整个项目的重难点主要是三个方面第一是数据挖掘、第二是自动化部署、第三点是权限校验。其他增删查改的功能我这就不展开来说,也比较简单。
数据挖掘
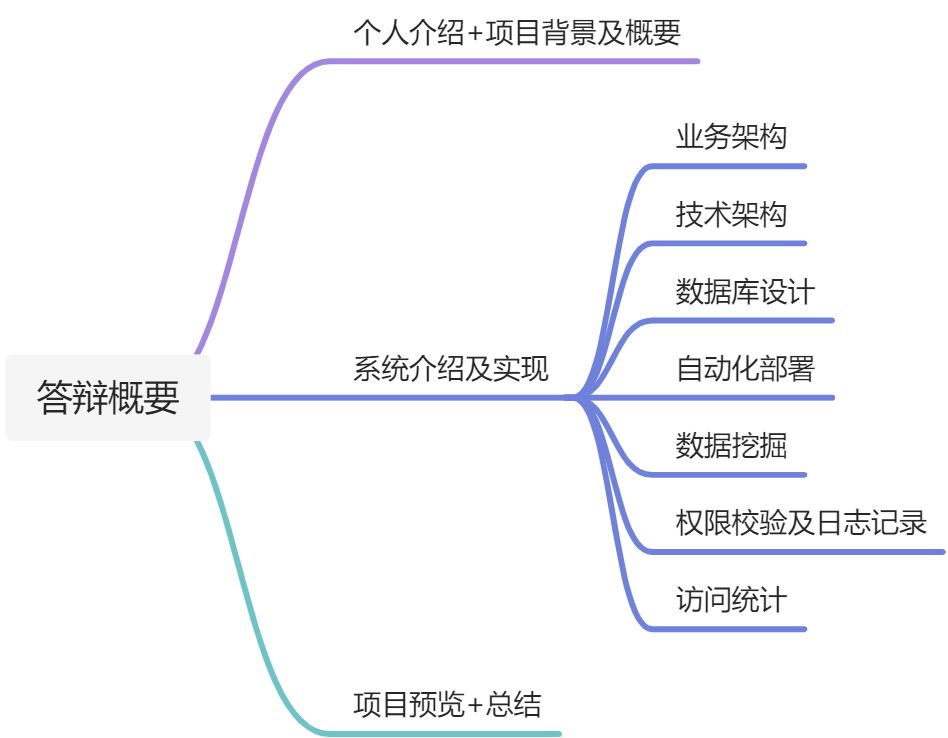
数据挖掘部分主要是通过云函数+MQ+MySQL实现的。云函数是个fass服务,Functions as a service,函数即服务,通过事件去触发方法,最大的优点就是节省资源,算力强大,部署简单。因为要爬取B站数据,需要大量的访问接口和存储,这个过程极其消耗服务器的资源,所以我采用了云函数的形式将数据挖掘部分单独部署出去,通过MQ进行异步化存储。数据爬取的过程中也有许多问题,比如其中一个最大的问题就是B站为了保护接口正常访问,会对一些数据接口进行高并发访问的ip地址封闭处理,这导致我们不能用一台两台服务去爬取大量B站视频数据,所以这部分需要使用动态ip进行代理访问。
整个爬取的过程如图所示,云函数中设置了定时任务,会定时触发函数,函数启动后,会去我服务器中获取动态的ip,服务器会去第三方网站获取动态ip(需要进行购买,价格是1元100个),服务器组装好购买凭证数据后,通过http请求获取,获取到之后,会对ip进行验证,验证有效后,返回给云函数。
云函数通过该动态ip去请求视频数据接口,这里我计算过一个动态ip大概可以爬取1k次,即1k条数据,一元100个,所以1元=10万条数据,而且视频还有弹幕,评论,标签等数据,所以我目前没这么多资本去获取所有的B站视频数据,而且我动态ip也使用完了,目前采取的视频的数据是来自于B站的热门数据和排行榜的数据,共有13个榜单,加上热门就是14个榜单,一个榜单一次100条数据,所以一次就是1400条数据,每4个小时执行一次,每天执行6次,一天就是8400条数据,将近1w这样。
数据获取完以后,将视频数据转化为MQ消息,发送出去,因为RocketMQ具有极高的并发量,对于这点数据量绰绰有余,而后我服务器订阅MQ,将消息进行顺序消费,将消息解析完成以后存储到数据库中。这个爬取个存储过程是解耦且异步的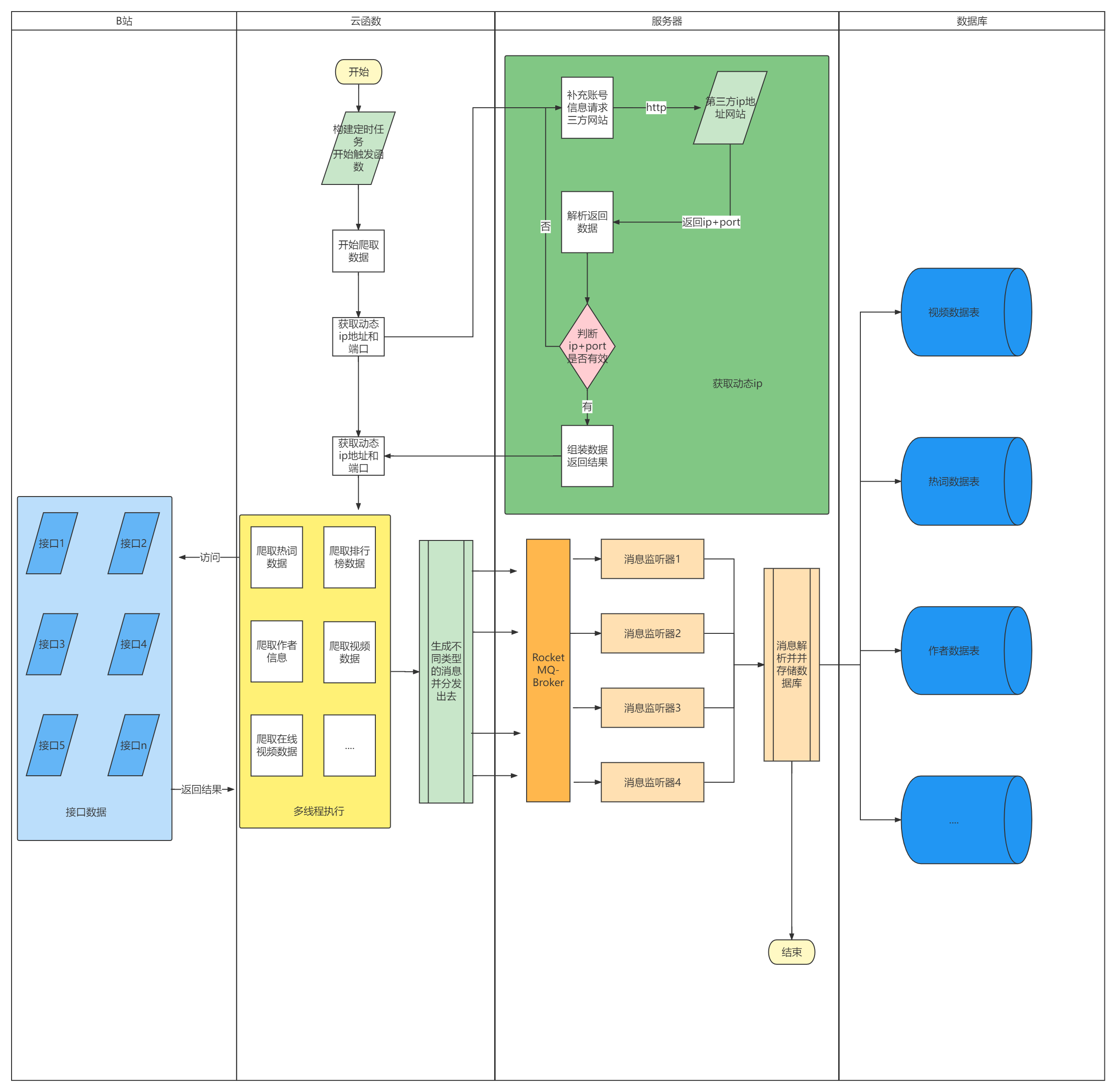
自动化部署
这部分主要就是CI/CD,方便开发者快速进行部署上线,主要用到的是maven+docker+Jenkins+Git;
主要自动化部署流程如下,开发者将代码开发完后,通过git提交代码到github或者其他代码平台中,这些平台有个钩子函数webhook,当开发者提交代码后会自动触发这个钩子函数,钩子函数会去触发个人服务器的Jenkins,Jenkins将代码平台代码拉下来,并在服务器上将项目打包成jar包,随后执行脚本,脚本内容主要是将jar包构建成docker镜像,构成镜像后将docker镜像部署成docker容器,最后启动docker容器完成整个项目的自动化部署,部署完成后可以选择使用邮件等通知开发者部署成功,个人服务器的前端,后端,云函数都是通过这套自动化部署流程执行的,只是中间脚本内容不一样,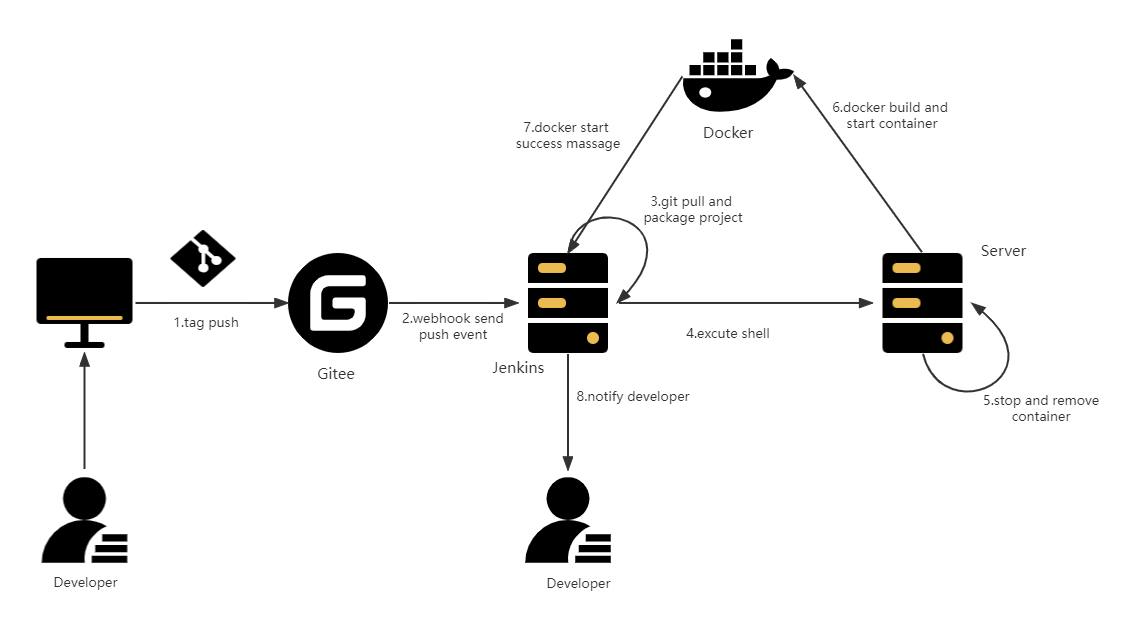
权限控制
权限控制主要是通过springsecurity+redis+jwt实现的

www.lenyuqin.site

若有收获,就点个赞吧
0 人点赞
