1. Yarn架构
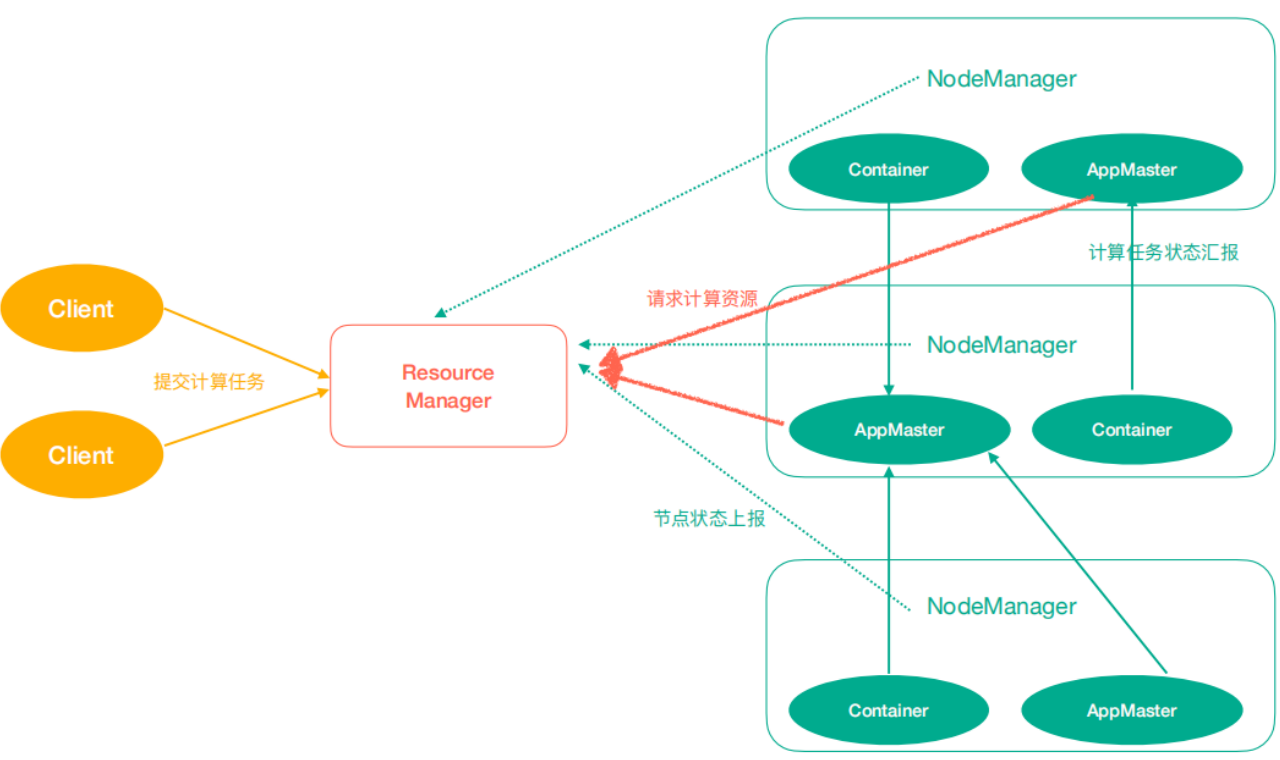
- ResourceManager(rm):
处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度
- NodeManager(nm):
单个节点上的资源管理、处理来⾃ResourceManager的命令、处理来自ApplicationMaster的命令
- ApplicationMaster(am):
数据切分、为应⽤程序申请资源,并分配给内部任务、任务监控与容错
- Container:
对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息
2. Yarn工作机制
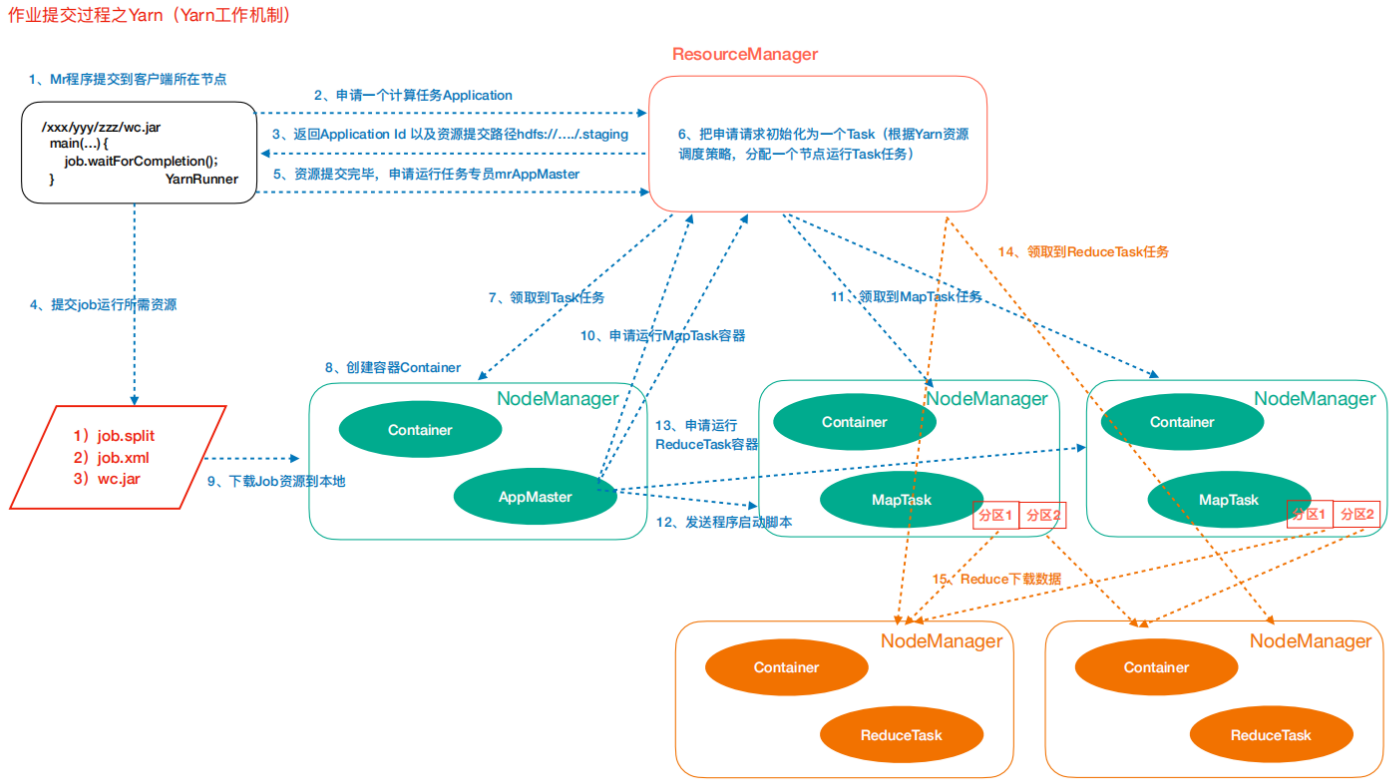
工作流程
- 作业提交
- Client调⽤job.waitForCompletion⽅法,向整个集群提交MapReduce作业。
- Client向RM申请⼀个作业id。
- RM给Client返回该job资源的提交路径和作业id
- Client提交jar包、切片信息和配置⽂件到指定的资源提交路径
- Client提交完资源后,向RM申请运⾏MrAppMaster
- 作业初始化
- 当RM收到Client的请求后,将该job添加到容量调度器中
- 某⼀个空闲的NM领取到该Job
- 该NM创建Container,并产⽣MRAppmaster
- 下载Client提交的资源到本地
- 任务分配
- MrAppMaster向RM申请运行多个MapTask任务资源
- RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器
- 任务运行
- MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序
- MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
- ReduceTask向MapTask获取相应分区的数据。
- 程序运⾏完毕后,MR会向RM申请注销自己
- 进度和状态更新
YARN中的任务将其进度和状态返回给应⽤管理器
客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户
- 作业完成
除了向应⽤管理器请求作业进度外, 客户端每5秒都会通过调⽤ waitForCompletion()来检查作业是否完成,时
间间隔可以通过 mapreduce.client.completion.pollinterval来设置。作业完成之后, 应⽤管理器和Container会
清理⼯作状态。作业的信息会被作业历史服务器存储以备之后⽤户核查。
3. yarn调度策略
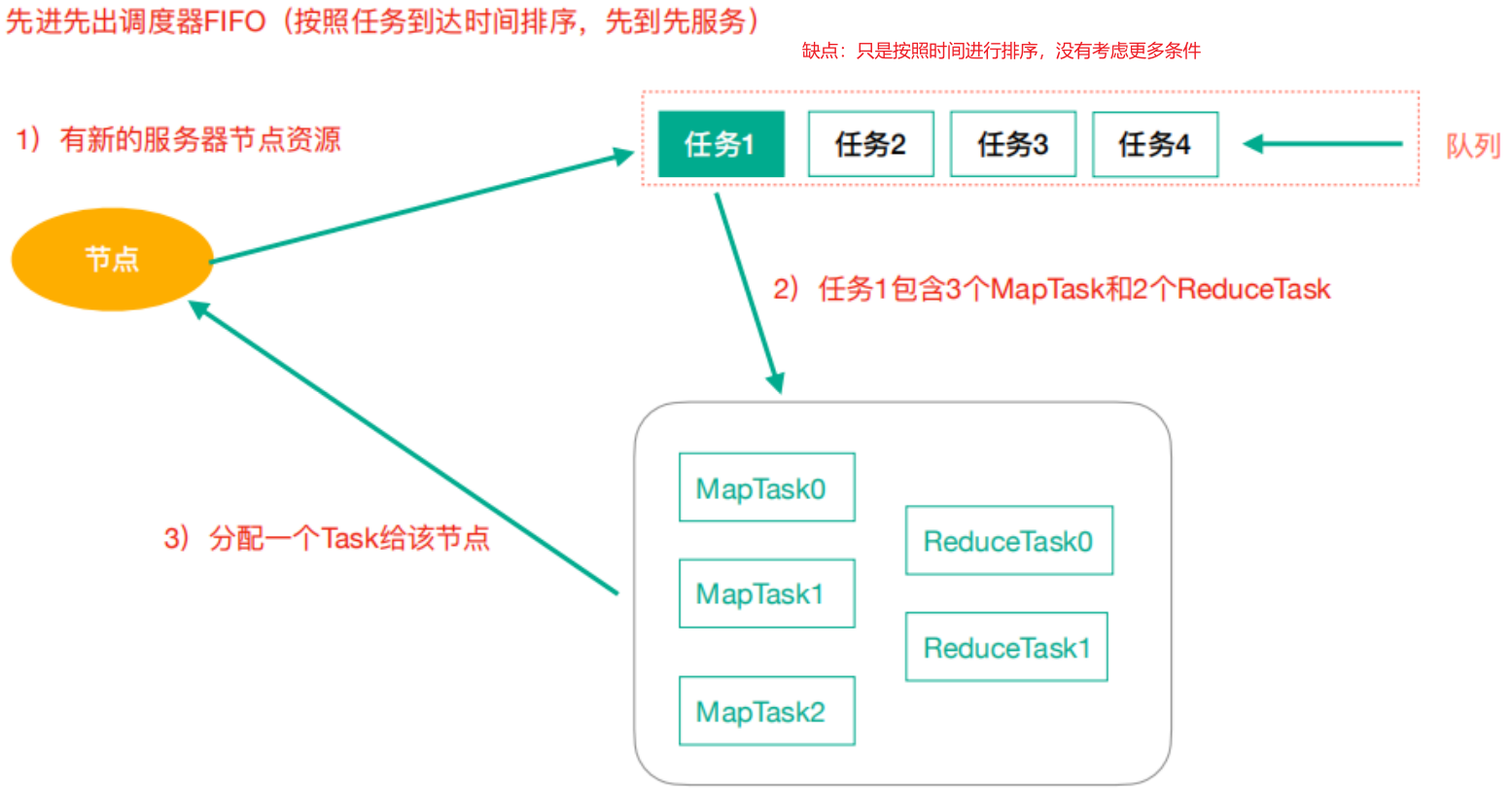
Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop2.9.2默认的资源调度器是Capacity Scheduler。
3.1 FIFO(先进先出调度器)
3.2 容量调度器
Apache Hadoop默认使⽤的调度策略。Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的⼀部分计算能⼒。通过为每个组织分配专⻔的队列,然后再为每个队列分配⼀定的集群资源,这样整个集群就可以通过设置多个队列的⽅式给多个组织提供服务了。除此之外,队列内 部⼜可以垂直划分,这样⼀个组织内部的多个成员就可以共享这个队列资源了,在⼀个队列内部, 资源的调度是采⽤的是先进先出(FIFO)策略。
缺点:当任务较少时,不能充分发挥集群的潜力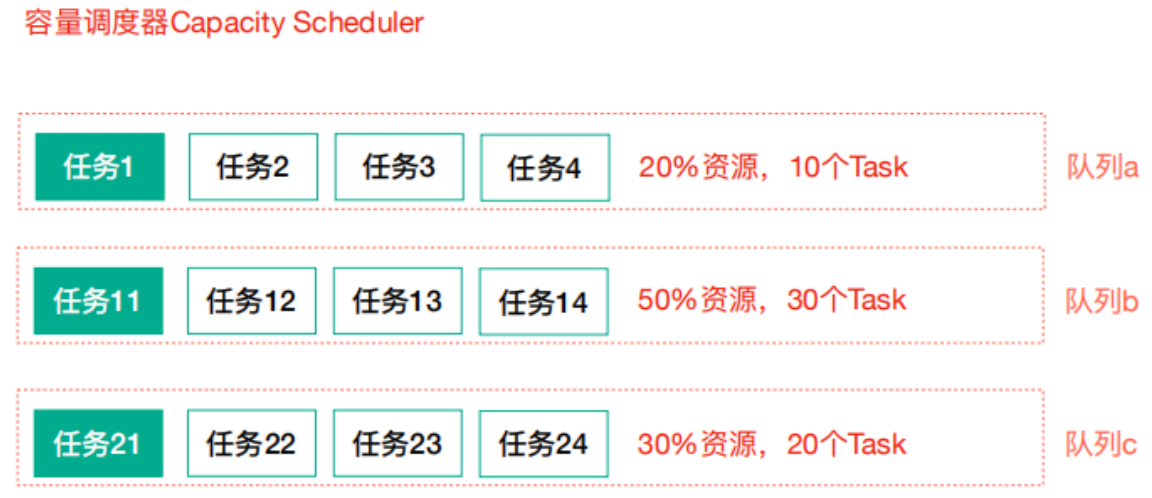
3.3 Fair Scheduler(公平调度器,CDH版本的hadoop默认使用)
Fair调度器的设计目标是为所有的应⽤分配公平的资源(对公平的定义可以通过参数来设置)。公平调度在也可以在多个队列间⼯作。举个例⼦,假设有两个⽤户A和B,他们分别拥有⼀个队列。 当A启动⼀个job而B没有任务时,A会获得全部集群资源;当B启动⼀个job后,A的job会继续运 ⾏,不过⼀会⼉之后两个任务会各⾃获得⼀半的集群资源。如果此时B再启动第⼆个job并且其它 job还在运⾏,则它将会和B的第⼀个job共享B这个队列的资源,也就是B的两个job会⽤于四分之 ⼀的集群资源,⽽A的job仍然⽤于集群⼀半的资源,结果就是资源最终在两个⽤户之间平等的共享
3.4 调度器配置
Yarn集群资源设置为A,B两个队列
- A队列设置占⽤资源70%,主要⽤来运⾏常规的定时任务
- B队列设置占⽤资源30%主要运⾏临时任务
- 两个队列间可相互资源共享,假如A队列资源占满,B队列资源⽐较充裕,A队列可以使⽤B队列的资源,使总体做到资源利用最大化.
- 选择使用Fair Scheduler调度策略!!
具体配置
yarn-site.xml
<!-- 指定我们的任务调度使⽤fairScheduler的调度⽅式 --><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description>In case you do not want to use the defaultscheduler</description></property>
创建fair-scheduler.xml⽂件,在Hadoop安装目录/etc/hadoop创建该文件
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <allocations> <defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy> <queue name="root" > <queue name="default"> <aclAdministerApps>*</aclAdministerApps> <aclSubmitApps>*</aclSubmitApps> <maxResources>9216 mb,4 vcores</maxResources> <maxRunningApps>100</maxRunningApps> <minResources>1024 mb,1vcores</minResources> <minSharePreemptionTimeout>1000</minSharePreemptionTimeout> <schedulingPolicy>fair</schedulingPolicy> <weight>7</weight> </queue> <queue name="queue1"> <aclAdministerApps>*</aclAdministerApps> <aclSubmitApps>*</aclSubmitApps> <maxResources>4096 mb,4vcores</maxResources> <maxRunningApps>5</maxRunningApps> <minResources>1024 mb, 1vcores</minResources> <minSharePreemptionTimeout>1000</minSharePreemptionTimeout> <schedulingPolicy>fair</schedulingPolicy> <weight>3</weight> </queue> </queue> <queuePlacementPolicy> <rule create="false" name="specified"/> <rule create="true" name="default"/> </queuePlacementPolicy> </allocations>向特定队列提交任务
// 假设有default,queue1,queue2三个队列 Configuration conf = new Configuration(); conf.set("mapred.job.queue.name", "queue2");reduce输出时的分隔符确定
Configuration conf = new Configuration(); //设置MapReduce的输出的分隔符为逗号 conf.set("mapred.textoutputformat.ignoreseparator", "true"); conf.set("mapred.textoutputformat.separator", ",")

若有收获,就点个赞吧
0 人点赞
