作者 l 李朋波 编辑 l 李朋波
本文目录CONTENTS
☞ 新型 ETL 工具 [ StreamSets、WarterDrop ]
☞ 计算引擎 [ MapReduce、Tez、Spark、Flink、ClickHouse、Doris ]
☞ 流程控制工具 [ Hudson、Airflow、Azkaban、Oozie、 DolphinScheduler]
0x00 前言
上篇,我们介绍了五种传统 ETL 工具和八种数据同步集成工具。
数据仓库详细介绍(五.ETL)工具篇上
本篇,我们接着介绍两种新型 ETL 工具、大数据发展不同阶段产生的六种主要计算引擎、五种流程控制组件。
最后我们简单讨论两个话题:
- 这么多组件我们该如何抉择?
- 如何快速将工具引入生产实践?
0x01 新型 ETL 工具
传统 ETL 工具,通常工具化程度很高,不需要编程能力且提供一套可视化的操作界面供广大数据从业者使用,但是随着数据量的激增,跟关系型数据库一样只能纵向扩展去增加单机的性能,这样数据规模的增长跟硬件的成本的增长不是线性的。
而新型 ETL 工具天然适应大数据量的同步集成计算,且支持实时处理,但缺点也很明显,就是工具化可视化程度低,搭建配置难度也比传统 ETL 工具要高,并且需要数据从业者具备一定的程序开发功底而传统数仓环境中的数据人绝大多数是不懂开发的。
但相信随着大数据技术的进一步成熟,终究还会走向低代码和 SQL 化的方向上去的。那时候少部分人负责组件/平台的开发和维护,大部分人使用这些组件去完成业务开发。
StreamSets
Streamsets 是由 Informatica 前首席产品官 Girish Pancha 和 Cloudera 前开发团队负责人 Arvind Prabhakar 于 2014 年创立的公司,总部设在旧金山。
Streamsets 产品是一个开源、可扩展、UI很不错的大数据 ETL 工具,支持包括结构化和半/非结构化数据源,拖拽式的可视化数据流程设计界面。Streamsets 利用管道处理模型(Pipeline)来处理数据流。你可以定义很多 Pipeline,一个 Pipeline 你理解为一个 Job 。
Streamsets 旗下有如下三个产品:
- Streamsets data collector(核心产品,开源):大数据 ETL 工具。
- Streamsets data collector Edge(开源):将这个组件安装在物联网等设备上,占用少的内存和 CPU。
- Streamsets control hub(收费项目):可以将 collector 编辑好的 pipeline 放入 control hub 进行管理,可实现定时调度、管理和 pipeline 拓扑。
_
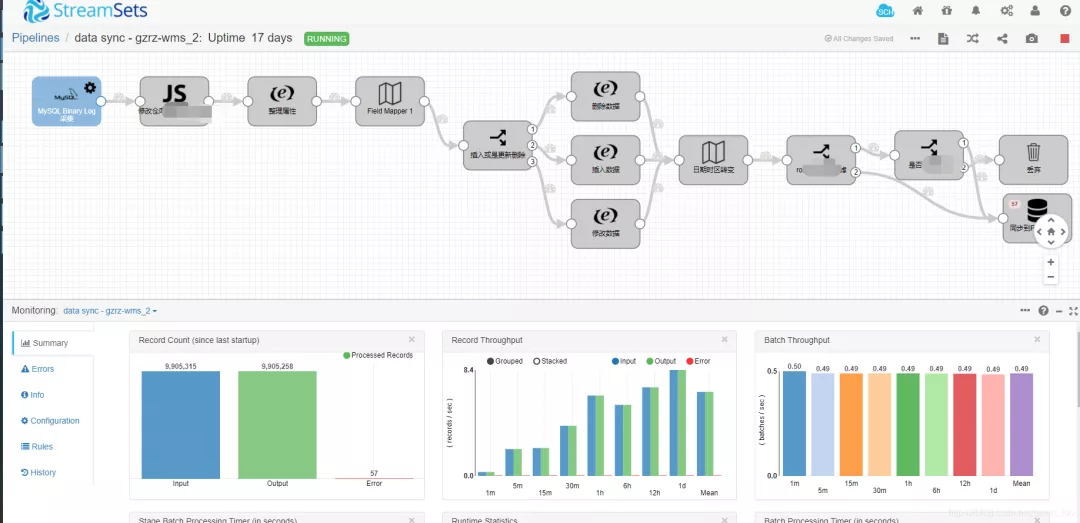
StreamSets 开发页面
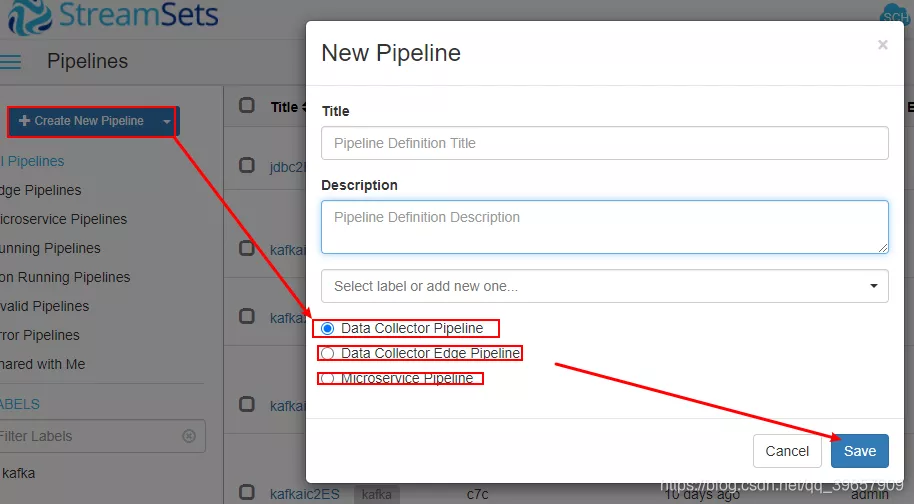
在管道的创建上分为了三个管道:
- data collector pipeline:用户普通 collector 开发。
- data collector Edge Pipeline:将开发好的 pipeline 上传到对应 Edge 系统。
- microservice pipeline:提供微服务。
管道创建好后,会根据需要去选择对应的组件信息。
主要有以下几类组件:
- origins (extract):数据来源,数据从不同的数据源抽取。(一个 pipeline 中只能有一个数据来源)
- processor(transform):数据转化,将抽取来的数据进行过滤,清洗。
- destination(load):数据存储,将数据处理完后存入目标系统或者转入另一个pipeline进行再次处理。
- executor:由处理数据组件的事件触发 executor ,执行相应任务。例如:某个组件处理失败,发送邮件通知。
WarterDrop
Waterdrop 项目由 Interesting Lab 开源,是一个非常易用,高性能、支持实时流式和离线批处理的海量数据处理产品,架构于 Apache Spark 和 Apache Flink 之上。
Spark 固然是一个优秀的分布式数据处理工具,但是直接使用 Spark 开发是个不小的工程,需要一定的 Spark 基础以及使用经验才能开发出稳定高效的 Spark 代码。除此之外,项目的编译、打包、部署以及测试都比较繁琐,会带来不少的时间成本和学习成本。
除了开发方面的问题,数据处理时可能还会遇到以下不可逃避的麻烦:
- 数据丢失与重复
- 任务堆积与延迟
- 吞吐量低
- 应用到生产环境周期长
- 缺少应用运行状态监控
Waterdrop 诞生的目的就是为了让 Spark 的使用更简单,更高效,并将业界使用 Spark 的优质经验固化到 Waterdrop 这个产品中,明显减少学习成本,加快分布式数据处理能力在生产环境落地。
gitHub 地址:
https://github.com/InterestingLab/waterdrop
软件包地址:
https://github.com/InterestingLab/waterdrop/releases
文档地址:
https://interestinglab.github.io/waterdrop-docs/
项目负责人
Gary(微信: garyelephant) , RickyHuo(微信: chodomatte1994)
_
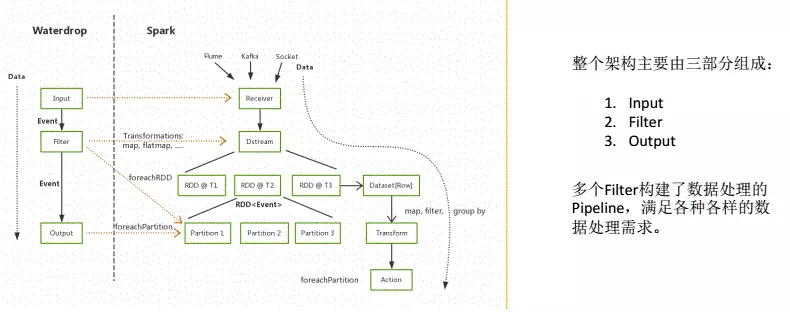
Waterdrop 架构
Waterdrop 使用场景:
- 海量数据 ETL
- 海量数据聚合
- 多源数据处理
Waterdrop 的特性:
- 简单易用,灵活配置,无需开发;可运行在单机、Spark Standalone 集群、Yarn 集群、Mesos 集群之上。
- 实时流式处理, 高性能, 海量数据处理能力。
- 模块化和插件化,易于扩展。Waterdrop 的用户可根据实际的需要来扩展需要的插件,支持 Java/Scala 实现的 Input、Filter、Output 插件。
- 支持利用 SQL 做数据处理和聚合。
- 方便的应用运行状态监控。
0x02 计算引擎
上边两种新型 ETL 工具的出现简化了数据处理操作,同步、集成、计算可以统一在一个工具内完成且有不错的界面可以使用,但对于一些更加复杂灵活的场景不一定能够支撑。
大数据场景下计算引擎还是主流,并且衍生出了许许多多的组件。我们这里无法一一列举,就分别挑选不同时期被广泛使用的几个做介绍吧。MapReduce
MapReduce 将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map 和 Reduce。它采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个 Map 任务并行处理。
**
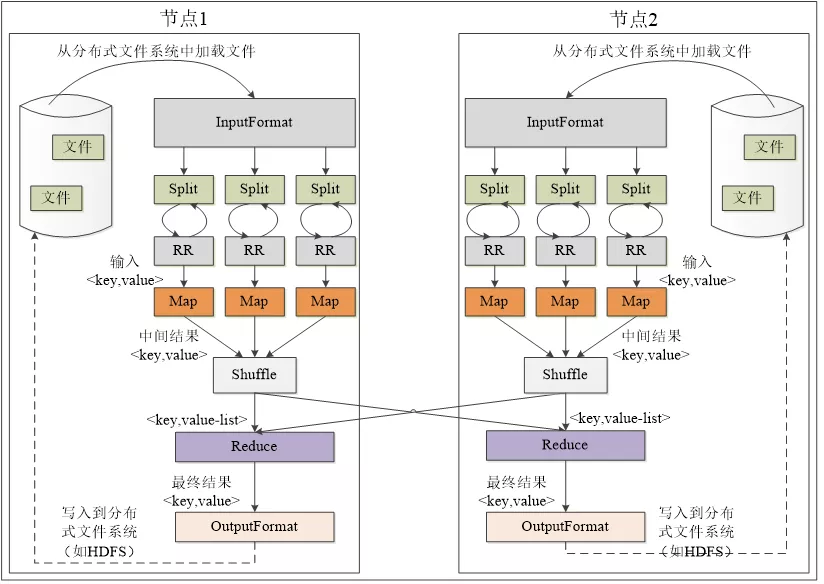
MapReduce 工作流程,来源于网络
不同的 Map 任务之间不会进行通信
不同的 Reduce 任务之间也不会发生任何信息交换
用户不能显式地从一台机器向另一台机器发送消息
所有的数据交换都是通过 MapReduce 框架自身去实现的
MapReduc 是 Hadoop 组件里的计算框架模型,另外还有分布式存储组件 HDFS、资源管理组件 Yarn。一开始计算和资源管理是耦合在一起的,Hadoop 2.0 才将其拆分开,这大大增加 Hadoop 使用的灵活性。
MapReduce 的缺陷:
- 第一,MapReduce 模型的抽象层次低,大量的底层逻辑都需要开发者手工完成。
- 第二,只提供 Map 和 Reduce 两个操作。很多现实的数据处理场景并不适合用这个模型来描述。实现复杂的操作很有技巧性,也会让整个工程变得庞大以及难以维护。
- 第三,在 Hadoop 中,每一个 Job 的计算结果都会存储在 HDFS 文件存储系统中,所以每一步计算都要进行硬盘的读取和写入,大大增加了系统的延迟。
Tez
Hadoop(MapReduce/Yarn、HDFS) 虽然能处理海量数据、水平扩展,但使用难度很大,而 Hive 的出现恰好解决这个问题,这使得 Hive 被迅速的推广普及成为大数据时代数据仓库组件的代名词(存储使用 hdfs,计算使用 MapReduce。Hive 只是一个壳根据自身维护的表字段跟底层存储之间映射关系 Hcatlog,对用户提交的 SQL 进行解析、优化,然后调用底层配置的执行引擎对底层数据进行计算)。
为解决 Hive 执行性能太差的问题,在计算引擎方面出现了 Tez,数据存储方面出现了 ORC(一种专门针对 Hive 开发的列式存储压缩格式。当然 HDFS 本身也有一些存储压缩格式,另外还有一个比较流行的列示存储格式 Parquet)这也使得 Hive 的性能有了质的提升。

MR 与 Tez 的比较,来源于网络
MapReduce 每一步都会落磁盘,这大大影响力执行效率
Tez 是 Apache 开源的支持 DAG (有向无环图,Directed Acyclic Graph)作业的计算框架。它把 Map/Reduce 过程拆分成若干个子过程,同时可以把多个 Map/Reduce 任务组合成一个较大的 DAG 任务,减少了 Map/Reduce 之间的文件存储。同时合理组合其子过程,也可以减少任务的运行时间。加上内存计算 Tez 的计算性能实际上跟 Spark 不相上下。
Tez 直接源于 MapReduce 框架,核心思想是将 Map 和 Reduce 两个操作进一步拆分,即 Map 被拆分成Input、Processor、Sort、Merge和Output, Reduce 被拆分成 Input、Shuffle、Sort、Merge、Processor 和 Output 等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的 DAG 作业。
Spark 、Flink
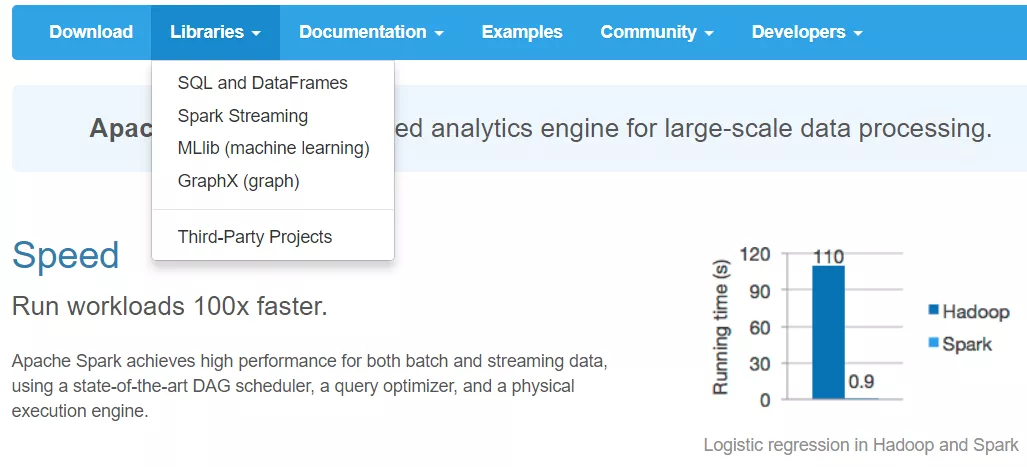
Apache Spark 是一个围绕速度、易用性和复杂分析构建的大数据处理框架,用于大规模数据处理的统一分析引擎,致力于一个组件满足大数据处理和分析的所有计算场景。
Spark 是当今最流行的分布式大规模数据处理引擎,被广泛应用在各类大数据处理场景。2009 年,美国加州大学伯克利分校的 AMP 实验室开发了 Spark。2013 年,Spark 成为 Apache 软件基金会旗下的孵化项目。而现在,Spark 已经成为了该基金会管理的项目中最活跃的一个。

SparkUI Stage 页面
Spark 应用场景:
- 离线计算:使用算子或 SQL 执行大规模批处理,对标 MapReduce、Hive。同时提供了对各种数据源(文件、各种数据库、HDFS 等)的读写支持。
- 实时处理:以一种微批的方式,使用各种窗口函数对流式数据进行实时计算。主要实现在这两部分:Spark Streaming、Structure Streaming(Spark 2.3 版本推出)。
- MLlib:一个常用机器学习算法库,算法被实现为对 RDD 的 Spark 操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX 扩展了 RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
Spark 数据结构:
- RDD:弹性分布式数据集,它代表一个可以被分区(partition)的只读数据集,它内部可以有很多分区,每个分区又有大量的数据记录(record)。RDD 表示已被分区、不可变的,并能够被并行操作的数据集合。
- DataFrame:可以被看作是一种特殊的 DataSet 可以被当作 DataSet[Row] 来处理,我们必须要通过解析才能获取各列的值。
- DataSet:数据集的意思,它是 Spark 1.6 新引入的接口。就像关系型数据库中的表一样,DataSet 提供数据表的 schema 信息比如列名列数据类型。
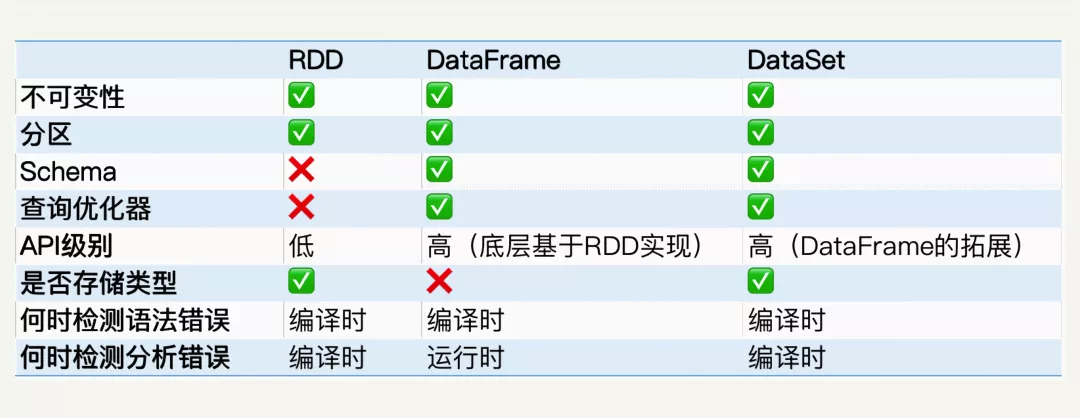
RDD、DataFrame、DataSet 对比
_**
Spark 数据结构发展历史:
- RDD API 在第一代 Spark 中就存在,是整个 Spark 框架的基石。
- 接下来,为了方便熟悉关系型数据库和 SQL 的开发人员使用,在 RDD 的基础上,Spark 创建了 DataFrame API。依靠它,我们可以方便地对数据的列进行操作。
- DataSet 最早被加入 Spark SQL 是在 Spark 1.6,它在 DataFrame 的基础上添加了对数据的每一列的类型的限制。
- 在Spark 2.0 中,DataFrame 和 DataSet 被统一。DataFrame 作为 DataSet[Row]存在。在弱类型的语言,如 Python 中,DataFrame API 依然存在,但是在 Java 中,DataFrame API 已经不复存在了。
Flink 起源于 2008 年柏林理工大学一个研究性项目, 在 2014 年被 Apache 孵化器所接受,然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一。德国人对 Flink 的推广力度跟美国人对 Spark 的推广差的比较远,直到 2019 年阿里下场才使得 Flink 在国内得到广泛应用,并且以很高的频率进行版本迭代。

Flink 组件栈
基于流执行引擎,Flink 提供了诸多更高抽象层的 API 以便用户编写分布式任务:
- DataSet API:对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用 Flink 提供的各种操作符对分布式数据集进行处理,支持 Java、Scala 和 Python。
- DataStream API:对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持 Java 和 Scala。
- Table API:对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类 SQL 的 DSL 对关系表进行各种查询操作,支持 Java 和 Scala。
- Flink ML:Flink 的机器学习库,提供了机器学习 Pipelines API 并实现了多种机器学习算法。
- Gelly:Flink 的图计算库,提供了图计算的相关 API 及多种图计算算法实现。
如上所述,Flink 等于说是把 Spark 的功能重新实现了一遍,区别在于 Spark 是由批入流 Flink 是由流入批。由于起步较晚,Flink 能够大量吸收 Hadoop、Spark 的优秀经验,凭借更高层次的抽象、更简洁的调用方式、高的吞吐、更少的资源占用,在实时计算、实时数仓等场景迅速超越了 Spark。但 Flink 想要完全超越 Spark 还有很长的路要走,比如对 SQL 的支持、批流一体的实现、机器学习、图计算等等。
对于数据开发者来说,Spark 比 MapReduce 支持的场景更广使用起来也容易的多,Flink 相比 Spark 同样更易用了。所以往后大数据开发的门槛将会越来越低:完全 SQL 化、低代码甚至会像传统 ETL 工具一样无代码。大数据从业者未来的路该怎么走?这是个值得思考的问题。
ClickHouse 、Doris
ClickHouse 是 Yandex 在 20160615 开源的一个数据分析的 MPP 数据库。并且在 18 年初成立了 ClickHouse 中文社区,应该是易观负责运营的。
ClickHouse 实质上是一个数据库。为了获得极致的性能,ClickHouse 在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与 SIMD 指令、代码生成等多种重要技术。普通大数据集群,单机十几亿数据检索秒出。因此许多即席查询场景 ClickHouse 被广泛使用。

Apache Doris 是一个现代化的 MPP 分析型数据库产品,百度开源并贡献给 Apache 社区。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris 的分布式架构非常简洁,易于运维,并且可以支持 10PB 以上的超大数据集。
Apache Doris 可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。令您的数据分析工作更加简单高效!

ClickHouse 确实是一个非常优秀的产品。但为了获得查询时的高性能我们放弃了一些东西:
- ClickHouse 过度依赖大宽表。
- ClickHouse 难以支持高并发的业务场景。
- 并不完全能够支持标准 SQL ,UDF 也是最近才支持的。
- ClickHouse 集群的运维复杂度也一定曾让您感到过头疼。
Doris 的诞生试图去解决 ClickHouse 的这些问题,让我们拭目以待吧。
0x03 流程控制组件
流程控制(也称工作流、任务流)是 ETL 重要的组成部分,通常是以 DAG 的方式配置,每次调用都会沿着有向无环图从前往后依次执行直至最后一个任务完成。
流程控制可以在 ETL 工具内配置,也可以在调度系统配置。传统 ETL 工具基本上都是单机版的,如果 ETL 的任务节点分布在多个服务器上,整体的流程依赖就会变的复杂起来(跨服务器的调度无法解决,就只剩下两种方法了:预估前置依赖完成时间、监控前置依赖运行状态比如将运行状态写入数据库等),这时候使用调度工具里的流程控制功能就是最优解。
Hudson
Hudson 是一个可扩展的持续集成引擎,是 SUN 公司时期就有的 CI 工具,后来因为 ORACLE 收购 SUN 之后的商标之争,创始人 KK 搞了新的分支叫 Jenkins 。今天的Hudson还在由ORACLE 持续维护,但风头已经远不如社区以及CloudBees 驱动的 Jenkins。
主要用于:
- 持续、自动地构建/测试软件项目,如 CruiseControl 与 DamageControl。
- 监控一些定时执行的任务。
 Hudson 操作界面
Hudson 操作界面
Hudson 拥有的特性包括:
- 易于安装:只要把 hudson.war 部署到 servlet 容器,不需要数据库支持。
- 易于配置:所有配置都是通过其提供的 web 界面实现。
- 集成 RSS/E-mail/IM:通过 RSS 发布构建结果或当构建失败时通过 e-mail 实时通知。
- 生成 JUnit/TestNG 测试报告。
- 分布式构建支持,Hudson 能够让多台计算机一起构建/测试。
- 文件识别:Hudson 能够跟踪哪次构建生成哪些 jar,哪次构建使用哪个版本的 jar 等。
- 插件支持:Hudson 可以通过插件扩展,你可以开发适合自己团队使用的工具。
_Hudson 是我们早期数仓项目中使用的一个调度工具,当然 Hudson 还有其它的一些功能,但我们用到的仅仅是调度。由于 ETL 系统整体的复杂性,源端数据汇总集成、数仓分层计算、数据推送到外部系统,我们分别部署在了三台服务器上,这时候 Hudson 就起到了跨服务器调度依赖控制的作用。
Airflow、 Azkaban、Oozie
Airflow 是一个可编程,调度和监控的工作流平台,基于有向无环图(DAG),Airflow 可以定义一组有依赖的任务,按照依赖依次执行。Airflow 提供了丰富的命令行工具用于系统管控,而其 web 管理界面同样也可以方便的管控调度任务,并且对任务运行状态进行实时监控,方便了系统的运维和管理。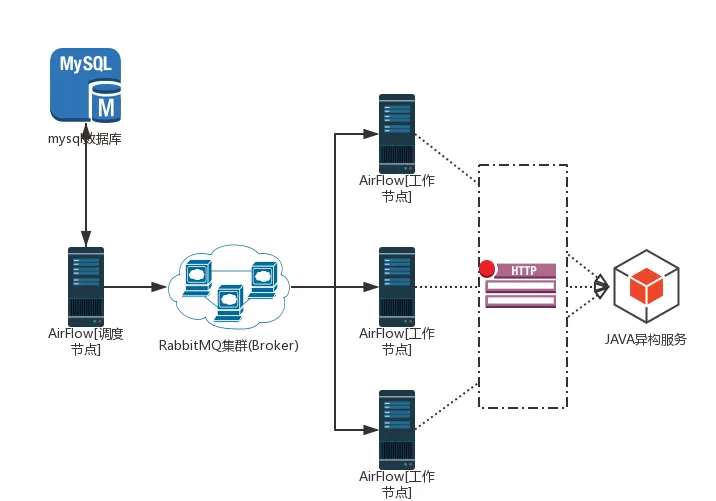
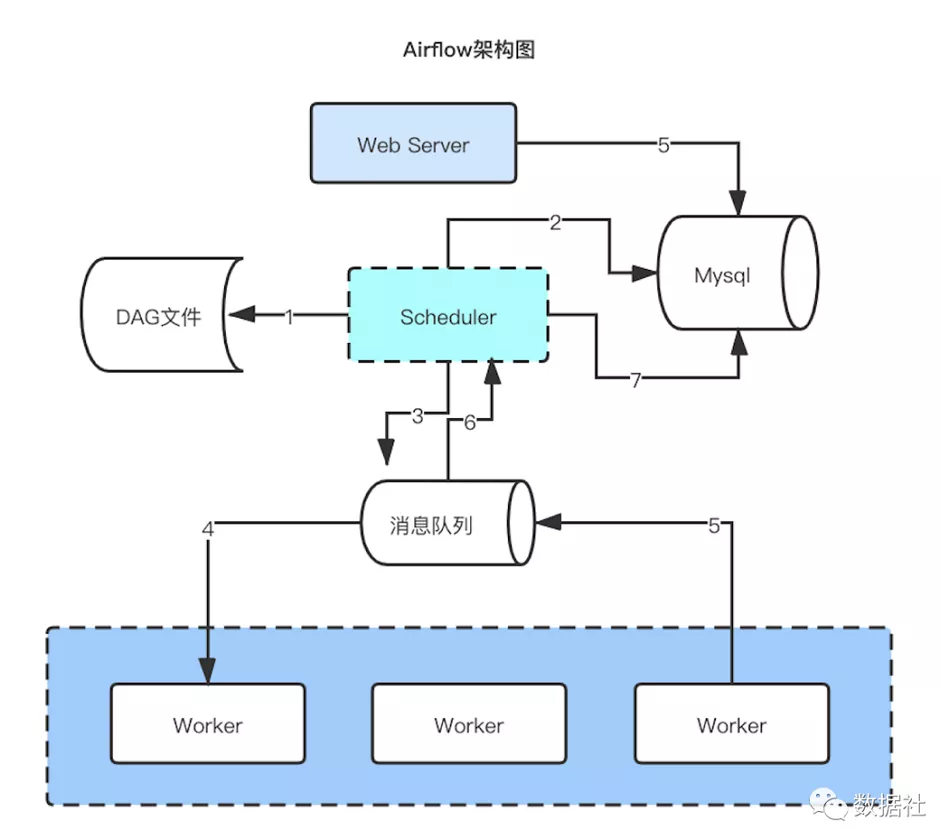
上图以及以下两段文字来源于公众号:数据社
主要有如下几种组件构成:
- web server: 主要包括工作流配置,监控,管理等操作。
- scheduler: 工作流调度进程,触发工作流执行,状态更新等操作。
- 消息队列:存放任务执行命令和任务执行状态报告。
- worker: 执行任务和汇报状态。
- mysql: 存放工作流,任务元数据信息。
具体执行流程:
- scheduler 扫描 dag 文件存入数据库,判断是否触发执行。
- 到达触发执行时间的 dag ,生成 dag_run,task_instance 存入数据库。
- 发送执行任务命令到消息队列。
- worker 从队列获取任务执行命令执行任务。
- worker 汇报任务执行状态到消息队列。
- schduler 获取任务执行状态,并做下一步操作。
- schduler 根据状态更新数据库。
Azkaban 是由 Linkedin 开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban 定义了一种 KV 文件格式来建立任务之间的依赖关系,并提供一个易于使用的 web 用户界面维护和跟踪你的工作流。
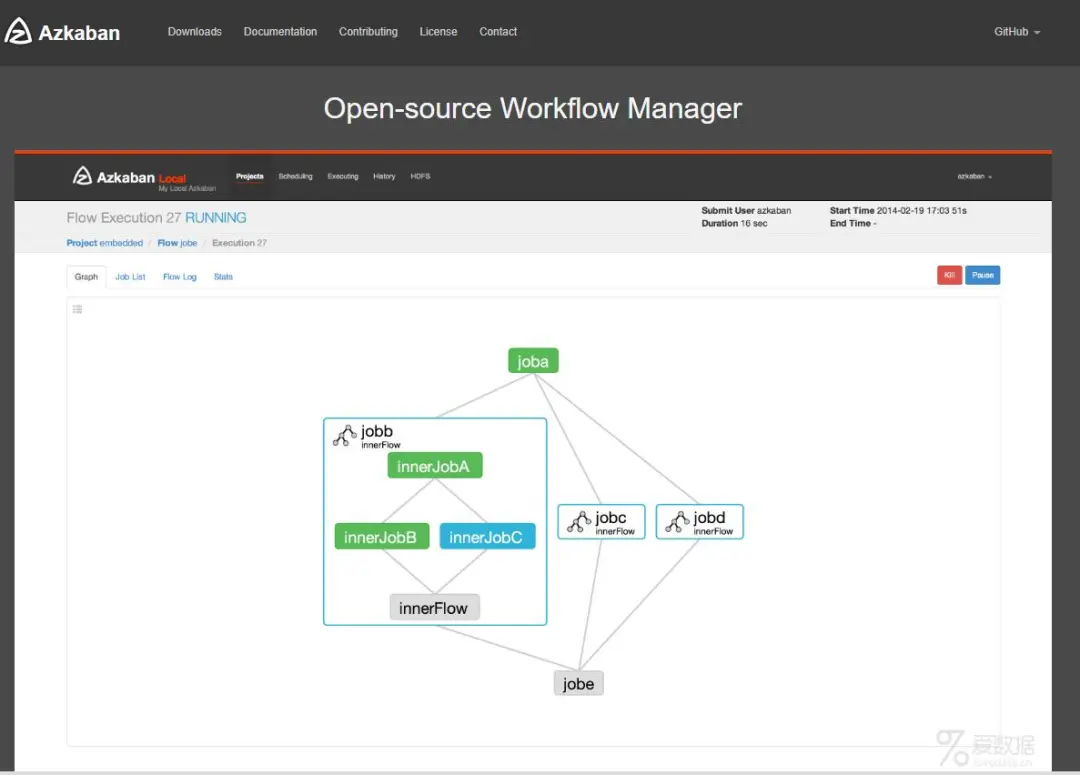
Azkaban 操作界面
_
Oozie 起源于雅虎,主要用于管理与组织 Hadoop 工作流。Oozie 的工作流必须是一个有向无环图,实际上 Oozie 就相当于 Hadoop 的一个客户端,当用户需要执行多个关联的 MR 任务时,只需要将 MR 执行顺序写入 workflow.xml,然后使用 Oozie 提交本次任务,Oozie 会托管此任务流。

以上三个组件都是在大数据环境下使用的调度工具,Oozie 属于非常早期的调度系统了并且深度服务于 Hadoop 生态目前使用的很少了,Azkaban 目前也使用的不多,Airflow 还有一定的市场。
DolphinScheduler
Apache DolphinScheduler 是一个分布式、去中心化、易扩展的可视化 DAG 工作流任务调度系统,其致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
DolphinScheduler 于 2019 年 8 月 29 日 进入 Apache 孵化器,于 2021 年 4 月 9 日成为 Apache 顶级项目。
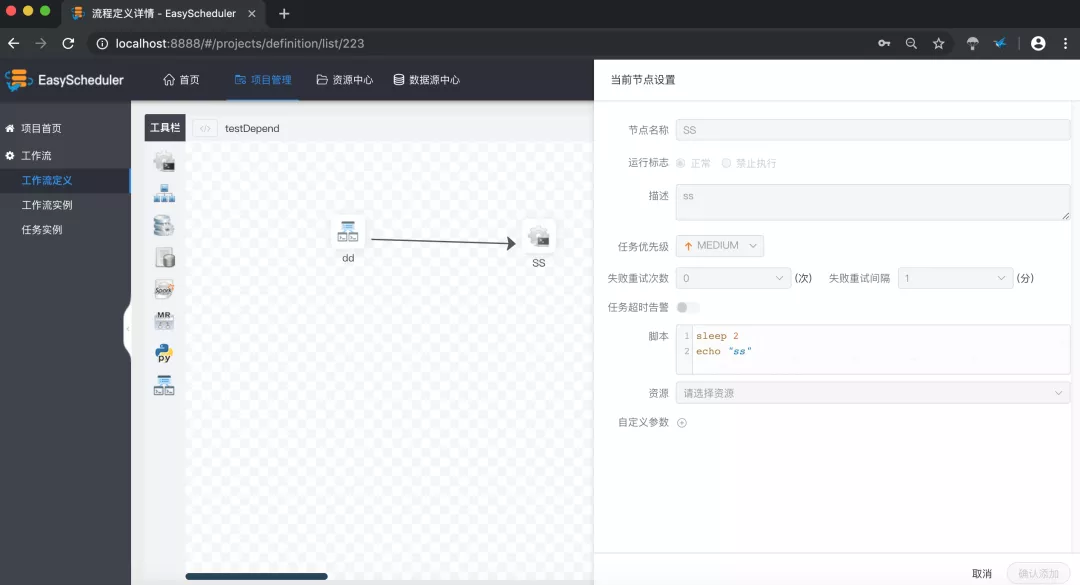
DolphinScheduler 操作界面
_
DolphinScheduler 提供了许多易于使用的功能,可加快数据 ETL 工作开发流程的效率。其主要特点如下:
- 通过拖拽以 DAG 图的方式将 Task 按照任务的依赖关系关联起来,可实时可视化监控任务的运行状态;
- 支持丰富的任务类型;
- 支持工作流定时调度、依赖调度、手动调度、手动暂停/停止/恢复,同时支持失败重试/告警、从指定节点恢复失败、Kill 任务等操作;
- 支持工作流全局参数及节点自定义参数设置;
- 支持集群 HA,通过 Zookeeper 实现 Master 集群和 Worker 集群去中心化;
- 支持工作流运行历史树形/甘特图展示、支持任务状态统计、流程状态统计;
- 支持补数,并行或串行回填数据。
0x04 总结
这么多组件我们该如何抉择
写到这里,计划中的 ETL 工具以及类 ETL 组件已经全部介绍完了,但我只是挑了不同时期比较流行的很少一部分,刚数了下有 26 个。
工具组件这么多,做为技术人肯定是学不完的,经常看到一些简历罗列了一二十个,大而全哪哪都不精这样的人市场上是没啥竞争力的。所以我们必须聚焦,在数据处理的全流程,每一类型选取其中一种组件深入学习并努力在生产实践中运用。在特定的场景,多种工具其实实现的功能大体是类似的,无非是后起的在性能、稳定性、易用性上会比早出现的好很多。
- 如果你已经在一家公司做数据了,就先看下公司的技术栈。如果市面上还是比较流行,恭喜你努力的去学精学透,从生产使用技巧到底层运行原理去深挖,其它的类似组件简单了解就行。如果公司使用的技术不好用或者过于陈旧就努力推动促使公司更换技术栈吧。
- 如果你还不是做数据的,或者以后想转数据,或者公司的技术栈陈旧又没法更换,这就需要自我学习了。我们需要挑选不同类型下最流行或者最优秀的那个深入学习,一通百通。比如 ETL 工具传统的那些就没必要学了直接学 StreamSets 或者 WaterDrop 即可;实时计算直接学 Flink 即可不用看 Spark 了;众多的 OLAP 我们直接学 ClickHouse 或者 Doris 即可其它的也不用看了;调度嘛直接 DS 就好了。求职时候尝试把你最最擅长的那一两个组件表现出来反而更容易获得面试官的认可。
如何快速将工具引入生产实践
当我们选好一个新的组件后,从入门到精通大致需要以下三个过程:
- 第一步,先用起来,并且对组件有基本的认知。我们需要先想明白我们想让该组件帮我们解决什么问题然后将问题分类细化逐个解决,拿最小集合快速的跑通全流程。
- 第二步,学习组件原理特性,将更多的特性运用到业务中去解决更多的实际问题,同时对现有流程进行调优。
- 第三步,学习源码对组件本身进行优化改造,用于解决更多的现实问题,如果有可能就贡献给社区。当然走到这一步的还是少数人,这是平台开发的事,数据开发很少有这样的机会因为投入产出比很差。
最后,我们举个例子吧:一个项目需要使用一个之前没用过的 ETL 工具,我们如何能够在两周内达到生产应用的水平呢?
首先我们需要搞明白我们需要 ETL 系统做什么?
数据源连接,连接上之后我们能够抽取或者加载数据。
文件的导入导出功能。
源端库数据的全量/增量抽取。
目标库数据的插入/更新/删除。
- 流程控制:任务流动方向的控制、串行/并行控制、任务成功/失败后的处理、必要的条件判断并能依据判断结果执行不同的操作。
- 参数传递与接收:多层/多级任务,参数能够从最外层往下一层或者从最上游往下游传递,每个任务节点要能通过变量接收到上层或者上游参数。
- ETL 执行过程监控,方便后续自动化监控和告警。
- ETL 运行出错时候的重试/补数。
正常来说,所有 ETL 工具都是能够支持以上功能的,我们需要找到它们(否则就得尽快寻找补救方案),然后就能正常的进行 ETL 开发了。我们需要使用新的工具先让系统稳定、准确的跑起来,同时能够提供有效的自动化运行监控,性能优化是下一步该做的事情。
好了,ETL 工具篇分上下两部分,合计一万五千多字,到这里就介绍完了。
下篇的 ETL 实践经验总结我们下周见。感兴趣的话欢迎关注下方公众号。
数仓与大数据
体系化的总结归纳数据仓库相关知识、大数据相关知识,为广大圈内同仁,提供一套完备的学习资料。
13篇原创内容
公众号
扩展阅读:
数据仓库详细介绍(二.架构)
数据仓库详细介绍(三.规范)心法篇
留个微信,大家不妨交个朋友,共同交流。同时,欢迎关注、分享、转载。


若有收获,就点个赞吧
0 人点赞
