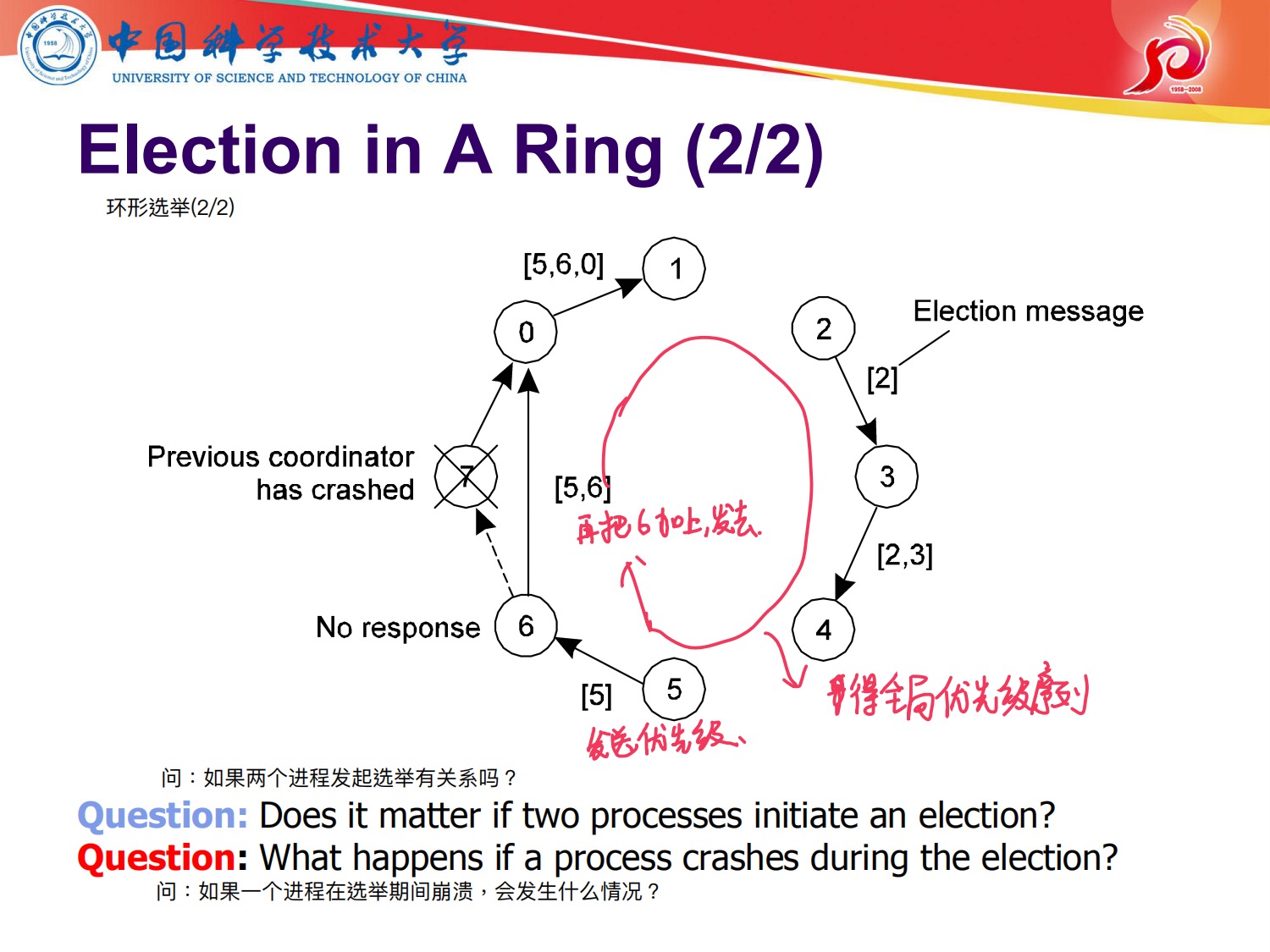


分布式系统死锁检测内容


分布式系统死锁检测是重点!!














若有收获,就点个赞吧
0 人点赞
