- 1.获取资源
- 2.查看资源详情
- 3.kubernetes设计Pod中为何要有pause根容器
- 4.修改RC(Replication Controller)的副本数量来实现Pod的动态缩放
- 5.创建Horizontal Pod Autoscaler
- 6.StatefulSet
- 7.查看资源yaml
- 8.删除资源
- 9.执行容器的命令
- 10.查看容器的日志
- 11.创建资源对象
- 12.创建或更新资源对象
- 13.在线编辑运行中的资源对象
- 14.将Pod的开放端口映射到本地
- 15.在Pod和本地之间复制文件
- 16.资源对象的标签设置
- 17.检查可用的API资源类型列表
- 18.通过kubectl创建ConfigMap
- 19.Pod挂载ConfigMap
- 20.进入容器内部
- 21.在容器内获取Pod信息(Downward API)
- 22.Pod状态
- 23.Pod重启策略
- 24.Pod健康检查和服务可用性检查
- 25.Deployment全自动调度
- 26.NodeSelector定向调度
- 27.NodeAffinity亲和性调度
- 28.PodAffinity亲和与互斥调度策略
- 29.Taints和Tolerations(污点和容忍)
- 30.Pod Priority Preemption:Pod优先级调度
- 31.DaemonSet:在每个Node上都调度一个Pod
- 32.Init Container:初始化容器
- 33.Deployment的升级与回滚
- 34.暂停和恢复Deployment的部署操作,以完成复杂的修改
- 35.使用kubectl rolling-update命令完成RC的滚动升级
- 36.Pod手动扩容机制
- 37.Pod自动扩容机制
- 38.使用StatefulSet搭建MongoDB集群
1.获取资源
kubectl get <reousrce_type>
2.查看资源详情
kubectl describe <reousrce_type> <reousrce_name>
3.kubernetes设计Pod中为何要有pause根容器
- Pause作为Pod的根容器,可以代表整个容器组的状态
- Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume,简化了业务容器之间的通信问题,也解决了它们之间文件共享问题
4.修改RC(Replication Controller)的副本数量来实现Pod的动态缩放
# 维持三个副本kubectl scale rc <pod_name> --replicas=3
5.创建Horizontal Pod Autoscaler
# 自动进行副本数量管理,当cpu占用大于90%,pod副本数量为1~10kubectl autoscale deployment <deployment_name> --cpu-percent=90 --min=1 --max=10
6.StatefulSet
管理有状态服务,如mysql集群、kafka集群、zookeeper集群等
StatefulSet可以看作Deployment/RC的变种
如果StatefulSet名称为kafka,那么第一个Pod叫kafka-0,第二个叫kafka-1,以此类推
7.查看资源yaml
kubectl get <resource_type> <resource_name> -o=yaml
8.删除资源
# 删除所有Podkubernetes delete pods --all# 删除包含某个Label的Pod和Servicekubernetes delete pods,services -1 name=<label-name>
9.执行容器的命令
# 执行Pod的date命令,默认使用Pod中的第一个容器执行kubectl exec <pod_name> date# 指定Pod中的某个容器执行date命令kubectl exec <pod_name> -c <container_name> date# 通过bash获得Pod中某个容器的TTY,相当于登录容器kubectl exec -ti <pod_name> -c <container_name> /bin/bash
10.查看容器的日志
# 查看容器输出到stdout的日志kubectl logs <pod_name># 跟踪查看容器的日志,相当于tail -f命令的结果kubectl logs -f <pod_name> -c <container_name>
11.创建资源对象
# 根据yaml配置文件一次性创建Service和RCkubectl create -f my-service.yaml -f my-rc.yaml# 根据<directory>目录下的所有.yaml、.yml、.json文件的定义进行创建kubectl create -f <directory>
12.创建或更新资源对象
# 用法与kubectl create类似,但是create不能做更新kubectl apply -f app.yaml
13.在线编辑运行中的资源对象
# 编辑运行中的deploymentkubectl edit deploy nginx
14.将Pod的开放端口映射到本地
# 将集群上Pod的80端口映射到本地的8888端口,浏览器可通过localhost:8888进行访问kubectl port-forward --address 0.0.0.0 \ pod/<pod_name> 8888:80
15.在Pod和本地之间复制文件
# 把Pod上的/etc/fstab 复制到本地的/tmpkubernetes cp <pod_name>:/etc/fstab /tmp
16.资源对象的标签设置
# 为default namespace设置testing=truekubectl label namespaces default testing=true
17.检查可用的API资源类型列表
# 该命令经常用于检查特定类型的资源是否已经定义,列出所有资源对象类型kubectl api-resources
18.通过kubectl创建ConfigMap
# 通过--from-file,指定文件,key就是文件名,value就是文件内容kubectl create configmap <cm_name> --from-file=<file_name> --from-file=<file_name># 通过--from-file参数从目录中进行创建,该目录下的每个配置文件名都被设置为key,文件的内容被设置为valuekubectl create configmap <cm_name> --from-file=<config_file_dir># 使用--from-literal,直接将指定key和valuekubectl create configmap <cm_name> --from-literal=key1=value1 --from-literal=key2=value2
19.Pod挂载ConfigMap
# 环境变量方式(1)apiVersion: v1kind: Podmetadata:name: cm-test-podspec:containers:- name: cm-testimage: busyboxcommand: ["/bin/sh", "-c", "env | grep APP"]env:# 定义环境变量名称- name: APPLOGLEVEL# key"apploglevel"对应的值valueFrom:configMapKeyRef:# configmap的名称name: cm-appvars# key为apploglevelkey: apploglevel- name: APPDATADIRvalueFrom:configMapKeyRef:name: cm-appvarskey: appdatadirrestartPolicy: Never# 环境变量方式(2),k8s1.6开始,引入了一个新字段evnFrom,会自动将ConfigMap种所有定义的key-value生成为环境变量apiVersion: v1kind: Podmetadata:name: cm-test-podspec:containers:- name: cm-testimage: busyboxcommand: ["/bin/sh", "-c", "env"]envFrom:- configMapRef:# configmap名称name: cm-appvarsrestartPolicy: Never# 通过volumeMount使用ConfigMapapiVersion: v1kind: Podmetadata:name: cm-test-podspec:containers:- name: cm-testimage: busyboxports:- containerPort: 8087volumeMounts:# 引用volume名称- name: vname# 挂载到容器内的目录mountPath: /configfilesvolumes:# 定义volume名称- name: vnameconfigMap:# configmap名称name: cm-appvars
20.进入容器内部
kubectl exec -ti <pod_name> bash
21.在容器内获取Pod信息(Downward API)
可以获取Pod名称、命名空间、IP等;通过查看Pod日志获取信息
# 环境变量方式:将Pod信息注入为环境变量# metadata.name:Pod的名称,当Pod通过RC生成时,其名称是RC随机产生的唯一名称。# status.podIP:Pod的IP地址,之所以叫作status.podIP而非metadata.IP,是因为Pod的IP属于状态数据,而非元数据。# metadata.namespace:Pod所在的NamespaceapiVersion: v1kind: Podmetadata:name: dapi-test-podspec:containers:- name: dapi-testimage: busyboxcommand:- /bin/sh- '-c'- envenv:- name: MY_POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: MY_POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace- name: MY_POD_IPvalueFrom:fieldRef:fieldPath: status.podIP# 环境变量方式:将容器资源信息注入为环境变量apiVersion: v1kind: Podmetadata:name: dapi-test-podspec:containers:- name: dapi-testimage: busyboximagePullPolicy: Neverports:- containerPort: 8087command:- /bin/sh- '-c'env:- name: MY_CPU_REQUESTvalueFrom:resourceFieldRef:containerName: dapi-testresource: requests.cpu- name: MY_CPU_LIMITvalueFrom:resourceFieldRef:containerName: dapi-testresource: limits.cpu- name: MY_MEM_LIMITvalueFrom:resourceFieldRef:containerName: dapi-testresource: limits.memory# 挂载volume方式---
22.Pod状态
Pending:API Server已经创建该Pod,但在Pod内还有一个或多个容器的镜像还没被创建,包括正在下载镜像的过程;
Running:Pod内所有的容器均已创建,且至少有一个容器处于运行状态,正在启动状态或正在重启状态;
Succeeded:Pod内所有容器均已成功执行后退出,且不会重启;
Failed:Pod内所有容器均已退出,但至少有一个容器退出为失败状态;
Unknow:由于某种原因无法获取该Pod状态,可能由于网络通信不畅导致。
23.Pod重启策略
Pod重启策略(RestartPolicy)应用于Pod内的所有容器,并且在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应的操作。
Pod的重启策略包括 Always(默认)、OnFailure、Never:
- Always:当容器失败时,由kubelet自动重启该容器;
- OnFailure:当容器终止运行且退出码不为0时,由kubelet重启该容器;
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
kubelet重启失效容器的时间间隔以sync-frequnecy乘以2n来计算,例如1、2、4、8倍等,最长延迟5min,并且在重启后10min后重置该时间。
Pod重启策略与控制方式:
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行;
- Job:OnFailure或Never,确保容器执行完后不会再运行;
- Kubelet:在Pod失效时自动重启它,不论将RestartPolicy设置为什么值,也不会对Pod进行健康检查。
24.Pod健康检查和服务可用性检查
Kubernetes对Pod的健康检查可以通过两类探针来检查:LivenessProbe和ReadinessProbe。
LivenessProbe探针:用于判断容器是否存活(Running状态),如果LivenessProbe探测到容器不健康,则kubelet将杀死该容器,并根据容器的重启策略进行相应的处理。如果一个容器不包括LivenessProbe探针,那么kubelet则会认为该容器的LivenessProbe探针返回的结果永远是success。
ReadinessProbe探针:用于判断容器是否可用(Ready状态),达到Ready状态的Pod才可以接收请求。对于背Service管理的Pod,Service与Pod Endpoint的关联关系也将基于Pod受否Reday进行设置。如果在运行过程中Ready变为Flase,则系统自动将其从Service的后端Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加入到Endpoint列表。这样可以保证客户端再访问Service时不会被转发到不可用的Pod实例上。
LivenessProbe和ReadinessProbe均可配置以下三种实现方式:
ExecAction:在容器内执行一个命令,如果该命令返回值为0,则表明容器健康。
# initialDelaySeconds 启动容器后进行首次健康检查的时间# timeoutSeconds 健康检查发送请求后等待响应的超时时间# 通过执行“cat /tmp/health”命令来判断一个容器运行是否正常。在该Pod运行后,将在创建/tmp/health文件10s后删除该文件,而LivenessProbe健康检查的初始探测时间(initialDelaySeconds)为15s,探测结果是Fail,将导致kubelet杀掉该容器并重启它apiVersion: v1kind: Podmetadata:labels:test: livenessname: liveness-execspec:containers:- name: livenessimage: nginxargs:- /bin/sh- '-c'- echo ok > /temp/healthy; sleep 10; rm -rf /temp/healthy; sleep 600livenessProbe:exec:command:- cat- /temp/healthyinitialDelaySeconds: 15timeoutSeconds: 1
TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康。
apiVersion: v1kind: Podmetadata:labels:test: livenessname: liveness-execspec:containers:- name: livenessimage: nginxports:- containerPort: 80livenessProbe:tcpSocket:port: 80initialDelaySeconds: 15timeoutSeconds: 1
HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTP GET方法,如果响应的状态码大于等于200小于400,认为容器健康。
apiVersion: v1kind: Podmetadata:labels:test: livenessname: liveness-execspec:containers:- name: livenessimage: nginxports:- containerPort: 80livenessProbe:httpGet:path: /_status/heathzport: 80initialDelaySeconds: 15timeoutSeconds: 1
Kubernetes的ReadinessProbe机制可能无法满足某些复杂应用对容器内服务可用状态的判断,1.11版本开始,引入Ready++,1.14版本达到稳定版,称其为Pod Readiness Gates。
25.Deployment全自动调度
# 会创建3个Nginx应用的PodapiVersion: apps/v1kind: Deploymentmetadata:name: nginx-deploymentspec:replicas: 3selector:matchLabels:app: nginx-servertemplate:metadata:labels:app: nginx-serverspec:containers:- name: nginx-deploymentimage: nginxports:- containerPort: 80
26.NodeSelector定向调度
Kubernetes Master上的Scheduler服务(kubernetes-scheduler进程)负责实现Pod的调度,整个调度过程通过执行一系列复杂的算法,最终为每个Pod都计算出一个最佳的目标节点,这一过程是自动完成的,通常我们无法知道Pod最终会调度到哪个节点上。如果需要将Pod调度到指定节点上,可以通过Node标签(Label)和Pod的nodeSelector属性相匹配 。
# 1.通过kubectl label命令给目标Node打上标签kubectl label nodes <node_name> <label_key>=<label_value># 2.在Pod的定义中加上nodeSelector的设置apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-deploymentspec:replicas: 3template:spec:containers:- name: nginximage: nginxports:- containerPort: 80nodeSelector:<label_key>: <label_value>
27.NodeAffinity亲和性调度
NodeAffinity意为Node亲和性的调度策略,适用于替换NodeSelector的全新调度策略。目前有两种节点亲和性表达。
- RequiredDuringSchedulingIgnoredDuringExecution:必须满足指定规则才可以调度Pod到Node上,相当于硬限制。
- PreferredDuringSchedulingIgnoredDuringExecution:强调优先满 足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软 限制。多个优先级规则还可以设置权重(weight)值,以定义执行的先 后顺序。
IgnoredDuringExecution的意思是:如果一个Pod所在的节点在Pod运 行期间标签发生了变更,不再符合该Pod的节点亲和性需求,则系统将 忽略Node上Label的变化,该Pod能继续在该节点运行。
apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-deploymentspec:replicas: 3selector:matchLabels:app: nginx-servertemplate:metadata:labels:app: nginx-serverspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:# kubernetes预定义标签- key: beta.kubernetes.io/arch# 也有NotInoperator: Invalues:- amd64preferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: disk-typeoperator: Invalues:- ssdcontainers:- name: nginx-deploymentimage: nginxports:- containerPort: 80
注意:如果同时定义了nodeSelector和nodeAffinity,那么必须都得到满足;如果nodeAffinity指定了多个nodeSelectorTerms,那么满足其中一个就可以;如果nodeSelectorTerms种有多个matchExpressions,则一个点满足matchExpressions才能运行该Pod。
28.PodAffinity亲和与互斥调度策略
PodAffinity根据节点上正在运行的Pod的标签而不是节点的标签进行判断和调度,要求对节点和Pod两个条件进行匹配。
例如:如果在具有标签X的Node上运行了一个或多个符合条件Y的Pod,那么Pod应该运行在这个Node上;
这里X指的是一个集群中的节点、机架、区域等概念,通过Kubernetes内置节点标签中的key来进行声明,这个key的名字为topologyKey,意为表达节点所属的topology范围。与节点不同的是,Pod是属于某个命名空间的,所以条件Y表达的是一个或者多个命名空间中的一个Label Selecotr。
和节点亲和性相同,Pod亲和与互斥的条件设置也是requiredDuringSchedulingIgnoredDuringExecution和
preferredDuringSchedulingIgnoredDuringExecution。Pod的亲和性被定义于PodSpec的affinity字段下的podAffinity子字段中。Pod间的互斥性则被定义于同一层次的podAntiAffinity子字段中。
# 1.创建一个名为pod-flag的Pod,带有标签security=S1和app=nginx,使用该Pod作为其他Pod亲和于互斥的目标PodapiVersion: v1kind: Podmetadata:name: pod-flaglabels:security: S1app: nginxspec:containers:- name: nginximage: nginx# 2.创建第二个pod来说明pod的亲和性,亲和标签为security=S1,对应目标pod,创建后与pod-flag在同一nodeapiVersion: v1kind: Podmetadata:name: pod-affinityspec:affinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: securityoperator: Invalues:- S1topologyKey: kubernetes.io/hostnamecontainers:- name: with-pod-affinityimage: nginx# 3.pod的互斥性调度,该pod不与目标pod运行在同一节点# 要求该pod与security=S1的pod为同一个zone,但不与app=nginx的pod为同一个nodeapiVersion: v1kind: Podmetadata:name: anti-affinityspec:affinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: securityoperator: Invalues:- S1topologyKey: failure-domain.beta.kubernetes.io/zonepodAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- nginxtopologyKey: kubernetes.io/hostnamecontainers:- name: with-pod-affinityimage: nginx
29.Taints和Tolerations(污点和容忍)
Taint需要和Toleration配合使用,让Pod避开那些不适合的Node。在Node上设置一个或多个Taint之后,除非Pod明确声明能够容忍这些污点,否则无法在这些Node上运行。Toleration是Pod的属性,让Pod能够运行在标注了Taint的Node上。
# 污点值:NoSchedule(一定不被调度) PreferNoSchedule(尽量不被调度) NoExecute(不被调度,并且驱除已有pod)# 设置污点,key、value随便写kubectl taint node <node_name> <key>=<value>:污点值# 删除污点kubectl taint node <node_name> <key>:NoSchedule- # 这里的key可以不用指定valuekubectl taint node <node_name> <key>:NoExecute-kubectl taint node <node_name> <key>-kubectl taint node <node_name> <key>:NoSchedule-
这个设置为node加上了一个Taint,该Taint的键为key,值为value,Taint的效果是NoSchedule。意味着除非Pod明确声明可以容忍该Taint,否则不会被调度到该node上。
# 设置污点容忍,该Pod可以运行在污点为<key>的node上apiVersion: v1kind: Podmetadata:name: taint-podspec:tolerations:- key: <key>operator: Equalvalue: value# operator: Exists 效果与以上相同effect: NoSchedulecontainers:- name: nginximage: nginx
Pod的Toleration声明中的key和effect需要与Taint的设置保持一致,并且满足以下条件之一:
- operator的值是Exists(无需指定value)。
- operator的值是Equal并且value相等。
如果不指定operator,则默认为Equal,另外,有如下两个特例:
- 空的key配合Exists操作符能够匹配所有的键和值。
- 空的effect匹配所有的effect。
effect取值:
- NoSchedule:Pod没有声明容忍该taint,则调度器不会把该Pod调度到这一节点上。
- PreferNoSchedult:调度器会尝试不把该Pod调度到这个节点上(不强制)。
- NoExecute:如果该Pod已经在该节点运行,则会被驱逐;如果没有,则调度器不会把该Pod调度到这一节点(可以设置驱逐时间,eg:tolerationSeconds=5000,在5s钟后被驱逐)。
30.Pod Priority Preemption:Pod优先级调度
当发生资源不足的情况时,系统可以选择释放一些不重要的负载(优先级最低的),保障最重要的负载能够有足够的资源稳定运行。
# 1.定义一个名为high-priority的优先级类别,优先级为1000000,数字越大,优先级越大,超过一亿的数字被系统保留,用于指派给系统组件apiVersion: scheduling.k8s.io/v1kind: PriorityClassmetadata:name: high-priorityvalue: 1000000globalDefault: falsedescription: This priority class should be used for XYZ service pods only# 2.在Pod上引用上述Pod优先级类别,priorityClassName: high-priorityapiVersion: v1kind: Podmetadata:name: nginxspec:containers:- name: nginximage: nginximagePullPolicy: IfNotPresentpriorityClassName: high-priority
31.DaemonSet:在每个Node上都调度一个Pod
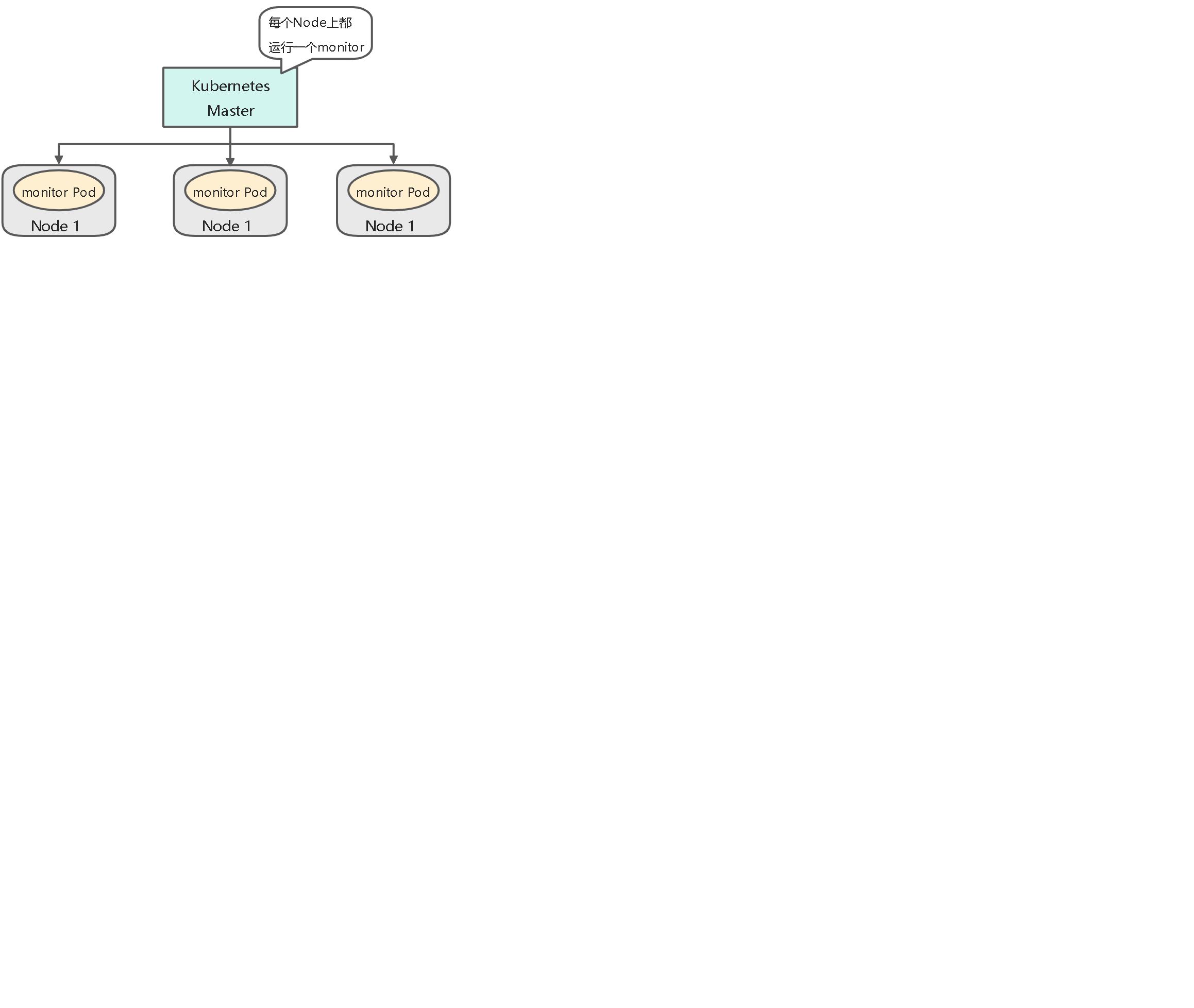
DaemonSet的Pod调度策略与RC类似,除了使用系统内置的算法在每个Node上进行调度,也可以在Pod的定义中使用NodeSelector或NodeAffinity来指定满足条件的Node范围进行调度。
# 每个Node上都启动一个fluentd容器,其中挂载了物理机的两个目录/var/log和/var/lib/docker/containersapiVersion: apps/v1kind: DaemonSetmetadata:name: fluentd-cloud-loggingnamespace: kube-systemlabels:k8s-app: fluentd-cloud-loggingspec:selector:matchLabels:k8s-app: fluentd-cloud-loggingtemplate:metadata:namespace: kube-systemlabels:k8s-app: fluentd-cloud-loggingspec:containers:- name: fluentd-cloud-loggingimage: ist0ne/fluentd-elasticsearchimagePullPolicy: IfNotPresentresources:limits:cpu: 100mmemory: 200Mienv:- name: FLUENTD_ARGSvalue: '-q'volumeMounts:- name: varlogmountPath: /var/logreadOnly: false- name: containersmountPath: /var/lib/docker/containersreadOnly: falsevolumes:- name: containershostPath:path: /var/lib/docker/containers- name: varloghostPath:path: /var/log
32.Init Container:初始化容器
用于在启动应用容器之前启动一个或多个初始化容器,完成应用容器所需的预置条件。init container与应用容器在本质上是一样的,但它们是仅运行一次就结束的任务。根据Pod的重启策略(RestarPolicy),当init container执行失败,而且设置了RestartPolicy=Never时,Pod将会启动失败;而设置RestartPolicy=Always时,Pod将会被系统重启。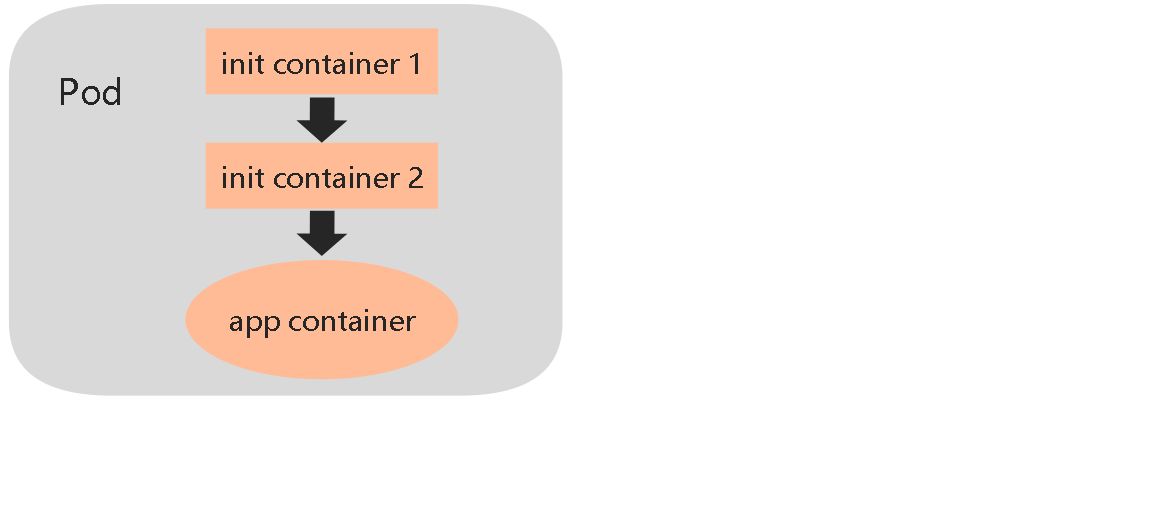
# initContainersapiVersion: v1kind: Podmetadata:name: nginx-podspec:initContainers:- name: installimage: busyboxcontainers:- name: nginximage: nginxports:- containerPort: 80
33.Deployment的升级与回滚
# 修改镜像名称kubectl set image deployment <deployment_name> <container_name>=<image_name>:<version># 查看修改状态kubectl rollout status deployment <deployment_name># 查看历史版本kubectl rollout history deployment <deployment_name># 回滚到上个版本kubectl rollout undo deployment <deployment_name># 回滚到指定版本(3是查看历史版本里面的版本号)kubectl rollout undo deployment <deployment_name> --to-revision=3
34.暂停和恢复Deployment的部署操作,以完成复杂的修改
对于一次复杂的Deployment配置修改,为了避免频繁触发Deployment的更新操作,可以先暂停Deployment的更新操作,然后进行配置修改,再恢复Deployment,一次性触发完整的更新操作,就可以避免不必要的Deployment更新操作。
# 暂停deployment更新操作kubectl rollout pause deployment <deployment_name># 修改deployment镜像信息kubectl set image deployment <deployment_name> <container_name>=<image_name>:<version># 查看修改deployment的历史记录,发现并没有触发新的deployment部署操作kubectl rollout history deploy <deploy_name># 再次更新容器资源限制kubectl set resources deploy <deploy_name> -c=<container_name> --limits=cpu=200m,memory=512Mi# 最后,恢复这个deployment的部署操作kubectl rollout resume deploy <deploy_name>
注意:暂停状态的Deployment无法回滚!
35.使用kubectl rolling-update命令完成RC的滚动升级
kubectl rolling-update <rc_name> --image=<image_name>:<version>
36.Pod手动扩容机制
# 将pod数量维持在10个kubectl scale deploy <deploy_name> --replicas 10
37.Pod自动扩容机制
Kubernetes从1.1版本开始,新增了名为Horizontal Pod AutoScaler(HPA)的控制器,用于实现基于CPU使用率进行自动Pod扩缩容的功能。HPA控制器基于Master的kube-controller-manager服务启动参数—horizontal-pod-autoscaler-sync-period定义探测周期(默认为15s),周期性地检测目标Pod的资源性能指标,并与HPA资源对象中的扩缩容条件进行对比,在满足条件时对Pod副本数量进行调整。
HPA工作原理:
Kubernetes中的某个Metrics Server(Heapster或自定义Metrics Server)持续采集所有Pod副本的指标数据。HPA控制器通过Metrics Server的API(Heapster的API或聚合API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标Pod副本数量。当目标Pod数量与当前副本数量不同时,HPA控制器就向Pod的副本控制器(Deployment、RC或ReplicaSet)发起scale操作,调整Pod的副本数量,完成扩缩容操作。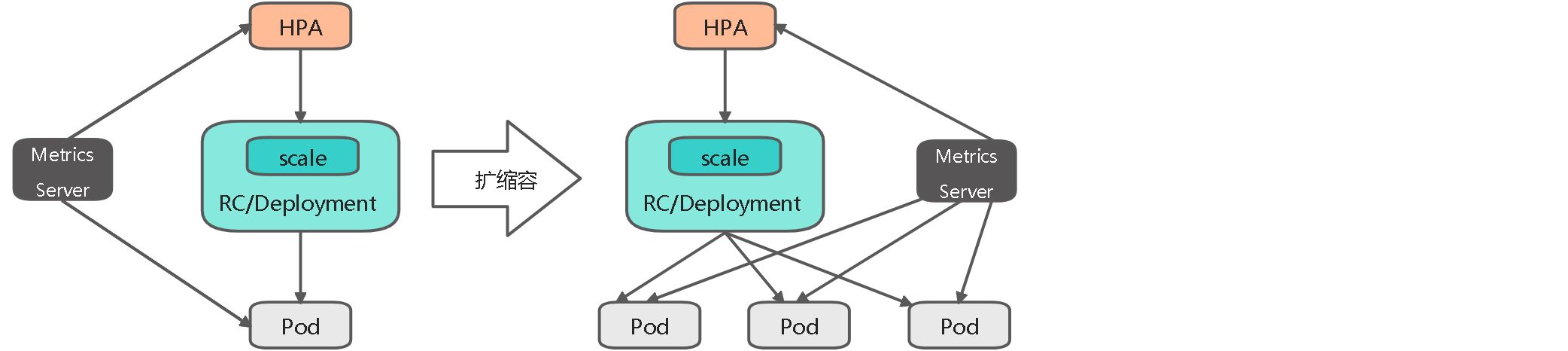
HPA配置详解:
Kubernetes将HPA资源对象提供给用户来定义扩缩容的规则。
HPA资源对象处于Kubernetes的API组“autoscaling”中,目前包括v1和v2两个版本。其中autoscaling/v1仅支持CPU使用率的自动扩缩容,autoscaling/v2则用于支持基于任意指标的自动化扩缩容配置,包括基于资源使用率、Pod指标、其他指标等类型的指标数据。
(1)基于autoscaling/v1版本的HPA配置,仅可设置CPU使用率:
apiVersion: autoscaling/v1kind: HorizontalPodAutoscalermetadata:name: php-apachespec:# 目标作用对象,可以是Deployment、ReplicationController或ReplicaSetscaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apache# Pod副本数量的最小值和最大值minReplicas: 1maxReplicas: 10# 期望每个Pod的CPU使用率都为50%,该使用率基于Pod设置的CPU Request值进行计算targetCPUUtilizationPercentage: 50
注意:使用autoscaling/v1版本的HPA,需预先安装Heapster组件或Metrics Server,用于采集CPU使用率。
(2)基于autoscaling/v2beta2的HPA配置:
apiVersion: autoscaling/v2beta2kind: HorizontalPodAutoscalermetadata:name: php-apachespec:# 目标作用对象,可以是Deployment、ReplicationController或ReplicaSetscaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apache# Pod副本数量的最小值和最大值minReplicas: 1maxReplicas: 10# 目标指标。在metrics中通过参数type定义指标类型;通过参数target定义响应的指标目标值,系统将在指标数据达到目标值触发扩缩容操作metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50
可以将metrics中的type(指标类型)设置为以下三种:
- Resource:基于资源的指标值,可以设置的资源为CPU和内存。
- Pods:基于Pod的指标,系统将对全部Pod副本的指标值进行平均值计算。
- Object:基于某种资源对象(如Ingress)的指标或应用系统的任意自定义指标。
Resource类型的指标可以设置CPU和内存。对于CPU使用率,在target参数中设置averageutilization定义目标平均CPU使用率。对于内存资源,在target参数中设置AverageValue定义目标平均内存使用值。指标数据可以通过API“metrics.k8s.io”进行查询,要求预先启动Metrics Server服务。
Pods类型和Object类型都属于自定义指标类型,指标的数据通常需要搭建自定义Metrics Server和监控工具进行采集和处理。指标数据可以通过API“custom.metrics.k8s.io”进行查询,要求预先自定义Metrics Server服务。
类型为Pods的指标数据来源于Pod对象本身,其target类型只能使用AverageValue。
# 其中Pod的指标名为packets-per-second,在目标指标平均值为1000时触发扩缩容操作metircs:- type: Podspods:metric:name: packets-per-secondtarget:type: AverageValueaverageValue: 1k
类型为Object的指标数据来源于其他资源对象或任意自定义指标,其target指标类型可以使用Value或Average Value(根据副本数计算平均平均值)进行设置。
# 例1:设置指标的名称为requests-per-second,其值来源于Ingress“main-route”,将目标值设置为2000,即在Ingress的每秒请求达到2000时触发扩缩容操作。metircs:- type: Objectobject:metric:name: requests-per-seconddescribedObject:apiVersion: extensions/v1Beta1kind: Ingressname: main-routetarget:type: valuevalue: 2k# 例2:设置指标的名称为http_requests,并且在该资源对象具有标签“verb=GET”,在指标平均值达到500时触发扩缩容操作。metircs:- type: Objectobject:metric:name: http_requestsselector: verb=GETtarget:type: AverageValueaverageValue: 500
在同一个HorizontalPodAutoscaler资源对象中定义多个类型的指标,系统将针对每种类型的指标都计算副本的目标数量,以最大值为准进行扩缩容准备。
apiVersion: autoscaling/v2beta2kind: HorizontalPodAutoscalermetadata:name: php-apachenamespace: defaultspec:# HPA的伸缩对象描述,HPA会动态修改该对象的pod数量scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apache# HPA的最小pod数量和最大pod数量minReplicas: 1maxReplicas: 10# 监控的指标数组,支持多种类型的指标共存metrics:# Object类型的指标- type: Objectobject:metric:# 指标名称name: requests-per-second# 监控指标的对象描述,指标数据来源于该对象describedObject:apiVersion: networking.k8s.io/v1beta1kind: Ingressname: main-route# Value类型的目标值,Object类型的指标只支持Value和AverageValue类型的目标值target:type: Valuevalue: 10k# Resource类型的指标- type: Resourceresource:name: cpu# Utilization类型的目标值,Resource类型的指标只支持Utilization和AverageValue类型的目标值target:type: UtilizationaverageUtilization: 50# Pods类型的指标- type: Podspods:metric:name: packets-per-second# AverageValue类型的目标值,Pods指标类型下只支持AverageValue类型的目标值target:type: AverageValueaverageValue: 1k# External类型的指标(用于对外部系统指标的支持)- type: Externalexternal:metric:name: queue_messages_ready# 该字段与第三方的指标标签相关联selector:matchLabels:env: stageapp: myapp# External指标类型下只支持Value和AverageValue类型的目标值target:type: AverageValueaverageValue: 30
38.使用StatefulSet搭建MongoDB集群

若有收获,就点个赞吧
0 人点赞
