四、RDD高阶编程
1、序列化
在实际开发中会自定义一些对RDD的操作,此时需要注意的是:
- 初始化工作是在 Driver端进行的
- 实际运行程序是在 Executor端进行的
这就涉及到了进程之间的通信,需要进行序列化
- 过程和方法都具备序列化能力
普通的类不具有序列化能力
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢 复丢失的分区
- RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,可根据这些信息来重新运算 和恢复丢失的数据分区
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。 依赖有2个作用:其一用来解决数据容错;其二用来划分stage
- 窄依赖:1:1 或 n:1
- 宽依赖:n:m;意味着有 shuffle
【记住宽依赖,剩下的就是窄依赖】:_ByKey 和 大部分的_join操作都是宽依赖,其余的是窄依赖**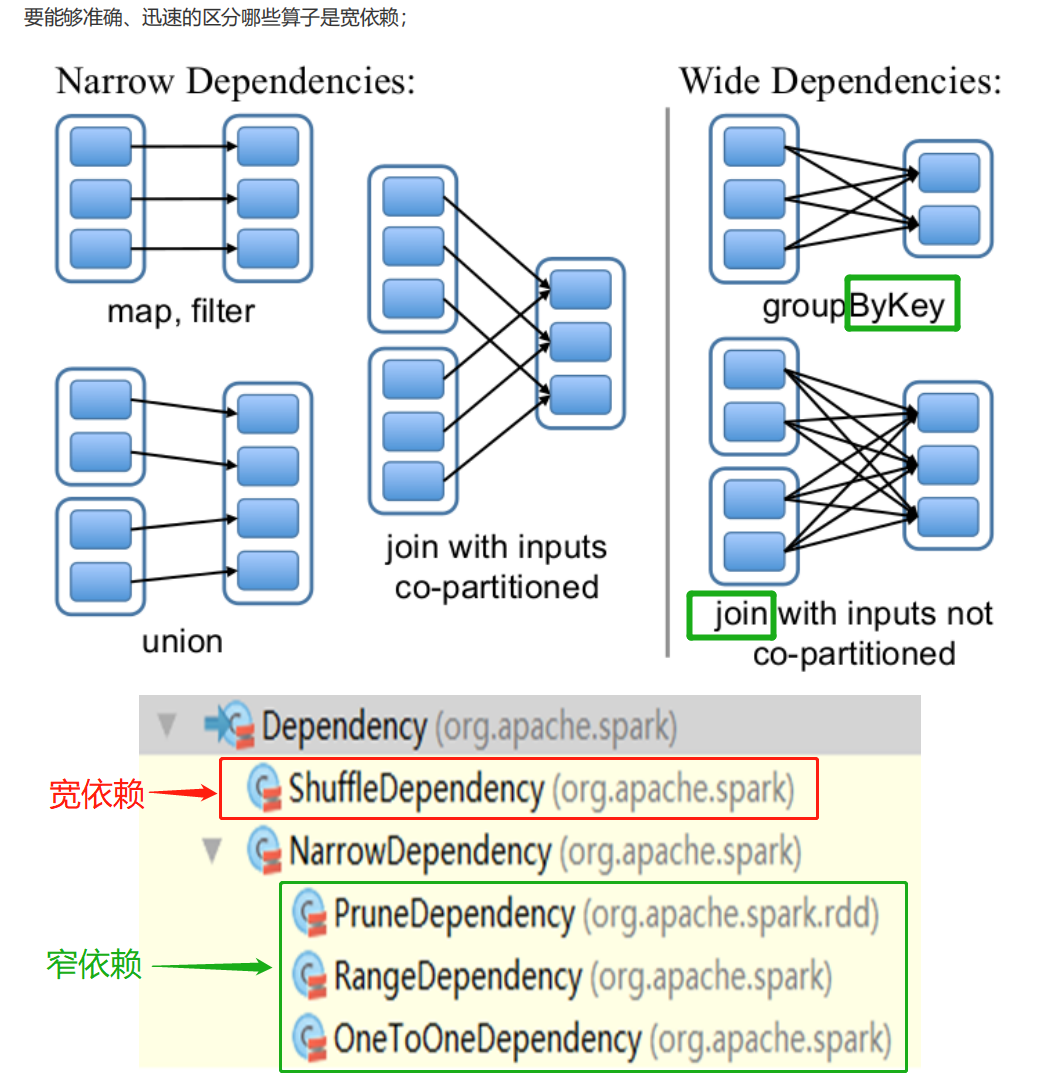
DAG(Directed Acyclic Graph)有向无环图,原始的RDD通过一系列的转换形成了DAG。根据RDD之间的依赖关系的不同,将DAG划分成不同的Stage:
- 对于窄依赖,partition的转换处理在stage中完成计算
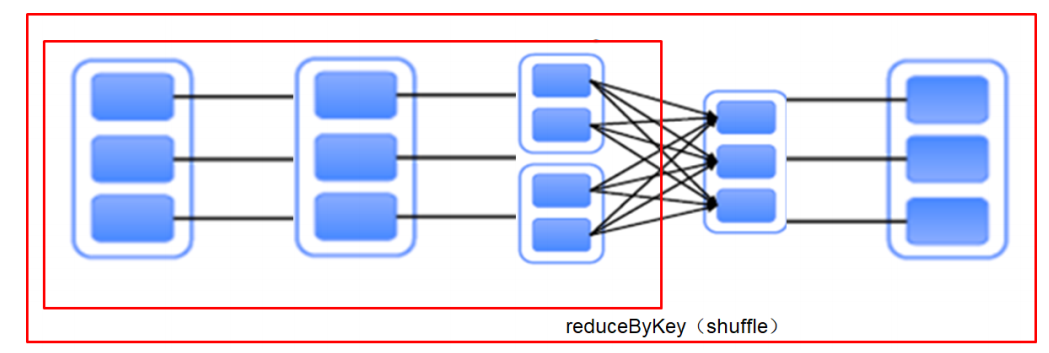
- 对于宽依赖,由于有shuffle的存在,只能在 parent RDD处理完成后,才能开始接下来的计算
- 宽依赖是 划分Stage 的依据
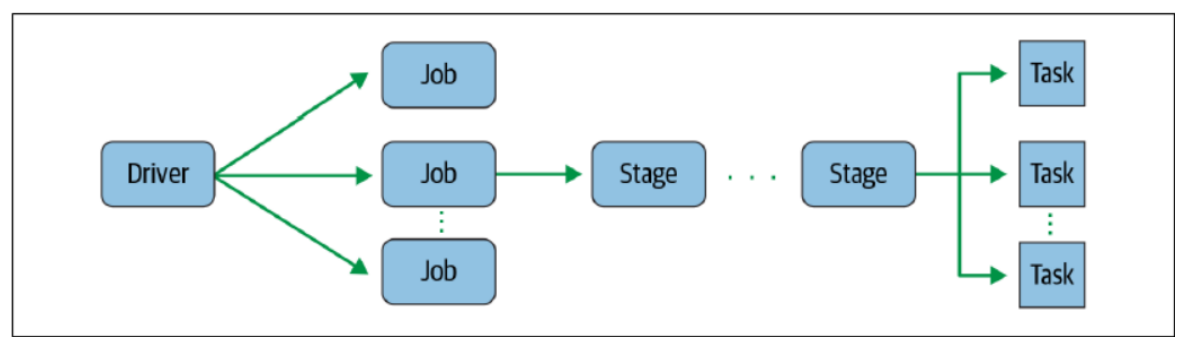
RDD任务切分中间分为:Driver programe、Job、Stage(TaskSet) 和 Task
- Driver program:初始化一个SparkContext即生成一个Spark应用
- Job:一个Action算子就会生成一个Job
- Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage
- Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task【task在 executor中执行】
- Task是Spark中任务调度的最小单位;每个Stage包含许多Task,这些Task执行的计算逻辑相同的,计算的数据 是不同的
注意:Driver programe -> Job -> Stage -> Task 每一层都是1对n的关系
// -------------窄依赖-------------val rdd1 = sc.parallelize(1 to 10, 1)val rdd2 = sc.parallelize(11 to 20, 1)val rdd3 = rdd1.union(rdd2)rdd3.dependencies.sizerdd3.dependencies// 打印rdd1的数据rdd3.dependencies(0).rdd.collect// 打印rdd2的数据rdd3.dependencies(1).rdd.collect=====================================================================// -------------宽依赖-------------val random = new scala.util.Randomval arr = (1 to 100).map(idx => random.nextInt(100))val rdd1 = sc.makeRDD(arr).map((_, 1))val rdd2 = rdd1.reduceByKey(_+_)// 观察依赖rdd2.dependenciesrdd2.dependencies(0).rdd.collectrdd2.dependencies(0).rdd.dependencies(0).rdd.collect
再谈WordCount:
val rdd1 = sc.textFile("/wcinput/wc.txt")val rdd2 = rdd1.flatMap(_.split("\\s+"))val rdd3 = rdd2.map((_, 1))val rdd4 = rdd3.reduceByKey(_+_)val rdd5 = rdd4.sortByKey()rdd5.count// 查看RDD的血缘关系rdd1.toDebugStringrdd5.toDebugString// 查看依赖rdd1.dependenciesrdd1.dependencies(0).rddrdd5.dependenciesrdd5.dependencies(0).rdd// 查看最佳优先位置val hadoopRDD = rdd1.dependencies(0).rddhadoopRDD.preferredLocations(hadoopRDD.partitions(0))# 使用 hdfs 命令检查文件情况hdfs fsck /wcinput/wc.txt -files -blocks -locations
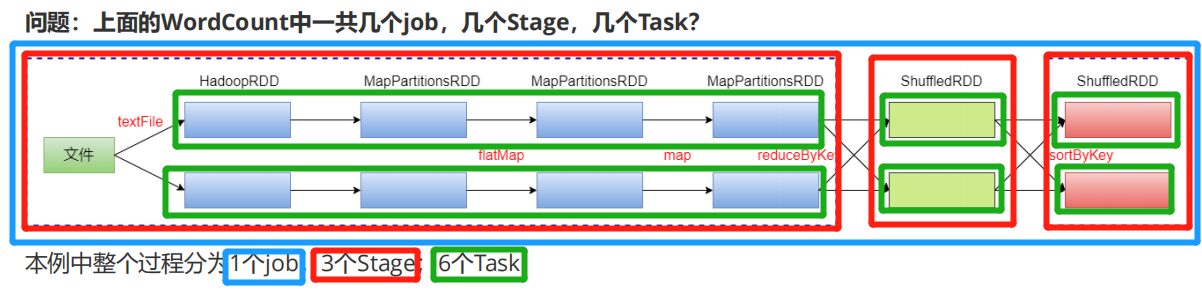
- 注:stage是有宽依赖的shuffle来划分的
3、RDD持久化/缓存
涉及到的算子:persist、cache、unpersist【都是Transformation算子】
- 缓存:将计算结果写入不同的介质,用户可定义存储级别(存储级别目前支持内存、堆外内存[JVM之外]、磁盘)
- 缓存是Spark构建迭代式算法和快速交互式查询的关键因 素。Spark速度非常快的原因之一,就是在内存中持久化(或缓存)一个数据集:当持久化一个RDD后,每一个节点都将计算的分片结果保存在内存中,并在对此数据集进行的其他Action中重用。
- 使用persist对一个RDD进行持久化的标记【Transformation】,遇到Action时持久化操作会被触发。
1、一般什么时候需要缓存数据:一般情况下,如果多个动作需要用到某个RDD,而它的计算代价有很高,则应该把该RDD缓存起来
2、缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除。RDD的缓存的容错机制保证了即使缓存丢失也能保证计算的正确执行。基于RDD的一系列转换,丢失的数据会被重算。RDD的各个Partition之间相对独立,因此只需要计算丢失的部分即可。
Spark默认缓存级别是:memory_only
4、容错机制 Checkpoint
涉及到的算子:checkpoint【Transformation】
- 检查点本质:将RDD写入到高可靠的磁盘,为了容错
- Lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从 做检查点的RDD开始重做Lineage,就会减少开销
- cache 和 checkpoint的区别:缓存把 RDD 计算出来然后放在内存中,但是 RDD 的依赖链不能丢掉,当某 个点某个 executor 宕了,上面 cache 的RDD就会丢掉, 需要通过依赖链重放计算。而 checkpoint 是把 RDD 保存在 HDFS中,是多副本可靠存储,此时依赖链可以丢掉,所以斩断了依赖链
以下场景适合使用检查点机制:
1、DAG中的Lineage过长,如果重算,开销太大
2、在宽依赖上做 Checkpoint获得的收益更大【免去了shuffle】
val rdd1 = sc.parallelize(1 to 100000)// 设置检查点目录sc.setCheckpointDir("/tmp/checkpoint")val rdd2 = rdd1.map(_*2)rdd2.checkpoint// checkpoint是lazy操作rdd2.isCheckpointed// checkpoint之前的rdd依赖关系rdd2.dependencies(0).rddrdd2.dependencies(0).rdd.collect// 执行一次action,触发checkpoint的执行rdd2.count rdd2.isCheckpointed// 再次查看RDD的依赖关系。可以看到checkpoint后,RDD的lineage被截断,变成从checkpointRDD开始rdd2.dependencies(0).rddrdd2.dependencies(0).rdd.collect//查看RDD所依赖的checkpoint文件rdd2.getCheckpointFile
备注:checkpoint的文件作业执行完毕后不会被删除
5、RDD的分区
spark.default.parallelism:(默认的并发数)= 2
当配置文件spark-default.conf中没有显示的配置,则按照如下规则取值:
1、本地模式
spark-shell --master local[N] spark.default.parallelism = Nspark-shell --master local spark.default.parallelism = 1
2、伪分布式(x为本机上启动的executor数,y为每个executor使用的core数,z为每个 executor使用的内存)
spark-shell --master local-cluster[x,y,z]spark.default.parallelism = x * y
3、分布式模式(yarn & standalone)
spark.default.parallelism = max(应用程序持有executor的core总数, 2)备注:total number of cores on all executor nodes or 2, whichever is larger
经过上面的规则,就能确定了spark.default.parallelism的默认值(配置文件spark-default.conf中没有显示的配置。 如果配置了,则spark.default.parallelism = 配置的值)
SparkContext初始化时,同时会生成两个参数,由上面得到 spark.default.parallelism推导出这两个参数的值:
// 从集合中创建RDD的分区数sc.defaultParallelism = spark.default.parallelism// 从文件中创建RDD的分区数sc.defaultMinPartitions = min(spark.default.parallelism, 2)
以上参数确定后,就可以计算 RDD 的分区数了:
创建 RDD 的几种方式:
1、通过集合创建
// 如果创建RDD时没有指定分区数,则rdd的分区数 = sc.defaultParallelismval rdd = sc.parallelize(1 to 100)rdd.getNumPartitions
备注:简单的说RDD分区数等于cores总数
2、通过textFile创建
val rdd = sc.textFile("data/start0721.big.log")rdd.getNumPartitions
如果没有指定分区数:
- 本地文件。rdd的分区数 = max(本地文件分片数, sc.defaultMinPartitions)
- HDFS文件。 rdd的分区数 = max(hdfs文件 block 数, sc.defaultMinPartitions)
备注:
- 本地文件分片数 = 本地文件大小 / 32M
- 如果读取的是HDFS文件,同时指定的分区数 < hdfs文件的block数,指定的数不生效
6、RDD分区器
- 只有Key-Value类型的RDD才可能有分区器,Value类型的RDD分区器的值是None
分区器的作用及分类:
- 在 PairRDD(key,value) 中,很多操作都是基于key的,系统会按照key对数据进行重组,如groupbykey;
- 数据重组需要规则,最常见的就是基于 Hash 的分区,此外还有一种复杂的基于抽样 Range 分区方法;
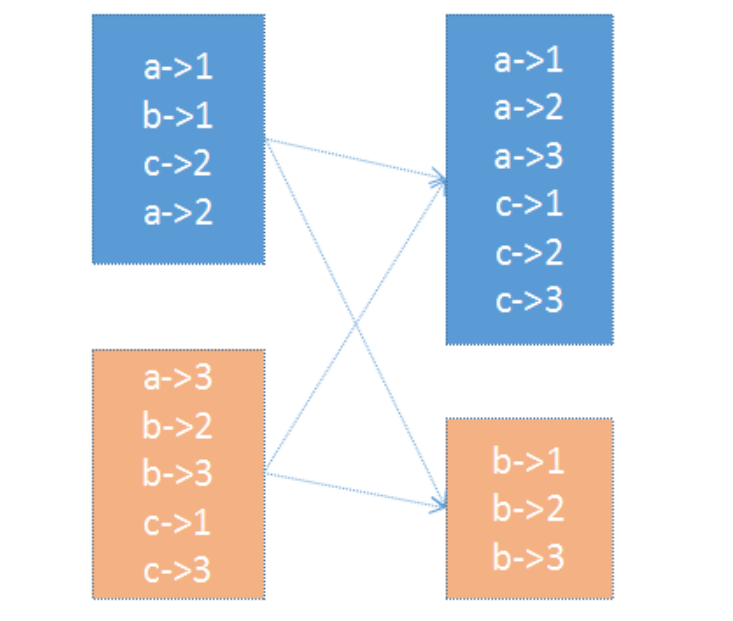
HashPartitioner
- 最简单、最常用,也是默认提供的分区器。对于给定的key,计算其hashCode,并除以分区的 个数取余,如果余数小于0,则用 余数+分区的个数,最后返回的值就是这个key所属的分区ID。该分区方法可以保证 key相同的数据出现在同一个分区中。
- 用户可通过 partitionBy 主动使用分区器,通过partitions参数指定想要分区的数量 ```scala val rdd1 = sc.makeRDD(1 to 100).map((_, 1)) rdd1.getNumPartitions
// 仅仅是将数据大致平均分成了若干份;rdd并没有分区器 rdd2.glom.collect.foreach(x=>println(x.toBuffer)) rdd1.partitioner
// 主动使用 HashPartitioner val rdd2 = rdd1.partitionBy(new org.apache.spark.HashPartitioner(10)) rdd2.glom.collect.foreach(x=>println(x.toBuffer))
// 主动使用 HashPartitioner val rdd3 = rdd1.partitionBy(new org.apache.spark.RangePartitioner(10, rdd1)) rdd3.glom.collect.foreach(x=>println(x.toBuffer))
Spark的很多算子都可以设置 HashPartitioner 的值:<br /><a name="CVC6o"></a>### RangePartitioner- 简单的说就是将一定范围内的数映射到某一个分区内。在实现中,分界的算法尤为重要,用到了**水塘抽样算法**。sortByKey会使用RangePartitioner- 现在的问题:在执行分区之前其实并不知道数据的分布情况,如果想知道数据分区就需要对**数据进行采样**;Spark中RangePartitioner在对数据采样的过程中使用了**水塘采样算法**。- **水塘采样:**从包含n个项目的集合S中选取k个样本,其中n为一很大或未知的数量,尤其适用于不能把所有n个项目都存放到主内存的情况;- 在采样的过程中执行了collect()操作,引发了Action操作<a name="WAHP0"></a>### 自定义分区器- Spark允许用户通过自定义的 Partitioner对象,灵活的来控制RDD的分区方式。实现自定义分区器按以下规则分区```scalapackage cn.lagou.sparkcoreimport org.apache.spark.rdd.RDDimport org.apache.spark.{Partitioner, SparkConf, SparkContext}import scala.collection.immutableclass MyPartitioner(n: Int) extends Partitioner{override def numPartitions: Int = noverride def getPartition(key: Any): Int = {val k = key.toString.toInt k / 100}}object UserDefinedPartitioner {def main(args: Array[String]): Unit = {// 创建SparkContextval conf = new SparkConf().setAppName(this.getClass.getCanonicalName).setMaster("local[*]")val sc = new SparkContext(conf)sc.setLogLevel("WARN")// 业务逻辑val random = scala.util.Randomval arr: immutable.IndexedSeq[Int] = (1 to 100).map(idx => random.nextInt(1000))val rdd1: RDD[(Int, Int)] = sc.makeRDD(arr).map((_, 1))rdd1.glom.collect.foreach(x => println(x.toBuffer))println("********************************************************************************")val rdd2 = rdd1.partitionBy(new MyPartitioner(10))rdd2.glom.collect.foreach(x => println(x.toBuffer))// 关闭SparkContextsc.stop()}}
7、广播变量
- 有时候需要在多个任务之间共享变量,或者在任务(Task)和Driver Program之间共享变量。为了满足这种需求,
Spark提供了两种类型的变量
- 广播变量(broadcast variables)
- 累加器(accumulators)
广播变量、累加器主要作用是为了优化Spark程序。
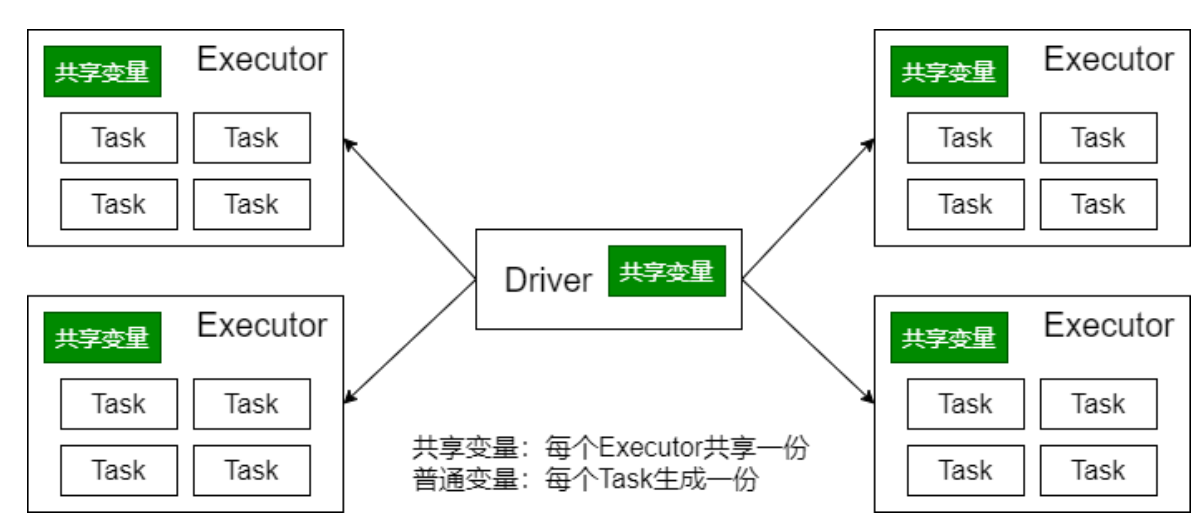
- 广播变量将变量在节点的 Executor 之间进行共享(由Driver广播出去);
- 广播变量用来高效分发较大的对象。向所有工作节点(Executor)发送一个较大的只读值,以供一个或多个操作使用。
- 使用广播变量的过程如下:
- 对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。 任何可序列化的类型都可 以这么实现(在 Driver 端)
- 通过 value 属性访问该对象的值(在 Executor 中)
- 变量只会被发到各个 Executor 一次,作为只读值 处理
广播变量的相关参数:
- spark.broadcast.blockSize (缺省值:4m)
- spark.broadcast.checksum(缺省值:true)
- spark.broadcast.compress(缺省值:true)
广播变量的运用(Map Side Join)
(1)普通的Join操作:
(2)Map Side Join: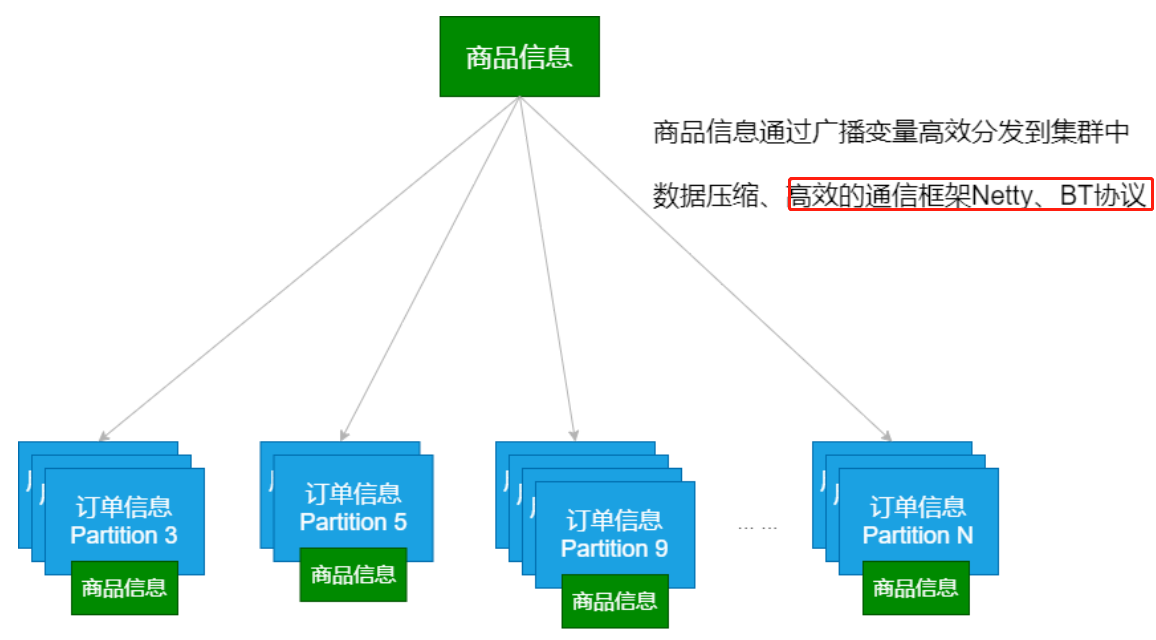
执行时间46s,shuffle read 450M:
import org.apache.spark.rdd.RDimport org.apache.spark.{SparkConf, SparkContext}object JoinDemo {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getCanonicalName.init)val sc = new SparkContext(conf)// 设置本地文件切分大小sc.hadoopConfiguration.setLong("fs.local.block.size", 128*1024*1024)// map task:数据准备val productRDD: RDD[(String, String)] = sc.textFile("data/lagou_product_info.txt").map { line =>val fields = line.split(";") (fields(0), line)}val orderRDD: RDD[(String, String)] = sc.textFile("data/orderinfo.txt",8 ).map { line =>val fields = line.split(";")(fields(2), line)}// join有shuffle操作val resultRDD = productRDD.join(orderRDD)println(resultRDD.count())Thread.sleep(1000000) sc.stop()}}
执行时间14s,没有shuffle:
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object MapSideJoin {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getCanonicalName.init)val sc = new SparkContext(conf)// 设置本地文件切分大小sc.hadoopConfiguration.setLong("fs.local.block.size", 128*1024*1024)// 数据合并:有大量的数据移动val productRDD: RDD[(String, String)] = sc.textFile("data/lagou_product_info.txt").map { line =>val fields = line.split(";")(fields(0), line)}val productBC = sc.broadcast(productRDD.collectAsMap())// map task:完成数据的准备val orderRDD: RDD[(String, String)] = sc.textFile("data/orderinfo.txt",8 ).map { line =>val fields = line.split(";")(fields(2), line)}// map端的joinval resultRDD = orderRDD.map{case (pid, orderInfo) => val productInfo = productBC.value(pid, (orderInfo, productInfo.getOrElse(pid, null)))}println(resultRDD.count())Thread.sleep(1000000) sc.stop()}}
8、累加器【不常用】
- 累加器的作用:可以实现一个变量在不同的 Executor 端能保持状态的累加;
- 累计器在 Driver 端定义,读取;在 Executor 中完成累加;
- 累加器也是 lazy 的,需要 Action 触发;Action触发一次,执行一次,触发多次,执行多次;
- 累加器一个比较经典的应用场景是用来在 Spark Streaming 应用中记录某些事件的数量;
Spark内置了三种类型的累加器,分别是
LongAccumulator用来累加整数型DoubleAccumulator用来累加浮点型CollectionAccumulator用来累加集合元素【底层是 List】 ```scala val data = sc.makeRDD(“hadoop spark hive hbase java scala hello world spark scala java hive”.split(“\s+”)) val acc1 = sc.longAccumulator(“totalNum1”) val acc2 = sc.doubleAccumulator(“totalNum2”) val acc3 = sc.collectionAccumulatorString val rdd = data.map { word => acc1.add(word.length) acc2.add(word.length) acc3.add(word) word }
rdd.count rdd.collect
println(acc1.value) println(acc2.value) println(acc3.value)
<a name="hoAcS"></a>## 9、TopN的优化```scalapackage cn.lagou.sparkcoreimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}import scala.collection.immutableobject TopN {def main(args: Array[String]): Unit = {// 创建SparkContextval conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")val sc = new SparkContext(conf)sc.setLogLevel("WARN")val N = 9// 生成数据val random = scala.util.Randomval scores: immutable.IndexedSeq[String] = (1 to 50).flatMap {idx => (1 to 2000).map {id => f"group$idx%2d,${random.nextInt(100000)}"}}val scoresRDD: RDD[(String, Int)] = sc.makeRDD(scores).map {line => val fields: Array[String] = line.split(",")(fields(0), fields(1).toInt)}scoresRDD.cache()// TopN的实现// groupByKey的实现,需要将每个分区的每个group的全部数据做shufflescoresRDD.groupByKey().mapValues(buf => buf.toList.sorted.takeRight(N).reverse).sortByKey().collect.foreach(println)println("******************************************")// TopN的优化scoresRDD.aggregateByKey(List[Int]())((lst, score) => (lst :+ score).sorted.takeRight(N),(lst1, lst2) => (lst1 ++ lst2).sorted.takeRight(N)).mapValues(buf => buf.reverse).sortByKey().collect.foreach(println)// 关闭SparkContextsc.stop()}}
五、Spark原理初探
1、Standalone模式作业提交
Standalone 模式下有四个重要组成部分,分别是:
- Driver:用户编写的 Spark 应用程序就运行在 Driver 上,由Driver 进程执行
- Master:主要负责资源的调度和分配,并进行集群的监控等职责
- Worker:Worker 运行在集群中的一台服务器上。负责管理该节点上的资源,负责启动启动节点上的 Executor
- Executor:一个 Worker 上可以运行多个 Executor,Executor通过启动多个线程(task)对 RDD 的分区进行 并行计算
SparkContext 中的三大组件:
- DAGScheduler:负责将DAG划分成若干个Stage
- TaskScheduler:将DAGScheduler提交的 Stage(Taskset)进行优先级排序,再将 task 发送到 Executor
- SchedulerBackend:定义了许多与Executor事件相关的处理,包括:新的executor注册进来的时候记录executor 的信息,增加全局的资源量(核数);executor更新状态,若任务完成的话,回收core;其他停止executor、remove 、executor等事件
Standalone模式下作业提交步骤:
1、启动应用程序,完成SparkContext的初始化
2、Driver向Master注册,申请资源
3、Master检查集群资源状况。若集群资源满足,通知Worker启动Executor
4、Executor启动后向Driver注册(称为反向注册)
5、Driver完成DAG的解析,得到Tasks,然后向Executor发送Task
6、Executor 向Driver汇总任务的执行情况
7、应用程序执行完毕,回收资源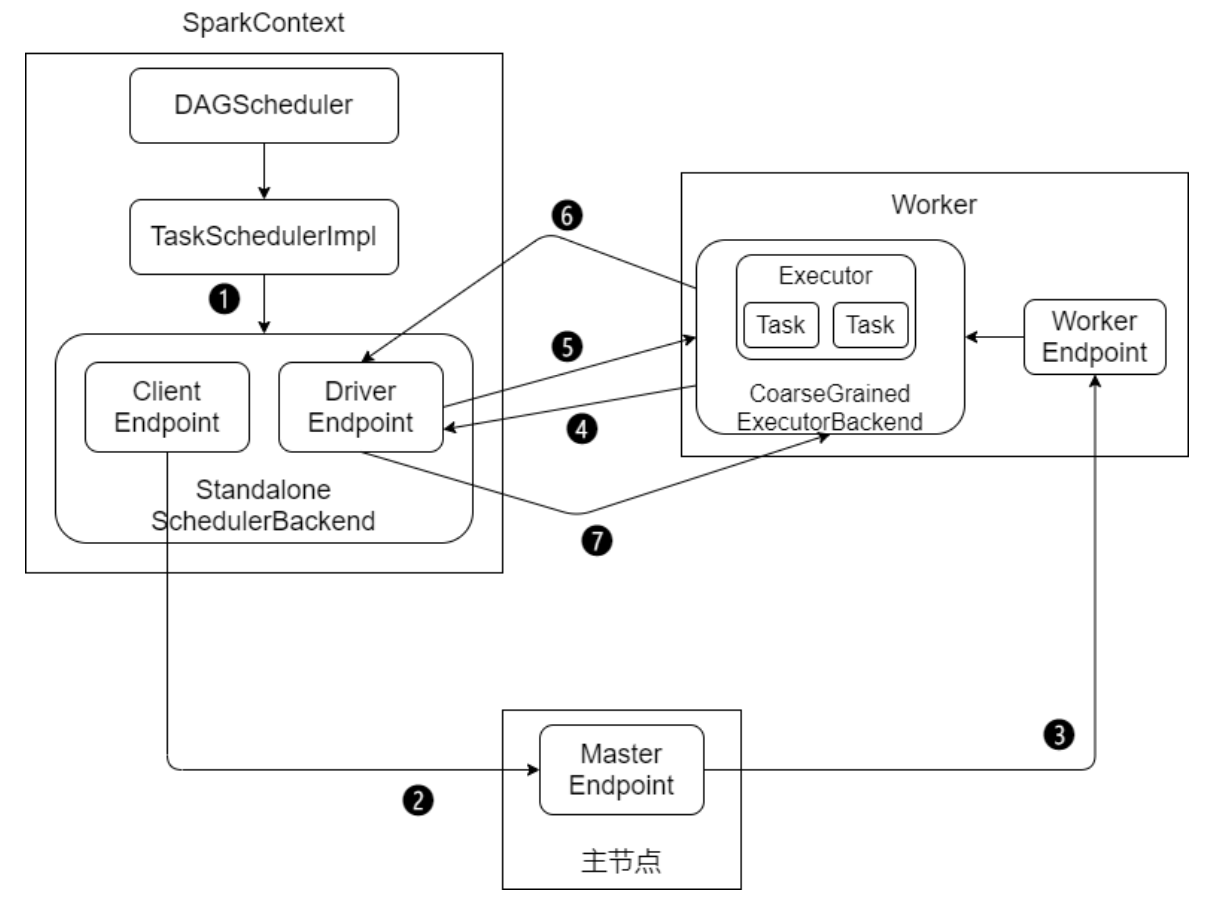
2、shuffle原理
- Shuffle的本意是洗牌,目的是为了把牌弄乱。
- Spark、Hadoop中的Shuffle可不是为了把数据弄乱,而是为了将随机排列的数据转换成具有一定规则的数据 。
- Shuffle是MapReduce计算框架中的一个特殊的阶段,介于Map 和 Reduce 之间。当Map的输出结果要被Reduce使 用时,输出结果需要按key排列,并且分发到Reducer上去,这个过程就是Shuffle。
- Shuffle涉及到了本地磁盘(非hdfs)的读写和网络的传输,大多数Spark作业的性能主要就是消耗在了Shuffle环节。 因此Shuffle性能的高低直接影响到了整个程序的运行效率
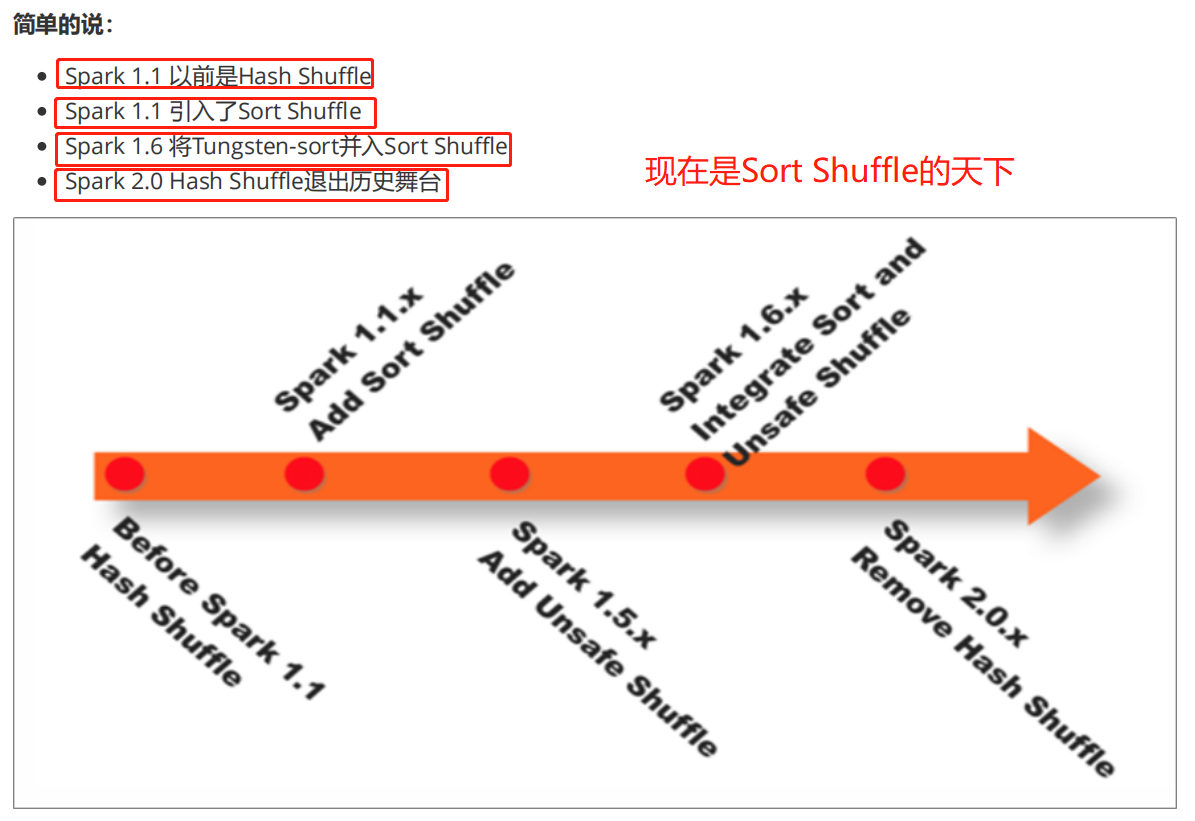
在Spark Shuffle的实现上,经历了Hash、Sort、Tungsten-Sort(堆外内存)三阶段:
- Spark 0.8 及以前 Hash Based Shuffle
- Spark 0.8.1 为Hash Based Shuffle引入File Consolidation机制
- Spark 0.9 引入ExternalAppendOnlyMap
- Spark 1.1 引入Sort Based Shuffle,但默认仍为Hash Based Shuffle
- Spark 1.2 默认的Shuffle方式改为Sort Based Shuffle
- Spark 1.4 引入Tungsten-Sort Based Shuffle
- Spark 1.6 Tungsten-sort并入Sort Based Shuffle
- Spark 2.0 Hash Based Shuffle退出历史舞台
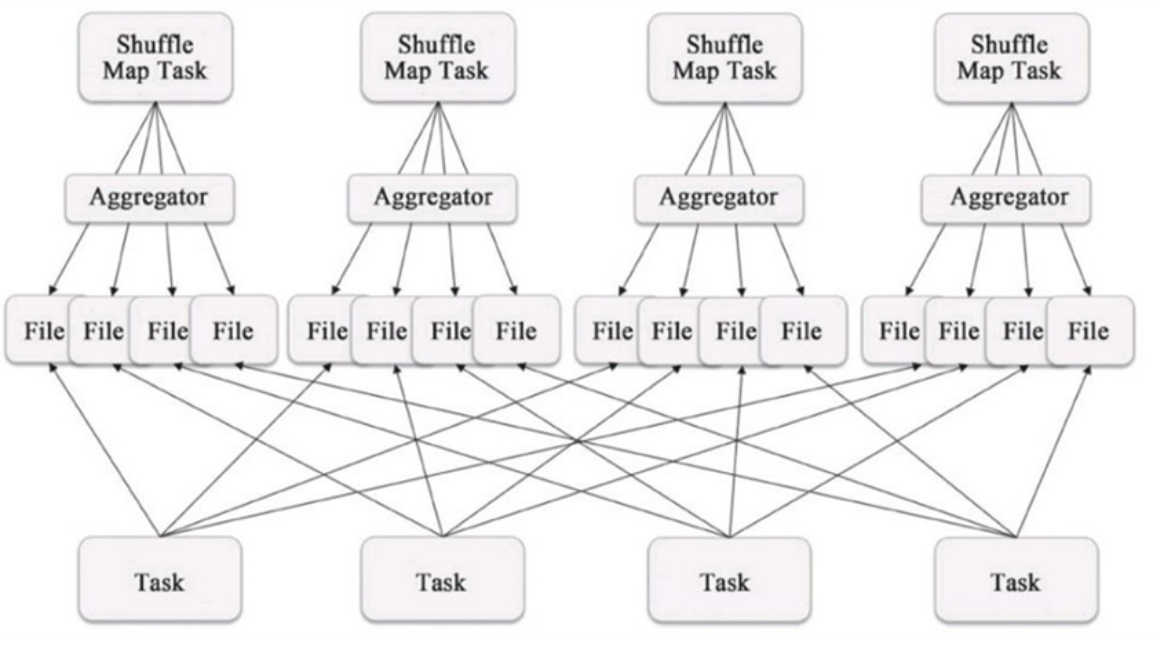
(1)Hash Base Shuffle V1
- 每个Shuffle Map Task需要为每个下游的Task创建一个单独的文件
- Shuffle 过程中会生成海量的小文件。同时打开过多文件、低效的随机IO
(2)Hash Base Shuffle V2
- Hash Base Shuffle V2 核心思想:允许不同的task复用同一批磁盘文件 ,有效将多个task的磁盘文件进行一定程度上 的合并,从而大幅度减少磁盘文件的数量,进而提升Shuffle write的性能。一定程度上解决了Hash V1中的问题,但 不彻底。
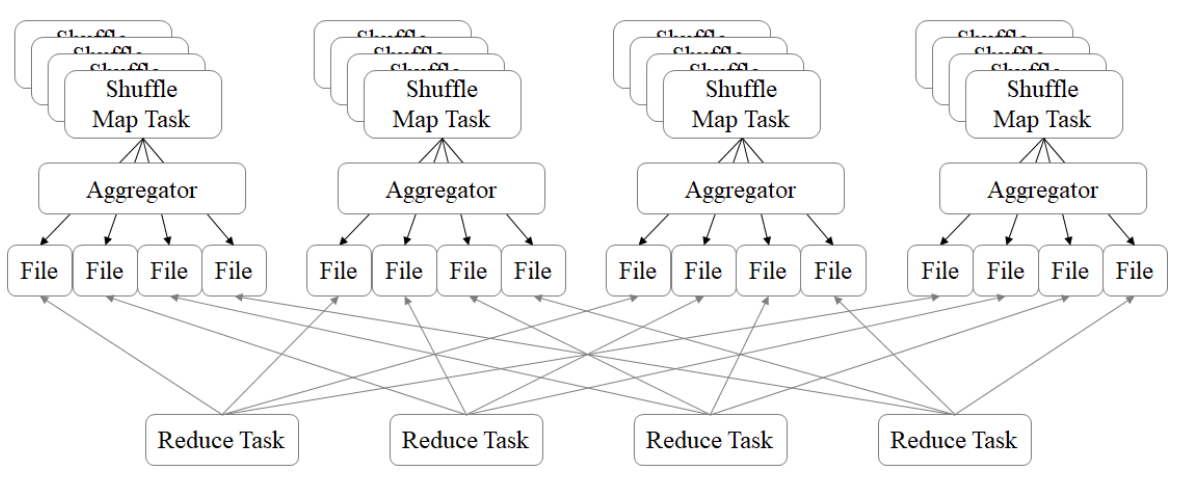
Hash Shuffle 规避了排序,提高了性能;总的来说在Hash Shuffle 过程中生成海量的小文件
(Hash Base Shuffle V2 使得生成海量小文件的问题得到了一定程度的缓解)
(3)Sort Base Shuffle
Sort Base Shuffle 大大减少了Shuffle 过程中产生的文件数,提高Shuffle 的效率;
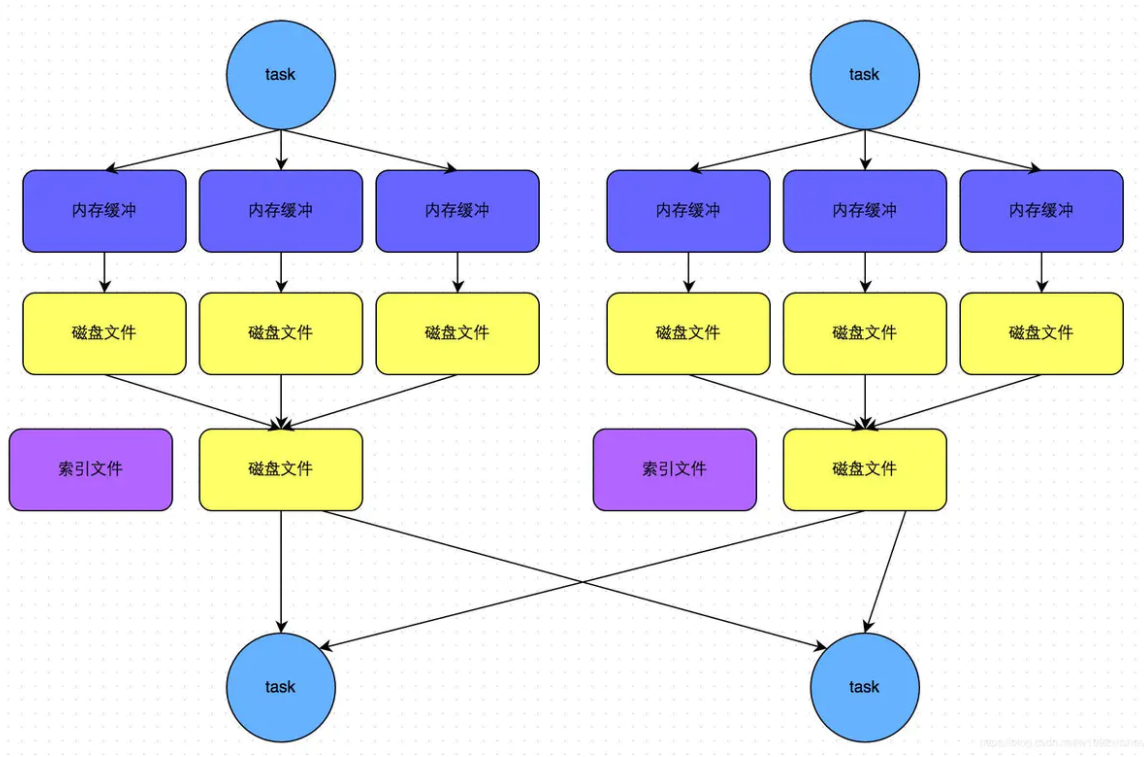
备注:Spark Shuffle 与 Hadoop Shuffle 从目的、意义、功能上看是类似的,实现(细节)上有区别。
3、RDD编程优化
1、RDD复用
- 避免创建重复的RDD。在开发过程中要注意:对于同一份数据,只应该创建一个RDD,不要创建多个RDD来代表同 一份数据。
2、RDD缓存/持久化
- 当多次对同一个RDD执行算子操作时,每一次都会对这个RDD以之前的父RDD重新计算一次,这种情况是必须 要避免的,对同一个RDD的重复计算是对资源的极大浪费
- 对多次使用的RDD进行持久化,通过持久化将公共RDD的数据缓存到内存/磁盘中,之后对于公共RDD的计算都 会从内存/磁盘中直接获取RDD数据
- RDD的持久化是可以进行序列化的,当内存无法将RDD的数据完整的进行存放的时候,可以考虑使用序列化的 方式减小数据体积,将数据完整存储在内存中
3、巧用 fifilter
- 尽可能早的执行filter操作,过滤无用数据
- 在filter过滤掉较多数据后,使用 coalesce 对数据进行重分区
4、使用高性能算子
- 避免使用groupByKey,根据场景选择使用高性能的聚合算子 reduceByKey、aggregateByKey
coalesce、repartition,在可能的情况下优先选择没有shufflfflffle的操作
foreachPartition 优化输出操作
map、mapPartitions,选择合理的选择算子
mapPartitions性能更好,但数据量大时容易导致OOM
用 repartitionAndSortWithinPartitions 替代 repartition + sort 操作
合理使用 cache、persist、checkpoint,选择合理的数据存储级别
filter的使用
减少对数据源的扫描(但是算法会变复杂)
5、设置合理的并行度
- Spark作业中的并行度指各个stage的task的数量
- 设置合理的并行度,让并行度与资源相匹配。简单来说就是在资源允许的前提下,并行度要设置的尽可能大, 达到可以充分利用集群资源。合理的设置并行度,可以提升整个Spark作业的性能和运行速度
6、广播大变量
- 默认情况下,task中的算子中如果使用了外部变量,每个task都会获取一份变量的复本,这会造多余的网络传输 和内存消耗
- 使用广播变量,只会在每个Executor保存一个副本,Executor的所有task共用此广播变量,这样就节约了网络 及内存资源

若有收获,就点个赞吧
0 人点赞
