1.Qos概述
1.1 Qos简介
- 随着网络技术的飞速发展,互联网中的业务越来越多样化。除了传统的WWW、E-Mail、FTP应用外,企业还尝试在Internet上拓展新业务,比如IP电话、电子商务、多媒体游戏、远程教学、远程医疗、可视电话、可视电话、电视会议、视频点播、在线电影等。企业用户也希望通过VPN技术,将分布在各地的分支机构连接起来,开展一些事务性应用,比如访问公司的数据库或通过Telnet管理远程设备。
- 网络的普及,业务的多样性,使互联网流量激增,产生网络拥塞,转发时延增加,严重时还会产生丢包,导致业务质量下降甚至不可用。所以,要在IP网络上开展这些实时性业务,就必须解决网络拥塞问题。QoS技术就是在这种背景下发展起来的。
1.2 服务质量类型
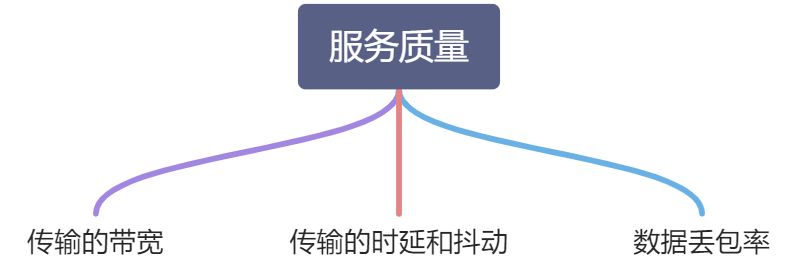
带宽: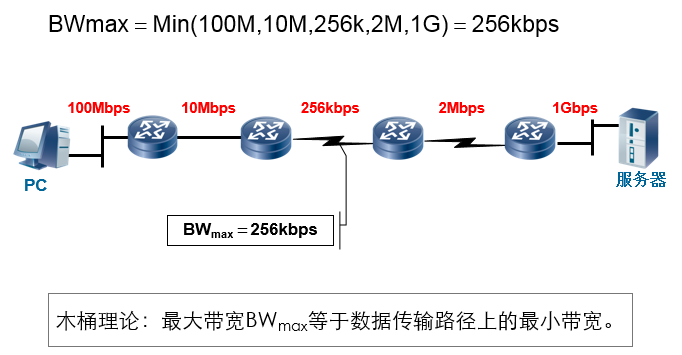
端到端时延: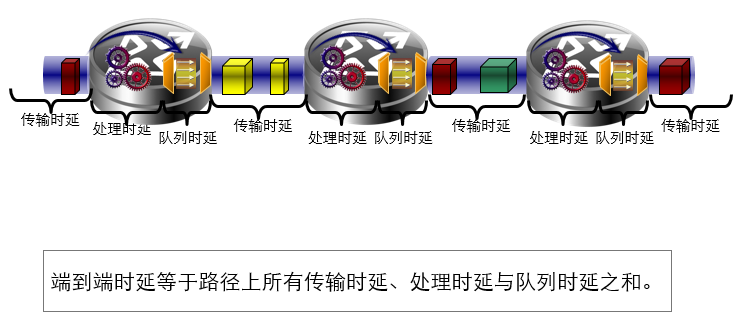
抖动: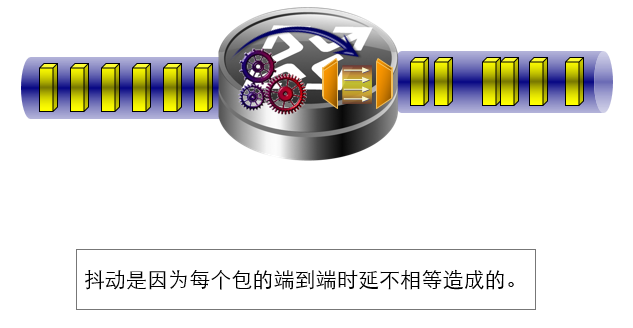
丢包: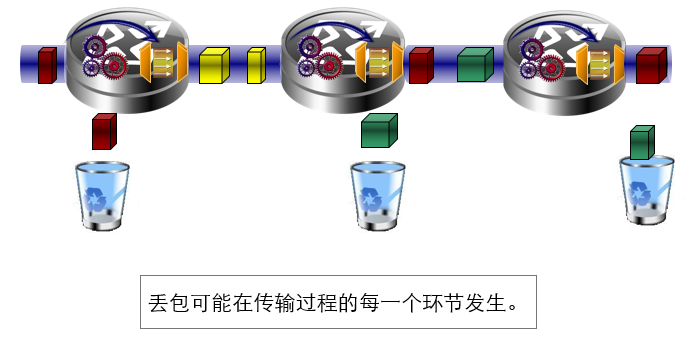
1.3 Qos服务模型

1.3.1 Best-Effort(尽力而为服务模型)
- 路由器及交换机等数据通信设备主要是分组交换设备,通过TCP/IP协议栈对每一个分组独立地选择传输路径,采用的是统计复用的方式,不像时分复用(TDM)那样具有专用连接的概念。传统的IP只提供单一的服务类型——尽力而为的服务,在这样服务方式下,所有经过网络传输的分组具有相同的优先级,尽力而为意味着IP网络会尽一切可能将分组正确完整的送到目的地,但不能确保分组在传输过程中不发生丢弃、损坏、重复、失序及错送等现象。另外也不对分组传输质量相关的传输特性(如传输时延、时延抖动等)作出任何承诺。
- 严格意义上说尽力而为的服务并不能归于QOS技术,但这是目前整个Internet所使用的主要服务模型,所以我们需要对它有一些了解。
- 尽力而为并不是一个贬义词,正因为这种服务模型才使得Internet有今天的发展,当然随着Internet的发展,这种尽力而为的服务模型已经不能完全满足越来越广泛地应用,因此服务提供商们有必要在现有的尽力而为服务基础上提供多种服务类型,使得每一种服务类型能够满足特定的性能要求。
- 尽力而为服务通过先进先出(FIFO)队列来实现。
1.3.2 Integrated Services Model(集成服务模型)
- 在集成服务模型中,负责传送QoS请求的信令是RSVP(Resource Reservation Protocol,资源预留协议),它通过路由器应用程序的QoS需求。RSVP是在应用程序开始发送报文之前来为该应用申请网络资源的,所以是带外(Out-Bind)信令。
集成服务模型可以提供以下两种服务:
- 保证服务(Guaranteed Service):它提供保证的带宽和时延来限制和满足应用程序的要求。如VoIP应用可以预留10M带宽和要求不超过1秒的时延。
负载控制服务(Controlled-Load Service):它保证即使在网络过载(Overload)的情况下,能对报文提供近似于网络未过载类似的服务,即在网络拥塞的情况下,保证某些应用程序的报文低延时和高通过。
集成服务模型是IETF于1993年开发的一种在IP网络上支持多种类型的机制,它的目的是在IP网络中同时支持实时服务的传统的尽力而为服务,它是一种基于为每个信息流预留资源的结构。
- 保证服务模型要求源和目的主机通过交换RSVP信令信息,在源和目的主机之间传输路径上的每一个节点中建立分组分类和转发状态。
- 保证服务模型需要为每一个流维持一个转发状态,因此可拓展性较差,而且Internet上有上百万的流量,为每个流维护状态对设备消耗巨大,因此保证服务模型一直没有真正的投入使用。
- 近来对RSVP进行了修改,使其支持资源预留合并,并可以和区分服务配合使用,特别是MPLS VPN技术的发展,使得RSVP又有了新的发展。但在QoS技术上,保证服务模型在实际应用中还是没有被广泛的应用。而区分服务模型恰恰解决了保证服务模型的弊端,成为目前使用最广泛的QoS技术。
1.3.3 Differentiated Services Model(区分服务模型)
- 在采用区分服务模型的应用中,应用程序在发送报文前不必预先向网络提出资源申请,而是通过设置IP报文头部的QoS参数信息,来告知网络节点它的QoS需求。报文传输路径上的各个路由器都可以通过对IP报文头的分析来获知报文的服务需求类别。
- 在实施区分服务模型时,接入路由器需要对报文进行分类,并在IP报文头部标记服务类别。下游的路由器只需简单地识别这些服务类别,并进行转发。
- 因此,区分服务模型是一种基于报文流地QoS解决方案。
- 只能在单个节点上预留资源。

IP网络中的区分服务模型: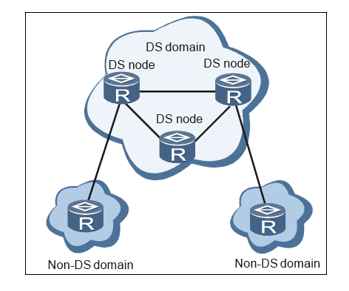
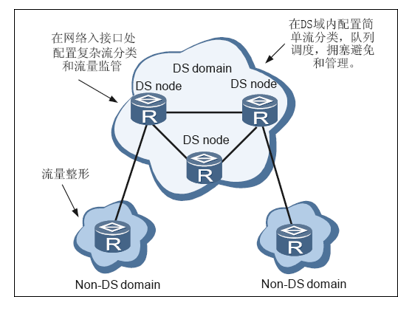
- DS节点:实现了区分服务模型功能的网络节点称为DS节点。
- DS域:由一组采用相同的服务提供策略和实现了相同PHB(per-Hop Behavior)集合的相连DS节点组成,如上图所示。
DS节点分为两种:
- DS边界节点:用于将DS域和非DS域连接在一起。DS边界节点需根据域间制定的流量控制协定TCA(Traffic Conditioning Agreement)进行流量控制并设置报文的DSCP(Differentiated Services CodePoint)值。
- DS内部节点:用于在同一个DS域中连接DS边界节点和其它内部节点。DS内部节点。DS内部节点仅需基于DSCP值进行简单的流分类以及对相应的流实施流量控制。
区分服务模型优先级映射: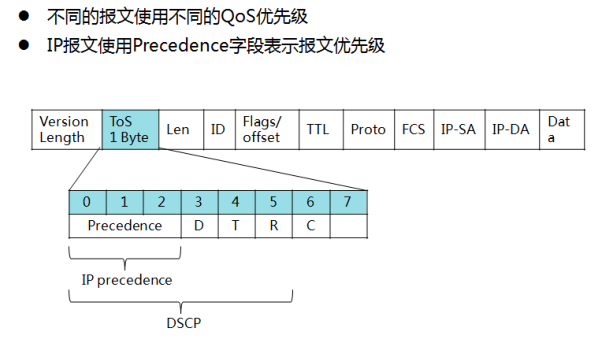
Precedence字段介绍:
- IP报文头ToS(Type of Service)域由8个比特组成,其中3个比特的Precedence字段标识了IP报文的优先级。
- 比特0~2表示Precedence字段,代表报文传输的8个优先级,按照优先级从高到低顺序取值为7、6、……、1和0。最高优先级是7或6,经常是为路由选择或更新网络控制通信保留的,用户级应用仅能使用0级~5级。ToS域中的比特6和7保留。
ToS域中还包括D、T、R三个比特:
- D比特表示延迟要求(Delay,0代表正常延迟,1代表低延迟)。
- T比特表示吞吐量(Throughput,0代表正常吞吐量,1代表高吞吐量)。
- R比特表示可靠性(Reliability,0代表正常可靠性,1代表高可靠性)。
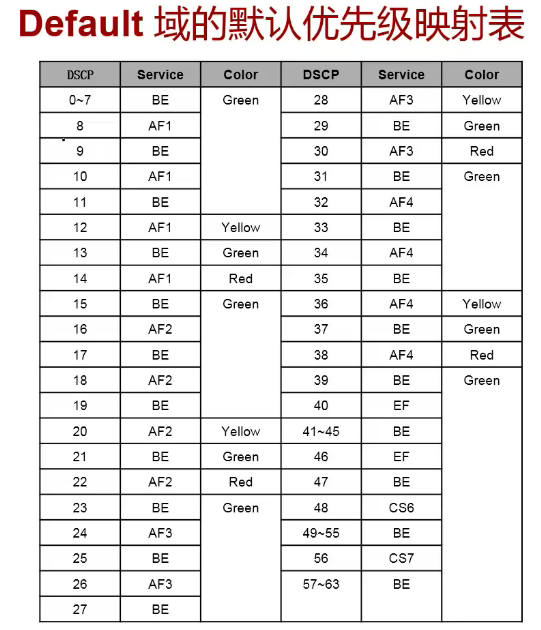
DSCP(DiffServ Code Point)字段介绍:RFC 2474重新定义了TOS字段,字段的前6个比特(高6比特)用来标识不同的业务类型,后2个比特(低2比特)保留未使用。根据这个定义,可以使用DSCP将流量分成64类。
- 每个DSCP值对应一个BA(Behavior Aggregate),然后可以对每一个BA指定一种PHB(比如转发、丢弃等),最后使用某些QoS机制(比如流量监管技术,队列技术等)来实现这个PHB。
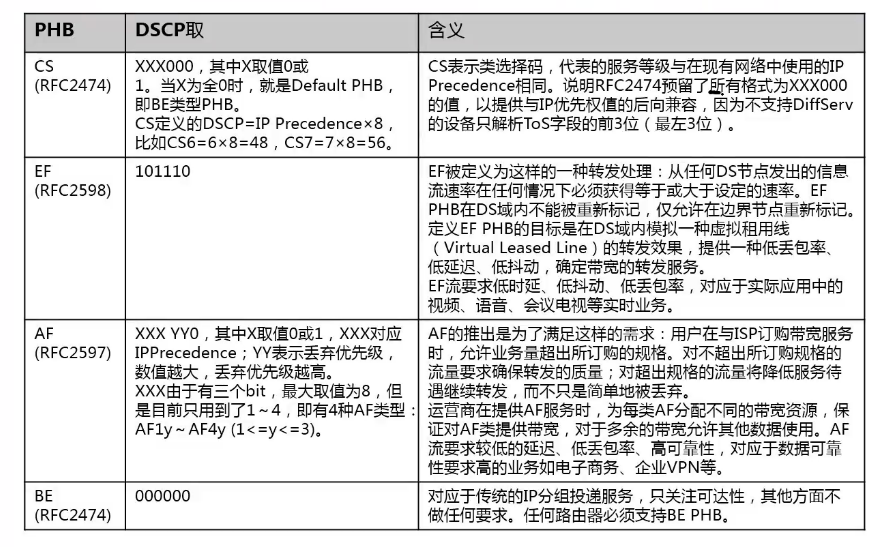
- DiffServ网络定义了四类PHB:
- EF(Expedited Forwarding)PHB:适用于低时延、低丢失、低抖动、确保带宽的优先业务,对应于实际应用中的视频、语音、会议电话等实时业务。
- AF(Assured Forwarding)PHB:分为四类(AF4、AF3、AF2、AF1),每个AF类又分为三个丢弃优先级,可以对相应业务进行等级细分,QoS性能参数低于EF类型。其目的推出是为了满足这样的需求:用户在与ISP订购带宽服务时,允许业务量超出所订购的规格。对不超过所订购规格的流量要求确保转发的质量,对超出规格的流量将降低服务待遇继续转发,而不只是简单的丢弃。AFxy中,x代表不同的类别,根据不同的分类后可以定义进入相对应的队列,y代表当队列被装满的时候丢包的概率,例如AF1类中的报文,其中丢包概率由小到大排序为AF11<AF12<AF13。
- CS(class selector)PHB:是从IP TOS字段演变而来,共8类;CS代表的服务等级与网络中使用的IP Precedence相同。在所有标准PHB中,CS的优先级最高。CS可以细分为CS7和CS6,默认用于协议报文,如企业内部各个交换机之间STP报文等。如果这些报文无法接收会引起协议中断。
- BE PHB(Default PHB):是CS中特殊一类,没有任何保证,现有IP网络流量也都默认为此类。对应于传统的IP报文投递服务,只关注可达性,其它方面 不做任何要求,任何交换机必须支持BE PHB。BE用于尽力而为的服务,用作不紧急、不重要、不需要负责的业务,如员工HTTP网页浏览业务。
- 在二层用CoS字段进行标记,正常的以太网帧是没有标记的,但是在ISL的报头和802.1Q的Tag中都有3bit 用来定义服务级别,从0到7,不过只有0-5可用,6和7都保留。
区分服务模型重要概念PHB:
- PHB(Per-Hop Behaviors),PHB是DS节点作用于数据流的行为。网络管理员可以配置DSCP到PHB的映射关系。PHB是网络节点对报文调度、丢包、监管和整形的处理,每类PHB都对应一组DSCP;如果DS节点接收到一个报文,检查其DSCP,发现未定义到PHB的映射,则DS节点将选择采用缺省PHB(即Best-Effort,DSCP=000000)进行转发处理。每个DS节点必须支持该缺省PHB。
PHB的分类,IETF DiffServ工作组目前定义了四种PHB:
- Default PHB:尽力而为BE(Best-Effort)
- Class-Selector PHB:类选择码CS
- Expedited Forwarding PHB:加速转发EF
- Assured Forwarding PHB:确保转发AF
CS PHB
- CS 表示类选择码,代表的服务等级与在现有网络中使用的IP Precedence 相同。DSCP 取值为“XXX000”,X 为0 或1。当X 为全0 时,就是Default PHB。
- EF PHB
- DSCP为“101 11 0” RFC2598;代表DiffServ网络中最高的服务质量,在有带宽确保的情况下,发包速度大于收包速度,适用于VoIP、虚拟租用线等实时业务;
- 可通过优先队列、低时延队列或RTP实时队列等多种队列机制来实现加速转发被定义为这样的一种转发处理:从任何DS 节点发出的信息流速率在任何情况下必须获得等于或大于设定的速率。
- EF PHB 在DS 域内不能被重新标记。仅允许在边界节点重新标记EF PHB,并且要求新的DSCP 满足EF PHB 的特性。
- 定义EF PHB 的目标是在DS 域内模拟一种虚拟租用线(Virtual Leased Line)的转发效果,提供一种低丢包率、低延迟、高带宽的转发服务。
- AF PHB
- 确保转发的推出是为了满足这样的需求。用户在与ISP 订购带宽服务时,允许业务量超出所订购的规格。对不超出所订购规格的流量要求确保转发的质量;对超出规格的流量将降低服务待遇继续转发,而不只是简单地被丢弃。
- 当前定义了四类AF,即AF1、AF2、AF3、AF4。每一类AF 业务的分组又可以细分为三种不同的丢弃优先级。AF 编码点AFij 表示AF 类为i(1<=i<=4),丢弃优先级为j(1<=j<=3)。
- 运营商在提供AF 服务时,为每类AF 分配不同的带宽资源。对AF PHB 的一个特别要求是:流量控制不能改变同一信息流中分组的顺序。比如,某一业务流中的不同分组归属同一AF 类,但在流量监管时被标记了不同的丢弃优先级,此时,虽然不同分组的丢包概率不同,但是他们之间的相互顺序不能改变。这种机制特别适合于多媒体业务的传输。
- AF的比较,只能是前面第一个数字相同时才有可比性,比如AF1,可以比较AF11、AF12、AF13,但是不能对AF1与AF2进行比较;
BE PHB
- 即传统的IP 分组投递服务,只关注可达性,其他方面不做任何要求。任何路由器必须支持BE PHB。
具体可以参考如下:[R1-drop-profile-data]dscp ?INTEGER<0-63> DSCP (DiffServ CodePoint) valueaf11 AF11 DSCP (001 01 0)af12 AF12 DSCP (001 10 0)af13 AF13 DSCP (001 11 0)af21 AF21 DSCP (010 01 0)af22 AF22 DSCP (010 10 0)af23 AF23 DSCP (010 11 0)af31 AF31 DSCP (011 01 0)af32 AF32 DSCP (011 10 0)af33 AF33 DSCP (011 11 0)af41 AF41 DSCP (100 01 0)af42 AF42 DSCP (100 10 0)af43 AF43 DSCP (100 11 0)cs1 CS1 (IP Precedence 1) DSCP (001 00 0)cs2 CS2 (IP Precedence 2) DSCP (010 00 0)cs3 CS3 (IP Precedence 3) DSCP (011 00 0)cs4 CS4 (IP Precedence 4) DSCP (100 00 0)cs5 CS5 (IP Precedence 5) DSCP (101 00 0)cs6 CS6 (IP Precedence 6) DSCP (110 00 0)cs7 CS7 (IP Precedence 7) DSCP (111 00 0)default Default DSCP (000000)ef EF DSCP (101 11 0)

1.4 实现QoS的相关技术
- 指的是在Dirr-Serv模型中的技术
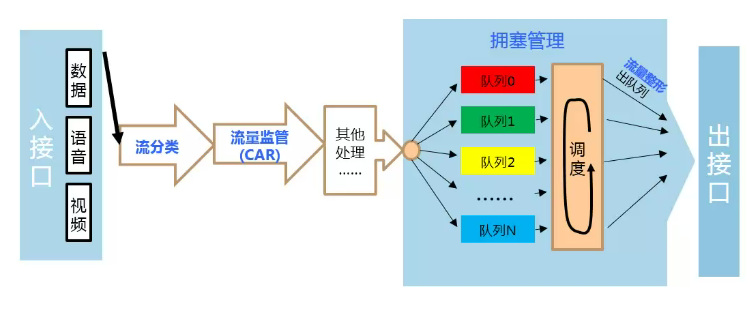
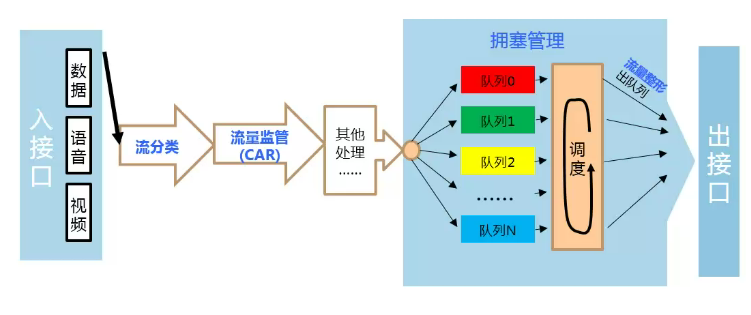
流分类、流量监管、流量整形、拥塞管理和拥塞避免是构造有区别地实施服务的基石。
- 流分类是基础,它依据一定的匹配规则识别出报文,是有区别地实施服务的基石。
- 而流量监管、流量整形、拥塞管理和拥塞避免从不同方面对网络流量及其分配的资源实施控制,是有区别地提供服务思想的具体体现。
流分类:依据一定的匹配规则识别出对象。流分类是有区别地实施服务的前提。
- 流量监管:对进入路由器的特定流量的规格进行监管。当流量超出规则时,可以采取限制或惩罚措施,以保护运营商的商业利益和网络资源不受损害。
- 流量整形:一种主动调整流的输出速率的流控措施,通常是为了使流量适配下游路由器可供给的网络资源,避免不必要的报文丢弃和拥塞。
- 拥塞管理:网络拥塞时必须采取的解决资源竞争的措施。通常是将报文放入队列中缓存,并采取某种调度算法安排报文的转发次序。
- 拥塞避免:过度的拥塞会对网络资源造成损害。拥塞避免监督网络资源的使用情况,当发现拥塞有加剧的趋势时采取主动丢弃报文的策略,通过调整流量来解除网络的过载。
1.5 四大QoS组件
- 四大组件包括:流分类、流量监管、拥塞管理、流量整形
2.流量分类与标记
2.1 流分类与标记概述
流量分类及标记是部署QoS的基础
- 流分类:可以根据ACL、以及报文自身信息对流量进行分类
- 标记:可以基于DSCP、IP Precedence、802.1P、MPLS EXP等信息对报文进行标记
虽然流量分类几乎可以根据报文的任何信息进行,但是流量的标记则一般只对IP报文的ToS域进行标记(根据所做的标记,执行后面的PHB)
2.2 流量分类
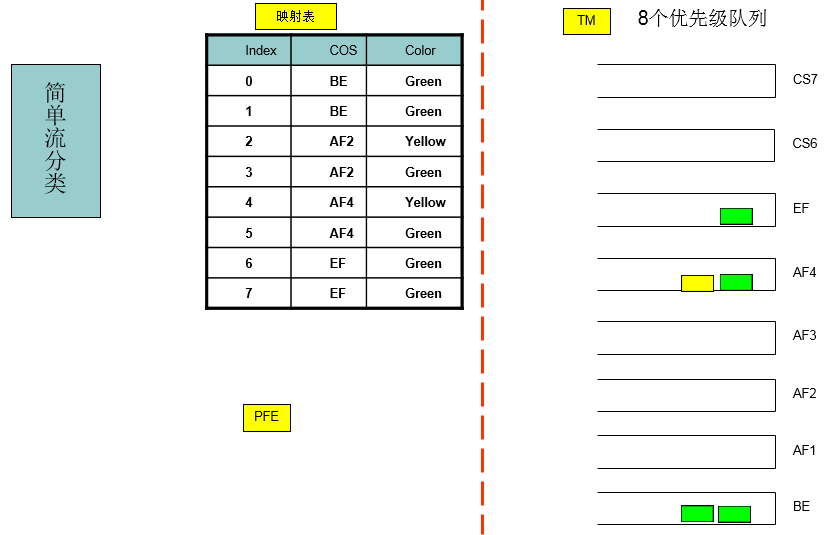
2.2.1 简单流分类
- 简单流分类是指采取简单的规则,如IP报文头中的DSCP/IP-PRE值,MPLS报文的EXP域值,VLAN报文头中的802.1P值对报文进行粗略的分类,以识别出具有不同优先级或服务等级特征的流量。
对应关系如下: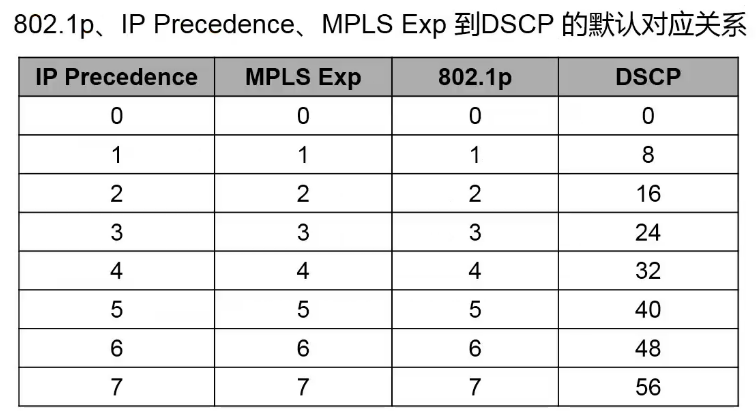
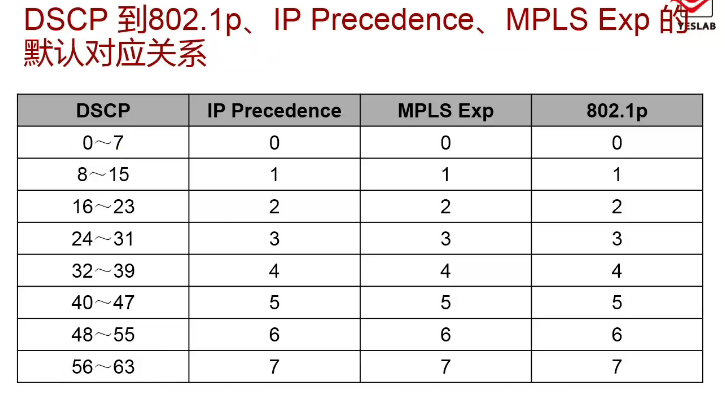
在华为路由器上,配置简单流分类就是配置DS域并定义该域中的优先级映射表,之后将DS域与信任的接口绑定。
2.2.2 复杂流分类
- 复杂流分类是指采用复杂的规则,如数据链路层、网络层、传输层信息(例如源MAC地址、目的MAC地址、源IP地址、目的IP地址、用户组号、协议类型或应用程序的TCP/UDP端口号等)对报文进行精细的分类。通常在Diff-Serv域的边界路由器上对流量进行复杂流分类。
2.2.3 QoS优先级映射
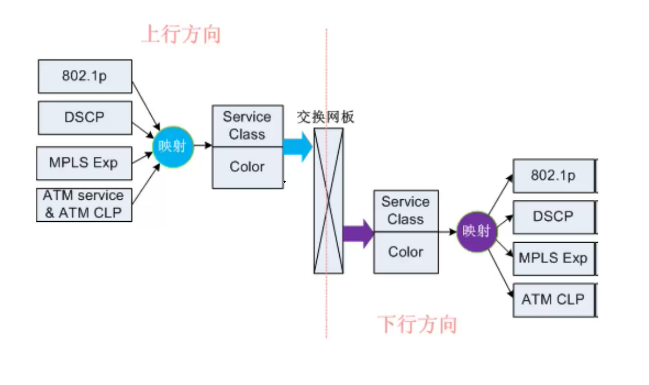
- 比如从IP域进入MPLS域的报文,优先级映射就是从DSCP到MPLS EXP。
2.3 简单流分类与标记
2.3.1 流量入方向以802.1P为例
- 实现业务内部映射
Color表示的是丢弃优先级(其它的标记可设置为)
- 通常于网络边界处对报文进行分类时,同时标记IP优先级或DSCP,这样,在网络的内部就可以简单的使用IP优先级或DSCP作为分类的标准。
- 而队列技术如WFQ、CBWFQ就可以使用这个优先级来对报文进行不同的处理。
下游(DownStream)网络可以选择接收上游(UpStream)网络的分类结果,也可以按照自己的分类标准对数据流量重新进行分类。
缺省的情况下,在MPLS网络的边缘,将IP报文的IP优先级直接拷贝到MPLS报文的EXP域。
2.3.2 流量出方向以802.1P为例
- 实现同域重标记或跨域保证服务等级不变
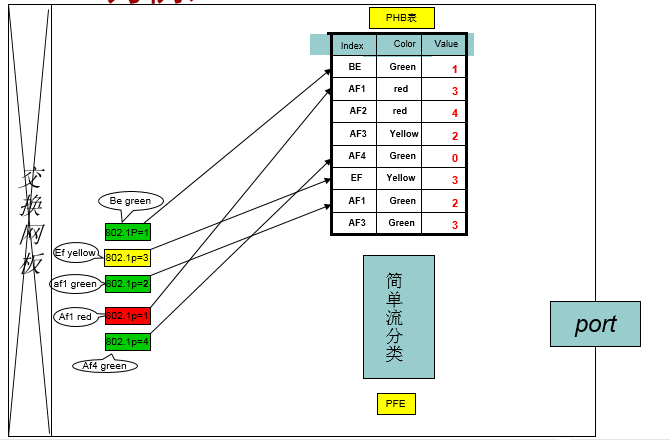
- 即数据从接口发出时进行了重新标记
2.3.3 在产品中的实现
华为路由器产品支持配置8个DS域
- 域:定义了一组分类规则,规定了带不同优先级(DSCP、MPLS EXP、802.1P等)的报文与内部优先级的映射关系,以及内部优先级与报文本身优先级的映射关系。
上行简单流分类:根据IP DSCP、MPLS EXP或802.1P将报文分为八种业务类型(CS7、CS6、EF、AF4-AF1、BE)、三种颜色(Green、Yellow、Red)(颜色就是丢弃优先级),从而区分不同的业务(如语音、视频、数据等)。在拥塞管理、队列调度时,不同业务进入不同的队列,得到差异化的调度。例如语音可以进入高优先级的PQ队列,保证低时延。上行若不做简单流分类,报文业务类型都为BE。(实现内部业务映射)
- 下游简单流分类:根据内部业务类型(CS7、CS6、EF、AF4-AF1、BE)、三种颜色(Green、Yellow、Red),重新设置报文的IP DSCP、MPLS EXP或802.1P,实现了重标记的功能,重新标记IP DSCP、MPLS EXP或802.1P。下游未配置简单流分类时,IP DSCP、MPLS EXP或802.1P不做改变。(实现数据发出时重标记)
配置举例(跨域保证服务等级不变)
在接口g3/0/0和g4/0/9,实现DSCP与EXP的映射。配置diffserv域,名称为d1[RT-0]diffserv domain d1配置报文入方向的映射关系[RT-0-dsdomain-d1]ip-dscp-inbound 34 phb af1 green配置报文出方向的映射关系[RT-0-dsdomain-d2]mpls-exp-outbound af1 green map 3在接口下应用简单流分类[RT-0-GigabitEthernet3/0/0]trust upstream d1[RT-1-GigabitEthernet4/0/9]trust upstream d1这样当DSCP为34的IP报文进入接口g3/0/0 后,根据简单流分类转换为路由器内部优先级af1(业务类型),green颜色参与队列调度,流量管理等处理。当报文出g4/0/9时,简单流分类将根据其内部的优先级Af1和颜色green标记报文的Exp值为3。
2.3.4 应用场景举例
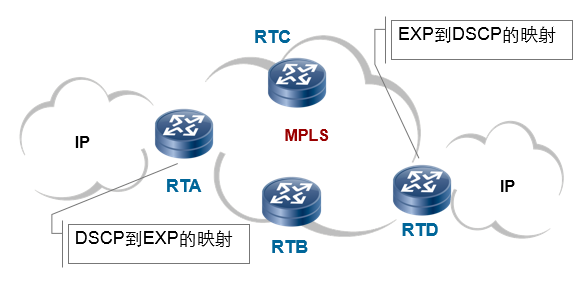
- 配置基于简单流分类的流量策略可以将一种网络流量中的优先级映射到另外一种网络流量中,使流量在另外一种网络中按照原来的优先级传送。(比如数据原来在IP网络,需要发往MPLS网络中,则需要将IP优先级相应地映射到MPLS的EXP中,但其实在同一种网络中,也可以做重标记)
- 在IP、MPLS、VLAN报文跨域转换时,可以使用简单流分类实现DSCP/IP-PRE/EXP/802.1P之间的映射,并保证报文的服务等级不受变化。(即如果还是在同一种网络类型中,使用这些标记来执行相关PHB)
- 简单流分类通常配置在网络的核心位置。
2.4 复杂流分类与标记
2.4.1 复杂流分类实例
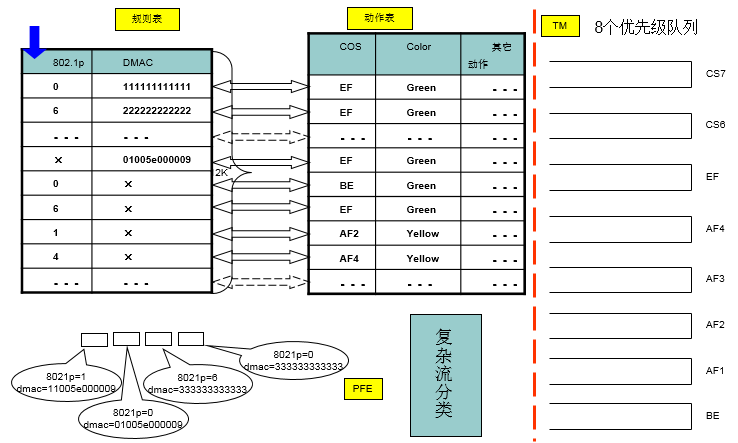
- 复杂流分类通过提取报文信息,如报文优先级、源IP、目的IP、源MAC、目的MAC、802.1P、报文封禁类型等等,组成关键字去匹配规则表,然后通过匹配规则得到一个索引,在根据索引查动作表,将报文映射为内部优先级,除了映射内部优先级外,复杂流分类还可以支持流量监管(CAR)、PBR(Policy-Based-Routing)、重标记、报文过滤、采样、镜像等其它动作。
2.4.2 在产品中的实现
- 在实现复杂流分类时分为两个部分:规则部分和动作部分。
- 当处理报文时,根据报文中用来分类的字段信息组成关键字,查找规则表;
- 如果报文能匹配上规则部分,则根据查找结果确定该规则对应的动作表,确定该报文应该执行何种动作。
- 如果报文没有匹配上任何一条规则,则报文不做分类按普通报文正常转发。
产品在实现复杂流分类时分为两部分:复杂流分类的规则部分与复杂流分类的动作部分。
[Huawei]traffic classifier 1 operator ?and Rule of matching all of the statementsor Rule of matching one of the statements
其中,operator and或operator or是可选操作符,默认是operator or。
- and表示流分类中各规则之间关系为“逻辑与”,如果流分类下定义了多个匹配规则,则必须满足所有规则的流量才属于该类。
- or表示流分类各规则之间是“逻辑或”的关系,如果流分类下定义了多个规则,数据报文至少要匹配其中一个规则,该流量才属于该类。
- 未显示定义operator时,流分类中各匹配规则之间的关系为“逻辑或”
1、创建复杂流分类的规则**
//定义一个名为c1的类。[Quidway] traffic classifier c1[Quidway-classifier-c1]
//配置一条匹配规则 dscp = 1。[Quidway-classifier-c1]if-match dscp 1
2、创建复杂流分类的动作部分
//定义一个名为b1的流行为。[Quidway] traffic behavior b1[Quidway-behavior-b1]
//配置一个重标记的动作。[Quidway-behavior-b1]remark dscp ef
3、将规则部分与动作部分结合起来,组成复杂流分类的流策略
//定义一个名为p1的策略。[Quidway] traffic policy p1
//在流策略p1中配置符合流分类c1的报文采用流行为b1。[Quidway] traffic policy p1[Quidway-trafficpolicy-p1]classifier c1 behavior b1
4、将该策略应用到接口上,复杂流分类功能生效
//将流量策略p1应用到接口GigabitEthernet 1/0/0的出方向上[Quidway] interface gigabitethernet1/0/0[Quidway-GigabitEthernet1/0/0]traffic-policy p1 outbound
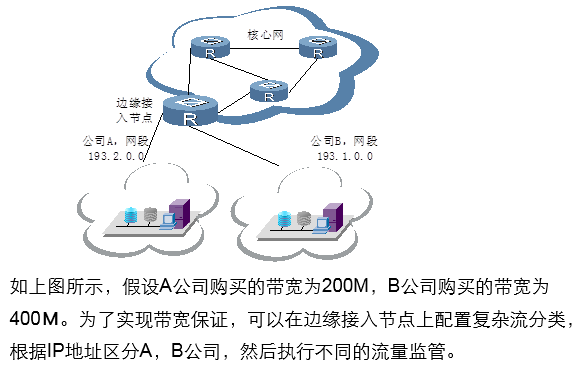
2.4.3 应用场景举例
3.流量监管与整形
3.1 流量监管(Traffic Policy)
- 对进来的数据进行处理
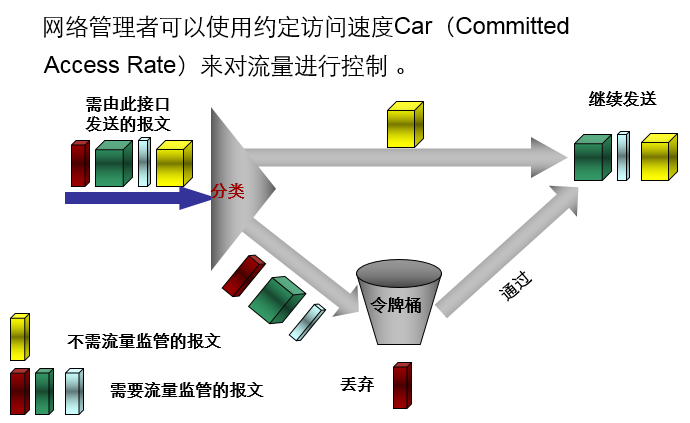
- CAR利用TB(Tocken Bucket - 令牌桶)进行流量控制,上图是CAR的处理过程,首先报文被分类,如果报文需要流量监管,则进入令牌桶中进行处理,如果令牌桶中有足够的令牌可以用来发送报文,则报文可以通过并被继续发送下去。
- 如果令牌桶中的令牌不满足报文的发送条件,则报文被丢弃。这样就可以对某类报文的流量进行控制。
- CAR可以对特定流量进行流量监管,对超出限额的流量进行丢弃或者重新标记。
3.1.1 Token Bucket:令牌桶
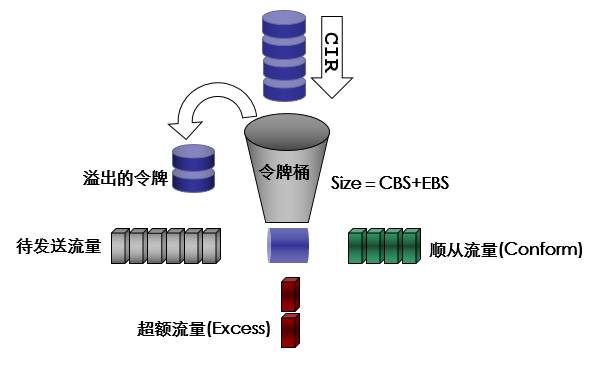
评估流量时,令牌桶的参数设置包括:
- 平均速率(Committed Information Rate):向桶中放置令牌的速率
- 突发尺寸(Cimmitted Burst Size):令牌桶的容量,每次突发所允许的最大流量尺寸,设置的突发尺寸必须大于最大报文长度
- 为了测量更复杂的情况,实施更灵活的调控策略,可以设置两个令牌桶。例如流量策略TP(Traffice Policing)中有三个参数
- 承诺信息速率CIR(Committed Information Rate)
- 承诺突发尺寸CBS(Committed Burst Size)
- 超出突发尺寸EBS(Excess Burst Size)它使用了两个令牌桶,每个桶投放令牌的速率一样,均为CIR,只是尺寸不同——分别为CBS和EBS,简称C桶和E桶,代表所允许的不同突发级别。每次测量时,依据“C桶有足够的令牌”、“C桶令牌不足,但E桶足够”以及“C桶和E桶都没有足够的令牌”的情况,可以分别实施不同的流控策略。
- 为了测量更复杂的情况,实施更灵活的调控策略,可以设置两个令牌桶。例如流量策略TP(Traffice Policing)中有三个参数
3.1.2 单速单桶
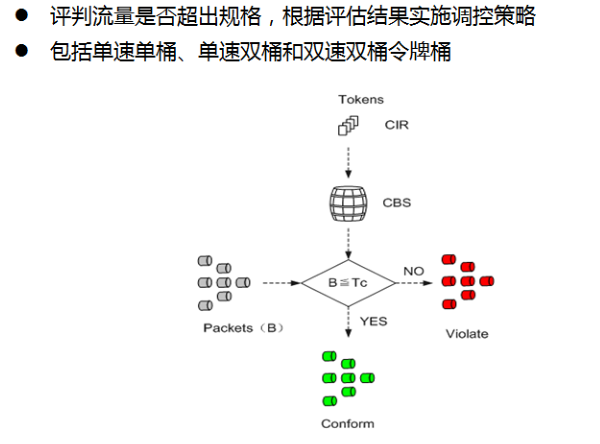
- TC:令牌桶中的令牌数
- 令牌桶称为C桶,用TC表示桶中的令牌数量。单速单桶有两个参数:
- CIR(Committed Information Rate):承诺信息速率,表示向C桶中投放令牌的速率,即C桶允许传输或转发报文的平均速率。
- CBS(Committed Burst Size):承诺突发尺寸,表示C桶的令牌,即C桶瞬间能够通过的承诺突发流量。
- 系统按照CIR速率向C桶中投放令牌,当TC<CBS时,令牌数增加,否则不增加。
- 对于到达的报文,用B表示报文的大小:
- 若B≦Tc,报文被标记为绿色,且Tc减少B
- 若B>Tc,报文被标记为红色,Tc不减少
3.1.3 单速双桶
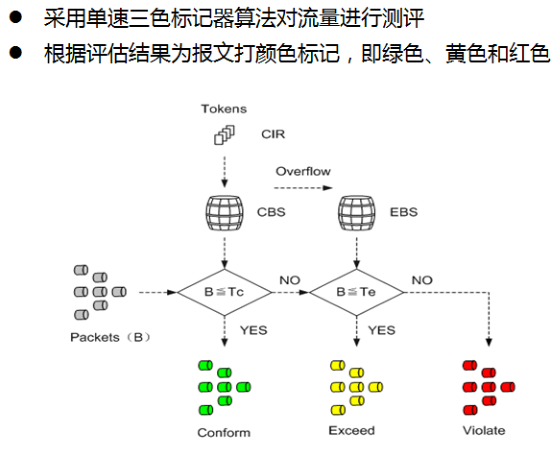
- 两个令牌桶称为C桶和E桶,用Tc和Te表示桶中的令牌数量。单速双桶有3个参数:
- CIR:承诺信息速率,表示向C桶中投放令牌的速率,即C桶允许传输或转发报文的平均速率;
- CBS:承诺突发尺寸,表示C桶的容量,即C桶瞬间能够通过的承诺突发流量;
- EBS(Excess Burst Size):超额突发尺寸,表示E桶的容量,即E桶瞬间能够通过的超出突发流量。
- 系统按照CIR速率向桶中投放令牌:
- 若Tc<CBS,Tc增加;
- 若Tc=CBS,Te<EBS,Te增加;
- 若Tc=CBS,Te=EBS,则都不增加。
- 对于到达的报文,用B表示报文的大小:
- 若B≤Tc,报文被标记为绿色,且Tc减少B;
- 若Tc<B≤Te,报文被标记为黄色,且Te减少B;
- 若Te<B,报文被标记为红色,且Tc和Te都不减少。
- 通过报文被标记的颜色判断报文速率
- 如果稳定时,报文总是被标记为绿色,则可以判定报文的速率小于等于CIR;
- 如果报文经常被标记为黄色或者红色,则可以判定报文的速率大于CIR;
3.1.4 双速双桶
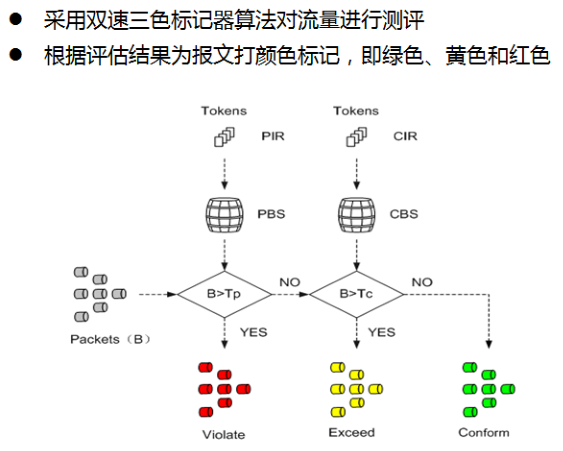
- 相比单速双桶,黄色和红色的速率就有区分了,控制更加准确
- 稳定时,如果报文被标记为红色,则可以判断报文速率大于PIR;
- 稳定时,如果报文被标记为黄色,则可以判断报文速率大于CIR小于PIR;
- 稳定时,如果报文被标记为绿色,则可以判断报文速率小于CIR;
- 两个令牌桶称为P桶和C桶,用Tp和Tc表示桶中的令牌数量。双速双桶有4个参数:
- PIR(Peak information rate):峰值信息速率,表示向P桶中投放令牌的速率,即P桶允许传输或转发报文的峰值速率,PIR大于CIR;
- CIR:承诺信息速率,表示向C桶中投放令牌的速率,即C桶允许传输或转发报文的平均速率;
- PBS(Peak Burst Size):峰值突发尺寸,表示P桶的容量,即P桶瞬间能够通过的峰值突发流量,PBS大于CBS;
- CBS:承诺突发尺寸,表示C桶的容量,即C桶瞬间能够通过的承诺突发流量。
- 系统按照PIR速率向P桶中投放令牌,按照CIR速率向C桶中投放令牌:
- 当Tp<PBS时,P桶中令牌数增加,否则不增加。
- 当Tc<CBS时,C桶中令牌数增加,否则不增加。
- 对于到达的报文,用B表示报文的大小:
- 若Tp<B,报文被标记为红色;
- 若Tc<B≤Tp,报文被标记为黄色,且Tp减少B;
- 若B≤Tc,报文被标记为绿色,且Tp和Tc都减少B。
3.1.5 流量监管(Traffice Pokicy)
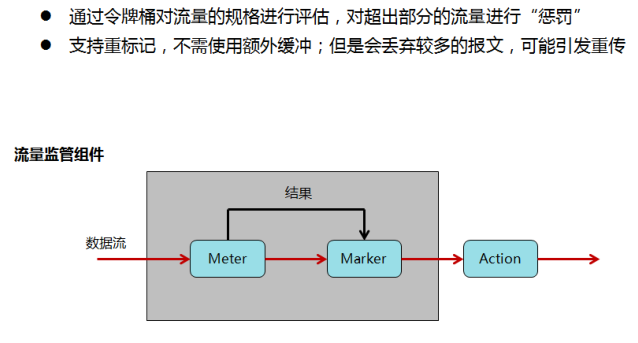
- 流量监管就是对流量进行控制,通过监管进入网络的流量速率,对超出部分的流量进行“惩罚”,使进入的流量被限制在一个合理的范围之内,从而保护网络资源和企业网用户的利益。
流量监管由三部分组成:
- Meter:通过令牌桶机制对网络流量进行度量,向Marker输出度量结果。
- Marker:根据Meter的度量结果对报文进行染色,报文会被染成green、yellow、red三种颜色。
Action:根据Marker对报文的染色结果(默认情况下,green、yellow进行转发,red报文丢弃。),对报文进行一些动作,动作包括:
- pass:对测量结果为“符合”的报文继续转发。
- remark + pass:修改报文内部优先级后再转发。
- discard:对测量结果为“不符合”的报文进行丢弃。
经过流量监管,如果某流量速率超出标准,设备可以选择降低报文优先级再进行转发或者直接丢弃。默认情况下,此类报文被丢弃。
3.2 流量整形(Traffice Shaping)
- 对发出去的数据做处理
- 流量整形可以使网络上下游之间的带宽匹配
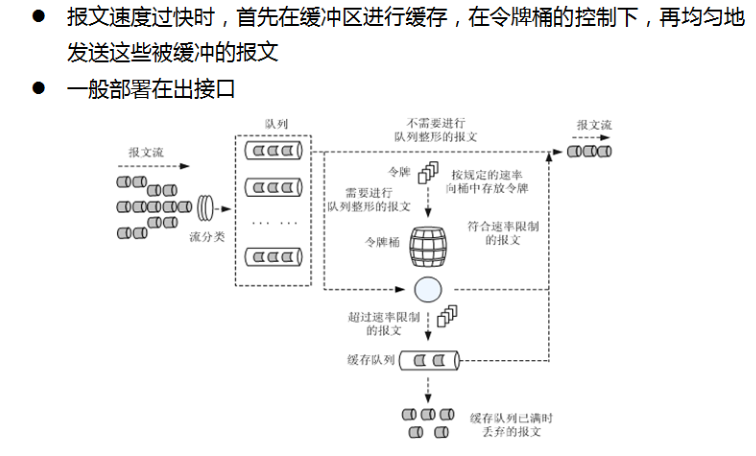
- 利用CAR进行报文流量控制时,对不符合流量特性的报文进行丢弃,而流量整形对于不符合流量特性的报文则是进行缓冲,减少了报文的丢弃(考虑流量整形主要是用在出接口就可以很好理解了)
- 上图是完全符合四大Qos组件的Qos技术应用框架
- 流量监管就是对流量进行控制,通过监管进入网络的流量速率,对超出部分的流量进行“惩罚”,使进入的流量被限制在一个合理的范围之内,从而保护网络资源和企业网用户的利益。
流量整形处理过程:
- 当报文到来的时候,首先对报文进行分类,使报文进入不同的队列。
- 若报文进入的队列没有配置队列整形功能,则直接发送该队列的报文,否则,进入下一步处理。
- 按用户设定的队列整形速率向令牌桶中放置令牌:
- 如果令牌桶中有足够的令牌可以用来发送报文,则报文直接被发送,在报文被发送的同时,令牌做相应的减少。
- 如果令牌桶中没有足够的令牌,则将报文放入缓存队列,如果报文放入缓存队列(GTS队列)时,缓存队列已满,则丢弃报文。
- 缓存队列有报文的时候,系统按一定的周期从缓存队列中取出报文进行发送,每次发送都会与令牌桶中的令牌数做比较,直到令牌桶中的令牌数减少到缓存队列中的报文不能再发送或缓存队列中的报文全部发送完毕为止。
3.2.1 GTS:Generic Traffic Shaping
- GTS流量整形这一步完成后,下一步是把数据交到出口
- GTS:通用流量整形
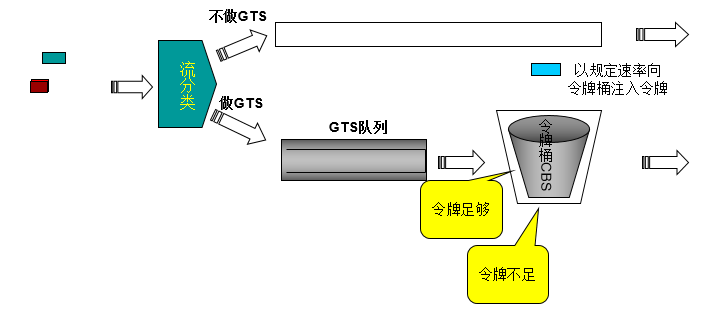
- GTS与CAR一样,都采用了令牌桶技术来控制流量。
- GTS与CAR的主要区别
- 利用CAR进行报文流量控制时,对不符合流量特性的报文进行丢弃;
- 而GTS对于不符合流量特性的报文则是进行缓冲,减少了报文的丢弃,同时满足报文的流量特性。
- GTS可以对接口上指定的报文流或所有报文进行整形。
- 当报文到来的时候,首先对报文进行分类,如果报文不需要进行GTS处理,就继续发送,不需要经过令牌桶的处理;
- 流量整形的令牌桶的构成同CAR一样,如果报文需要进行GTS处理,则与令牌桶中的令牌进行比较,进入令牌桶处理的包长度B –TB<0则报文被发送,否则报文被缓存,等到令牌桶中有足够的令牌时继续发送报文。
- 令牌桶按用户设定的速度向桶中放置令牌,如果令牌桶中有足够的令牌可以用来发送报文,则报文直接被继续发送出去,同时,令牌桶中的令牌量按报文的长度做相应的减少。
- 当令牌桶中的令牌少到报文不能再发送时,报文将被缓存入GTS队列中(队列是FIFO队列),此队列与接口上的FIFO不是同一个队列,当然队列有一定的长度(以包为单位),当需要缓存的报文个数大于队列长度时报文因无法缓存而丢弃。
- 当GTS队列中有报文的时候,GTS按一定的周期从队列中取出报文进行发送,每次发送都会与令牌桶中的令牌数作比较,令牌数足够则发送,令牌数不够就继续缓存。另外,GTS也允许有突发。GTS只能在出接口上生效。
3.2.2 LR:Line Rate
- LR:物理接口总速率限制
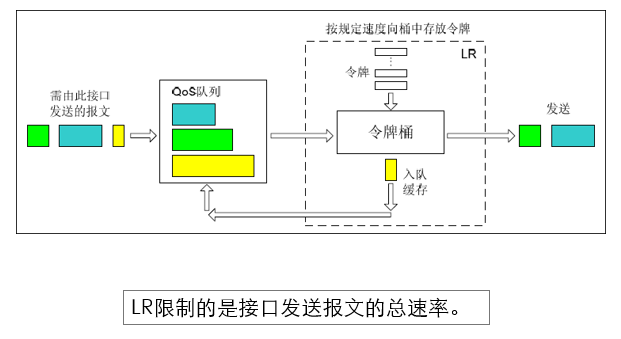
- 物理接口总速率限制(简称LR)可以在一个物理接口上,限制接口发送报文(包括紧急报文)的总速率。
- LR的处理过程仍是采用令牌桶进行流量控制。
- 如果用户在路由器的某个接口上配置了LR,规定了流量特性,则所有经由该接口发送的报文首先要经过LR的令牌桶进行处理。
- 如果令牌桶中有足够的令牌可以用来发送报文,则报文可以发送。
- 如果令牌桶中的令牌不满足报文的发送条件,则报文进入Qos队列进行拥塞管理。这样,就可以对满足该物理接口的报文流量进行控制。LR的处理过程如上图所示。
- 同样的,由于采用了令牌桶控制流量,当令牌桶中积存有令牌时,可以允许报文的突发性传输。当令牌桶中没有令牌的时候,报文将不能被发送,只有等到桶中生成了新的令牌,报文才可以发送,这就可以限制报文的流量只能是小于等于令牌生成的速度,具有限制流量,同时允许突发流量通过的目的。
- LR能够限制在物理接口上通过的所有报文,CAR和GTS在IP层实现,对不经过IP层处理的报文不起作用。LR与GTS比较,LR不但能够对超过流量限制的报文进行缓存,而且还使报文进入Qos队列机制进行处理,所以队列调度机制更灵活。
- 在用户只要求对所有报文限速时,使用LR所需的配置操作简单。对于网络建设投资者,可以对客户隐藏实际带宽,客户只能严格按所购买的带宽来使用。
3.3 流量监管与流量整形的区别
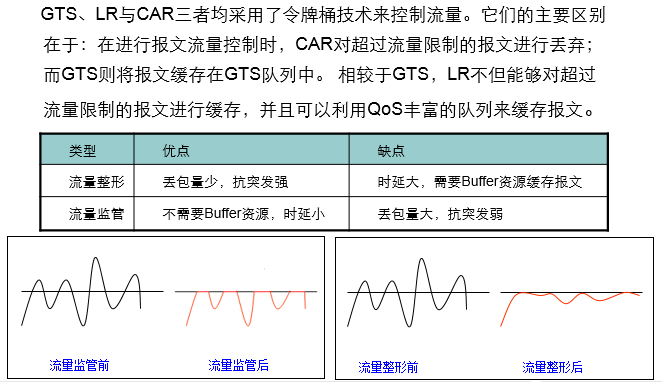
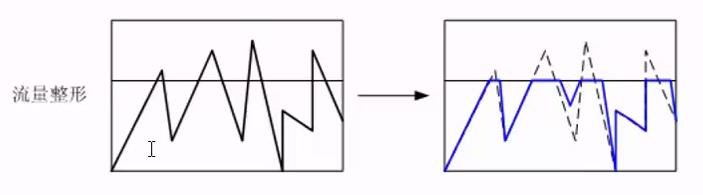
- 非常形象的比喻:流量监管是削峰,而流量整形是削峰填谷,这从上图中就可以看出来
- 看下图的流量整形的图可以更清楚地看出这一点:
4. 拥塞管理与避免
4.1 拥塞管理
4.1.1 概述
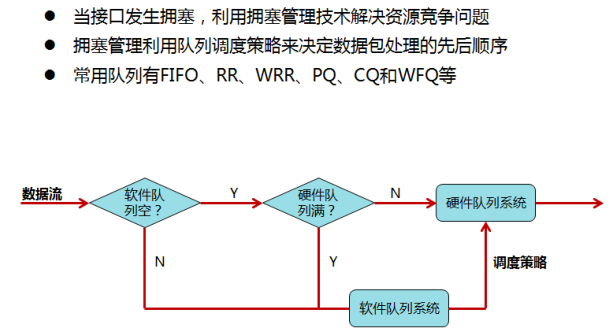
- 对于网络单元,当数据包到达的速度大于该接口发送数据包的速度时,在该接口处就会产生拥塞。
- 如果没有足够的存储空间来保存这些分组,它们其中的一部分就会丢失。
数据包的丢失又可能会导致发送该数据包的主机或路由器因超时而重传此数据包,这将导致恶行循环。
当拥塞发生时,多个报文会同时竞争使用资源,导致得不到资源的某些业务报文将丢弃,尤其不能保证业务的带宽、时延、抖动等Qos参数。
此时如何制定一个资源的调度策略决定报文转发的处理次序,就是报文的队列归属的流分类,以及队列间的调度策略。
最初的队列调度策略只有FIFO(先进先出),后来为了满足不同业务的需求,设计了多种调度机制。
- 队列调度机制由两部分组成:硬件队列和软件队列
- 硬件队列:也叫发送队列(Transmite Queue,TxQ),接口驱动在逐个传输数据包的时候需要使用这个队列,这个队列是FIFO队列。
- 软件队列:根据QOS的要求把数据包调度到硬件队列,软件队列可以使用多种调度方式。
4.1.2 FIFO:First In First Out
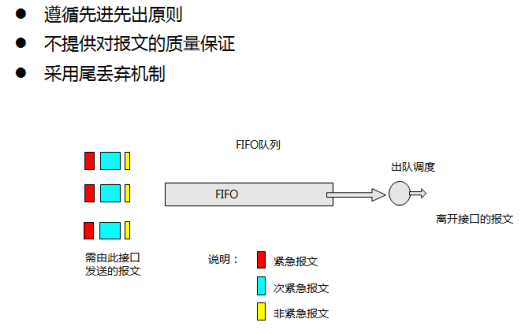
优点:
- 简单
缺点
- 没有公平性,不同的流之间不相互隔离,当某一个流的带宽太大的时候会占用其它流的带宽,并且造成其它流的时延增加。
- 当拥塞发生的时候,FIFO对一部分报文进行丢弃。TCP的连接发现有丢包后, 会降低传输的速度,来主动的避免拥塞,但是UDP是非连接的,不降低发送速率。导致FIFO中TCP和UDP的报文不平衡,TCP的流量太低。
一条流的突发流量可能占用全部buffer,将其它的流量全部阻断。
Tail Drop:尾丢弃
- 队列数目:一个队列
4.1.3 RR:Round Robin(调度算法)
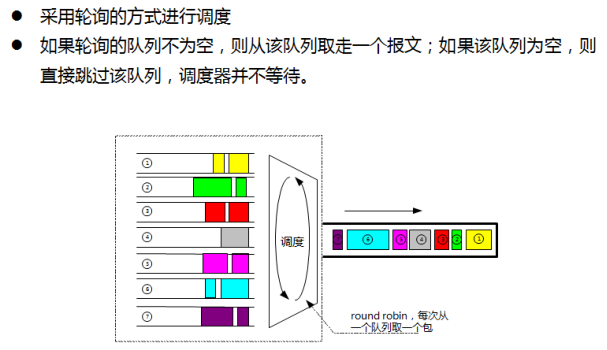
优点:
- 隔离了不同的流,实现了队列之间对带宽的平等利用
- 剩余带宽能够被其它队列平均分配
缺点:
- 无法设置队列占用带宽的权重
- 当不同队列中的报文长度不一的时候,调度不准确
- 当调度速率低的时候,时延和抖动的问题比较突出,比如一个包到达一个空队列,而这个队列刚刚被调度完毕,则这个包要等到其它全部的队列调度完才能取得出接口的机会,这样会导致抖动比较大,但是如果调度速度非常高,则这种时延可以忽略,RR在高速路由器内部有很多应用。
4.1.4 WRR:Weight Round Robin(加权调度算法)
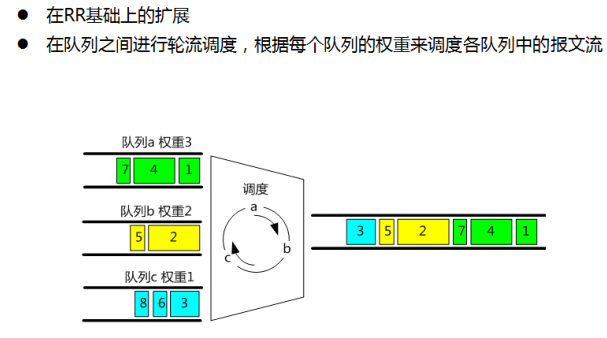
- WRR(Weighted Round Robin)主要针对RR不能设置权重的不足,在轮询的时候,每个队列享受的机会和该队列的权重成比例。
- WRR对于空的队列直接跳过,调度一周结束的时间变短,因此当某个队列的流量小的时候,剩余带宽能够被其他队列按照比例占用。
华为交换机二层接口的缺省调度方式
优点:能够按照权重来分配带宽,某个队列的剩余带宽能够为其他队列公平占用,低优先级的队列同样能够得到调度,不存在饥饿的问题。
- 实现简单、复杂度低。
- 适合diffserv聚合后的端口
缺点:
- 与RR调度算法一致,在报文长度不一致的时候,调度不准确。
- 在调度速率低的时候报文的时延控制的不好,时延抖动无法预期。
4.1.5 PQ:Priority Queuing
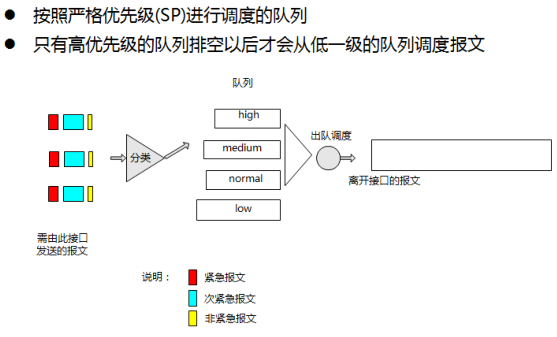
- 常规情况下PQ有四个级别的队列,分别为Top、Middle、Normal、Bottom,不过目前的设备大部分都实现了8个优先级队列,只要相对高的优先级队列有报文,就一直从高优先级队列取报文,所以PQ的优缺点是很明显的。
- PQ队列的优点是可以保证高优先级队列的报文可以得到较大带宽、较低的时延、较小的抖动;缺点是低优先级队列的报文不能得到及时的调度,甚至得不到调度,即会出现“饿死”现象。
- PQ具有如下特征:
- 可以使用ACL对报文进行分类,根据需要将报文入队列;
- 报文丢弃策略采用Tail Drop机制,且只有这一种机制;
- 队列长度可以设置为0,表示该队列无穷大,即进入该队列的报文不会被Tail Drop机制丢弃,除非内存耗尽了;
- 队列内部使用FIFO逻辑;
- 当从队列调度报文时,先从高优先级的队列调度报文。
从PQ特点可以看出,PQ保证某类流量尽可能得到最好的服务,而不管其它流量的“死活”。
优点:高优先级队列的时延控制非常好。
- 实现简单,能够区分多种业务。
缺点:
- 无法做到带宽的合理分配,高优先级的流量比较大的时候,导致低优先级的流量“饿死(starvation)”。
- 高优先级的时延得到保证的代价是牺牲低优先级的时延。
- 如果高优先级传送TCP流量,低优先级传送UDP流量,则TCP增加传送速率,导致UDP流量无法得到足够的带宽。
4.1.6 CQ:Custom Queuing
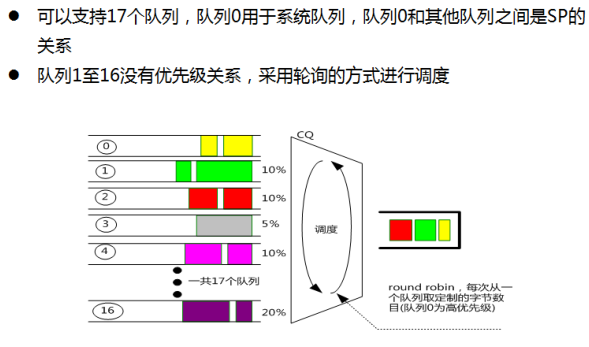
- CQ ~= PQ + WRR
- 这种队列需要在配置的时候为每一个队列指定每次调度的字节数量,每次队列调度的时候,如果报文长度超过配置的字节长度,则报文被调度,这种办法可以防止字节数配置得太小,导致某个队列阻塞。
- 但是这种做法当配置字节数量比较小的时候,会导致带宽分配不准确。
- 比如某个队列配置的调度字节数为500字节,而这个队列中的报文一般都是1000字节以上,则这个队列实际分配的带宽要比预期的大。
- 如果将调度的字节数配置的比较大,则时延表现不好。
CQ一次可以调度多个报文,数量为每次调度的字节数目能够容纳的包的个数。
优点:按照比例来分配带宽,当某个队列的流量小的时候,其他队列能等比的占用带宽。
- 实现简单。
缺点:
- 当配置字节数小的时候,带宽分配不准确,当配置字节数大的时候,时延抖动比较大。
4.1.7 WFQ:Weighted Fair Queuing
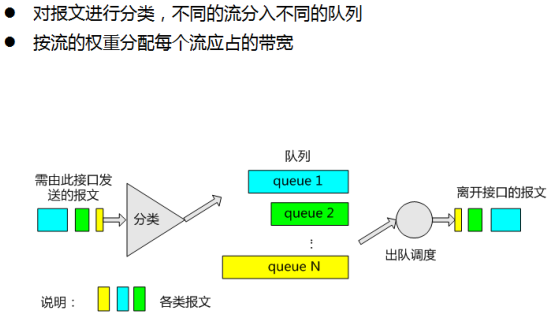
- WFQ:加权公平队列(以后简称WFQ)对报文按流进行分类,
- 对于IP网络,可以将相同源IP地址,目的IP地址,源端口号,目的端口号,协议号,IP优先级的报文属于同一个流,(有点像是同一个用户)
- 而对于MPLS网络,具有相同的标签和EXP域值的报文属于同一个流。
- 每一个流被分配到一个队列,尽量将不同的流分入不同的队列。在出队的时候,WFQ按权重来分配每个流应占有出口的带宽。权重的数值越小,所得的带宽越少。权重的数值越大,所得的带宽越多。这样就保证了相同优先级业务之间的公平,体现了不同优先级业务之间的权值。
- 例如:接口中当前有8个流,它们的权重值分别为1、2、3、4、5、6、7、8。则带宽的总配额将是所有权重值之和,即:1 +2 + 3 + 4 + 5 + 6 + 7 + 8 = 36。每个流所占带宽比例为:各自的权重/带宽的总配额。即,每个流可得的带宽比例分别为:1/36、2/36、3/36、4/36、5/36、6/36、7 /36、8/36。
由此可见,WFQ在保证公平的基础上对不同优先级的业务体现权值,而权值依赖于IP报文头中所携带的IP优先级。
- WFQ的概述为:
- 1.通过5元组进行流分类;
- 2.不同的流进入不同的队列;
- 3.根据IP优先级或DSCP值给每个流设置权重;
- 4.通过不同的权值分配不同的带宽比例;
- WFQ和FQ的最大区别在于:
- WFQ能根据IP优先级或DSCP为不同的流设置权重值,依赖五元组对流进行分类,同时使用权值来为不同的流设置不同的带宽比例;
- FQ不能根据IP优先级或DSCP来为流设置权重值,只是依赖五元组对流进行分类;
优点:- WFQ的概述为:
按照字节粒度进行调度,调度公平。
- 能区分业务,分配权重。
- 时延控制的好,抖动小。
缺点:
- 实现复杂。
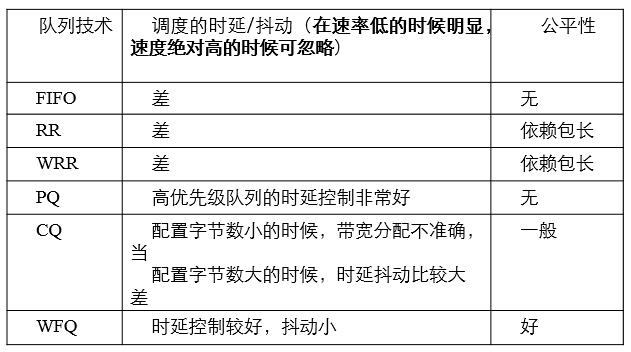
4.1.8 各种队列调度技术对比
4.1.9 队列技术在产品中的实现
- 目前产品中,主要使用FIFO、WFQ、PQ三种队列技术来实现拥塞管理。
- 端口队列调度采用PQ+WFQ调度算法,采用这种调度优势在于,既能使时延敏感的实时业务得到保证,也使优先业务的报文的带宽占用可以绝对优先,又可以为不同优先级的流根据配置的权重分配不同的带宽。
- 对于DiffServ模型,系统为每个端口预留8个业务队列,分别对应BE,AF1至AF4,EF,CS6,CS7等业务类别,
- 对AF1~AF4以及BE队列默认配置成WFQ调度,根据配置的权重参数按比例分配带宽。
- EF,CS6,CS7队列默认配置PQ调度,这种按照绝对优先级调度,一般是时延敏感的业务采用PQ调度。
4.2 拥塞避免
4.2.1 概述
- 拥塞避免是一种流控机制,它可以通过监视网络资源(如队列或内存缓冲区)的使用情况,在拥塞有加剧的趋势时。主动丢弃报文,通过调整网络的流量来解除网络过载。
- 拥塞避免机制包括:尾丢弃、RED和WRED
4.2.2 尾丢弃(Tail-Drop)
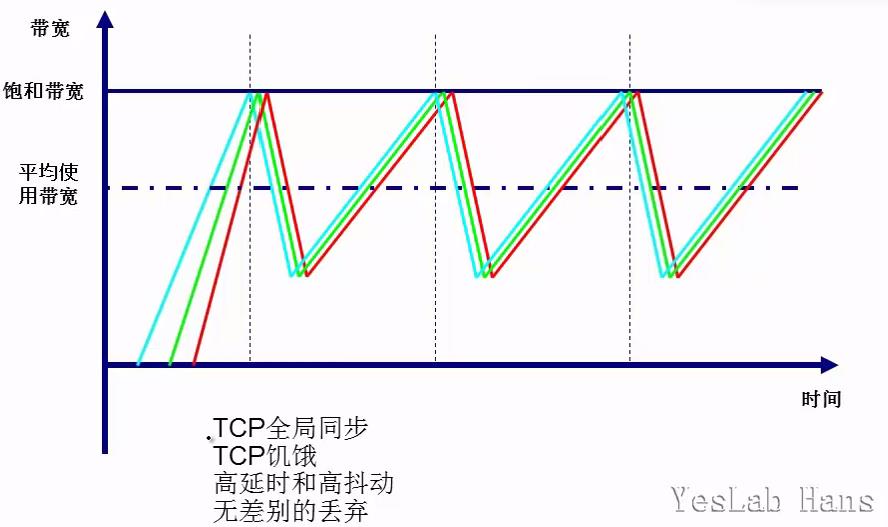
- 传统的丢包策略采用尾部丢弃(Tail-Drop)的方法。当队列的长度达到某一最大值后,所有新到来的报文都将被丢弃。这种丢弃策略会导致下面的问题:
- TCP全局同步:当队列同时丢弃多个TCP连接的报文时,将造成多个TCP连接同时进入慢启动和拥塞避免,称之为TCP全局同步。
- TCP饥饿:尾丢弃会造成TCP流量之间分配带宽不均衡,一些“贪婪”的流量会占用大部分的带宽,而普通的TCP流量分配不了带宽而“饿死”。(特别是网络中既有TCP流量和UDP流量的时候)
- 高延时和高抖动
- 无差别的丢弃:没有区分各种不同优先级的报文
4.2.3 RED:Random Early Detection
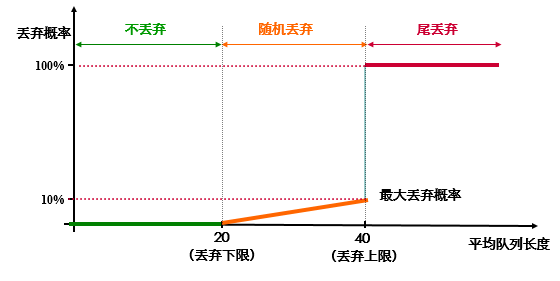
- 横坐标指的应该是当前队列长度,而不是实际队列长度
- RED就是一种在队列拥塞之前进行报文丢弃的一种拥塞避免机制。RED会主动丢弃可能造成拥塞的报文。他能够使TCP会话所占用的输出带宽缓慢的降低,不会引起大量的TCP全局同步以及TCP饥饿,还能够降低平均队列长度。
- RED共有三种丢弃模式:绿色报文不丢弃、黄色报文概率丢弃、红色报文全丢弃。这三种模式是以队列丢弃的上下两个阀值(low-limit和high-limit)所决定的。
- 绿色报文:当平均队列长度小于low-limit时被标记为绿色,不进行丢弃。
- 黄色报文:当平均队列长度介于low-limit和high-limit之间时,报文被标记为黄色,进行概率丢弃。并且,队列的长度越长,丢弃的概率越高。
- 红色报文:当平均队列的长度大于high-limit时,报文被标记为红色。并且进行全部丢弃。(此时进行的是尾丢弃!)
4.2.4 WRED:Weighted Random Early Detection
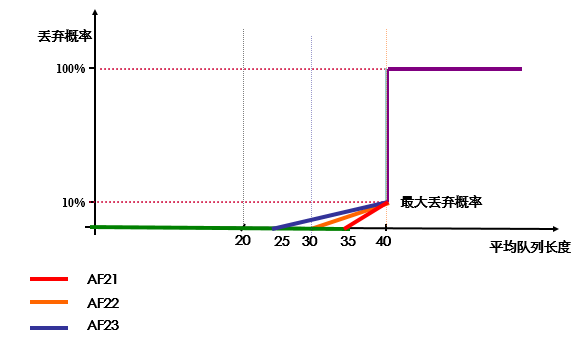
- WRED(Weighted Random Early Detection)与RED的区别是引入了优先权,不同的优先权可以有不同的丢弃策略。
- 每一个丢弃策略都包含有RED的三个参数:下限阀值、上限阀值以及最大丢弃概率。
- 目前WRED优先权可以根据DSCP和IP优先级进行划分,对低优先级报文的丢弃概率大于高优先级的报文。
- DSCP AF PHB表示为aaadd0,其中‘aaa’表示流量类别,‘dd’表示丢弃优先级。
- 比如AF21(010010)、AF22(010100)和AF23(010110)属于同一个流量类,并且在拥塞发生的时候,丢弃可能性AF21<AF22<AF23,所以在配置WRED参数时,可以按图中所示进行配置。对标记为AF21的流量下限设为35,上限设为40;标记为AF22的流量下限设为30,上限设为40;标记为AF23的流量下限设为25,上限设为40。另外,在达到上限时的丢弃概率是10%。因此,在可能发生拥塞之前,AF23的数据包最有可能最先被丢弃。
4.2.5 拥塞避免配置举例

5.链路效率机制(压缩)
5.1 概述

- VRP提供了两种链路效率机制:IP报文头压缩协议(IP Header Compression,IPHC)和链路分片与交叉(Link Fragmentation and Interleaving,LFI)。 其中IP报文头压缩协议可以对RTP和TCP报文头进行压缩。
- 对于同一个流的数据部,IP头部的大部分字段是相同的,因此可以对这些字段进行压缩,提高链路传输的效率。
- LFI技术主要在低速链路上使用,目的是减小实时数据报文的延时和抖动。
5.2 IPHC:IP Header Compression
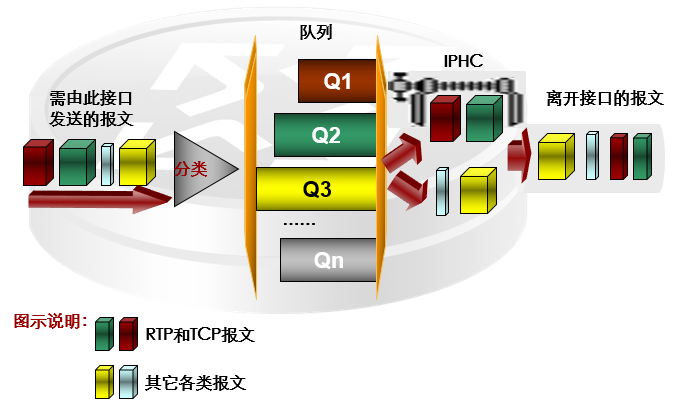
- IP报文头压缩协议(IP Header Compression,IPHC)是一个主机-主机协议,用于在IP网络上承载语音、视频等实时多媒体业务,是在PPP链路和FR链路应用的低速链路技术。IPHC支持对RTP和TCP报文头的压缩。
- RTP包括数据部分和头部分,RTP的数据部分相对较小,而RTP的头部分较大。12字节的RTP头,加上20字节的IP头和8字节的UDP头,就是40字节的IP/UDP/RTP头。而RTP典型的负载是20字节到160字节。为了避免不必要的带宽消耗,可以使用IPHC特性对报文头进行压缩。IPHC将IP/UDP/RTP头从40字节压缩到2~4字节,对于40字节的负载,头压缩到4字节,压缩比为(40+40)/(40+4),约为1.82,可见效果是相当可观的。
5.3 LFI:Link Fragmentation and Interleaving
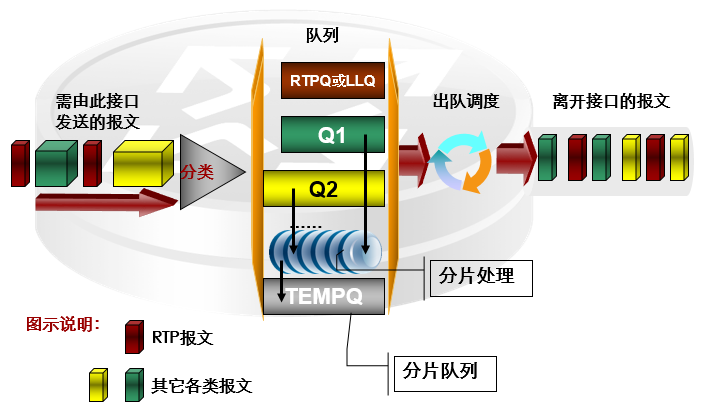
- 链路分片与交叉是在PPP链路和FR链路应用的低速链路技术。
- 在低速串行链路上,实时交互式通信,如Telnet和VoIP,往往会由于大型分组的发送而导致阻塞延迟:
- 例如,正好在大报文被调度而等待发送时,语音报文到达,它需要等该大报文被传输完毕后才能被调度。对于诸如交互式语音等实时应用而言,大报文导致的这种阻塞延迟太长了,对端将听到断断续续的话音。交互式语音要求端到端的延迟不大于100~150ms。
- 一个1500bytes(即通常MTU的大小)的报文需要花费215ms穿过56Kbps的链路,这超过了人所能忍受的延迟限制。为了在相对低速的链路上限制实时报文的延迟时间,例如56Kbps Frame Relay或64Kbps ISDN B通道,需要一种方法将大报文进行分片,将小报文和大报文的分片一起加入到队列。
- LFI将大型数据帧分割成小型帧,与其他小片的报文一起发送,从而减少在速度较慢的链路上的延迟和抖动。
- 上图描述了链路分片与交叉的处理过程。大报文和实时报文一起到达某个接口时,除了RTP实时队列和LLQ队列中的报文外,其他队列中的大报文将被分成若干小包放入分片队列进行发送;但如果此时RTP实时队列和LLQ中有缓存的报文,则优先调度RTP实时队列和LLQ队列,否则继续调度分片队列,这样就避免了在低速链路上传送大包对实时报文造成的时延与抖动。
6.流策略
7.参考:IP城域网Qos解决方案
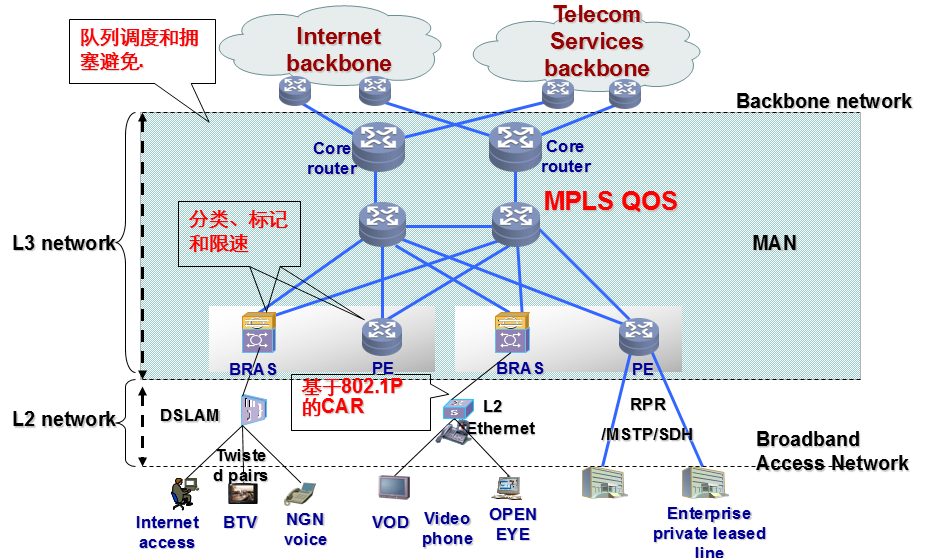
- 通常运营商网络由宽带接入网、城域网和骨干网三部分组成。宽带接入网一般是由DSLAM或二层交换机组成的二层网络,在QoS方面可以部署802.1P区分不同用户的优先级,并配置基于802.1P的CAR来限制入网流量。
- 城域网BRAS或PE设备上可以通过进一步流分类区分出同一用户的不同业务流,为不同的业务流选择合适的队列调度算法和拥塞避免方法,从而为不同的业务提供不同的服务保证。

若有收获,就点个赞吧
0 人点赞
