场景:
有两个工作簿,每个工作簿中有多个表,我们这里用两个表,每个工作簿中的同名表格式相同,但同一工作簿中的两个工作表 不一样。
要求:将这两个工作簿中,同名的工作表合并。
实际操作中,不只两个工作簿,也不只两个工作表。
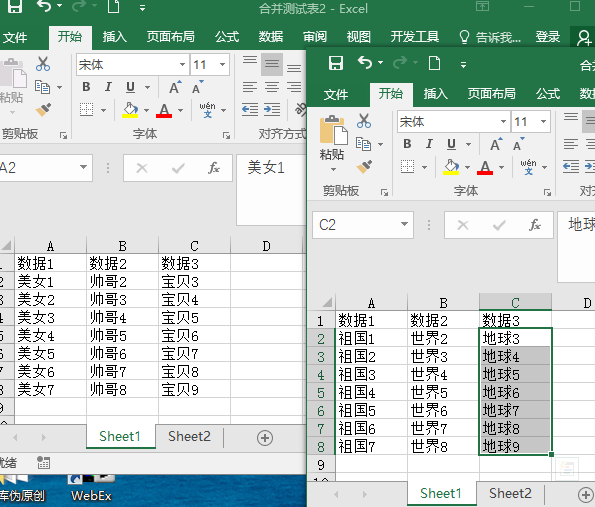
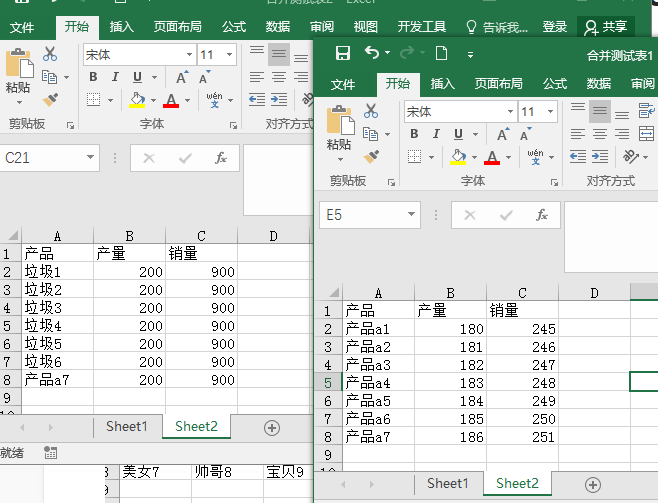
分析数据特征如下:
数据所在路径 C:\Users\Administrator\Desktop\合并
由上可得信息如下:
- 所有 xlsx 工作簿都在同一个文件夹下
- data01.xlsx 与 data02.xlsx 中 sheet 名相同的进行合并。也就是sheet1与sheet1合并,sheet2与sheet2合并其它同理。
我们需要合并数据,首先需要读取到每个工作簿下每个工作表的数据,实现流程如下:
- 获取文件夹下所有工作簿名
- 拼接为绝对路径
- 读取所有表格数据
- 保存到空列表中
那要通过代码完成上面的连环操作,我们就需要使用到 python 中的内置模块 os 模块——与操作系统进行交互的模块,来获取文件夹下所有工作簿名:
无法只通过文件名去系统中找到对应的文件,所以我们需要更准确一点儿的地址——绝对路径,所以现在我们需要拼接每个文件的绝对路径
有了文件的绝对路径后,我们就可以来读取文件中的数据,那就要使用到法宝 pandas 了。首先大家注意,pandas 并不是 python 的内置模块,而是需要我们去安装的。然后使用 pandas 的 read_excel() 方法读取数据,但是需要注意的是,此时我们需要读取的是工作簿下的所有工作表,所以需要指定 sheet_name 为 None,否则会默认读取第一个工作表。
我们通过 202001 可以取到两个工作簿中 202001 的数据,这是为什么呢?傻瓜,因为循环呀~所以,现在我们就想,把数据都添加到一个列表中。除此之外,我们还需要工作表名来获取数据,也就是将工作表名保存到一个集合中(以便去重),也就是集合set()。
有了这些宝贝之后,我们就可以来实现非常关键的步骤了,也就是取出相同名称的工作表进行拼接保存到新的工作表中。
不过仍然要思考的是,我们怎么使用 pandas 给一个工作簿中添加多个工作表呢?那就需要使用 pd.ExcelWriter了。
| 1
2
3
4
5
6
7
8 | import os
import pandas as pd
# 定义文件名集合
all_file_name=set()
# 定义数据列表
all_data_li=[]
# 列出 C:\Users\Administrator\Desktop\合并 下所有文件名
file_name_li = os.listdir(r”C:\Users\Administrator\Desktop\合并”)
for file_name in file_name_li:
file_path_li=os.path.join(r”C:\Users\Administrator\Desktop\合并”,file_name)
# 读取 excel 表格数据
all_data=pd.read_excel(file_path_li, sheet_name=None)
#需要读取的是工作簿下的所有工作表,所以需要指定 sheet_name 为 None,否则会默认读取第一个工作表
# 将数据添加到数据列表中<br /> all_data_li.append(all_data)<br /> # 将工作表名添加到文件夹集合中<br /> for name in all_data:<br /> all_file_name.add(name)<br /><br /># 创建工作簿<br />writer = pd.ExcelWriter("all_data.xls")<br /><br /><br /># 遍历每个工作表名<br />for sheet_name in all_file_name:<br /> data_li = []<br /> # 遍历数据<br /> for data in all_data_li:<br /> # 获取同名数据并添加到data_li中<br /> n_rows = data_li.append(data[sheet_name])<br /> # 将同名数据进行拼接<br /> group_data = pd.concat(data_li)<br /> # 保存到writer工作簿中,并指定工作表名为sheet_name<br /> group_data.to_excel(writer, sheet_name=sheet_name)<br /><br /># 千万莫忘记,保存工作簿<br />writer.save() |
| :—- | :—- |

若有收获,就点个赞吧
0 人点赞
