1. 接口爬取地址
2. 爬取实现方式
由于B站对接口有请求限制保护,会对短时间的大量请求进行封ip处理,而IP地址恢复时间需要4-6小时,所以目前采用的方案是多线程+动态ip的形式去爬取数据,以下是具体实现过程。
1. 云函数定时触发事件,触发爬虫服务执行函数。
2. 云函数去服务器获取动态ip地址+port以及从服务器的Redis中获取b站用户的cookie信息,用于组装请求使用。
3. 服务器组装第三方网址账号信息数据,请求三方网址接口。
4. 服务器得到返回结果后,对ip+port进行有效性验证,采用的方式是用这个动态ip去访问一次b站的接口,如果正确返回,则返回;不然则重新获取。
5. 云函数访问数据库,获取需要爬取的视频。
6. 云函数从线程池获取5个线程,并将视频数据进行分片,按照每个线程1000个视频数据去爬取视频数据。
7. 假如某个线程动态ip失效了,访问不了B站接口,会重新去服务器上获取新的ip+port,并对访问失效的视频数据重新访问,获取数据
8. 每个线程获取到视频数据后,会将数据进行解析,并封装成MQ消息,发送出去,每一个视频就是一个MQ消息。
9. 服务端订阅消息,解析MQ消息体,并将其存入数据库中。
10. 当所有视频爬取完后,线程池关闭,云函数执行成功,腾讯云控制台打印相应日志结果。
获取作者数据、视频标签与上述过程一致,只是访问接口不同,爬取频率是一天一次。爬取排行榜数据是另一个云函数触发爬取的,这个访问接口数量少,所以使用单线程执行,也不使用动态ip,也是通过http请求去爬取个分区的排行榜,接口一次返回100个数据,共13个分区,即13次请求,1300条视频数据,还有热门数据,一次请求返回50个视频数据,需要请求2次,共100个视频数据,以及热词是请求一次返回10条热词数据,故执行一次,共请求16次请求,1400条视频数据 10条热词数据。周期频率是每一个小时爬取一次,一天是 33600条视频数据 240条热词
第二个是多线程执行 是通过http请求访问每一个视频数据的接口,一条视频即一次请求,请求次数较多,b站会将请求ip给封闭,禁止访问,所以需要使用动态ip池去进行访问,执行策略是这样的,通过ip池获取ip,并将改ip请求伪造成浏览器请求去访问,当返回结果非success时,则再去ip池去获取。请求次数和数据库中视频数以及作者数相关,并且为了提高效率,采用了线程池+多线程的方式去进行数据爬取,周期频率是半天一次。
数据保存的实现是通过消息进行处理,每一条视频作者的数据就是一个消息,后续服务端通过订阅消息,将视频作者数据进行保存。爬取和持久化的过程是异步化的
持久化是通过mybatis-plus+druid实现的
具体实现流程图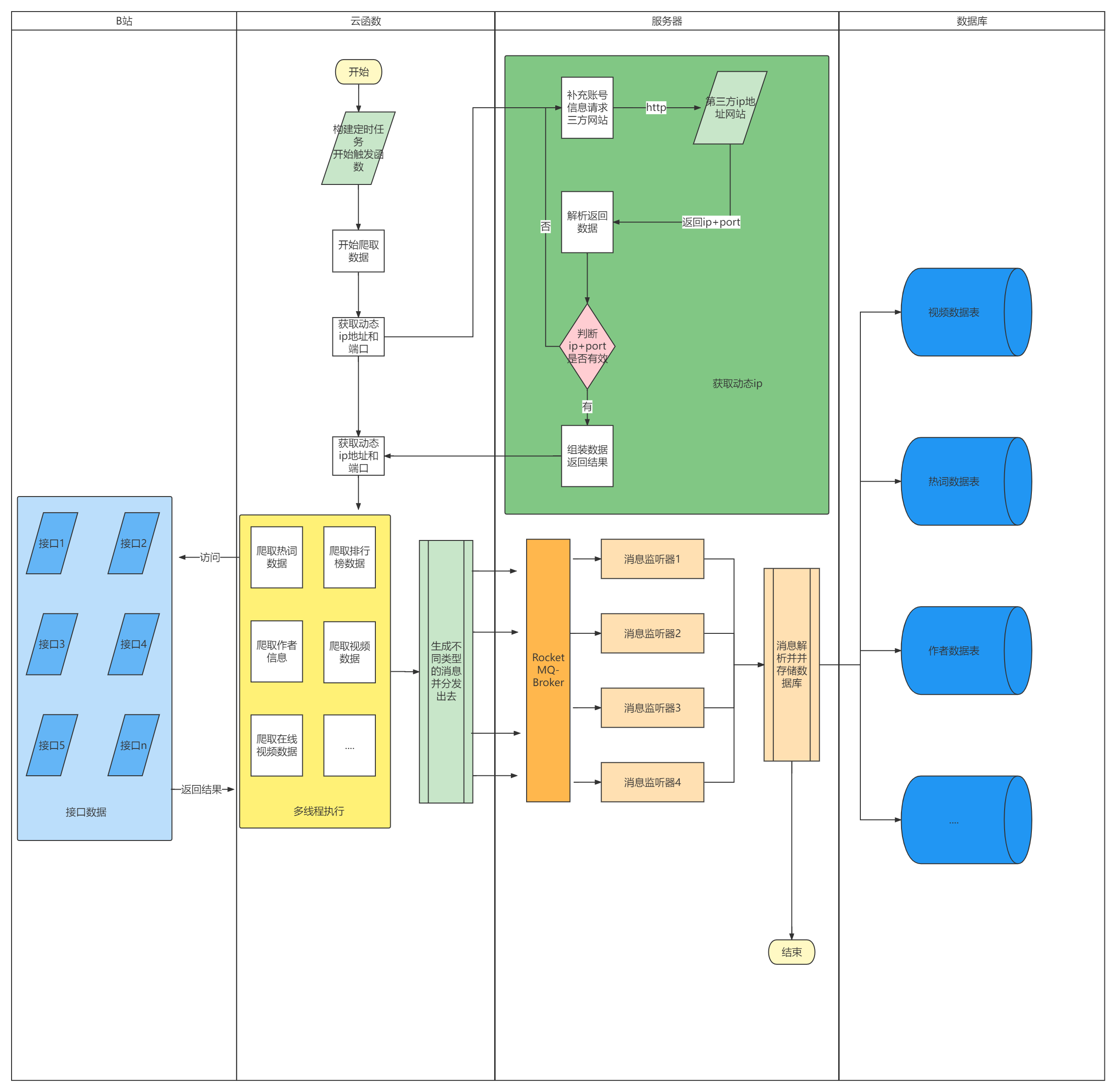
MQ订阅设计
数据保存的实现是通过消息进行处理,每一条视频作者的数据就是一个消息,后续服务端通过订阅消息,将视频作者数据进行保存。爬取和持久化的过程是异步化的,数据持久化是通过mybatis-plus+druid实现的。
其中MQ消息的订阅采用工厂模式和代理模式实现,通过注解的形式监听订阅消息,其中核心组件是RocketMessageListenerContainer 该组件是一个Consumer容器,容器实现了Spring的SmartLifecycle接口,容器的生命周期由Spring容器进行智能控制 系统中的所有Consumer的生命周期由该容器进行管理。容器可以对Consumer的消费行为进行控制和管理,同时提供Consumer 各个运行信息的获取接口。
RocketMessageListenerContainer 创建建MqPushConsumerFactory监听工厂该工厂实现ApplicationContextAware,InitializingBean两个接口,由Spring容器进行管理,通过监听工厂创建消费者,并根据注解RocketMQListener和RocketListeners获取消费类的信息和实际执行的方法,通过注解RocketMQListener属性上tag匹配具体的执行方法,并将消息体内容以String的形式作为执行方法的入参。
后续通过fastjson工具包,将消息解析成我们需要的对象,并最近将其储存在数据库中,由于消息中间件的作用,数据的爬取和数据的存储是分割开的,大大提升了数据爬取的处理速度。

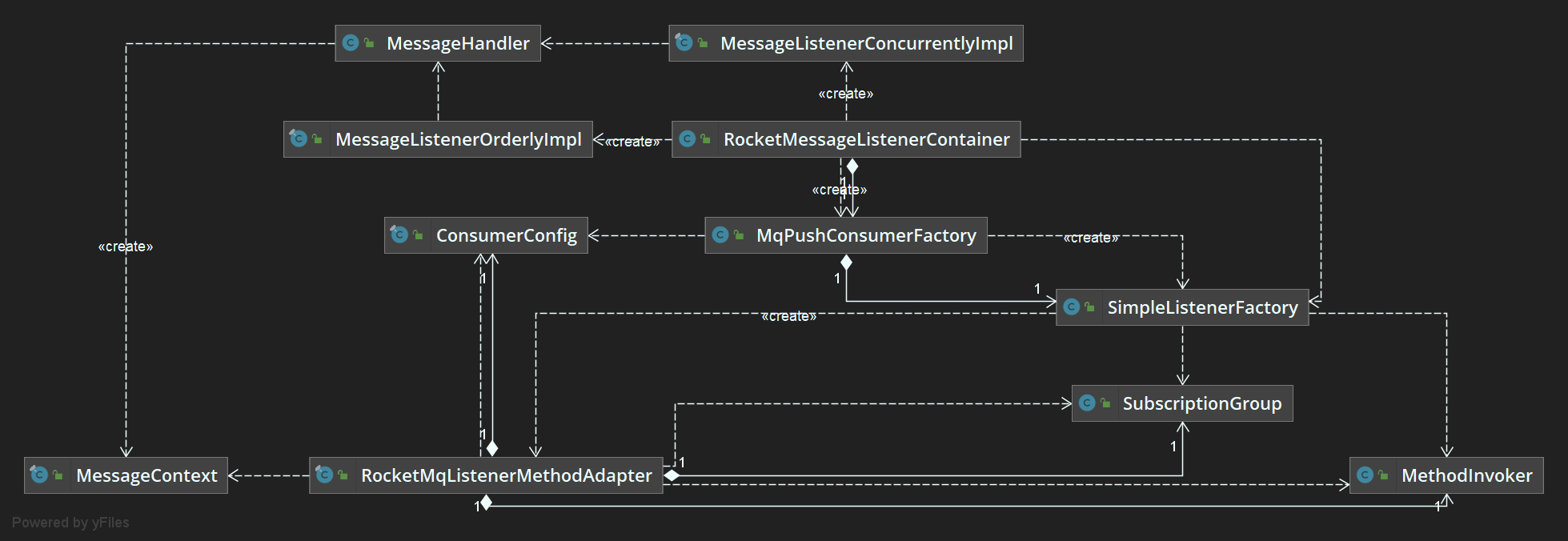
核心代码实现
@Slf4j@RocketListeners(topic = "BDATA",consumerGroup = "CID_YUQIN")public class BdMsgListener {@Resourceprivate BdVideoOperationService bdVideoOperationService;@Resourceprivate BdHotWordsOperationService bdHotWordsOperationService;@RocketMQListener(tag = "RANK_LIST")public void getVideoList(String msg) {BdVideoListMsg bdVideoListMsg = JSON.parseObject(msg, BdVideoListMsg.class);bdVideoOperationService.saveMessage(bdVideoListMsg);}@RocketMQListener(tag = "HOT_WORDS")public void getHotWords(String msg) {List<BdHotWordsDTO> bdHotWordsDTOList = JSON.parseArray(msg, BdHotWordsDTO.class);bdHotWordsOperationService.saveMessage(bdHotWordsDTOList);}}
服务流程图

若有收获,就点个赞吧
0 人点赞
