基础概念
- 架构与框架,架构是结构,框架是规范
- 模块与组件,模块是逻辑概念,通过分解使复杂问题简单化,组件是物理概念,将具体的模块落地,且各个组件间保持松散耦合
定义:架构,是一个系统的顶层结构,包括这个系统的各个组件,组件的外部可见属性及组件间的相互关系。
架构设计需要从多个不同的视角去展开:
- 业务架构,是战略,描述想要做一件什么事情,用户涉及到几类人,分为几个模块。
- 应用架构,是战术,承接业务架构落地,影响技术架构选型,业务架构里的每一个模块在这里都有对应的模块。
- 技术架构,是装备,为了满足业务需求及性能指标所做的一系列技术选型。
- 数据架构,主要包括数据存储结构设计及相关规范。
- ETL架构,涉及流程模块的划分,模块间存在依赖的还需要考虑调用关系,任务调度与管理。
- 部署架构,需要考虑服务器的数量,配置及连通性,各个应用的部署位置,多节点还应考虑各个节点间的网络带宽。
业务架构
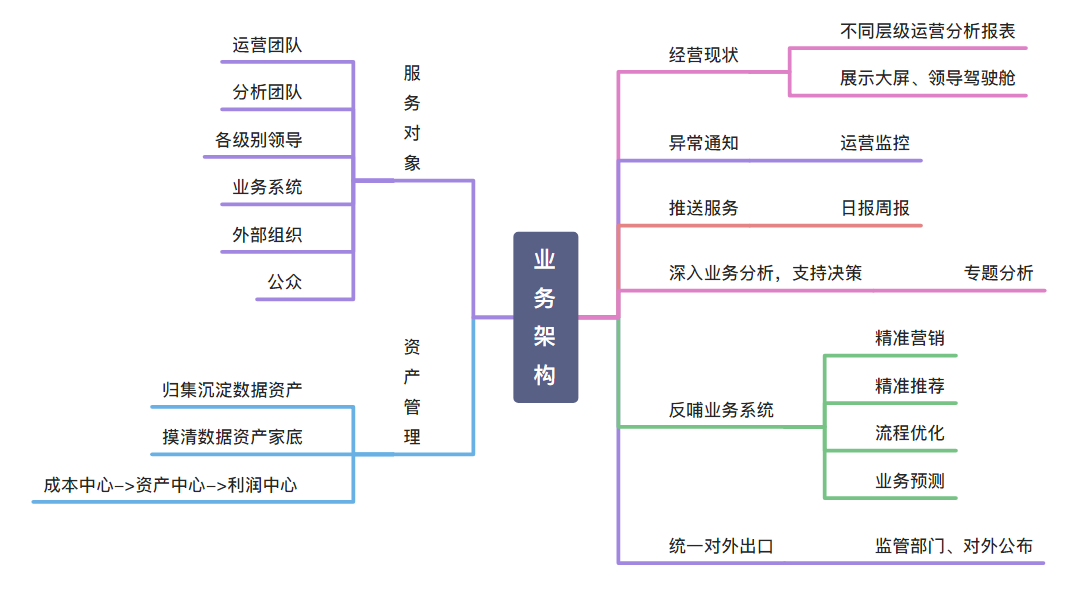
简单来讲,业务架构,需要从全局的角度出发,思考具体的业务诉求,思考数仓的真实价值。
需要清晰的了解组织的真实诉求、实际的服务对象。通常的业务诉求,包含两部分:数据资产管理、数据应用。业务架构是对业务需求的提炼和抽象,使用一套方法论对产品(项目)所涉及需求的业务进行业务边界划分,简单地讲就是根据一套逻辑思路进行业务的拆分,开发软件必须满足业务需求,否则就是空中楼阁。<br /> 业务架构是决定一个软件项目能否顺利开展的总纲,软件架构是业务架构在技术层面的映射,合理的开发分工也应该基于业务架构去做。如果没有业务架构,进行软件开发就会很盲目。业务架构是需求和开发的汇聚点,需求分析是否做到位,功能开发是否达到预期目标,都以此为依托。我们在工作中会遇到一些问题,例如研发人员说需求分析做得不到位,而做需求的人员会质疑需求做到怎样才算到位,为什么开发出的产品和用户想要的不一致,这些从根上来说,都是因为没有将业务架构梳理清楚,没有达成共识。站在软件项目的角度来看,在项目前期做好业务架构设计,对整个项目的开发都有重要的意义。<br />业务架构是技术与业务沟通的桥梁,不需要考虑技术实现。
应用架构-数据应用
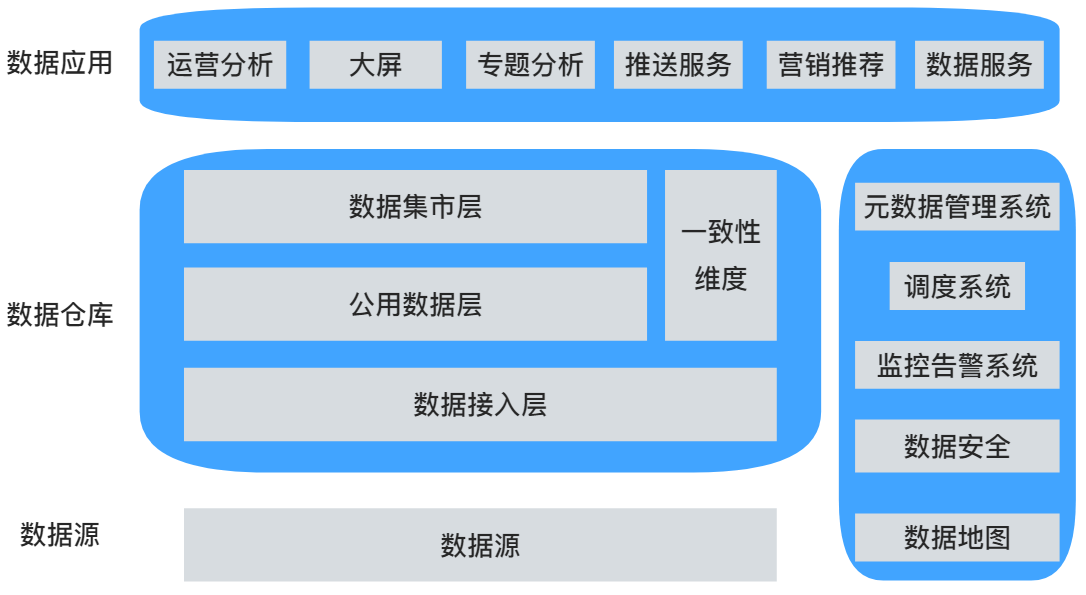
一句话,应用架构是承接业务架构落地的。所以应用架构必须有清晰的模块划分。<br /> 上边这张图是业务架构里的数据应用部分,由于时间原因,数据资产管理后期再补充。大体分为四个部分:数据源、数仓存储、数仓管理工具、数据应用。这里的绝大多数都会在后续的章节里详细介绍。
应用架构-数据资产管理(待补充)
数据架构
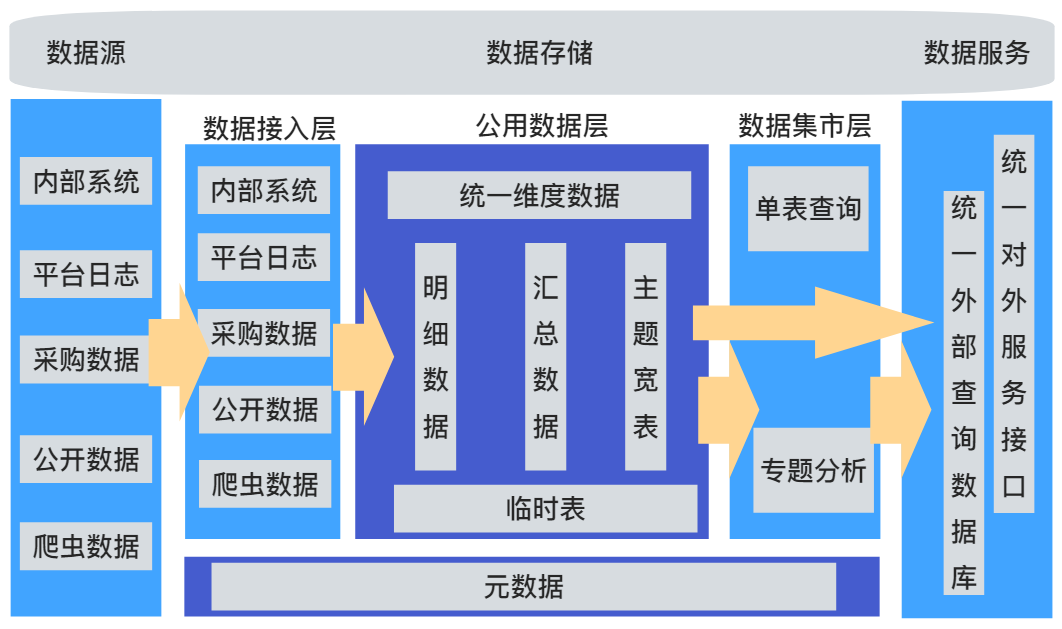
数仓里的数据架构,核心在于分层、主题域划分。<br /> 公用数据层,是数仓的核心层,对接入层的原始数据做清洗、补全、重新组织、编码映射后入明细数据层。数据服务,需要考虑数据查询的效率和数据使用过程中的安全性。<br /> 基于安全性考虑,可以采用统一接口调用、开辟独立数据存储、分配只有指定表、字段制度权限的账号等方式。<br /> 基于查询效率考虑,优先使用上层汇总表、维度退化尽量单表查询等方式。数据接入层,保持跟数据源一致的结构,模块划分完全采用数据源分类。<br /> 公用数据层,主题域的划分最好依据对实际业务的抽象,需要保持一定的稳定性、兼容性、前瞻性,主题域的划分需要保证整体数据完整,且数据无重叠。当然也可以按照业务模块、产品模块、分析需求、部门等方式划分。<br /> 数据集市层,模块划分主要依据业务需求或分析主题,模块之间数据允许重叠。
技术架构
数仓概念发展至今,也有三十多年了,虽然基础理论没太大变化,但技术体系已经发展到第四代第五代了。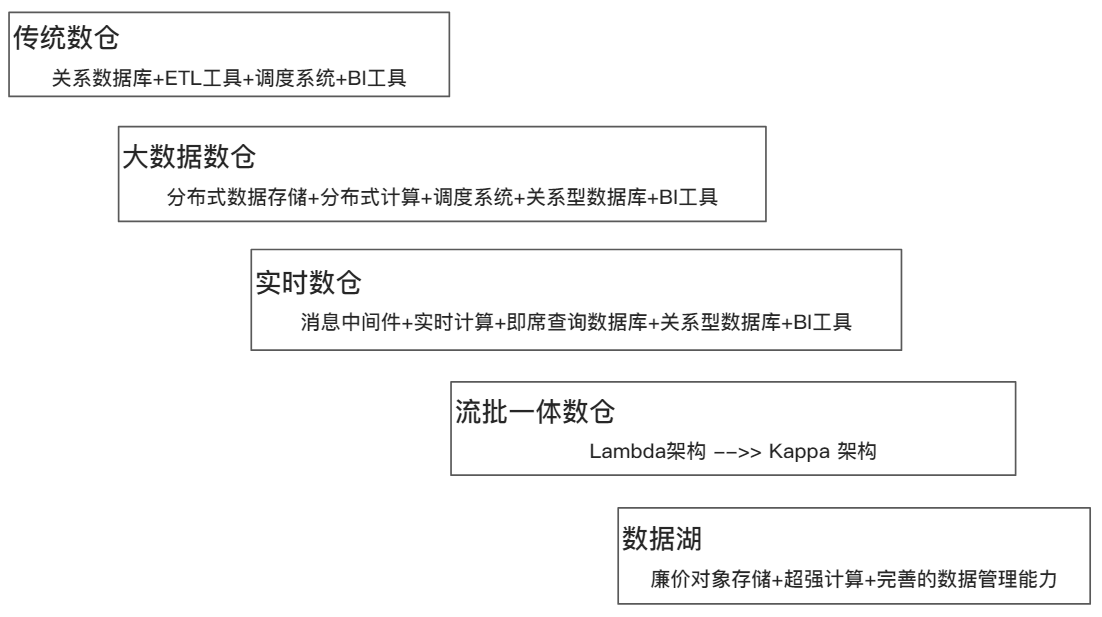
传统数仓的技术架构就不做介绍了。下边是大数据场景下,一个常规的技术架构图:
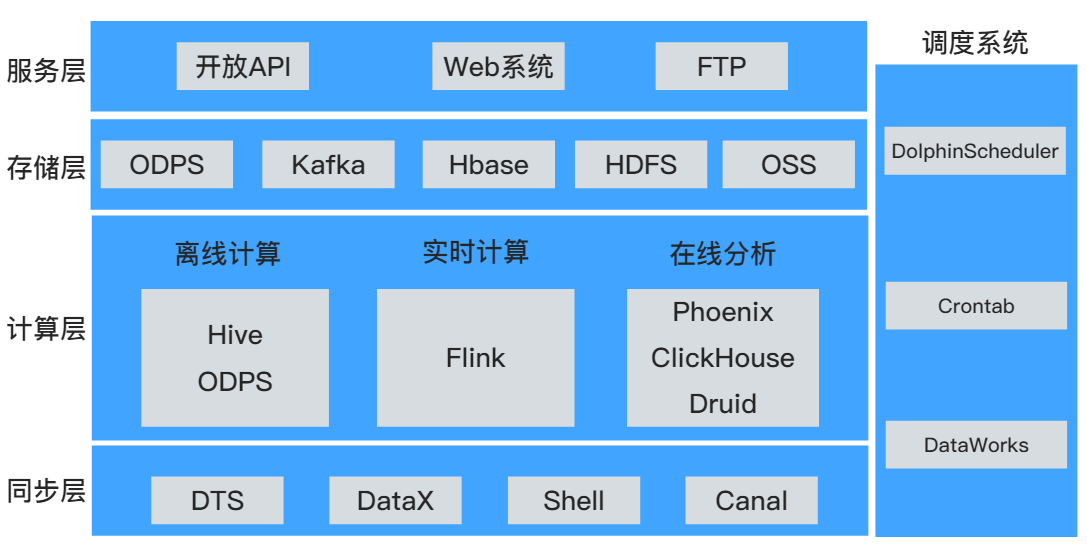
调度系统:
如果调度任务简单,完全可以用 Linux 自带的 Crontab 调度,ETL流程直接用 Shell 拼接。
如果调度任务繁多,ETL流程依赖复杂,可以采用 DolphinScheduler 调度,开源、社区支持大、操作简单、调度需要的各种功能都有。
离线数仓:
如果公司人力或技术储备不足的话,阿里云ODPS是个不错的选择。
如果人力充足的话,使用 hive on tez(或 spark) 也是一个不错的离线数仓方案。
实时数仓:
基于社区的大力推广,Flink 从18、19年开始在国内迅速流行起来,但一开始肯定会有各种各样的问题,所以王知无大佬建议中小公司生产慎用,可小范围业务尝试。
但随着 Flink 1.12 版本的发布,真正奠定了 Flink 在流计算领域正在大规模生产可用,比如公布了几个重大特性:基于 K8S 的高可用方案、对 Hive 的全面支持、对 SQL 的全面支持、DataStream API 支持批执行模式。
Flink 解决了流式计算的问题,但实时数仓还有两个问题需要解决,即流式的Upsert(Delete)功能和实时查询功能。Upsert 可选的技术组件有 HBase/Hudi/Iceberg/Redis/Mysql,实时查询可选的技术组件:HBase/Redis/Mysql。
在线分析:
这部分目前比较混乱,技术组件众多,后期需要专门研究,现在就先不深入了。
下边是,阿里巴巴分享的技术架构,写的很好,大家可以参考下: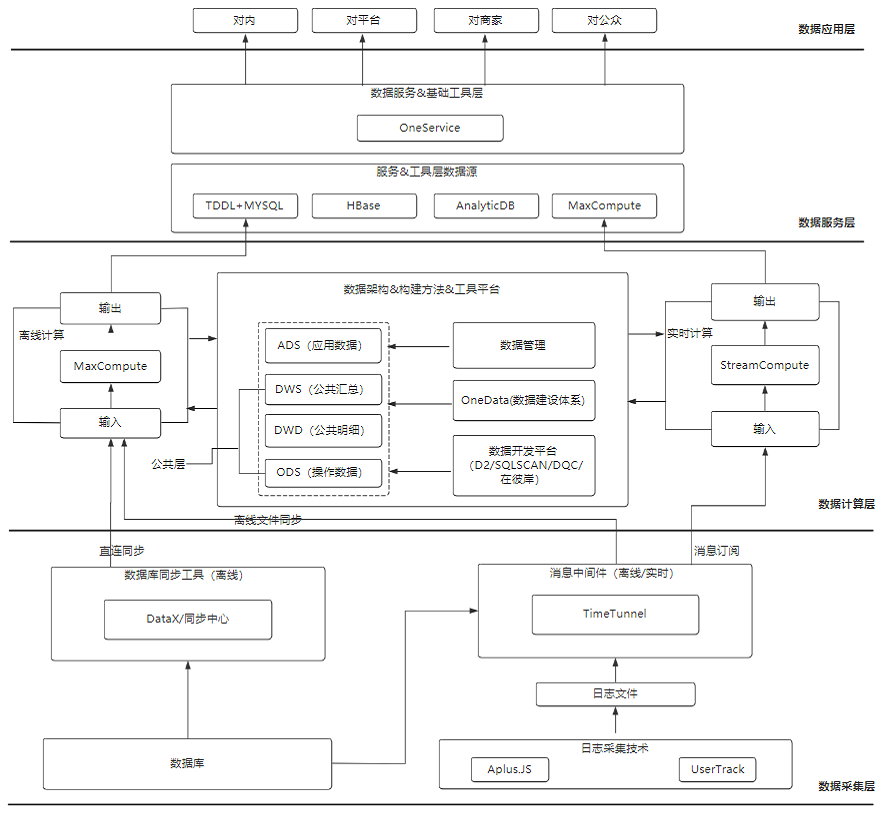
技术架构-实时数仓
目前实时数仓经验有限,以下技术架构来源于微信公众号文章,另外附有原文连接,仅供参考学习。
基于以上,实际的实时数据仓技术选型如下: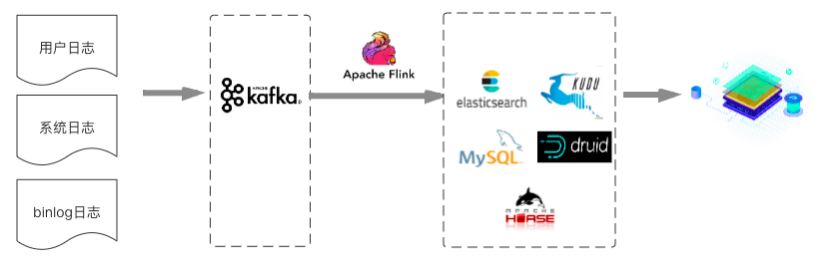
以上,是实时计算的最开始架构,没有数仓分成,直接一步计算出最终结果。
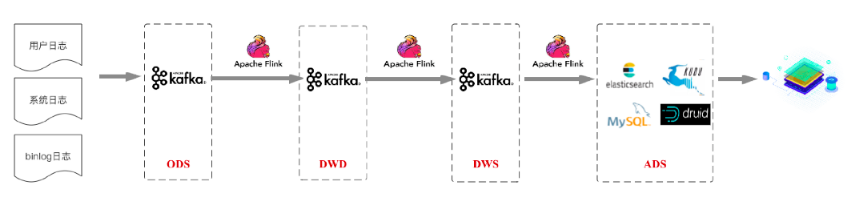
业内常用的实时数仓架构,是上边两张图展示的,把 Kafka 作为数仓各层的实际存储,但 Kafka 数据保留周期短、只支持 append 不支持 upsert/delete 。
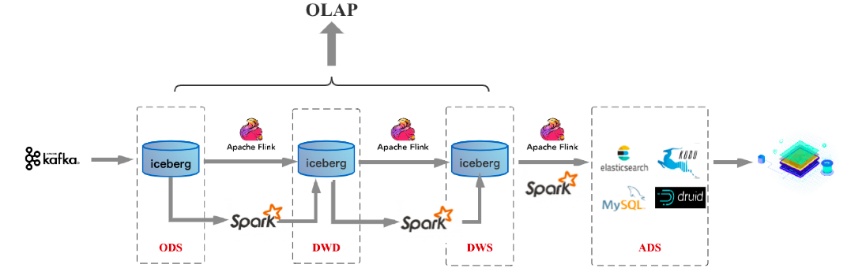
上图是采用 Iceberg 作为数仓存储的 Lambda 架构,支持数据的 upsert/delete。当然 Iceberg 也可以换成 Hudi。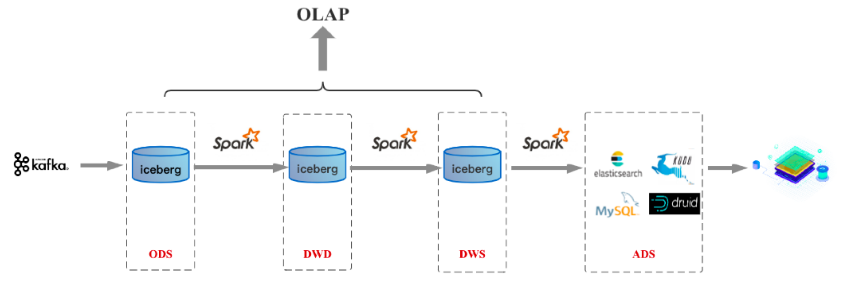
上图是流批一体的架构。相信未来很快 Flink 在批处理领域成熟到一定程度,也可以替换到 Flink 。

若有收获,就点个赞吧
0 人点赞
