- 第一节 系统配置优化
- 第二节 表结构设计优化
- 第三节 SQL 语句及索引优化
- 3.1 EXPLAIN 查看索引使用情况
- 3.2 SQL 语句中 IN 包含的值不应过多
- 3.3 SELECT 语句务必指明字段名称
- 3.4 当只需要一条数据的时候,使用 limit 1
- 3.5 排序字段加索引
- 3.6 如果限制条件中其他字段没有索引,尽量少用 or
- 3.7 尽量用 union all 代替 union
- 3.8 不使用 ORDER BY RAND()
- 3.9 区分 in 和 exists、not in 和 not exists
- 3.10 使用合理的分页方式以提高分页的效率
- 3.11 分段查询
- 3.12 不建议使用 % 前缀模糊查询
- 3.13 避免在 where 子句中对字段进行表达式操作
- 3.14 避免隐式类型转换
- 3.15 对于联合索引来说,要遵守最左前缀法则
- 3.16 必要时可以使用 force index 来强制查询走某个索引
- 3.17 注意范围查询语句
- 3.18 使用 JOIN 优化
- 第四节 MySQL 开发规约
- 第五节 优化总结
数据库优化维度有四个:
硬件升级、系统配置、表结构设计、SQL 语句及索引。
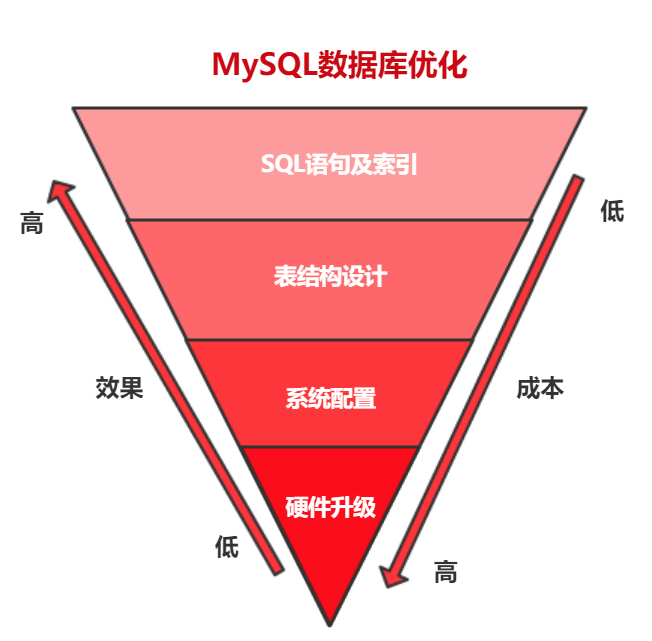
优化选择:
优化成本:硬件升级 > 系统配置 > 表结构设计 >SQL 语句及索引。
优化效果:硬件升级 < 系统配置 < 表结构设计 <SQL 语句及索引。
第一节 系统配置优化
1.1 保证从内存中读取数据
MySQL 会在内存中保存一定的数据,通过 LRU 算法将不常访问的数据保存在硬盘文件中。 尽可能的扩大内存中的数据量,将数据保存在内存中,从内存中读取数据,可以提升 MySQL 性能。 扩大 innodb_buffer_pool_size,能够全然从内存中读取数据。最大限度降低磁盘操作。 确定 innodb_buffer_pool_size 足够大的方法
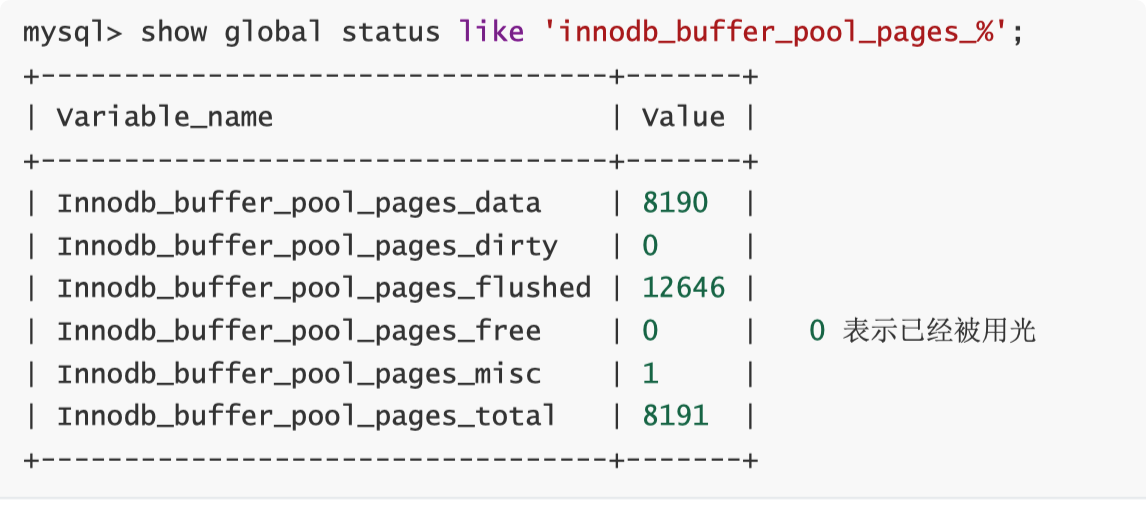
为了降低频繁的 io 操作磁盘调整 my.cnf 下的 innodb_buffer_pool_size
默认 128M,理论上可以扩大到内存的 3/4 或 4/5。 修改 my.cnf innodb_buffer_pool_size = 750M 如果是专用的 MySQL Server 可以禁用 SWAP

1.2 数据预热
默认情况,仅仅有某条数据被读取一次,才会缓存在 innodb_buffer_pool。 所以,数据库刚刚启动,须要进行数据预热,将磁盘上的全部数据缓存到内存中。 数据预热能够提高读取速度。
1、对于 InnoDB 数据库,进行数据预热的脚本是
SELECT DISTINCTCONCAT( 'SELECT ', ndxcollist, ' FROM ', db, '.', tb, ' ORDER BY ', ndxcollist, ';' ) SelectQueryToLoadCacheFROM(SELECT ENGINE,table_schema db,table_name tb,index_name,GROUP_CONCAT( column_name ORDER BY seq_in_index ) ndxcollistFROM(SELECTB.ENGINE,A.table_schema,A.table_name,A.index_name,A.column_name,A.seq_in_indexFROMinformation_schema.statistics AINNER JOIN ( SELECT ENGINE, table_schema, table_name FROM information_schema.TABLES WHERE ENGINE = 'InnoDB' ) B USING ( table_schema, table_name )WHEREB.table_schema NOT IN ( 'information_schema', 'mysql' )ORDER BYtable_schema,table_name,index_name,seq_in_index) AGROUP BYtable_schema,table_name,index_name) AAORDER BYdb,tb;
将该脚本保存为:loadtomem.sql
2、执行命令:
mysql -uroot -proot -AN < /root/loadtomem.sql > /root/loadtomem.sql
3、在需要数据预热时,比如重启数据库
执行命令:
mysql -uroot < /root/loadtomem.sql > /dev/null 2>&1
1.3 降低磁盘写入次数
增大 redolog,减少落盘次数 innodb_log_file_size 设置为 0.25 * innodb_buffer_pool_size
通用查询日志、慢查询日志可以不开 ,bin-log 开,生产中不开通用查询日志,遇到性能问题开慢查询日志
写 redolog 策略 innodb_flush_log_at_trx_commit 设置为 0 或 2 如果不涉及非常高的安全性 (金融系统),或者基础架构足够安全,或者事务都非常小,都能够用 0 或者 2 来减少磁盘操作。
1.4 提高磁盘读写性能
使用 SSD 或者内存磁盘
第二节 表结构设计优化
2.1 设计中间表
设计中间表,一般针对于统计分析功能,或者实时性不高的需求(OLTP、OLAP)
2.2 设计冗余字段
为减少关联查询,创建合理的冗余字段(创建冗余字段还需要注意数据一致性问题)
2.3 拆表
对于字段太多的大表,考虑拆表(比如一个表有 100 多个字段)
对于表中经常不被使用的字段或者存储数据比较多的字段,考虑拆表
2.4 主键优化
每张表建议都要有一个主键(主键索引),而且主键类型最好是 int 类型,建议自增主键(不考虑分布 式系统的情况下 雪花算法)。
2.5 字段的设计
数据库中的表越小,在它上面执行的查询也就会越快。 因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。 尽量把字段设置为 NOTNULL,这样在将来执行查询的时候,数据库不用去比较 NULL 值。
对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为 ENUM 类型。因为在 MySQL 中, ENUM 类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。这样,我 们又可以提高数据库的性能。
第三节 SQL 语句及索引优化
设计一个表:tbiguser
CREATE TABLE tbiguser (id INT PRIMARY KEY auto_increment,nickname VARCHAR ( 255 ),loginname VARCHAR ( 255 ),age INT,sex CHAR ( 1 ),STATUS INT,address VARCHAR ( 255 ));
向该表中写入 10000000 条数据
CREATE PROCEDURE test_insert () BEGINDECLAREi INT DEFAULT 1;WHILEi <= 10000000 DOINSERT INTO tbiguserVALUES( NULL, concat( 'zy', i ), concat( 'zhaoyun', i ), 23, '1', 1, 'beijing' );SET i = i + 1;END WHILE;COMMIT;END;
执行该存储过程 可以插入 10000000 条数据
mysql> select count(*) from tbiguser;+----------+| count(*) |+----------+|10000000 |+----------+
3.1 EXPLAIN 查看索引使用情况
使用【慢查询日志】功能,去获取所有查询时间比较长的 SQL 语句 3 秒-5 秒 使用 explain 查看有问题的 SQL 的执行计划,重点查看索引使用情况
mysql> explain select * from tbiguser \G;*************************** 1. row ***************************id: 1select_type: SIMPLEtable: tbiguserpartitions: NULLtype: ALLpossible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 10730filtered: 100.00Extra: NULL1 row in set, 1 warning (0.00 sec)
type 列,连接类型。一个好的 SQL 语句至少要达到 range 级别。杜绝出现 all 级别。
index key 列,使用到的索引名。如果没有选择索引,值是 NULL。可以采取强制索引方式。
key_len 列,索引长度。
rows 列,扫描行数。该值是个预估值。
extra 列,详细说明。
注意,常见的不太友好的值,如下:Using filesort,Using temporary 。
常见的索引: where 字段 、组合索引 (最左前缀) 、 索引下推 (非选择行不加锁) 、覆盖索引(不回表) on 两边、排序 、分组统计
3.2 SQL 语句中 IN 包含的值不应过多
MySQL 对于 IN 做了相应的优化,即将 IN 中的常量全部存储在一个数组里面,而且这个数组是排好序 的。但是如果数值较多,产生的消耗也是比较大的。
3.3 SELECT 语句务必指明字段名称
SELECT * 增加很多不必要的消耗(CPU、IO、内存、网络带宽);减少了使用覆盖索引的可能性;当 表结构发生改变时,前端也需要更新。所以要求直接在 select 后面接上字段名。
3.4 当只需要一条数据的时候,使用 limit 1
limit 是可以停止全表扫描的

3.5 排序字段加索引
不然排序是在内存中会耗费大量的时间
3.6 如果限制条件中其他字段没有索引,尽量少用 or
or 两边的字段中,如果有一个不是索引字段,会造成该查询不走索引的情况。
3.7 尽量用 union all 代替 union
union 和 union all 的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序, 增加大量的 CPU 运算,加大资源消耗及延迟。当然,union all 的前提条件是两个结果集没有重复数据。
3.8 不使用 ORDER BY RAND()


3.9 区分 in 和 exists、not in 和 not exists
区分 in 和 exists 主要是造成了驱动顺序的改变(这是性能变化的关键),如果是 exists,那么以外层表为 驱动表,先被访问,如果是 IN,那么先执行子查询。所以 IN 适合于外表大而内表小的情况;EXISTS 适合 于外表小而内表大的情况。
关于 not in 和 not exists,推荐使用 not exists,不仅仅是效率问题,not in 可能存在逻辑问题。如何高 效的写出一个替代 not exists 的 SQL 语句?
原 SQL 语句:
select colname … from A表 where a.id not in (select b.id from B表)
高效的 SQL 语句:
select colname … from A表 Left join B表 on where a.id = b.id where b.id is null
3.10 使用合理的分页方式以提高分页的效率
分页使用 limit m,n 尽量让 m 小
利用主键的定位,可以减小 m 的值
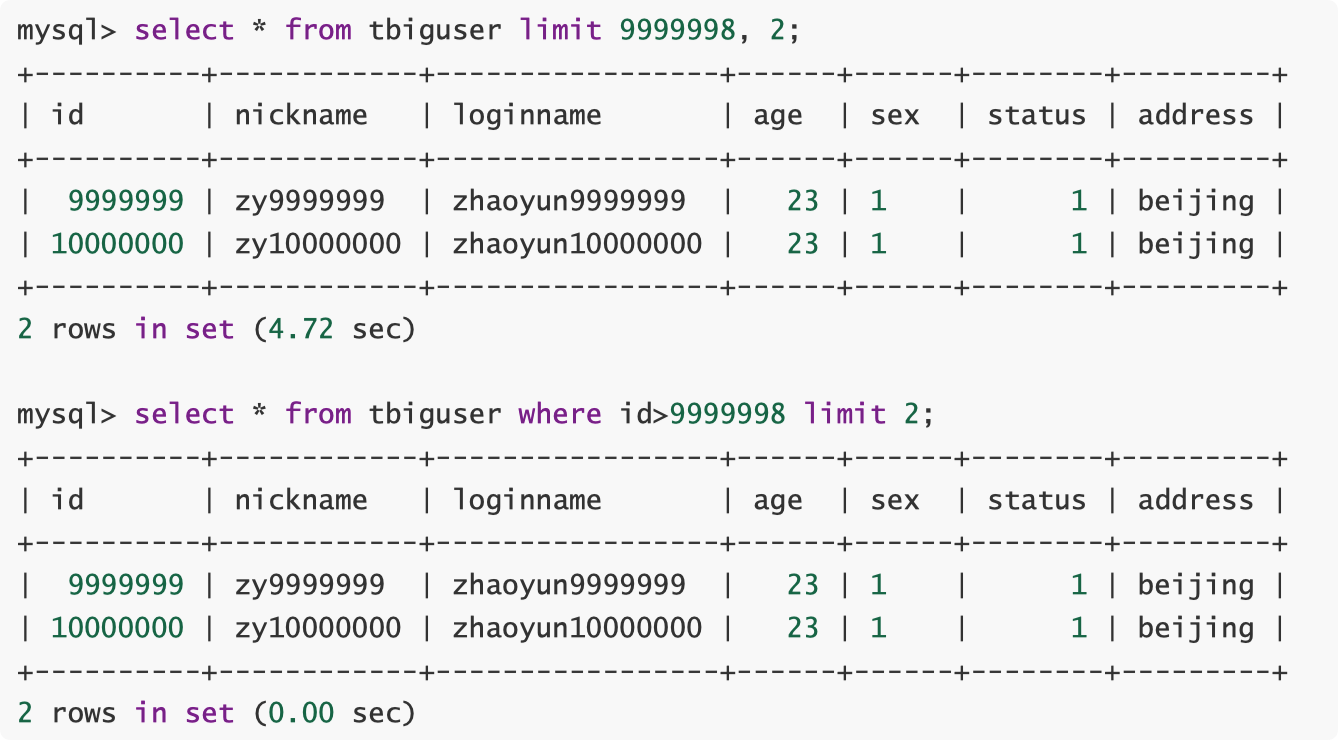
3.11 分段查询
一些用户选择页面中,可能一些用户选择的范围过大,造成查询缓慢。主要的原因是扫描行数过多。这 个时候可以通过程序,分段进行查询,循环遍历,将结果合并处理进行展示。
3.12 不建议使用 % 前缀模糊查询
例如 LIKE“%name”或者 LIKE“%name%”,这种查询会导致索引失效而进行全表扫描。但是可以使用 LIKE “name%”。
那么如何解决这个问题呢,答案:使用全文索引或 ES 全文检索
3.13 避免在 where 子句中对字段进行表达式操作
select user_id,user_project from user_base where age*2=36;
中对字段就行了算术运算,这会造成引擎放弃使用索引,建议改成:
select user_id,user_project from user_base where age=36/2;
3.14 避免隐式类型转换
where 子句中出现 column 字段的类型和传入的参数类型不一致的时候发生的类型转换,建议先确定 where 中的参数类型。 where age=’18’
3.15 对于联合索引来说,要遵守最左前缀法则
举列来说索引含有字段 id、name、school,可以直接用 id 字段,也可以 id、name 这样的顺序,但是 name;school 都无法使用这个索引。所以在创建联合索引的时候一定要注意索引字段顺序,常用的查询 字段放在最前面。
3.16 必要时可以使用 force index 来强制查询走某个索引
有的时候 MySQL 优化器采取它认为合适的索引来检索 SQL 语句,但是可能它所采用的索引并不是我们想 要的。这时就可以采用 forceindex 来强制优化器使用我们制定的索引。
3.17 注意范围查询语句
对于联合索引来说,如果存在范围查询,比如 between、>、< 等条件时,会造成后面的索引字段失效。
3.18 使用 JOIN 优化
LEFT JOIN A 表为驱动表,INNER JOIN MySQL 会自动找出那个数据少的表作用驱动表,RIGHT JOIN B 表为驱动表。 注意:
1)MySQL 中没有 full join,可以用以下方式来解决:
select * from A left join Bon B.name = A.namewhere B.name is nullunion allselect * from B;
2)尽量使用 inner join,避免 left join: 参与联合查询的表至少为 2 张表,一般都存在大小之分。如果连接方式是 inner join,在没有其他过滤条 件的情况下 MySQL 会自动选择小表作为驱动表,但是 left join 在驱动表的选择上遵循的是左边驱动右边 的原则,即 left join 左边的表名为驱动表。
3)合理利用索引:
被驱动表的索引字段作为 on 的限制字段。
4)利用小表去驱动大表:
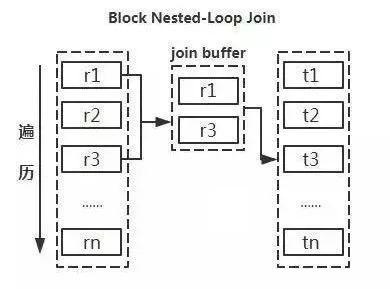
从原理图能够直观的看出如果能够减少驱动表的话,减少嵌套循环中的循环次数,以减少 IO 总量及 CPU 运算的次数。
第四节 MySQL 开发规约
我们知道各大公司都有自己的 MySQL 开发规约,我们以阿里为例,阿里的 MySQL 开发规约如下:
4.1 建表规约
1、【强制】表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint
(1 表示是,0 表示否)。
说明:任何字段如果为非负数,必须是 unsigned。 注意:POJO 类中的任何布尔类型的变量,都不要加 is 前缀,所以,需要在设置 从 is_xxx 到 Xxx 的映射关系。数据库表示是与否的值,使用 tinyint 类型,坚持 is_xxx 的 命名方式是为了明确其取值含义与取值范围。 正例:表达逻辑删除的字段名 is_deleted,1 表示删除,0 表示未删除。 2、【强制】表名、字段名必须使用小写字母或数字,禁止出现数字开头,禁止两个下划线中间只 出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。 说明:MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写。因此,数据库名、 表名、字段名,都不允许出现任何大写字母,避免节外生枝。 正例:aliyun_admin,rdc_config,level3_name 反例:AliyunAdmin,rdcConfig,level_3_name 3、【强制】表名不使用复数名词。 说明:表名应该仅仅表示表里面的实体内容,不应该表示实体数量,对应于 DO 类名也是单数 形式,符合表达习惯。
4、【强制】禁用保留字,如 desc、range、match、delayed 等,请参考 MySQL 官方保留字。
5、【强制】主键索引名为 pk 字段名;唯一索引名为 uk 字段名;普通索引名则为 idx_字段名。
说明:pk 即 primary key;uk 即 unique key;idx_ 即 index 的简称。
6、【强制】小数类型为 decimal,禁止使用 float 和 double。 说明:float 和 double 在存储的时候,存在精度损失的问题,很可能在值的比较时,得到不 正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数分开存储。
7、【强制】如果存储的字符串长度几乎相等,使用 char 定长字符串类型。
8、【强制】varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长 度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索 引效率。
9、 【强制】表必备三字段:id, gmt_create, gmt_modified。 说明:其中 id 必为主键,类型为 bigint unsigned、单表时自增、步长为 1。gmt_create, gmt_modified 的类型均为 datetime 类型,前者现在时表示主动创建,后者过去分词表示被 动更新。
10、【推荐】表的命名最好是加上“业务名称_表的作用”。 正例:alipay_task / force_project / trade_config 11、【推荐】库名与应用名称尽量一致。
12、【推荐】如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释。
13、【推荐】字段允许适当冗余,以提高查询性能,但必须考虑数据一致。冗余字段应遵循:
1)不是频繁修改的字段。
2)不是 varchar 超长字段,更不能是 text 字段。 正例:商品类目名称使用频率高,字段长度短,名称基本一成不变,可在相关联的表中冗余存 储类目名称,避免关联查询。
14、【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。 说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
15、【参考】合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检 索速度。 正例:如下表,其中无符号值可以避免误存负数,且扩大了表示范围。
| 对象 | 年龄区间 | 类型 | 字节 | 表示范围 |
|---|---|---|---|---|
| 人 | 150 岁之内 | tinyint unsigned | 1 | 无符号值:0 到 255 |
| 龟 | 数百岁 | smallint unsigned | 2 | 无符号值:0 到 65535 |
| 恐龙化石 | 数千万年 | int unsigned | 4 | 无符号值:0 到约 42.9 亿 |
| 太阳 | 约 50 亿年 | bigint unsigned | 8 | 无符号值:0 到约 10 的 19 次方 |
4.2 索引规约
1、【强制】业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。 说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的;另 外,即 使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
2、【强制】三个表以上禁止 join。需要 join 的字段,数据类型必须绝对一致;多表关联查询时, 保证被关联的字段需要有索引。 说明:即使双表 join 也要注意表索引、SQL 性能。
3、【强制】在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据 实际文本区分度决定索引长度即可。
4、【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。 说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
5、【推荐】如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合 索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。 正例:where a=? and b=? order by c; 索引:a_b_c 反例:索引中有范围查找,那么索引有序性无法利用,如:WHERE a>10 ORDER BY b; 索引 a_b 无法排 序。
6、【推荐】利用覆盖索引来进行查询操作,避免回表。 说明:如果一本书需要知道第 11 章是什么标题,会翻开第 11 章对应的那一页吗?目录浏览 一下就好,这个目录就是起到覆盖索引的作用。 正例:能够建立索引的种类分为主键索引、唯一索引、普通索引三种,而覆盖索引只是一种查 询的一种效果,用 explain 的结果,extra 列会出现:using index。
7、【推荐】利用延迟关联或者子查询优化超多分页场景。 说明:MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 行,返回 N 行,那当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过 特定阈值的页数进行 SQL 改写。 正例:先快速定位需要获取的 id 段,然后再关联: SELECT a. FROM 表 1 a, (select id from 表 1 where 条件 LIMIT 100000,20 ) b where a.id=b.id
8、【推荐】SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,如果可以是 consts 最 好。 说明:
1)consts 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
2)ref 指的是使用普通的索引(normal index)。
3)range 对索引进行范围检索。 反例:explain 表的结果,type=index,索引物理文件全扫描,速度非常慢,这个 index 级 别比较 range 还低,与全表扫描是小巫见大巫。
9、【推荐】建组合索引的时候,区分度最高的在最左边 正例:如果 where a=? and b=? ,如果 a 列的几乎接近于唯一值,那么只需要单建 idx_a 索引即可。 说明:存在非等号和等号混合时,在建索引时,请把等号条件的列前置。如:where c>? and d=? 那么即使 c 的区分度更高,也必须把 d 放在索引的最前列,即索引 idx_d_c。
10、【推荐】防止因字段类型不同造成的隐式转换,导致索引失效。
11、 【参考】创建索引时避免有如下极端误解
1)宁滥勿缺。认为一个查询就需要建一个索引。
2)宁缺勿滥。认为索引会消耗空间、严重拖慢更新和新增速度。
3)抵制惟一索引。认为业务的惟一性一律需要在应用层通过“先查后插”方式解决。
4.3 SQL 语句
1、【强制】不要使用 count(列名)或 count(常量)来替代 count(),count()是 SQL92 定义的标准统计行 数的语法, 跟数据库无关,跟 NULL 和非 NULL 无关。 说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
2、【强制】count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1, col2) 如果其中一 列全为 NULL,那么即使另一列有不同的值,也返回为 0。
3、【强制】当某一列的值全是 NULL 时,count(col)的返回结果为 0,但 sum(col)的返回结果为 NULL,因此使用 sum()时需注意 NPE (Null Pointer Exception)问题。 正例:可以使用如下方式来避免 sum 的 NPE 问题:SELECT IF(ISNULL(SUM(g)),0,SUM(g))FROM table;
4、【强制】使用 ISNULL()来判断是否为 NULL 值。 说明:NULL 与任何值的直接比较都为 NULL。
1) NULL<>NULL 的返回结果是 NULL,而不是 false。
2) NULL=NULL 的返回结果是 NULL,而不是 true。
3) NULL<>1 的返回结果是 NULL,而不是 true。
5、 【强制】在代码中写分页查询逻辑时,若 count 为 0 应直接返回,避免执行后面的分页语句。
6、【强制】不得使用外键与级联,一切外键概念必须在应用层解决。 说明:以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为 级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻 塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
7、【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
8、【强制】数据订正(特别是删除、修改记录操作)时,要先 select,避免出现误删除,确认无误才 能执行更新 语句。
9、【推荐】in 操作能避免则避免,若实在避免不了,需要仔细评估 in 后边的集合元素数量,控制在 1000 个 之内。
10、【参考】如果有国际化需要,所有的字符存储与表示,均以 utf-8 编码,注意字符统计函数的区 别。 说明: SELECT LENGTH(“轻松工作”); 返回为 12 SELECT CHARACTER_LENGTH(“轻松工作”); 返回为 4 如果需要存储表情,那么选择 utf8mb4 来进行存储,注意它与 utf-8 编码的区别。
11、【参考】TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE 无事务且不 触发 trigger,有可能造成事故,故不建议在开发代码中使用此语句。 说明:TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同
4.4 ORM 映射
- 【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。 说明:1)增加查询分析器解析成本。2)增减字段容易与 resultMap 配置不一致。3)无用字 段增加网络消耗,尤其是 text 类型的字段。
- 【强制】POJO 类的布尔属性不能加 is,而数据库字段必须加 is_,要求在 resultMap 中进行 字段与属性之间的映射。 说明:参见定义 POJO 类以及数据库字段定义规定,在中增加映射,是必须的。 在 MyBatis Generator 生成的代码中,需要进行对应的修改。
- 【强制】不要用 resultClass 当返回参数,即使所有类属性名与数据库字段一一对应,也需 要定义;反过来,每一个表也必然有一个 POJO 类与之对应。 说明:配置映射关系,使字段与 DO 类解耦,方便维护。 4. 【强制】sql.xml 配置参数使用:#{},#param# 不要使用 ${} 此种方式容易出现 SQL 注入。
- 【强制】iBATIS 自带的 queryForList(String statementName,int start,int size)不推荐使用。 说明:其实现方式是在数据库取到 statementName 对应的 SQL 语句的所有记录,再通过 subList 取 start,size 的子集合。
正例:Map
map.put(“start”, start); map.put(“size”, size);
- 【强制】不允许直接拿 HashMap 与 Hashtable 作为查询结果集的输出。 说明:resultClass=”Hashtable”,会置入字段名和属性值,但是值的类型不可控。
- 【强制】更新数据表记录时,必须同时更新记录对应的 gmt_modified 字段值为当前时间。
- 【推荐】不要写一个大而全的数据更新接口。传入为 POJO 类,不管是不是自己的目标更新字 段,都进行 update table set c1=value1,c2=value2,c3=value3; 这是不对的。执行 SQL 时,不要更新无改动的字段,一是易出错;二是效率低;三是增加 binlog 存储。
- 【参考】@Transactional 事务不要滥用。事务会影响数据库的 QPS,另外使用事务的地方需 要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
- 【参考】中的 compareValue 是与属性值对比的常量,一般是数字,表示相等时带 上此条件;表示不为空且不为 null 时执行;表示不为 null 值时执行。
第五节 优化总结
- 开启慢查询日志,定位运行慢的 SQL 语句
- 利用 explain 执行计划,查看 SQL 执行情况
- 关注索引使用情况:type
- 关注 Rows:行扫描
- 关注 Extra:没有信息最好 加索引后,查看索引使用情况,index 只是覆盖索引,并不算很好的使用索引
- 如果有关联尽量将索引用到 eq_ref 或 ref 级别
- 复杂 SQL 可以做成视图,视图在 MySQL 内部有优化,而且开发也比较友好
- 对于复杂的 SQL 要逐一分析,找到比较费时的 SQL 语句片段进行优化

若有收获,就点个赞吧
0 人点赞
