写在之前
在上篇文章《go 基础之 map - 写在前面(一)》介绍了 map 的数据结构,本篇会详细介绍 map 的增和改的代码实现,由于增和改的实现基本上差不多,所以就纳到一起分析了。如果想详细查看源码的注释,可以查看我的GitHub, 欢迎批评指正。我的打算是把一些常用的数据结构都分析一遍,如果有志同道合的人,可以联系我。
环境说明
我的具体调试环境在《go 基础之 map - 写在前面(一)》已经说明的非常仔细了,现在只讲我分析增和改的调试代码。
package mainimport ("fmt""strconv")func main() {m1 := make(map[string]string, 9)fmt.Println(m1)for i := 0; i < 20; i++ {str := strconv.Itoa(i)m1[str] = str}}
老规矩编译一波,看看第 9 行的申明到底干了啥?
go tool compile -N -l -S main.go > main.txt
编译结果有点多,我只列举重点代码:
"".main STEXT size=394 args=0x0 locals=0x980x0000 00000 (main.go:8) TEXT "".main(SB), ABIInternal, $152-0....0x0036 00054 (main.go:9) LEAQ type.map[string]string(SB), AX0x003d 00061 (main.go:9) PCDATA $0, $00x003d 00061 (main.go:9) MOVQ AX, (SP)0x0041 00065 (main.go:9) MOVQ $9, 8(SP)0x004a 00074 (main.go:9) MOVQ $0, 16(SP)0x0053 00083 (main.go:9) CALL runtime.makemap(SB)....0x0107 00263 (main.go:13) PCDATA $0, $50x0107 00263 (main.go:13) LEAQ type.map[string]string(SB), DX0x010e 00270 (main.go:13) PCDATA $0, $40x010e 00270 (main.go:13) MOVQ DX, (SP)0x0112 00274 (main.go:13) PCDATA $0, $60x0112 00274 (main.go:13) MOVQ "".m1+56(SP), BX0x0117 00279 (main.go:13) PCDATA $0, $40x0117 00279 (main.go:13) MOVQ BX, 8(SP)0x011c 00284 (main.go:13) PCDATA $0, $00x011c 00284 (main.go:13) MOVQ CX, 16(SP)0x0121 00289 (main.go:13) MOVQ AX, 24(SP)0x0126 00294 (main.go:13) CALL runtime.mapassign_faststr(SB)....
- 第 9 行调用了
runtime.makemap方法做一些初始化操作,我把 map 的初始容量设为大于 8 底层才会走该方法,否则会调用runtime.makemap_small 方法。 - 第 22 行调用了
runtime.mapassign_faststr 方法,该方法对应main.go第 13 行的赋值方法m1[str] = str。
我们找到了方法,在后面就可以在$go_sdk_path/src/runtime/map.go和$go_sdk_path/src/runtime/map_faststr.go
找到方法,然后断点调试即可。
makemap_small 和 makemap 的区别
makemap_small的代码如下:
func makemap_small() *hmap {h := new(hmap)h.hash0 = fastrand()return h}
该代码的实现十分简单,就设置了一个 hash 种子,其他的例如申通桶内存的操作只有在真正赋值数据的时候才会创建桶。该方法在什么情况会被调用呢?如注释说说 “hint is known to be at most bucketCnt at compile time and the map needs to be allocated on the heap”,bucketCnt 就是 8 个,所以上面我的示例代码为何要设初始容量为 9 的原因就在这里。
我就直接略过这种情况,因为在实际应用场景下还是要指定容量, 避免后面因为频繁扩容造成性能损失,makemap的代码如下:
func makemap(t *maptype, hint int, h *hmap) *hmap {mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)if overflow || mem > maxAlloc {hint = 0}if h == nil {h = new(hmap)}h.hash0 = fastrand()B := uint8(0)for overLoadFactor(hint, B) {B++}h.B = Bif h.B != 0 {var nextOverflow *bmaph.buckets, nextOverflow = makeBucketArray(t, h.B, nil)if nextOverflow != nil {h.extra = new(mapextra)h.extra.nextOverflow = nextOverflow}}return h}
看程序注释大概明白该代码的作用就是得到 B 值和申请桶,overLoadFactor方法是用了 6.5 的扩容因子去计算出最大的 B 值,保证你申请的容量 count 要大于 (1>> B) * 6.5, 这个扩容因子想必大家都不陌生,在 java 中是 0.75,为什么在 go 中是 0.65 呢?在runtime/map.go开头处有测试数据,综合考虑来说选择了 6.5。大家可能注意到maptype用来申请桶的内存块了,下面看看maptype的代码, 也有助于理解 map 的结构:
type maptype struct {typ _typekey *_typeelem *_typebucket *_typehasher func(unsafe.Pointer, uintptr) uintptrkeysize uint8elemsize uint8bucketsize uint16flags uint32}
makemap方法里面math.MulUintptr(uintptr(hint), t.bucket.size)用到了 bucket 的 size,这里这个 size 和maptype的 bucketsize 一模一样都是 272(《go 基础之 map - 写在前面(一)》有介绍为什么是 272),所以就能计算出需要分配的内存。仔细分析makemap的字段,可以发现定义了 map 的基本数据结构,后面代码用来申请桶的内存块的时候都使用了这个数据结构。
makemap第 36 行代码调用了方法makeBucketArray方法来申请内存,我们简单看看它里面的细节:
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {base := bucketShift(b)nbuckets := baseif b >= 4 {nbuckets += bucketShift(b - 4)sz := t.bucket.size * nbucketsup := roundupsize(sz)if up != sz {nbuckets = up / t.bucket.size}}if dirtyalloc == nil {buckets = newarray(t.bucket, int(nbuckets))b0 := (*dmap)(add(buckets, uintptr(0)*uintptr(t.bucketsize)))println(b0.debugOverflows)} else {buckets = dirtyallocsize := t.bucket.size * nbucketsif t.bucket.ptrdata != 0 {memclrHasPointers(buckets, size)} else {memclrNoHeapPointers(buckets, size)}}if base != nbuckets {nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))last.setoverflow(t, (*bmap)(buckets))}return buckets, nextOverflow}
注意 12 行处有个优化点,当 B 小于 4 的时候,也就是初始申请 map 的容量的时候的 count <(1>> B) * 6.5 的时候,很大的概率其实不会使用逸出桶。当 B 大于 4 的时候,程序就预估出一个逸出桶的个数,在 26 行处就一并申请总的桶的内存块。第 27 行的代码是在源码中没有的,我只是用来调试代码所用,这个在《go 基础之 map - 写在前面(一)》有介绍这个小技巧。在第 49 行就通过 bucketsize 计算出逸出桶的位置,并且在 51 到 53 行有个技巧,给最后一个桶的溢出桶指针设置了桶的起始地址,这个在后面系列的博客会介绍到为何这么使用。
ok,现在 map 的数据如下:
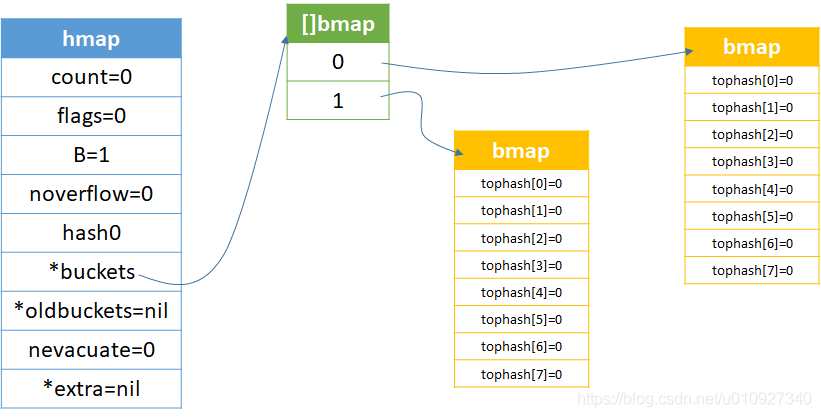
只有 2 个桶,而且每个桶的 tophash 值都是默认值 0,由于此时 key 和 value 都为空,故没有展示出来。extra没有值是因为 B 小 4 没有溢出桶导致的。
添加元素(没触发扩容的情况)
m1[str] = str我上面分析了是对应的map_faststr.go里面的mapassign_faststr方法。第一次添加的 key 和 value 都是 string 类型。
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer {if h.flags&hashWriting != 0 {throw("concurrent map writes")}key := stringStructOf(&s)hash := t.hasher(noescape(unsafe.Pointer(&s)), uintptr(h.hash0))h.flags ^= hashWritingif h.buckets == nil {h.buckets = newobject(t.bucket)}again:mask := bucketMask(h.B)bucket := hash & maskif h.growing() {growWork_faststr(t, h, bucket)}b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))top := tophash(hash)var insertb *bmapvar inserti uintptrvar insertk unsafe.Pointerbucketloop:for {for i := uintptr(0); i < bucketCnt; i++ {if b.tophash[i] != top {if isEmpty(b.tophash[i]) && insertb == nil {insertb = binserti = i}if b.tophash[i] == emptyRest {break bucketloop}continue}k := (*stringStruct)(add(unsafe.Pointer(b), dataOffset+i*2*sys.PtrSize))if k.len != key.len {continue}if k.str != key.str && !memequal(k.str, key.str, uintptr(key.len)) {continue}inserti = iinsertb = bgoto done}ovf := b.overflow(t)if ovf == nil {break}b = ovf}if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again}if insertb == nil {insertb = h.newoverflow(t, b)inserti = 0}insertb.tophash[inserti&(bucketCnt-1)] = topinsertk = add(unsafe.Pointer(insertb), dataOffset+inserti*2*sys.PtrSize)*((*stringStruct)(insertk)) = *keyh.count++done:elem := add(unsafe.Pointer(insertb), dataOffset+bucketCnt*2*sys.PtrSize+inserti*uintptr(t.elemsize))if h.flags&hashWriting == 0 {throw("concurrent map writes")}h.flags &^= hashWritingreturn elem}
- 2 到 21 行是我的调试代码,打印下桶里面有哪些键值对。
- 23 行和 32 行都是对写标志位的操作,可见,map 不支持多个 goroutine 写操作。
- 26 行把 key 转成
stringStructOf类型,后面方便用stringStructOf里面的len和具体的 string 的字符数组值str,这也是个优化点,少了后面通过len(str)的计算,提高效率。 - 28 行
noescape防止 key 被逃逸分析,计算出 key 的 hash。 - 38 行到 54 行的
again的代码块主要计算式 key 应该落在哪个 buket,为什么作为一个代码块操作呢?是因为在触发扩容的时候,会重新计算落到哪个 bucket。40 行计算出 bucket 掩码,这里二进制值是10,41 行和 hash 做与运算,得到的值就是要把 key 应该存的桶号。这里也是个优化操作,通过二进制运算提高效率。第 50 行计算得到的值正是放到 bucket 里面的前 8 个 hash 槽里面。先忽略掉 251 行的扩容情况。 - 57 行到 123 行的
bucketloop代码块主要作用是找到 key 和 value 存取的位置,并把 key 放到 bucket 所在的内存位置。里面有 2 个 for 循环,外循环轮询 bucket 以及 bucket 的逸出桶,里循环轮询桶的 8 个 tophash 槽,如果找到空的 tophash 槽 (66 行和 67 行) 就执行到done语句块。71 行之后就是 key 的高 8 位 hash 码相等了,那么就有可能 bucket 已经存在了这个 key,所以就先比 key 的长度,再比较内存。102~105 行先忽略。107-110 会申请一个逸出桶然后把 key 存到逸出桶的第一个位置。113 行把 tophash 值放到 hash 槽里面。 - 至于第 66 行为什么要比较 hash 槽等于
emptyRest才算找到了呢?这个在后面的系列会介绍到。
done代码块的代码比较清晰,就是得到 value 放的内存位置,并且把状态设置为写完成。
done:elem := add(unsafe.Pointer(insertb), dataOffset+bucketCnt*2*sys.PtrSize+inserti*uintptr(t.elemsize))if h.flags&hashWriting == 0 {throw("concurrent map writes")}h.flags &^= hashWritingreturn elem}
现在的 map 的内存结构是什么样的呢?
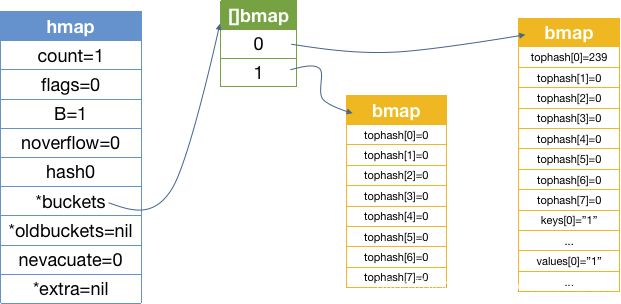
一直到在发生扩容前的 map 内存结构是怎样的呢
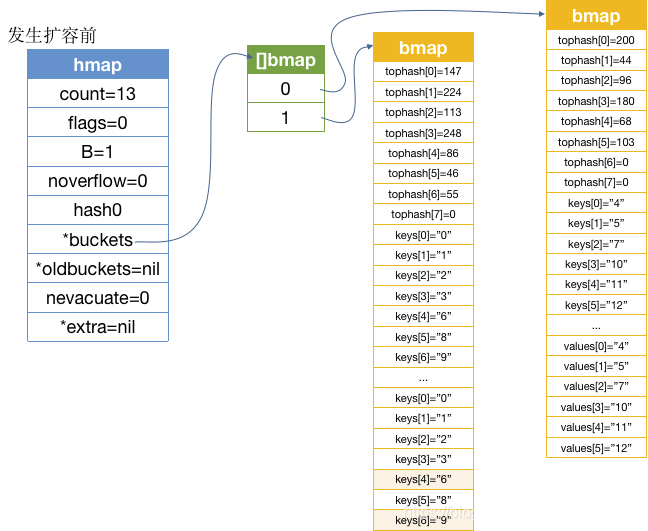
为啥明明 2 个桶都没填充完就要马上扩容了呢?这是因为扩容因子作用了:
func overLoadFactor(count int, B uint8) bool {return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)}
count此时值是 13,13 * (2 / 2) = 13,但是在下次的 13 的 key 放进来的时候就会发生扩容了。
发生扩容
上面说到 key 为 13 的时候发生扩容,下面具体分析如何扩容的:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {d := (*dmap)(unsafe.Pointer(uintptr(h.buckets)))bucketD := uintptr(0)for bucketD < bucketShift(h.B)+3 {flag := falsefor i, debugKey := range d.debugKeys {if debugKey == "" {continue}println(d.tophash[i])if flag == false {print("bucket:")println(bucketD)}print("key:")println(debugKey)flag = true}bucketD++d = (*dmap)(unsafe.Pointer(uintptr(h.buckets) + bucketD*uintptr(t.bucketsize)))}println()hashGrow(t, h)goto again}
在上面的 2 层 for 循环里面虽然找到了 bucket 还有剩余位置,但是第 7 行的overLoadFactor(h.count+1, h.B)计算出要发生扩容。8~28 行是我的调试代码,用来打印出此时 map 的内存结构。hashGrow会做具体的扩容操作,然后执行again从新计算落入哪个 bucket。
看看hashGrow干了嘛:
func hashGrow(t *maptype, h *hmap) {bigger := uint8(1)if !overLoadFactor(h.count+1, h.B) {bigger = 0h.flags |= sameSizeGrow}oldbuckets := h.bucketsnewbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)flags := h.flags &^ (iterator | oldIterator)if h.flags&iterator != 0 {flags |= oldIterator}h.B += biggerh.flags = flagsh.oldbuckets = oldbucketsh.buckets = newbucketsh.nevacuate = 0h.noverflow = 0if h.extra != nil && h.extra.overflow != nil {if h.extra.oldoverflow != nil {throw("oldoverflow is not nil")}h.extra.oldoverflow = h.extra.overflowh.extra.overflow = nil}if nextOverflow != nil {if h.extra == nil {h.extra = new(mapextra)}h.extra.nextOverflow = nextOverflow}}
- 当不是因为逸出桶太多导致的扩容,那么就扩容 2 倍,桶是原来的桶的 2 倍。
- 第 13 行会申请内存,这里没有
nextOverflow,下面会分析makeBucketArray方法。 - 由于 hmap 的 extra 是 nil,所以后面的代码基本忽略。
- 将 hmap 的 oldbuckets 的指针指向原来的 buckets,将 hmap 的 buckets 指针指向新申请的桶。oldbuckets 是用于将老的桶里面的数据逐步拷贝到新申请的桶里面。
我画一下此时的 map 的内存结构, 方便对比上面没扩容时候的内存结构:
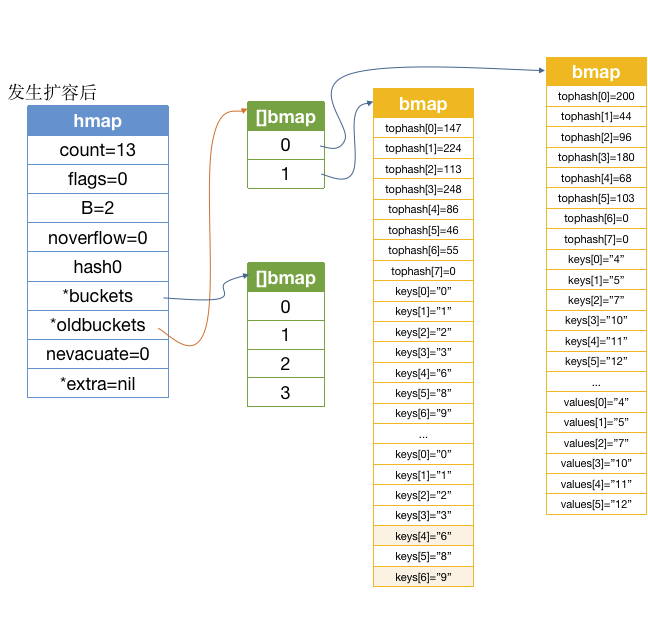
然后会走到agian代码块里面的这段代码:
if h.growing() {growWork_faststr(t, h, bucket)}
growing方法就是判断是否有 oldbuckets,此时会走向growWork_faststr方法去复制数据到新桶里面。此时bucket的值是 0-3 其中的一个值,此时我调试的值是 0,该值就是该 key 即将落入新申请桶的编号。
func growWork_faststr(t *maptype, h *hmap, bucket uintptr) {mask := h.oldbucketmask()oldbucket := bucket & maskevacuate_faststr(t, h, oldbucket)if h.growing() {evacuate_faststr(t, h, h.nevacuate)}}
第 6 行的与操作肯定得到的桶号是在老桶的序号内,即将要迁移的就是该桶。evacuate_faststr就是迁移逻辑。12~15 行意思就是如果还有待迁移的桶,那么就继续迁移。
接下来就到了扩容里面真正重点的代码了:
func evacuate_faststr(t *maptype, h *hmap, oldbucket uintptr) {b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))newbit := h.noldbuckets()if !evacuated(b) {var xy [2]evacDstx := &xy[0]x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))x.k = add(unsafe.Pointer(x.b), dataOffset)x.e = add(x.k, bucketCnt*2*sys.PtrSize)if !h.sameSizeGrow() {y := &xy[1]y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))y.k = add(unsafe.Pointer(y.b), dataOffset)y.e = add(y.k, bucketCnt*2*sys.PtrSize)}for ; b != nil; b = b.overflow(t) {k := add(unsafe.Pointer(b), dataOffset)e := add(k, bucketCnt*2*sys.PtrSize)for i := 0; i < bucketCnt; i, k, e = i+1, add(k, 2*sys.PtrSize), add(e, uintptr(t.elemsize)) {top := b.tophash[i]if isEmpty(top) {b.tophash[i] = evacuatedEmptycontinue}if top < minTopHash {throw("bad map state")}var useY uint8if !h.sameSizeGrow() {hash := t.hasher(k, uintptr(h.hash0))if hash&newbit != 0 {useY = 1}}b.tophash[i] = evacuatedX + useYdst := &xy[useY]if dst.i == bucketCnt {dst.b = h.newoverflow(t, dst.b)dst.i = 0dst.k = add(unsafe.Pointer(dst.b), dataOffset)dst.e = add(dst.k, bucketCnt*2*sys.PtrSize)}dst.b.tophash[dst.i&(bucketCnt-1)] = top*(*string)(dst.k) = *(*string)(k)typedmemmove(t.elem, dst.e, e)dst.i++dst.k = add(dst.k, 2*sys.PtrSize)dst.e = add(dst.e, uintptr(t.elemsize))}}if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))ptr := add(b, dataOffset)n := uintptr(t.bucketsize) - dataOffsetmemclrHasPointers(ptr, n)}}if oldbucket == h.nevacuate {advanceEvacuationMark(h, t, newbit)}}
- 第 3 行得到待迁移的老桶地址。
- 第 5 行得到偏移的桶数,该值等于老桶数。这样的用意是把老桶的数据按照 hash 分散在新桶的里面。画图说明下:
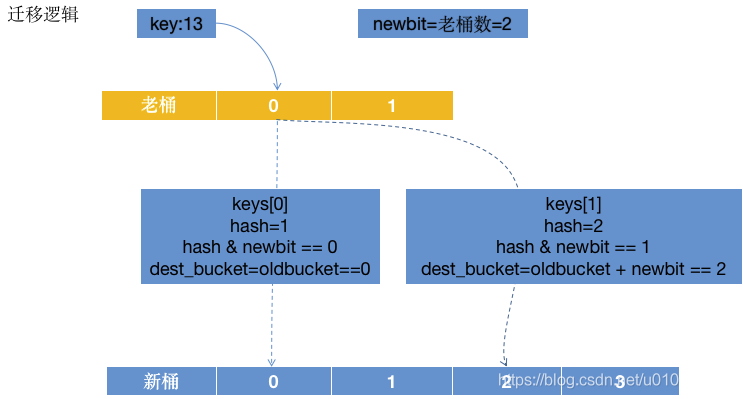
8~95 行的意思和上图差不多一致,有兴趣对照我的注释看一看。 - 96~109 行会去释放掉刚刚迁移完成的老桶,需要注意下,当有迭代老桶的时候就先不释放数据,当 key 和 value 都不是指针的时候也先不释放,到后面会解释到何时释放。
- 580~586 行意思就是去标记释放了多少个桶被释放了,此时
oldbucket和h.nevacuate都是 0,所以会进去标记。下面进去看看里面是怎么标记的。
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {h.nevacuate++stop := h.nevacuate + 1024if stop > newbit {stop = newbit}for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {h.nevacuate++}if h.nevacuate == newbit {h.oldbuckets = nilif h.extra != nil {h.extra.oldoverflow = nil}h.flags &^= sameSizeGrow}}
- 3 行就标记已经释放完一个桶了。
- 8 行算是一个权衡,最多往后面查看 1024 个桶,为什么不去查完呢?我理解的是到了 1024 个桶其实已经算一个比较大的 map 了,如果桶的真的很多的话,那就会影响效率,注意我们上面分析的扩容其实一直在添加 13 这个 key 的过程中,如果耗费太多时间的话那就不太好了。而且 go map 的扩容设计就不是想一次性把所有老桶的数据一下搬过来,一次搬不过来,那在下次添加 key 的时候继续搬。
- 12~15 行就是去往后面查看桶是否已经被迁移完,迁移完就 + 1。
- 17 行判断是否已经迁移完成,把
oldbuckets的指针设为 nil - 21~27 行就是判断是有 hmap 的
extral是否为空,这里着重说明下:
①、extral为空,那能说明该 hamp 是没有逸出桶的,这个推断在这里不重要;但是它也能说明extra的overflow和oldoverflow也为空,这个推断就比较重要了。当桶里面的 key 和 value 都不是指针的时候,那么这里overflow和oldoverflow就不会为空了(如果后面有时间的话我再续写一篇博客说明下,因为我该系列的博客都是规划的 map[string][string],key 和 value 都是指针,所以不存在该情况),所以此时会把oldoverflow设为空指针。
②、还记得上面释放桶的时候这段代码吗?t.bucket.ptrdata != 0。当桶的 key 和 value 都不是指针的时候,这里就是 0 了,所以上面就不会释放桶里的数据,但是在这里把oldoverflow设置为 nil 指针,就能释放桶了。 - 再回到上面
growWork_faststr方法,因为还有另外一个桶需要迁移,故会继续执行evacuate_faststr迁移。这次就会判断if h.nevacuate == newbit成功,并且释放 oldbuckets,ok,这里一次添加的 key 的过程当中就迁移完成了。
最后就回到again代码块了,下面就是重新寻桶,寻桶的位置,继续不断的放 key,直到下次发生扩容。很遗憾,我在这里没有打印出所有桶的数据,不能画出此时 map 的内存结构。大致内存结构是老桶的数据会按照 hash 分散到新的 4 个桶里面。
总结
上面分析了 map 的增加 key 的代码,改的代码和增的情况 99.9% 像,详细看我的分析或者我的源码注释,应该都明白了。如果有什么疑惑的地方在下面给我留言我们一起探讨吧。

https://blog.csdn.net/u010927340/article/details/110194541

若有收获,就点个赞吧
0 人点赞
