- Prometheus架构
- K8S监控指标及实现思路
- 在K8S平台部署Prometheus
- 基于K8S服务发现的配置解析
- 在K8S平台部署Grafana
- 监控K8S集群中Pod、Node、资源对象
- 使用Grafana可视化展示Prometheus监控数据
- 告警规则与告警通知
说在前面的话,现在监控首选的话,肯定是Prometheus+Grafana,也就是很多大型公司也都在用,像RBM,360,网易,基本都是使用这一套监控系统。
一、Prometheus 是什么?
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。SoundCloud是搞云计算的一家国外的公司,也是由一位工程师来到这家公司之后开发的这个系统,自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会
(CNCF),成为继Kubernetes之后的第二个项目,这个项目发展的还是比较快的,随着k8s的发展,它也起来了。
https://prometheus.io 官方网站
https://github.com/prometheus GitHub地址
Prometheus组成及架构
接下来看一下它这个官方给出的架构图,我们来研究一下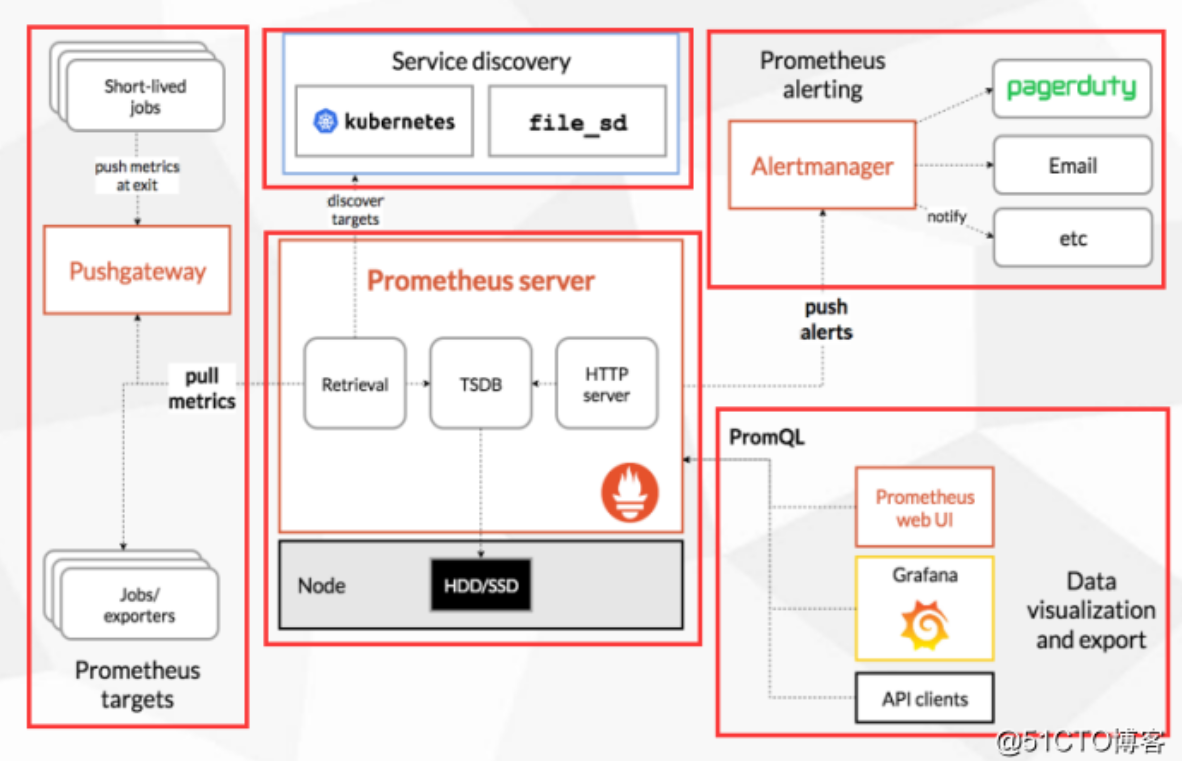
最左边这块就是采集的,采集谁监控谁,一般是一些短周期的任务,比如cronjob这样的任务,也可以是一些持久性的任务,其实主要就是一些持久性的任务,比如web服务,也就是持续运行的,暴露一些指标,像短期任务呢,处理一下就关了,分为这两个类型,短期任务会用到Pushgateway,专门收集这些短期任务的。
中间这块就是Prometheus它本身,内部是有一个TSDB的数据库的,从内部的采集和展示Prometheus它都可以完成,展示这块自己的这块UI比较lou,所以借助于这个开源的Grafana来展示,所有的被监控端暴露完指标之后,Prometheus会主动的抓取这些指标,存储到自己TSDB数据库里面,提供给Web UI,或者Grafana,或者API clients通过PromQL来调用这些数据,PromQL相当于Mysql的SQL,主要是查询这些数据的。
中间上面这块是做服务发现的,也就是你有很多的被监控端时,手动的去写这些被监控端是不现实的,所以需要自动的去发现新加入的节点,或者以批量的节点,加入到这个监控中,像k8s它内置了k8s服务发现的机制,也就是它会连接k8s的API,去发现你部署的哪些应用,哪些pod,通通的都给你暴露出去,监控出来,也就是为什么K8S对prometheus特别友好的地方,也就是它内置了做这种相关的支持了。
右上角是Prometheus的告警,它告警实现是有一个组件的,Alertmanager,这个组件是接收prometheus发来的告警就是触发了一些预值,会通知Alertmanager,而Alertmanager来处理告警相关的处理,然后发送给接收人,可以是email,也可以是企业微信,或者钉钉,也就是它整个的这个框架,分为这5块。
小结:
• Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
• ClientLibrary:客户端库,这些可以集成一些很多的语言中,比如使用JAVA开发的一个Web网站,那么可以集成JAVA的客户端,去暴露相关的指标,暴露自身的指标,但很多的业务指标需要开发去写的,
• Push Gateway:短期存储指标数据。主要用于临时性的任务
• Exporters:采集已有的第三方服务监控指标并暴露metrics,相当于一个采集端的agent,
• Alertmanager:告警
• Web UI:简单的Web控制台
数据模型
Prometheus将所有数据存储为时间序列;具有相同度量名称以及标签属于同一个指标。
每个时间序列都由度量标准名称和一组键值对(也成为标签)唯一标识。 也就是查询时
也会依据这些标签来查询和过滤,就是写PromQL时
时间序列格式:
二、K8S监控指标
Kubernetes本身监控
• Node资源利用率 :一般生产环境几十个node,几百个node去监控
• Node数量 :一般能监控到node,就能监控到它的数量了,因为它是一个实例,一个node能跑多少个项目,也是需要去评估的,整体资源率在一个什么样的状态,什么样的值,所以需要根据项目,跑的资源利用率,还有值做一个评估的,比如再跑一个项目,需要多少资源。
• Pods数量(Node):其实也是一样的,每个node上都跑多少pod,不过默认一个node上能跑110个pod,但大多数情况下不可能跑这么多,比如一个128G的内存,32核cpu,一个java的项目,一个分配2G,也就是能跑50-60个,一般机器,pod也就跑几十个,很少很少超过100个。
• 资源对象状态 :比如pod,service,deployment,job这些资源状态,做一个统计。
Pod监控
• Pod数量(项目):你的项目跑了多少个pod的数量,大概的利益率是多少,好评估一下这个项目跑了多少个资源占有多少资源,每个pod占了多少资源。
• 容器资源利用率 :每个容器消耗了多少资源,用了多少CPU,用了多少内存
• 应用程序:这个就是偏应用程序本身的指标了,这个一般在我们运维很难拿到的,所以在监控之前呢,需要开发去给你暴露出来,这里有很多客户端的集成,客户端库就是支持很多语言的,需要让开发做一些开发量将它集成进去,暴露这个应用程序的想知道的指标,然后纳入监控,如果开发部配合,基本运维很难做到这一块,除非自己写一个客户端程序,通过shell/python能不能从外部获取内部的工作情况,如果这个程序提供API的话,这个很容易做到。 
如果想监控node的资源,就可以放一个node_exporter,这是监控node资源的,node_exporter是Linux上的采集器,你放上去你就能采集到当前节点的CPU、内存、网络IO,等待都可以采集的。
如果想监控容器,k8s内部提供cAdvisor采集器,pod呀,容器都可以采集到这些指标,都是内置的,不需要单独部署,只知道怎么去访问这个Cadvisor就可以了。
如果想监控k8s资源对象,会部署一个kube-state-metrics这个服务,它会定时的API中获取到这些指标,帮你存取到Prometheus里,要是告警的话,通过Alertmanager发送给一些接收方,通过Grafana可视化展示。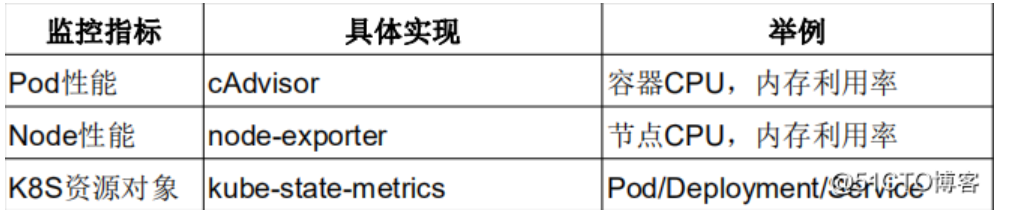
服务发现:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
三、在K8S中部署Prometheus+Grafana
文档有的yaml格式可能不对部署可能会出现问题
建议拉取我代码仓库的地址,拉取的时候请把你的公钥给我,不然拉取不下来
git clone git@gitee.com:zhaocheng172/prometheus.git
[root@k8s-master prometheus-k8s]# lsalertmanager-configmap.yaml OWNERSalertmanager-deployment.yaml prometheus-configmap.yamlalertmanager-pvc.yaml prometheus-rbac.yamlalertmanager-service.yaml prometheus-rules.yamlgrafana.yaml prometheus-service.yamlkube-state-metrics-deployment.yaml prometheus-statefulset-static-pv.yamlkube-state-metrics-rbac.yaml prometheus-statefulset.yamlkube-state-metrics-service.yaml README.mdnode_exporter.sh
现在先来创建rbac,因为部署它的主服务主进程要引用这几个服务
因为prometheus来连接你的API,从API中获取很多的指标
并且设置了绑定集群角色的权限,只能查看,不能修改
[root@k8s-master prometheus-k8s]# cat prometheus-rbac.yamlapiVersion: v1kind: ServiceAccountmetadata:name: prometheusnamespace: kube-systemlabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcile---apiVersion: rbac.authorization.k8s.io/v1beta1kind: ClusterRolemetadata:name: prometheuslabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcilerules:- apiGroups:- ""resources:- nodes- nodes/metrics- services- endpoints- podsverbs:- get- list- watch- apiGroups:- ""resources:- configmapsverbs:- get- nonResourceURLs:- "/metrics"verbs:- get---apiVersion: rbac.authorization.k8s.io/v1beta1kind: ClusterRoleBindingmetadata:name: prometheuslabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: ReconcileroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: prometheussubjects:- kind: ServiceAccountname: prometheusnamespace: kube-system[root@k8s-master prometheus-k8s]# kubectl create -f prometheus-rbac.yaml
现在创建一下configmap,
rule_files:- /etc/config/rules/*.rules
这是写入告警规则的目录,也就是这个configmap会挂载到普罗米修斯里面,让主进程读取这些配置
scrape_configs:- job_name: prometheusstatic_configs:- targets:- localhost:9090
下面这些都是来配置监控端的,job_name是分组,这是是监控它本身,下面还有监控node,我们会在node上起一个nodeport,这里修改要监控node节点
scrape_interval: 30s:这里采集的时间,每多少秒采集一次数据这里还有一个alerting的服务的名字alerting:alertmanagers:- static_configs:- targets: ["alertmanager:80"]
[root@k8s-master prometheus-k8s]# kubectl create -f prometheus-configmap.yaml[root@k8s-master prometheus-k8s]# cat prometheus-configmap.yaml# Prometheus configuration format https://prometheus.io/docs/prometheus/latest/configuration/configuration/apiVersion: v1kind: ConfigMapmetadata:name: prometheus-confignamespace: kube-systemlabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: EnsureExistsdata:prometheus.yml: |rule_files:- /etc/config/rules/*.rulesscrape_configs:- job_name: prometheusstatic_configs:- targets:- localhost:9090- job_name: kubernetes-nodesscrape_inteal: 30sstatic_configs:- targets:- 192.168.30.22:9100- 192.168.30.23:9100- job_name: kubernetes-apiserverskubernetes_sd_configs:- role: endpointsrelabel_configs:- action: keepregex: default;kubernetes;httpssource_labels:- __meta_kubernetes_namespace- __meta_kubernetes_service_name- __meta_kubernetes_endpoint_port_namescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtinsre_skip_verify: truebearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token- job_name: kubernetes-nodes-kubeletkubernetes_sd_configs:- role: noderelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtinsecure_skip_verify: truebearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token- job_name: kubernetes-nodes-cadvisorkubernetes_sd_configs:- role: noderelabel_configs:- action: lamapregex: __meta_kubernetes_node_label_(.+)- target_label: __metrics_path__replacement: /metrics/cadvisorscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtinsecure_skip_verify: truebearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token- job_name: kubernetes-service-endpointskubernetes_sd_configs:- role: endpointsrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_service_annotation_prometheus_io_scrape- action: replaceregex: (https?)source_labels:- _kubernetes_service_annotation_prometheus_io_schemetarget_label: __scheme__- action: replaceregex: (.+)source_labels:- __meta_kubernetes_service_annotation_prometheus_io_pathtarget_label: __metrics_path__- action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2source_labels:- __address__- __meta_kubernetes_service_annotation_prometheus_io_porttarget_label: __address__- action: labelmapregex: __meta_kubernetes_service_label_(.+)- action: replacesource_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- action: replacesource_labels:- __meta_kubernetes_service_nametarget_label: kubernetes_name- job_name: kubernetes-serviceskubernetes_sd_configs:- role: servicemetrics_path: /probeparams:module:- http_2xxrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_service_annotation_prometheus_io_probe- source_labels:- __address__target_label: __param_target- replacement: blackboxtarget_label: __address__- source_labels:- __param_targettarget_label: instance- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- source_labels:- __meta_kubernetes_service_nametarget_label: kubernetes_name- job_name: kubernetes-podskubernetes_sd_configs:- role: podrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_pod_annotation_prometheus_io_scrape- action: replaceregex: (.+)source_labels:- __meta_kubernetes_pod_annotation_prometheus_io_pathtarget_label: __metrics_path__- action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2source_labels:- __address__- __meta_kubernetes_pod_annotation_prometheus_io_porttarget_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- action: replacesource_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- action: replacesource_labels:- __meta_kubernetes_pod_nametarget_label: kubernetes_pod_namealerting:alertmanagers:- static_configs:- targets: ["alertmanager:80"]
再配置这个角色,这个就是配置告警规则的,这里分为两块告警规则,一个是通用的告警规则,适用所有的实例,如果实例要是挂了,然后发送告警,实例我们被监控端的agent,还有一个node角色,这个监控每个node的CPU、内存、磁盘利用率,在prometheus写告警值是通过promQL去写的,来查询一个数据来比对,如果符合这个比对的表达式,就是为真的情况下,去触发当前这条告警,比如就是下面这条,然后会将这条告警推送给alertmanager,它来处理这个信息的告警。
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
[root@k8s-master prometheus-k8s]# kubectl create -f prometheus-rules.yaml[root@k8s-master prometheus-k8s]# cat prometheus-rules.yamlapiVersion: v1kind: ConfigMapmetadata:name: prometheus-rulesnamespace: kube-systemdata:general.rules: |groups:- name: general.rulesrules:- alert: InstanceDownexpr: up == 0for: 1mlabels:severity: errorannotations:summary: "Instance {{ $labels.instance }} 停止工作"description: "{{ instance }} job {{ labels.job }} 已经停止5分钟以上."node.rules: |groups:- name: node.rulesrules:- alert: NodeFilesystemUsageexpr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{ext4|xfs"} * 100) > 80for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高"description: "{{ $labels.instance }}: {{ $labels.mountpoint }} 分区使用大于80% (当前值: {{ $value }})"- alert: NodeMemoryUsageexpr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} 内存使用率过高"description: "{{ $labels.instance }}内存使用大于80% (当前值: {{ $value }})"- alert: NodeCPUUsageexpr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 60for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} CPU使用率过高"description: "{{ $labels.instance }}CPU使用大于60% (当前值: {{ $value }})"
然后再部署一下statefulset
name: prometheus-server-configmap-reload:这条主要是来重新加载prometheus的配置文件,下面就是prometheus的主服务端了,用来启动prometheus的服务,另外就是/data目录做持久化,配置文件使用configmap,告警的规则也从configmap存储,这里使用还是我们的动态创建pv的存储类,名字子managed-nfs-storage
[root@k8s-master prometheus-k8s]# cat prometheus-statefulset.yamlapiVersion: apps/v1kind: StatefulSetmetadata:name: prometheusnamespace: kube-systemlabels:k8s-app: prometheuskubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcileversion: v2.2.1spec:serviceName: "prometheus"replicas: 1podManagementPolicy: "Parallel"updateStrategy:type: "RollingUpdate"selector:matchLabels:k8s-app: prometheustemplate:metadata:labels:k8s-app: prometheusannotations:scheduler.alpha.kubernetes.io/critical-pod: ''spec:priorityClassName: system-cluster-criticalserviceAccountName: prometheusinitContainers:- name: "init-chown-data"image: "busybox:latest"imagePullPolicy: "IfNotPresent"command: ["chown", "-R", "65534:65534", "/data"]volumeMounts:- name: prometheus-datamountPath: /datasubPath: ""containers:- name: prometheus-server-configmap-reloadimage: "jimmidyson/configmap-reload:v0.1"imagePullPolicy: "IfNotPresent"args:- --volume-dir=/etc/config- --webhook-url=http://localhost:9090/-/reloadvolumeMounts:- name: config-volumemountPath: /etc/configreadOnly: trueresources:limits:cpu: 10mmemory: 10Mirequests:cpu: 10mmemory: 10Mi- name: prometheus-serverimage: "prom/prometheus:v2.2.1"imagePullPolicy: "IfNotPresent"args:- --config.file=/etc/config/prometheus.yml- --storage.tsdb.path=/data- --web.console.libraries=/etc/prometheus/console_libraries- --web.console.templates=/etc/prometheus/consoles- --web.enable-lifecycleports:- containerPort: 9090readinessProbe:httpGet:path: /-/readyport: 9090initialDelaySeconds: 30timeoutSeconds: 30livenessProbe:httpGet:path: /-/healthyport: 9090initialDelaySeconds: 30timeoutSeconds: 30# based on 10 running nodes with 30 pods eachresources:limits:cpu: 200mmemory: 1000Mirequests:cpu: 200mmemory: 1000MivolumeMounts:- name: config-volumemountPath: /etc/config- name: prometheus-datamountPath: /datasubPath: ""- name: prometheus-rulesmountPath: /etc/config/rulesterminationGracePeriodSeconds: 300volumes:- name: config-volumeconfigMap:name: prometheus-config- name: prometheus-rulesconfigMap:name: prometheus-rulesvolumeClaimTemplates:- metadata:name: prometheus-dataspec:storageClassName: managed-nfs-storageaccessModes:- ReadWriteOnceresources:requests:storage: "16Gi"
这里呢因为我之前就把nfs动态创建pvc的搭建好了,使用的nfs做的网络存储,所以这里没有演示,可以看我之前的博客,然后这里已经创建好了
[root@k8s-master prometheus-k8s]# kubectl get pod -n kube-systemNAME READY STATUS RESTARTS AGEcoredns-bccdc95cf-kqxwv 1/1 Running 3 2d4hcoredns-bccdc95cf-nwkbp 1/1 Running 3 2d4hetcd-k8s-master 1/1 Running 2 2d4hkube-apiserver-k8s-master 1/1 Running 2 2d4hkube-controller-manager-k8s-master 1/1 Running 5 2d4hkube-flannel-ds-amd64-dc5z9 1/1 Running 1 2d4hkube-flannel-ds-amd64-jm2jz 1/1 Running 1 2d4hkube-flannel-ds-amd64-z6tt2 1/1 Running 1 2d4hkube-proxy-9ltx7 1/1 Running 2 2d4hkube-proxy-lnzrj 1/1 Running 1 2d4hkube-proxy-v7dqm 1/1 Running 1 2d4hkube-scheduler-k8s-master 1/1 Running 5 2d4hprometheus-0 2/2 Running 0 3m3s
然后看一下service,我们使用Nodeport类型,端口使用9090。当然也可以使用ingress暴露出去
[root@k8s-master prometheus-k8s]# kubectl create -f prometheus-service.yaml[root@k8s-master prometheus-k8s]# kubectl get svc -n kube-systemNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkube-dns ClusterIP 10.1.0.10 <none> 53/UDP,53/TCP,9153/TCP 2d4hprometheus NodePort 10.1.58.1 <none> 9090:32276/TCP 22s
一个非常简洁的UI页面,没有什么好的功能,很难满足企业UI的要求的,不过只在这里做一个调试,上面主要写promQL的表达式的,怎么去查这个数据,就好比mysql的SQL,去查询出你的数据,可以在status里面去进行调试,而里面的config配置文件我们增加了告警预值,增加了对nodeport的支持还有指定了alertmanager的地址,然后rules,我们也是规划了两块,一个是通用规则,一个是node节点规则,主要监控三大块,内存、磁盘、CPU
现在查看CPU的利用率,一般都是使用Grafana去展示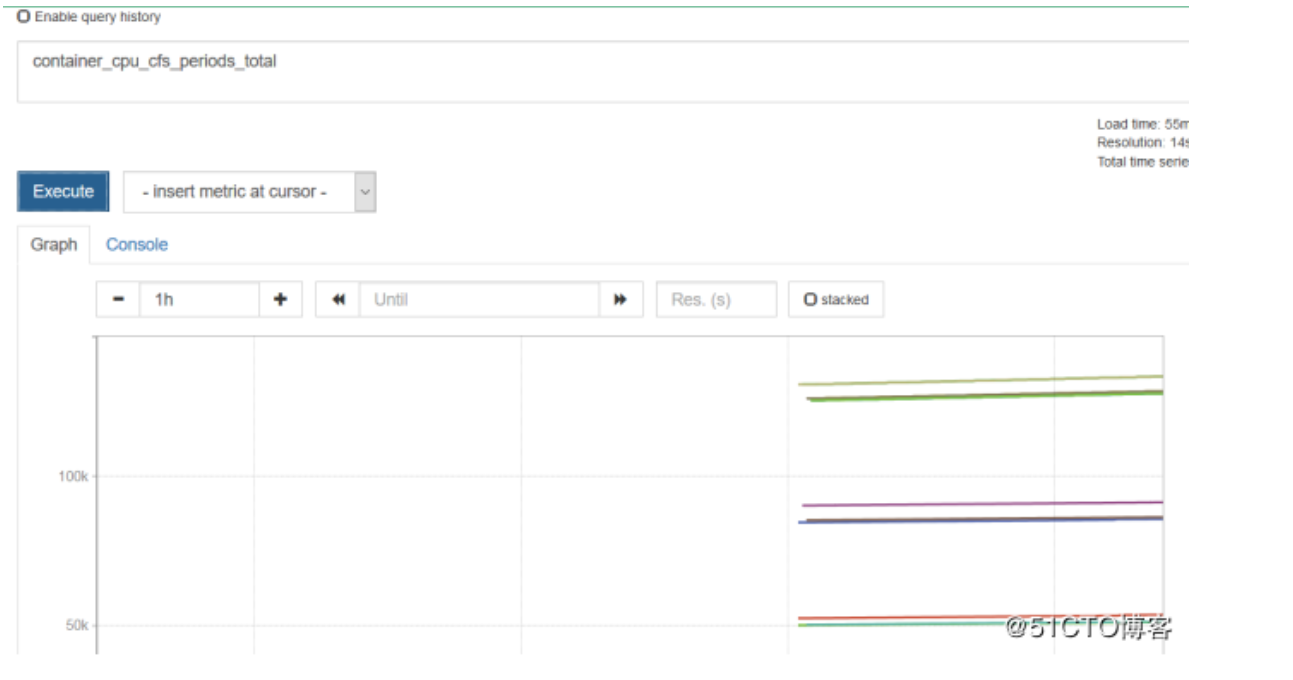
五、在K8S平台部署Grafana
这里也是用statefulset去做的,也是自动创建pv,定义的端口是30007
```shell [root@k8s-master prometheus-k8s]# cat grafana.yaml apiVersion: apps/v1 kind: StatefulSet metadata: name: grafana namespace: kube-system spec: serviceName: “grafana” replicas: 1 selector: matchLabels:app: grafana
template: metadata:
labels:app: grafana
spec:
containers:- name: grafanaimage: grafana/grafanaports:- containerPort: 3000protocol: TCPresources:limits:cpu: 100mmemory: 256Mirequests:cpu: 100mmemory: 256MivolumeMounts:- name: grafana-datamountPath: /var/lib/grafanasubPath: grafanasecurityContext:fsGroup: 472runAsUser: 472
volumeClaimTemplates:
- metadata:
name: grafana-data
spec:
storageClassName: managed-nfs-storage
accessModes:
resources:- ReadWriteOnce
requests:storage: "1Gi"
apiVersion: v1 kind: Service metadata: name: grafana namespace: kube-system spec: type: NodePort ports:
- port : 80
targetPort: 3000
nodePort: 30007
selector:
app: grafana
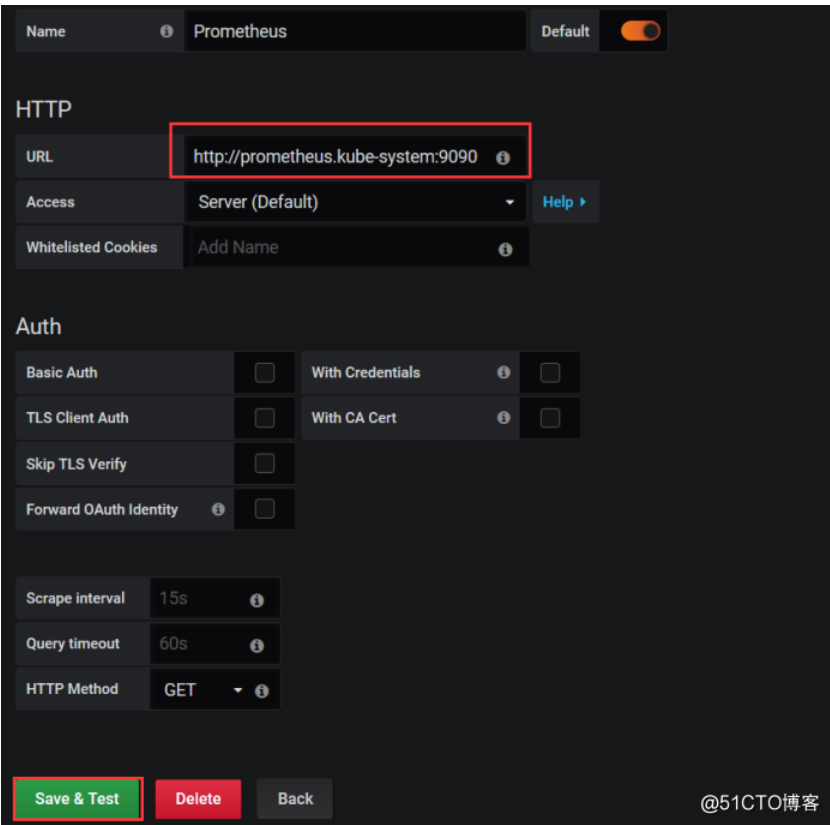
默认账号密码都是admin <br /><br /> 首先我们将prometheus做为数据源,添加一个数据源并选择prometheus <br /><br /> 添加一个URL地址,可以写你访问UI页面的地址也可以写service的地址shell [root@k8s-master prometheus-k8s]# kubectl get svc -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE grafana NodePort 10.1.246.14380:30007/TCP 11m kube-dns ClusterIP 10.1.0.10 53/UDP,53/TCP,9153/TCP 2d5h prometheus NodePort 10.1.58.1 9090:32276/TCP 40m
<br /> 查看数据源已经有一个了 <br />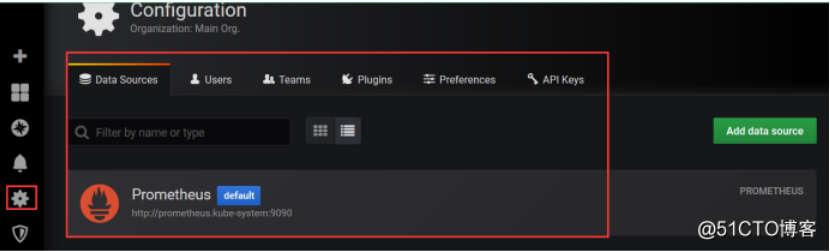<a name="VZf79"></a>## 六、监控K8S集群中Pod、Node、资源对象<a name="wqZk8"></a>### Pod<br />kubelet的节点使用cAdvisor提供的metrics接口获取该节点所有Pod和容器相关的性能指标数据。<br />也就是kubelet会暴露两个接口地址:<br />[https://NodeIP:10255/metrics/cadvisor](https://NodeIP:10255/metrics/cadvisor) 只读<br />[https://NodeIP:10250/metrics/cadvisor](https://NodeIP:10250/metrics/cadvisor) kubelet的API,授权没问题的话可以做任何操作<br />可以在node节点去看一下,这个端口主要用作于访问kubelet的一些API鉴权,和提供一些cAdvisor指标用的,咱们部署prometheus的时候,就已经开始收集cAdvisor数据了,为什么会采集,因为prometheus配置文件就已经去定义怎么去采集数据了```shell[root@k8s-node1 ~]# netstat -antp |grep 10250tcp6 0 0 :::10250 :::* LISTEN 107557/kubelettcp6 0 0 192.168.30.22:10250 192.168.30.23:58692 ESTABLISHED 107557/kubelettcp6 0 0 192.168.30.22:10250 192.168.30.23:46555 ESTABLISHED 107557/kubelet
Node
使用node_exporter收集器采集节点资源利用率。
https://github.com/prometheus/node_exporter
使用文档:https://prometheus.io/docs/guides/node-exporter/
资源对象
kube-state-metrics采集了k8s中各种资源对象的状态信息,
https://github.com/kubernetes/kube-state-metrics
现在导入一个能够查看pod数据的模版,也就是通过模版更能直观去展示这些数据
七、使用Grafana可视化展示Prometheus监控数据
推荐模板: 也就是在grafana共享中心里面的,也就是别人写的模版上传到这里库里面的,自己也可以写,写完上传上去,别人也可以访问到,下面是模版的id,只要获取这个ID,就能使用这个模版了,只要这个模版,后端提供执行promeQL,只要有数据就能帮你展示出来
Grafana.com
• 集群资源监控:3119
• 资源状态监控 :6417
• Node监控 :9276
现在使用这个3319模版,来展示我们的集群的资源,打开添加模版,选择dashboard 
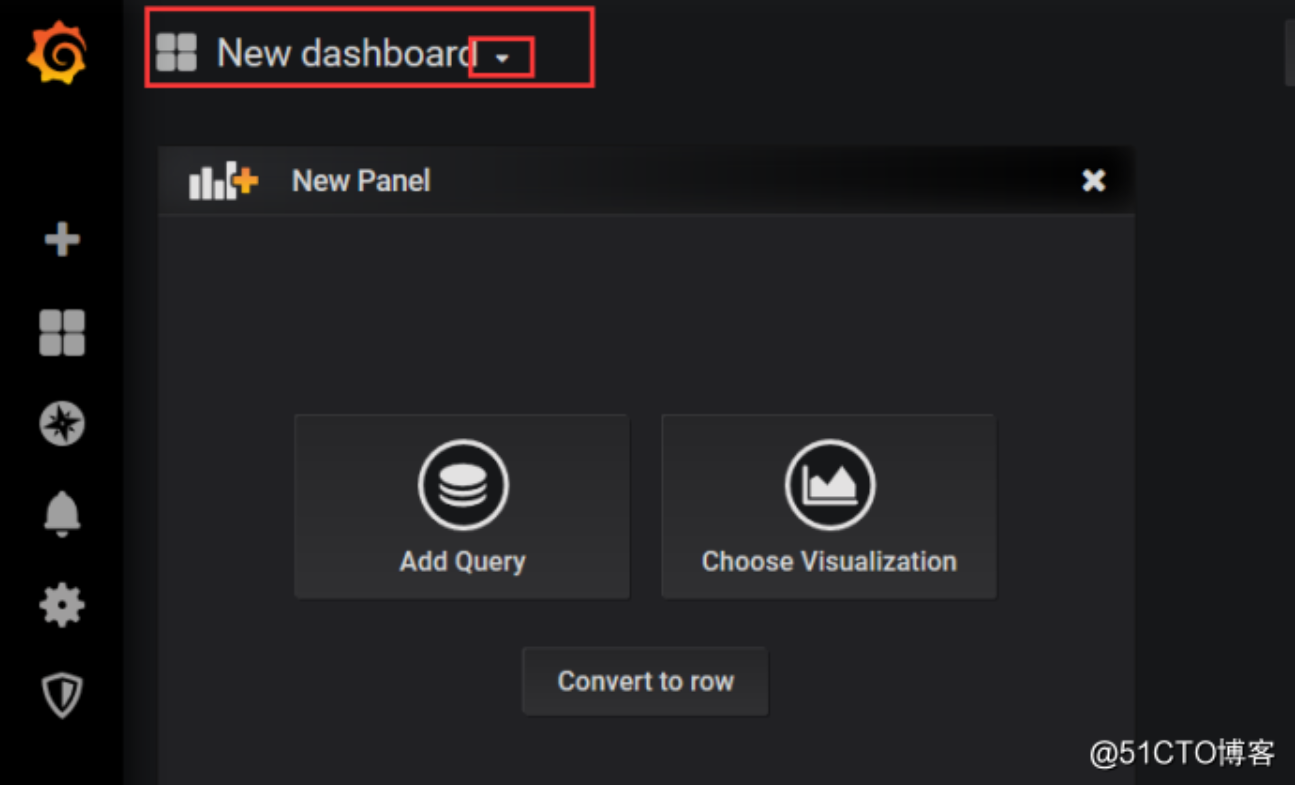
选择导入模版 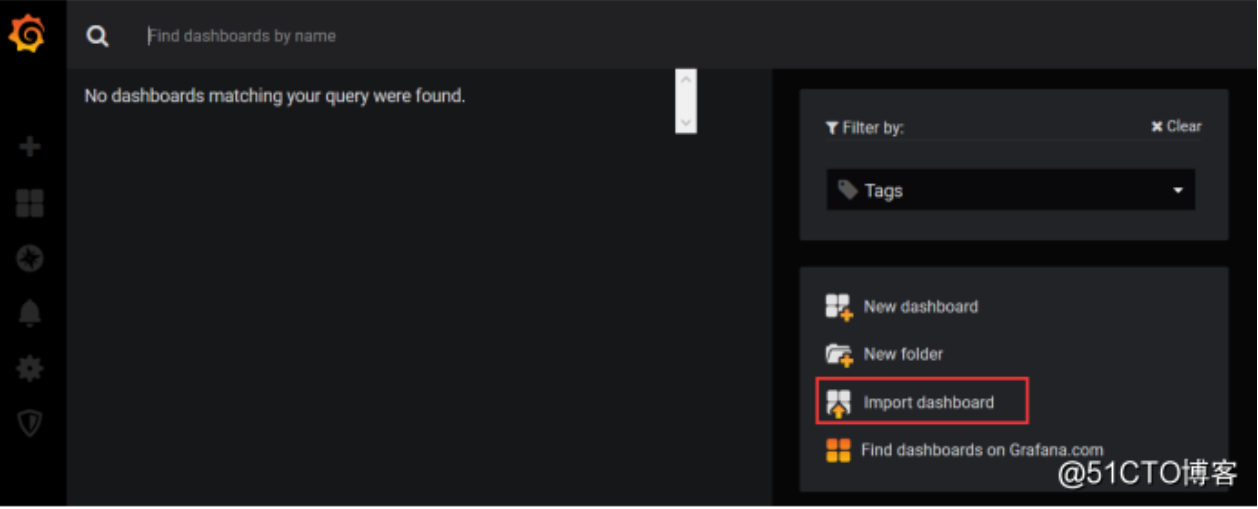
写入3119,它能自动帮你识别这个模版的名字 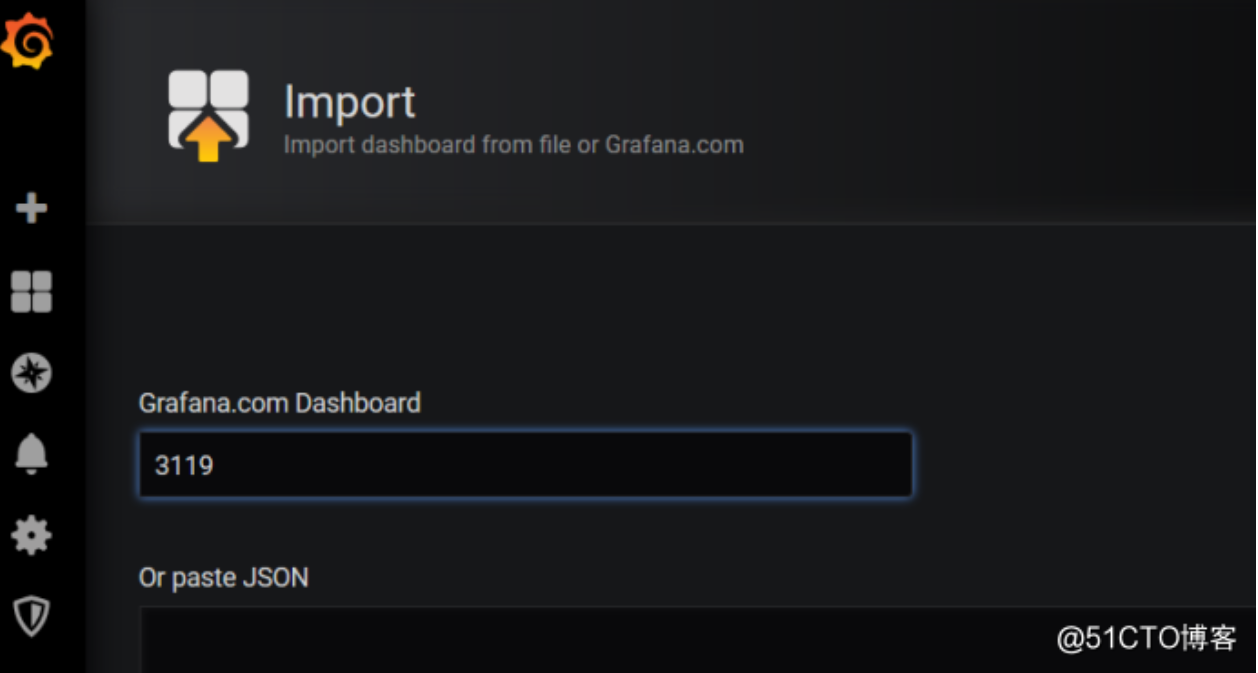
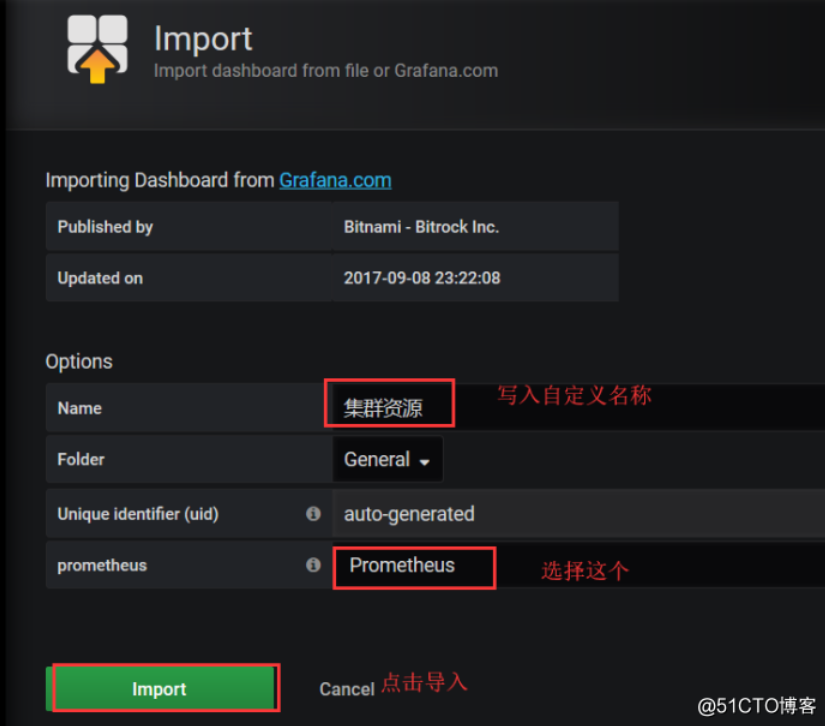
因为这些都有数据了,所以就直接能查看到所有集群的资源
下面这个是网络IO的图表,一个是接收,一个是发送 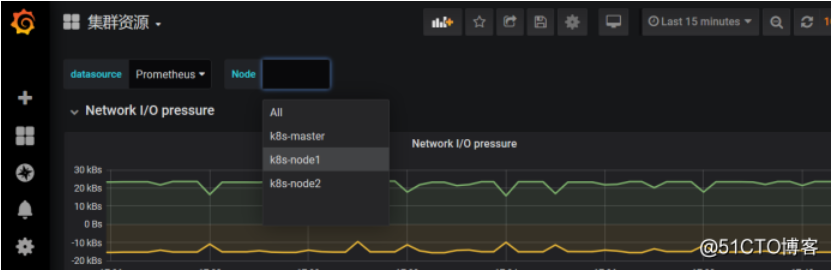
下面这个是集群内存的使用情况
这里是4G,只识别了3.84G,使用2.26G,CPU是双核,使用了0.11,右边这个是集群文件系统,但是没有显示出来,我们可以看一下它PromQL怎么写的,把这个写promQL拿到promQL Ui上测试一下有没有数据,一般是没有匹配到数据导致的 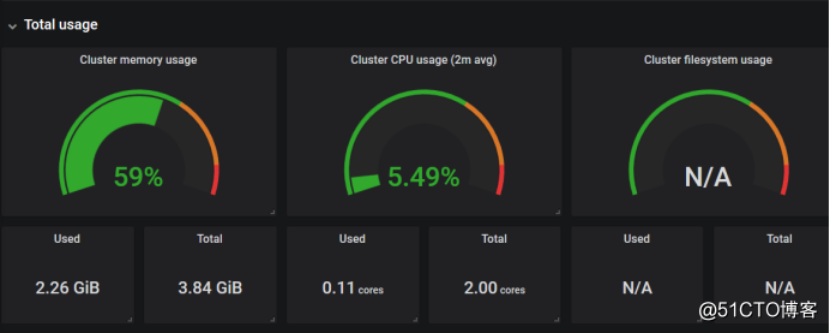
来看一下这个怎么解决 
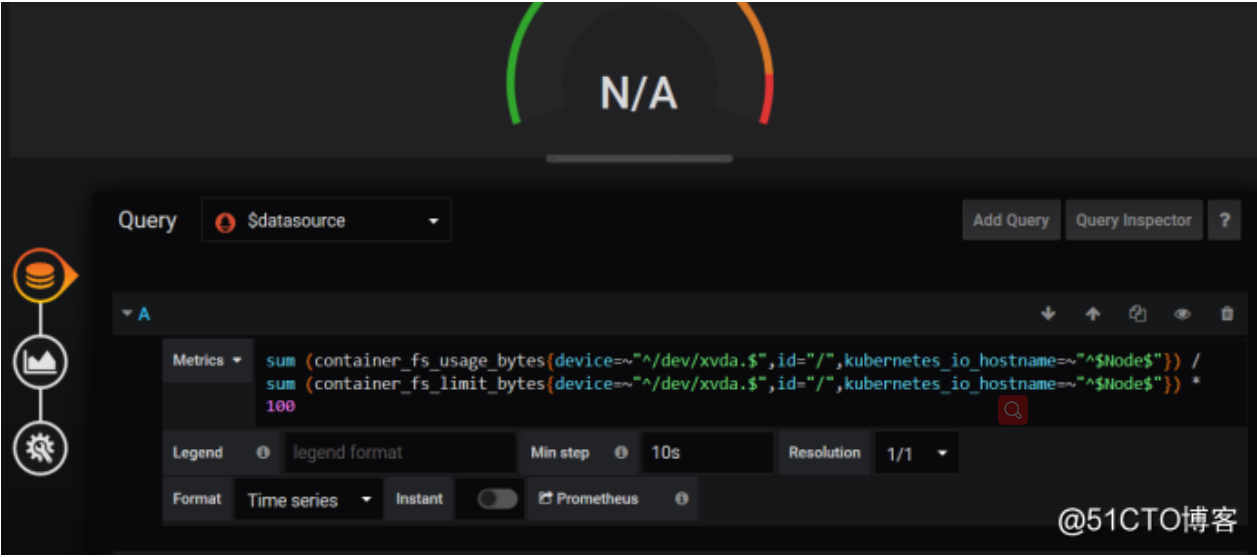
拿这个数据去比对,找到数据,一点一点去删除,现在我们找到数据了,这里是匹配的你节点的名称,根据这个我们去找,因为这个模版是别人上传的,我们自己用肯定根据自己的内容去匹配,这里可以去匹配相关的promQL,然后改一下我们grafana的promQL,现在是获取到数据了 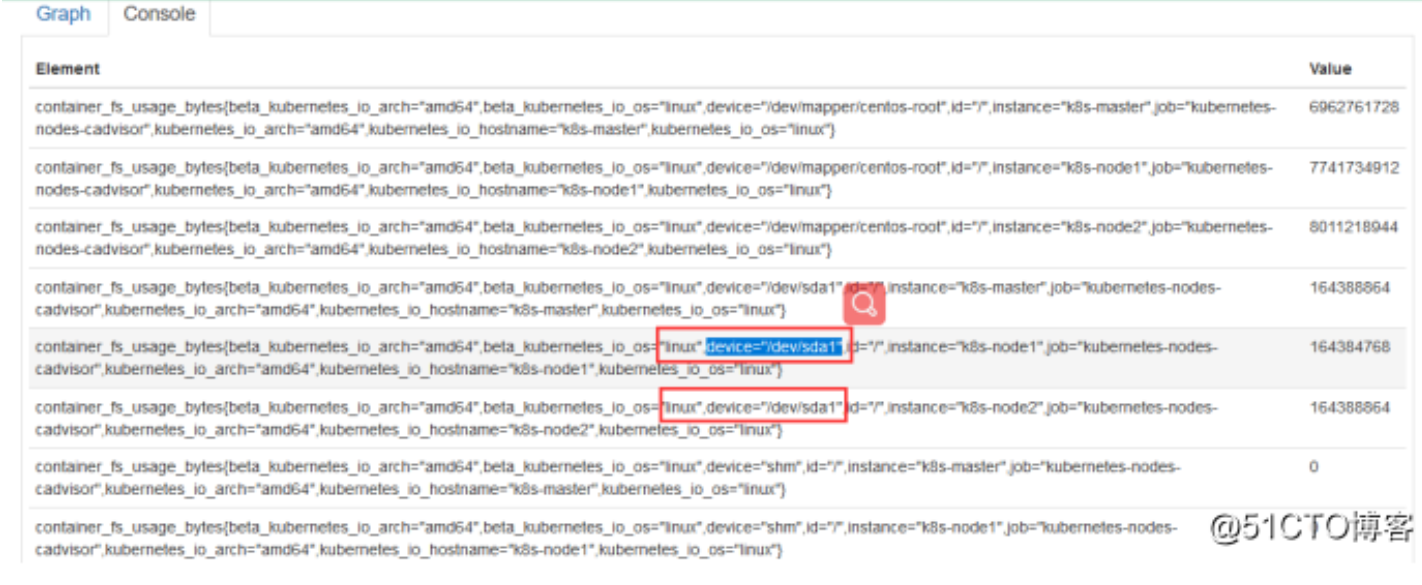
另外我们可能还做一些其他的模版的监控,可以在它Grafana的官方去找一些模版,但是有的可能不能用,自己需要去修改,比如输入k8s,这里是监控etcd集群的 
Node
使用node_exporter收集器采集节点资源利用率。
https://github.com/prometheus/node_exporter
使用文档:https://prometheus.io/docs/guides/node-exporter/
这个目前没有使用pod去部署,因为没有展示到一个磁盘的使用率,官方给出了一个statfulset的方式,无法展示磁盘,不过也可以以一个守护进程的方式部署在node 节点上,这个部署也比较简单,以二进制的方式去部署,在宿主机上启动一个就可以了
看一下这个脚本,是以systemd去过滤服务启动监控的状态,如果守护进程挂了话,也会被Prometheus采集到也就是下面这个参数
--collector.systemd --collector.systemd.unit-whitelist=(docker|kubelet|kube-proxy|flanneld).service
[root@k8s-node1 ~]# bash node_exporter.sh#!/bin/bashwget https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gztar zxf node_exporter-0.17.0.linux-amd64.tar.gzmv node_exporter-0.17.0.linux-amd64 /usr/local/node_exportercat <<EOF >/usr/lib/systemd/system/node_exporter.service[Unit]Description=https://prometheus.io[Service]Restart=on-failureExecStart=/usr/local/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|kubelet|kube-proxy|flanneld).service[Install]WantedBy=multi-user.targetEOFsystemctl daemon-reloadsystemctl enable node_exportersystemctl restart node_exporter
prometheus是主动的去采集资源的指标,而不是被动的被监控端推送这些数据
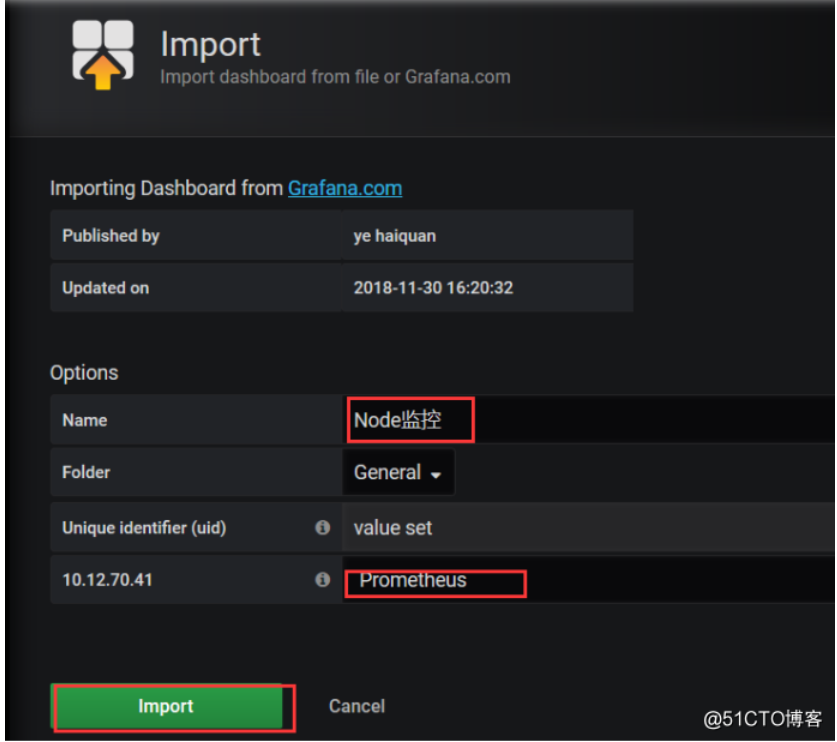
然后使用的是9276这个模版,我们可以先让这个模版导入进来 
[root@k8s-node1 ~]# ps -ef |grep node_exroot 5275 1 0 21:59 ? 00:00:03 /usr/local/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|kubelet|kube-proxy|flanneld).serviceroot 7393 81364 0 22:15 pts/1 00:00:00 grep --color=auto node_ex
选择nodes ,这里可以看到两个节点的资源状态 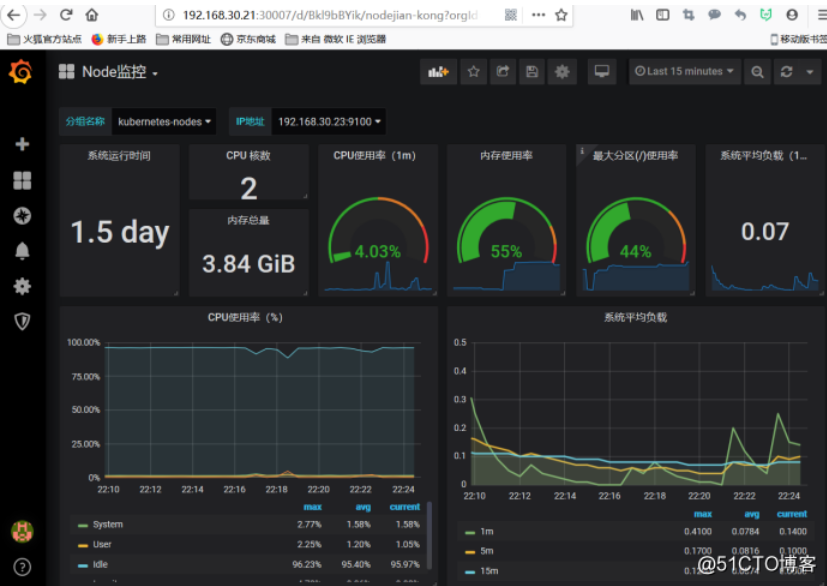
获取网络带宽失败,然后我们可以去测这个promeQL,一般这个情况就是查看网卡的接口名称,有的是eth0,有的是ens32,ens33,这个根据自己的去写 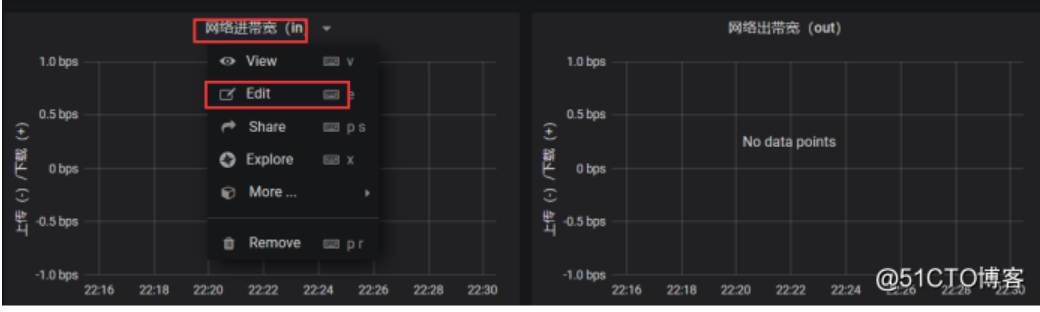
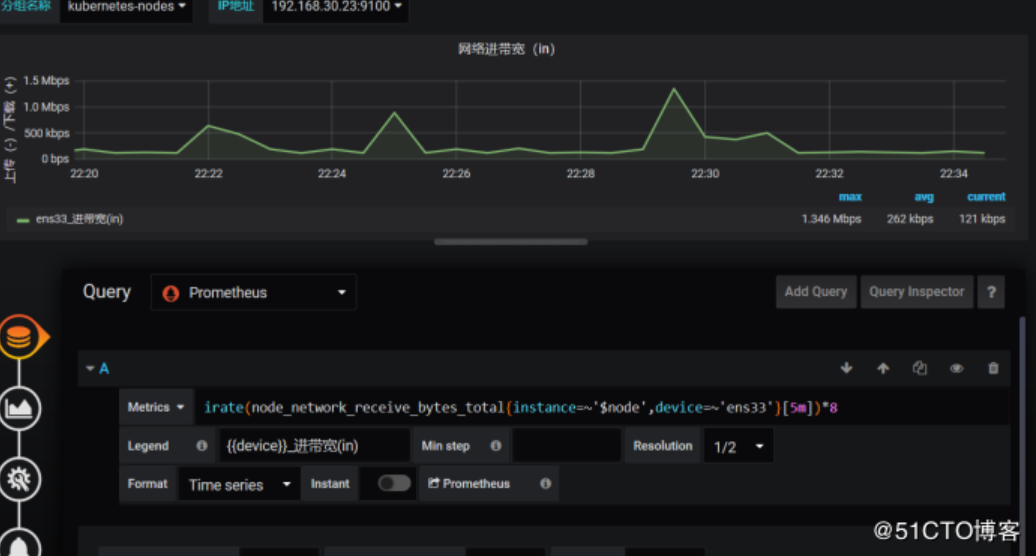
点击这个保存 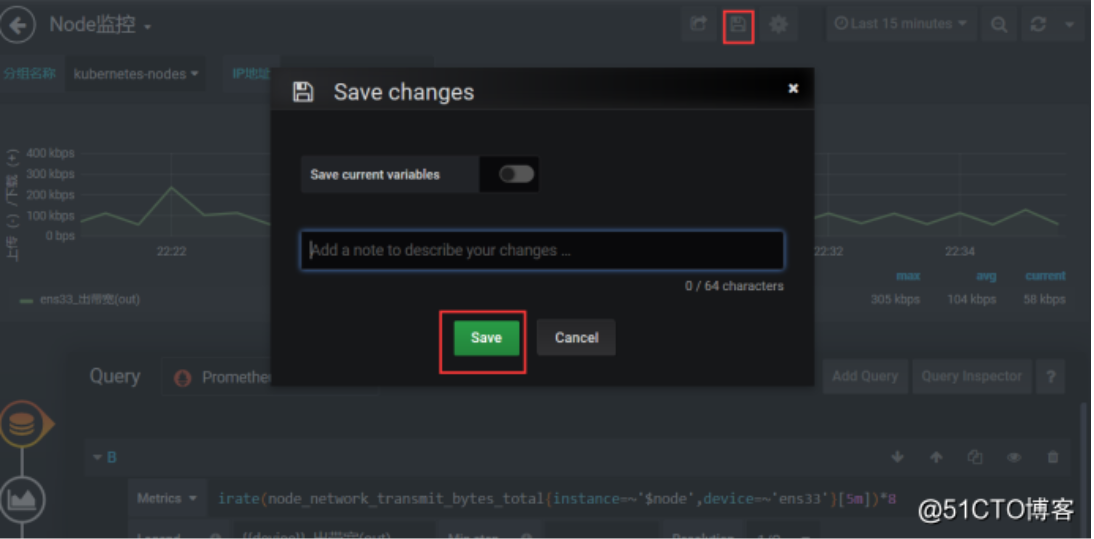
现在就有了 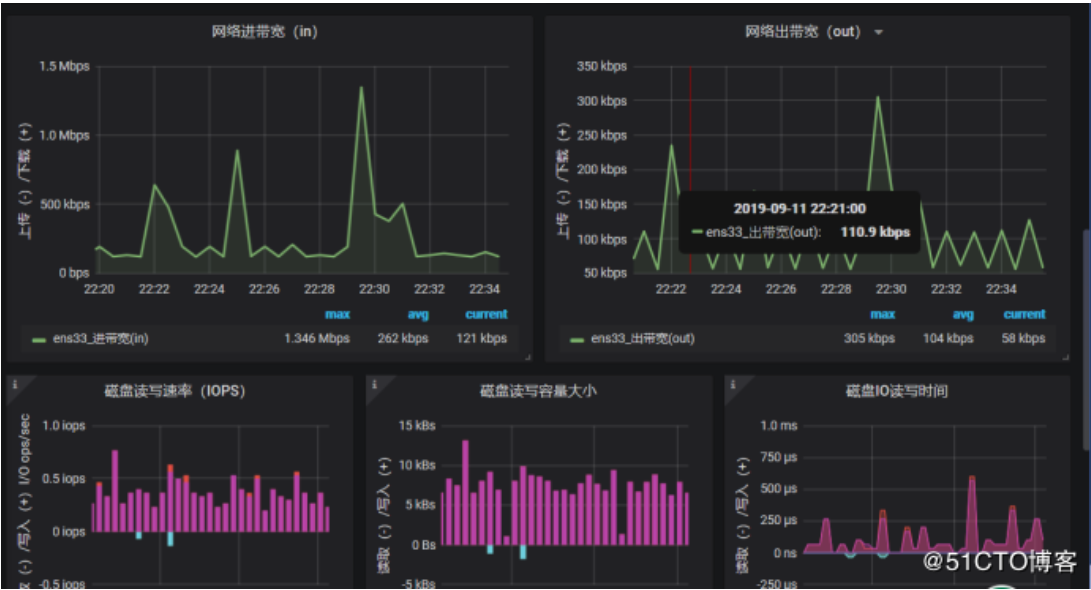
K8s资源对象的监控
具体实现 kube-state-metrics ,这种类型pod/deployment/service
这个组件是官方开发的,通过API去获取k8s资源的状态,通过metrics来完成数据的采集。比如副本数是多少,当前是什么状态了,是获取这些的
当然github上都有这些,只需要把国外的源换成国外的就可以了,或者换成我的,我已经把镜像上传到docker hub上了。
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
创建rbac授权规则
[root@k8s-master prometheus-k8s]# cat kube-state-metrics-rbac.yamlapiVersion: v1kind: ServiceAccountmetadata:name: kube-state-metricsnamespace: kube-systemlabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcile---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:name: kube-state-metricslabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcilerules:- apiGroups: [""]resources:- configmaps- secrets- nodes- pods- services- resourcequotas- replicationcontrollers- limitranges- persistentvolumeclaims- persistentvolumes- namespaces- endpointsverbs: ["list", "watch"]- apiGroups: ["extensions"]resources:- daemonsets- deployments- replicasetsverbs: ["list", "watch"]- apiGroups: ["apps"]resources:- statefulsetsverbs: ["list", "watch"]- apiGroups: ["batch"]resources:- cronjobs- jobsverbs: ["list", "watch"]- apiGroups: ["autoscaling"]resources:- horizontalpodautoscalersverbs: ["list", "watch"]---apiVersion: rbac.authorization.k8s.io/v1kind: Rolemetadata:name: kube-state-metrics-resizernamespace: kube-systemlabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcilerules:- apiGroups: [""]resources:- podsverbs: ["get"]- apiGroups: ["extensions"]resources:- deploymentsresourceNames: ["kube-state-metrics"]verbs: ["get", "update"]---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:name: kube-state-metricslabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: ReconcileroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: kube-state-metricssubjects:- kind: ServiceAccountname: kube-state-metricsnamespace: kube-system---apiVersion: rbac.authorization.k8s.io/v1kind: RoleBindingmetadata:name: kube-state-metricsnamespace: kube-systemlabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: ReconcileroleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: kube-state-metrics-resizersubjects:- kind: ServiceAccountname: kube-state-metricsnamespace: kube-system
创建deployment
[root@k8s-master prometheus-k8s]# cat kube-state-metrics-deployment.yamlapiVersion: apps/v1kind: Deploymentmetadata:name: kube-state-metricsnamespace: kube-systemlabels:k8s-app: kube-state-metricskubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcileversion: v1.3.0spec:selector:matchLabels:k8s-app: kube-state-metricsversion: v1.3.0replicas: 1template:metadata:labels:k8s-app: kube-state-metricsversion: v1.3.0annotations:scheduler.alpha.kubernetes.io/critical-pod: ''spec:priorityClassName: system-cluster-criticalserviceAccountName: kube-state-metricscontainers:- name: kube-state-metricsimage: zhaocheng172/kube-state-metrics:v1.3.0ports:- name: http-metricscontainerPort: 8080- name: telemetrycontainerPort: 8081readinessProbe:httpGet:path: /healthzport: 8080initialDelaySeconds: 5timeoutSeconds: 5- name: addon-resizerimage: zhaocheng172/addon-resizer:1.8.3resources:limits:cpu: 100mmemory: 30Mirequests:cpu: 100mmemory: 30Mienv:- name: MY_POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: MY_POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespacevolumeMounts:- name: config-volumemountPath: /etc/configcommand:- /pod_nanny- --config-dir=/etc/config- --container=kube-state-metrics- --cpu=100m- --extra-cpu=1m- --memory=100Mi- --extra-memory=2Mi- --threshold=5- --deployment=kube-state-metricsvolumes:- name: config-volumeconfigMap:name: kube-state-metrics-config---# Config map for resource configuration.apiVersion: v1kind: ConfigMapmetadata:name: kube-state-metrics-confignamespace: kube-systemlabels:k8s-app: kube-state-metricskubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconciledata:NannyConfiguration: |-apiVersion: nannyconfig/v1alpha1kind: NannyConfiguration
创建暴露的端口,这里使用的是service
[root@k8s-master prometheus-k8s]# cat kube-state-metrics-service.yamlapiVersion: v1kind: Servicemetadata:name: kube-state-metricsnamespace: kube-systemlabels:kubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/name: "kube-state-metrics"annotations:prometheus.io/scrape: 'true'spec:ports:- name: http-metricsport: 8080targetPort: http-metricsprotocol: TCP- name: telemetryport: 8081targetPort: telemetryprotocol: TCPselector:k8s-app: kube-state-metrics
部署成功之后,导入模版就能监控到我们的数据
[root@k8s-master prometheus-k8s]# kubectl get pod,svc -n kube-system
NAME READY STATUS RESTARTS AGE
pod/coredns-bccdc95cf-kqxwv 1/1 Running 3 2d9h
pod/coredns-bccdc95cf-nwkbp 1/1 Running 3 2d9h
pod/etcd-k8s-master 1/1 Running 2 2d9h
pod/grafana-0 1/1 Running 0 4h50m
pod/kube-apiserver-k8s-master 1/1 Running 2 2d9h
pod/kube-controller-manager-k8s-master 1/1 Running 5 2d9h
pod/kube-flannel-ds-amd64-dc5z9 1/1 Running 1 2d9h
pod/kube-flannel-ds-amd64-jm2jz 1/1 Running 1 2d9h
pod/kube-flannel-ds-amd64-z6tt2 1/1 Running 1 2d9h
pod/kube-proxy-9ltx7 1/1 Running 2 2d9h
pod/kube-proxy-lnzrj 1/1 Running 1 2d9h
pod/kube-proxy-v7dqm 1/1 Running 1 2d9h
pod/kube-scheduler-k8s-master 1/1 Running 5 2d9h
pod/kube-state-metrics-6474469878-6kpxv 1/2 Running 0 4s
pod/kube-state-metrics-854b85d88-zl777 2/2 Running 0 35s
pod/prometheus-0 2/2 Running 0 5h30m
还是刚才步骤一样,导入一个6417的模版 
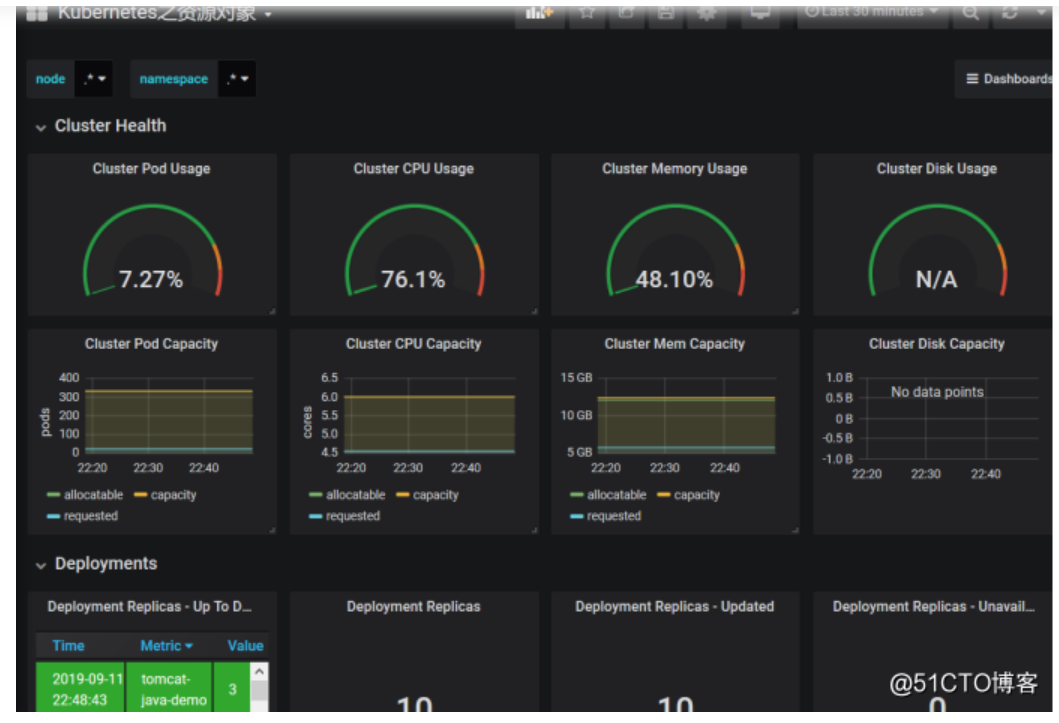
数据现在已经展示出来了,它会从target里面获取到这些数据,也就是这个来提供的,由prometheus自动的发现了。它这个发现是根据里面的一个注解来获取的,也就是在service里面
annotations:
prometheus.io/scrape: ‘true’
也就是声明了部署了哪些应用,可以被prometheus去自动的发现,如果加这条规则,prometheus会自动把这些带注解的监控到,也就是自己部署的应用,并提供相应的指标,也能自动发现这些状态。 
磁盘这里需要更改一个因为这里更新了,添加bytes 

下面这里是pod的容量,最大可以创建的数量,也就是kubelet去限制的,总共一个节点可以创建330个pod,已经分配24个。 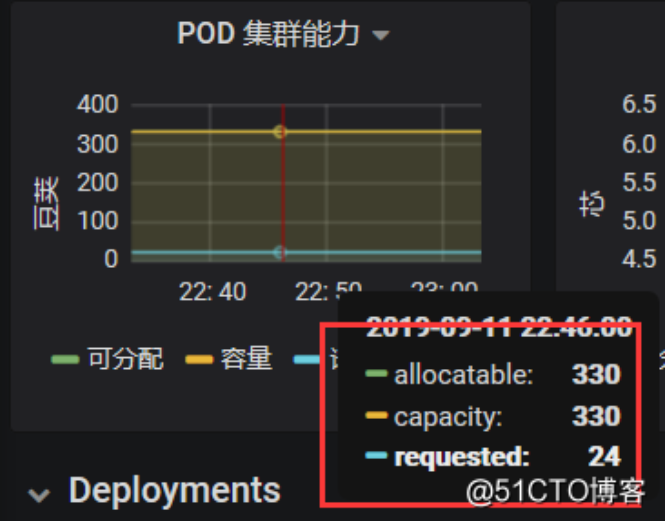
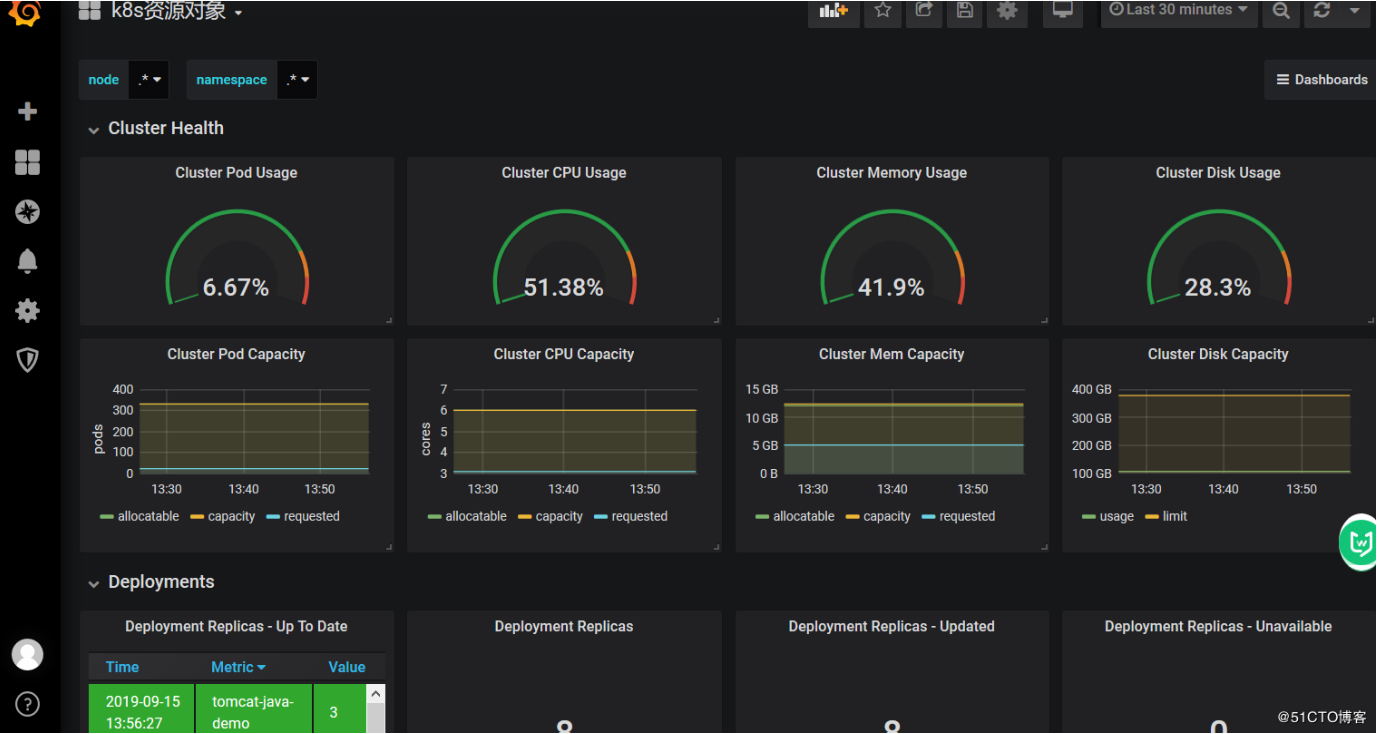
小结:
所以有了这些监控,基本上就能了解k8s的基本资源的使用状态了
八、告警规则与告警通知
在K8S中部署Alertmanager
说在前面的话,在k8s使用告警使用的是Alertmanager,先定义监控预值的规则,比如node的内存到达60%,才能告警,先定义好这些规则,如果prometheus采集的指标,匹配到这个规则,就是为真的话,它会发送告警,会将这个个告警信息推送给
Alertmanager,Alertmanager经过一系列的处理,最终发送到告警人手上,可以是webhook,email,钉钉,企业微信,目前我们拿email来做以下实例,企业微信需要注册企业的一些相关信息营业执照等,而webhook需要对接第三方的系统调一个接口去传值,email默认都支持,prometheus原生是不支持钉钉的,如果想支持的话,需要找第三方,做这个数据转换的组件。因为promethes传入的数据,它与钉钉传入的数据是不匹配的,所有有中间的程序数据之间进行转换,现在也有开源的可以去实现。
基本流程就行这样的,我们定义的规则都是在prometheus中 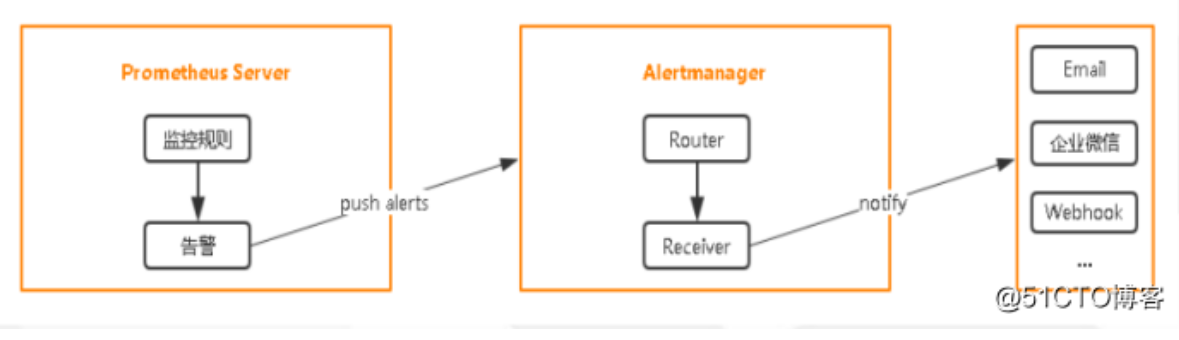
在K8S中部署Alertmanager
- 部署Alertmanager
- 配置Prometheus与Alertmanager通信
- 配置告警
- prometheus指定rules目录
- configmap存储告警规则
- configmap挂载到容器rules目录
- 增加alertmanager告警配置
这里是定义谁发送这个告警信息的,谁接收这个邮件
[root@k8s-master prometheus-k8s]# vim alertmanager-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
alertmanager.yml: |
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'baojingtongzhi@163.com'
smtp_auth_username: 'baojingtongzhi@163.com'
smtp_auth_password: 'liang123'
receivers:
- name: default-receiver
email_configs:
- to: "17733661341@163.com"
route:
group_interval: 1m
group_wait: 10s
receiver: default-receiver
repeat_interval: 1m
[root@k8s-master prometheus-k8s]# cat alertmanager-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: kube-system
labels:
k8s-app: alertmanager
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v0.14.0
spec:
replicas: 1
selector:
matchLabels:
k8s-app: alertmanager
version: v0.14.0
template:
metadata:
labels:
k8s-app: alertmanager
version: v0.14.0
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
containers:
- name: prometheus-alertmanager
image: "prom/alertmanager:v0.14.0"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/alertmanager.yml
- --storage.path=/data
- --web.external-url=/
ports:
- containerPort: 9093
readinessProbe:
httpGet:
path: /#/status
port: 9093
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: storage-volume
mountPath: "/data"
subPath: ""
resources:
limits:
cpu: 10m
memory: 50Mi
requests:
cpu: 10m
memory: 50Mi
- name: prometheus-alertmanager-configmap-reload
image: "jimmidyson/configmap-reload:v0.1"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9093/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: config-volume
configMap:
name: alertmanager-config
- name: storage-volume
persistentVolumeClaim:
claimName: alertmanager
查看我们的pvc这里也是使用的我们的自动供给managed-nfs-storage
[root@k8s-master prometheus-k8s]# cat alertmanager-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "2Gi"
这里使用的是类型为cluster IP
[root@k8s-master prometheus-k8s]# cat alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Alertmanager"
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9093
selector:
k8s-app: alertmanager
type: "ClusterIP"
然后把我们的资源都创建好
[root@k8s-master prometheus-k8s]# kubectl create -f alertmanager-configmap.yaml
[root@k8s-master prometheus-k8s]# kubectl create -f alertmanager-deployment.yaml
[root@k8s-master prometheus-k8s]# kubectl create -f alertmanager-pvc.yaml
[root@k8s-master prometheus-k8s]# kubectl create -f alertmanager-service.yaml
[root@k8s-master prometheus-k8s]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
alertmanager-5d75d5688f-xw2qg 2/2 Running 0 66s
coredns-bccdc95cf-kqxwv 1/1 Running 2 6d
coredns-bccdc95cf-nwkbp 1/1 Running 2 6d
etcd-k8s-master 1/1 Running 1 6d
grafana-0 1/1 Running 0 14h
kube-apiserver-k8s-master 1/1 Running 1 6d
kube-controller-manager-k8s-master 1/1 Running 2 6d
kube-flannel-ds-amd64-dc5z9 1/1 Running 1 5d23h
kube-flannel-ds-amd64-jm2jz 1/1 Running 1 5d23h
kube-flannel-ds-amd64-z6tt2 1/1 Running 1 6d
kube-proxy-9ltx7 1/1 Running 2 6d
kube-proxy-lnzrj 1/1 Running 1 5d23h
kube-proxy-v7dqm 1/1 Running 1 5d23h
kube-scheduler-k8s-master 1/1 Running 2 6d
kube-state-metrics-6474469878-lkphv 2/2 Running 0 98m
prometheus-0 2/2 Running 0 15h
然后也可以在我们的prometheus上看到我们设置的告警规则 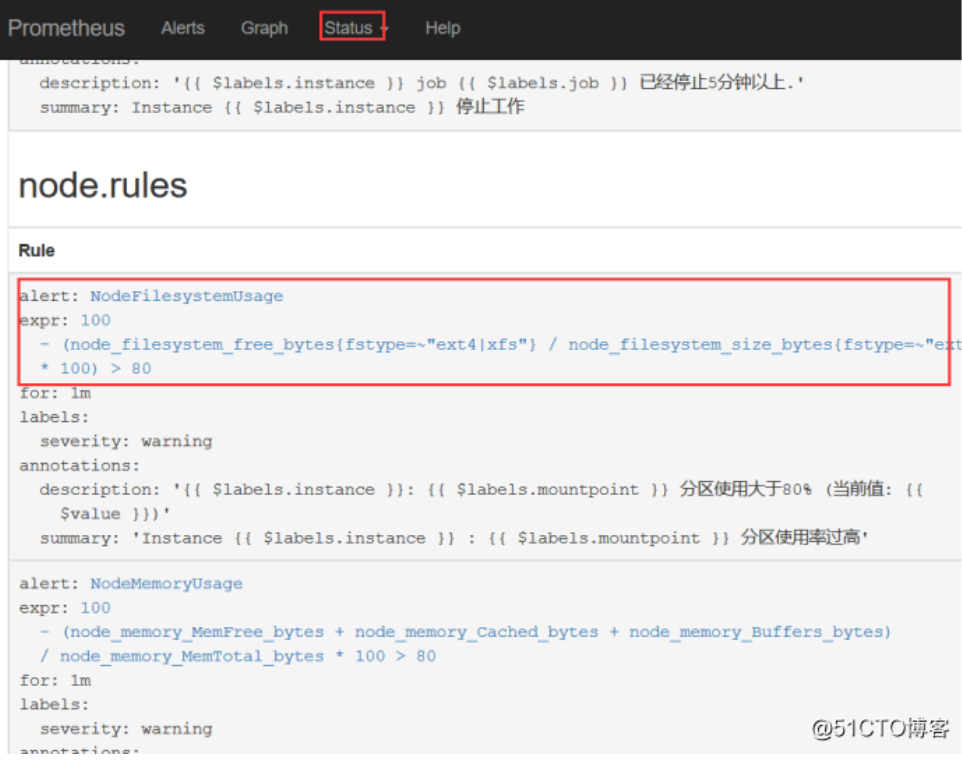
然后我们测试一下我们的告警,修改一下我们的prometheus的rules
把node磁盘资源设置为>20 就报警
[root@k8s-master prometheus-k8s]# vim prometheus-rules.yaml
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 20
重建一下pod,这里会自动启动,查看prometheus,已经生效,另外上产环境都是去调用api,发送一个信号给rules,这里我是重建的,也可以找一些网上的其他文章
[root@k8s-master prometheus-k8s]# kubectl delete pod prometheus-0 -n kube-system
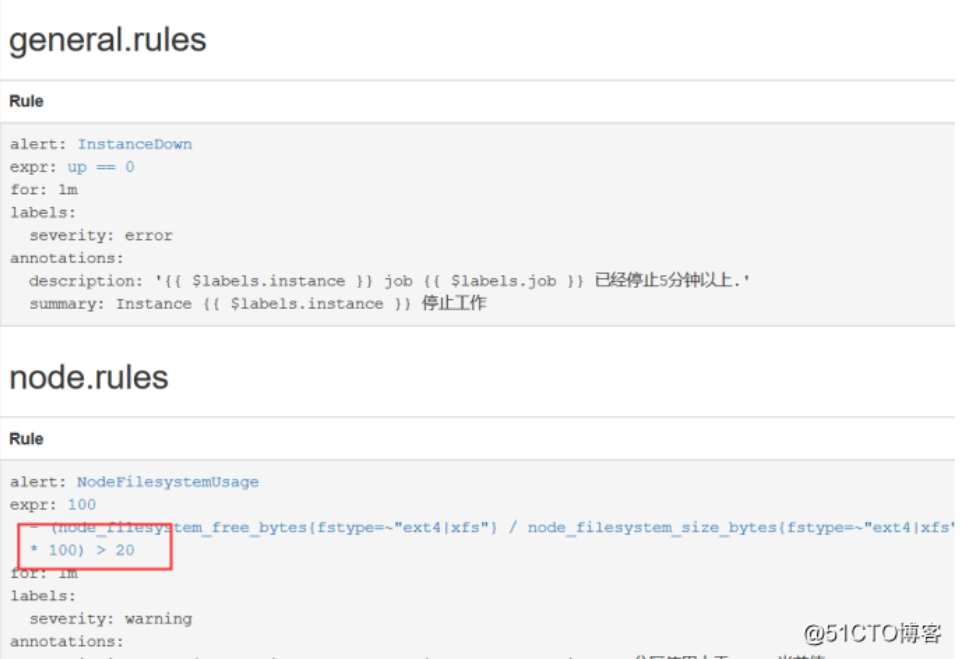
查看Alerts,这里会变颜色,等会会变成红色,也就是alertmanager它是有一个处理的逻辑的,还是比较复杂的,它会设计到一个静默,就是告警收敛这一块,还有一个分组,还有一个再次等待的的确认,所有不是一触发就发送
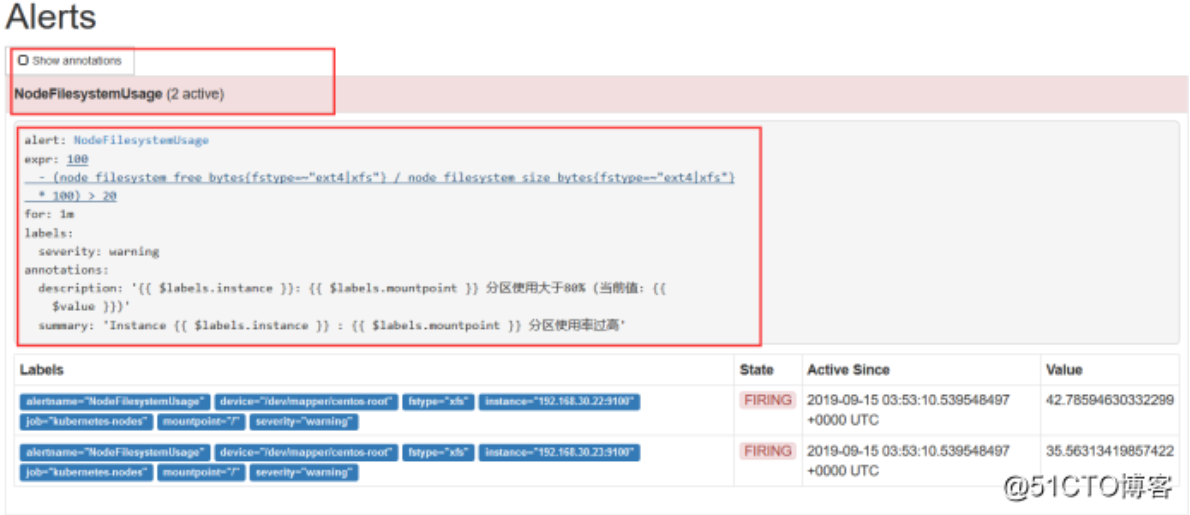
粉红色其实已经将告警推送给Alertmanager了,也就是这个状态下才去发送这个告警信息 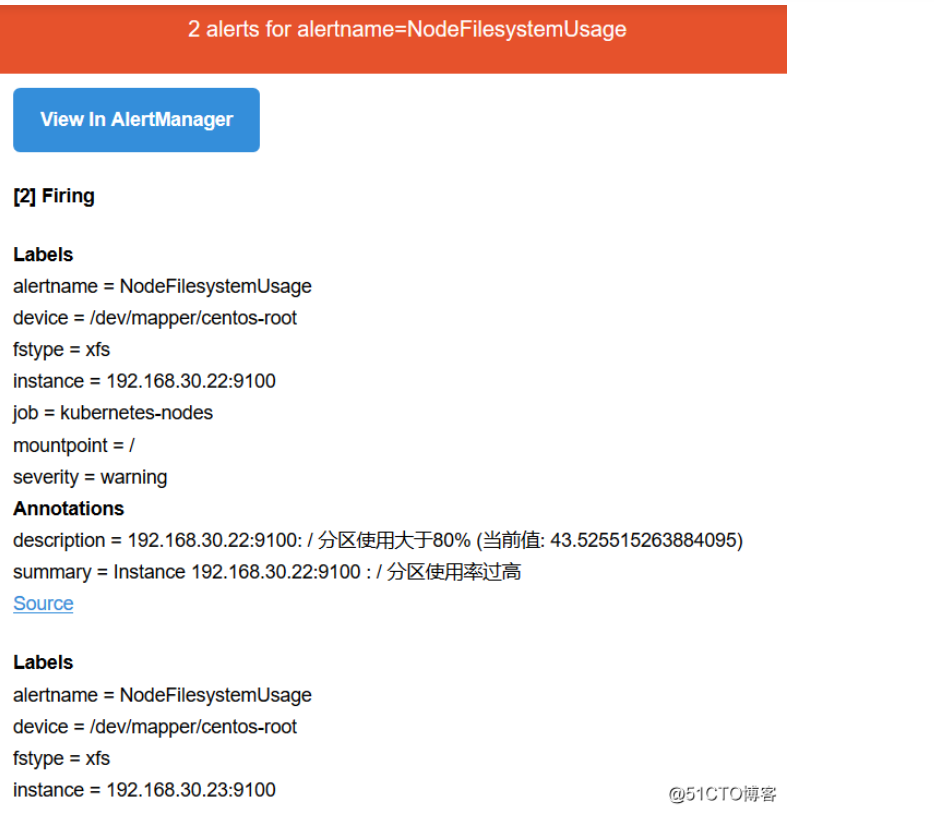

若有收获,就点个赞吧
0 人点赞
