- How to Train a GAN? Tips and tricks to make GANs work
- 1. Normalize the inputs
- 2: A modified loss function
- 3: Use a spherical Z
- 4: BatchNorm
- 5: Avoid Sparse Gradients: ReLU, MaxPool
- 6: Use Soft and Noisy Labels
- 7: DCGAN / Hybrid Models
- 8: Use stability tricks from RL
- 9: Use the ADAM Optimizer
- 10: Track failures early
- 11: Dont balance loss via statistics (unless you have a good reason to)
- 12: If you have labels, use them
- 13: Add noise to inputs, decay over time
- 14: [notsure] Train discriminator more (sometimes)
- 15: [notsure] Batch Discrimination
- 16: Discrete variables in Conditional GANs
- 17: Use Dropouts in G in both train and test phase
- Authors
原文:https://github.com/soumith/ganhacks#authors
How to Train a GAN? Tips and tricks to make GANs work
While research in Generative Adversarial Networks (GANs) continues to improve the fundamental stability of these models, we use a bunch of tricks to train them and make them stable day to day.
Here are a summary of some of the tricks.
Here’s a link to the authors of this document
If you find a trick that is particularly useful in practice, please open a Pull Request to add it to the document. If we find it to be reasonable and verified, we will merge it in.
1. Normalize the inputs
- normalize the images between -1 and 1
Tanh as the last layer of the generator output
2: A modified loss function
In GAN papers, the loss function to optimize G is min (log 1-D), but in practice folks practically use max log D
because the first formulation has vanishing gradients early on
- Goodfellow et. al (2014)
In practice, works well:
Flip labels when training generator: real = fake, fake = real
3: Use a spherical Z
Dont sample from a Uniform distribution
- Sample from a gaussian distribution
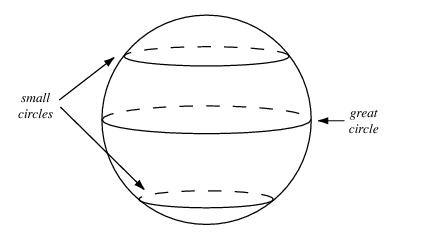
- When doing interpolations, do the interpolation via a great circle, rather than a straight line from point A to point B
Tom White’s Sampling Generative Networks ref code https://github.com/dribnet/plat has more details
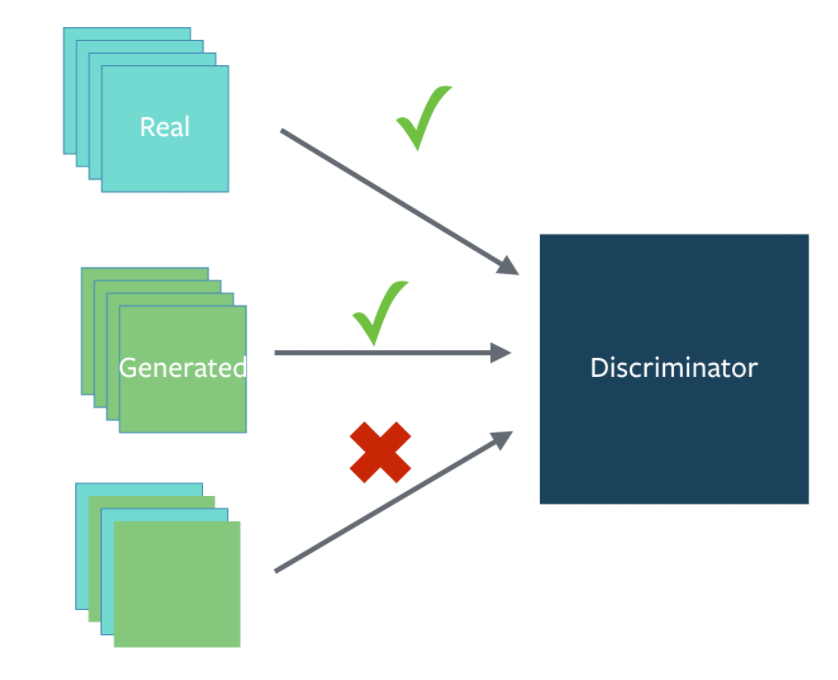
4: BatchNorm
Construct different mini-batches for real and fake, i.e. each mini-batch needs to contain only all real images or all generated images.
- when batchnorm is not an option use instance normalization (for each sample, subtract mean and divide by standard deviation).
5: Avoid Sparse Gradients: ReLU, MaxPool
- the stability of the GAN game suffers if you have sparse gradients
- LeakyReLU = good (in both G and D)
- For Downsampling, use: Average Pooling, Conv2d + stride
For Upsampling, use: PixelShuffle, ConvTranspose2d + stride
- PixelShuffle: https://arxiv.org/abs/1609.05158
6: Use Soft and Noisy Labels
- PixelShuffle: https://arxiv.org/abs/1609.05158
Label Smoothing, i.e. if you have two target labels: Real=1 and Fake=0, then for each incoming sample, if it is real, then replace the label with a random number between 0.7 and 1.2, and if it is a fake sample, replace it with 0.0 and 0.3 (for example).
- Salimans et. al. 2016
make the labels the noisy for the discriminator: occasionally flip the labels when training the discriminator
7: DCGAN / Hybrid Models
Use DCGAN when you can. It works!
if you cant use DCGANs and no model is stable, use a hybrid model : KL + GAN or VAE + GAN
8: Use stability tricks from RL
Experience Replay
- Keep a replay buffer of past generations and occassionally show them
- Keep checkpoints from the past of G and D and occassionaly swap them out for a few iterations
- All stability tricks that work for deep deterministic policy gradients
-
9: Use the ADAM Optimizer
optim.Adam rules!
- See Radford et. al. 2015
Use SGD for discriminator and ADAM for generator
10: Track failures early
D loss goes to 0: failure mode
- check norms of gradients: if they are over 100 things are screwing up
- when things are working, D loss has low variance and goes down over time vs having huge variance and spiking
if loss of generator steadily decreases, then it’s fooling D with garbage (says martin)
11: Dont balance loss via statistics (unless you have a good reason to)
Dont try to find a (number of G / number of D) schedule to uncollapse training
- It’s hard and we’ve all tried it.
- If you do try it, have a principled approach to it, rather than intuition
For example
while lossD > A: train D while lossG > B: train G
12: If you have labels, use them
if you have labels available, training the discriminator to also classify the samples: auxillary GANs
13: Add noise to inputs, decay over time
Add some artificial noise to inputs to D (Arjovsky et. al., Huszar, 2016)
adding gaussian noise to every layer of generator (Zhao et. al. EBGAN)
especially when you have noise
hard to find a schedule of number of D iterations vs G iterations
15: [notsure] Batch Discrimination
-
16: Discrete variables in Conditional GANs
Use an Embedding layer
- Add as additional channels to images
Keep embedding dimensionality low and upsample to match image channel size
17: Use Dropouts in G in both train and test phase
Provide noise in the form of dropout (50%).
- Apply on several layers of our generator at both training and test time
https://arxiv.org/pdf/1611.07004v1.pdf
Authors
Soumith Chintala
- Emily Denton
- Martin Arjovsky
- Michael Mathieu
自己做个笔记:
1。normalize输入,让它在[-1,1]。generater的输出用tanh,也是[-1,1],这就对应起来了。
2。论文里面optimize G是min log(1 - D),但在实际训练的时候可以用 max log(D)
3。对于噪声z,别用均匀(uniform)分布,用高斯分布。
4。可以用instance norm代替 batch norm。还有就是real放一起,generated放一起(感觉这个是废话QAQ)。
5。避免稀疏的gradients:RELU,Maxpool那些。这一点我认为原因是不像做辨别式的网络,判别式的,尽可能提取重要的信息,其实一些对预测影响不大的信息都被忽略掉了。但是GAN不同,是生成式的模型,所以要尽可能的表现出细节方面的内容,所以避免使用稀疏的这些?
- LeakyRelu
- For Downsampling, use: Average Pooling, Conv2d + stride
- For Upsampling, use: PixelShuffle, ConvTranspose2d + stride
6。可以把label为1的(real)变到0.7~1.2,label为0的变到0~0.3。这个可以深入想想。
7。能用DCGAN就用,用不了的话用混合模型,KL+GAN,VAE+GAN之类的。
8。借用RL训练技巧。
- Keep a replay buffer of past generations and occassionally show them
- Keep checkpoints from the past of G and D and occassionaly swap them out for a few iterations
9。用ADAM!或者是D可以用SGD,G用ADAM
10。注意训练过程,尽早发现训练失败,不至于训练好长时间最后才发现,浪费时间。
11。最好别尝试设置一些常量去balance G与D的训练过程。(他们说这个work很难做。我觉得有时间的话其实还是可以试一下的。)
12。如果你对real有相应的label,用label,AC-GAN。加入label信息,可以降低生成的难度,这个应该可以想的通。
13。加噪声?作用是improve生成内容得diversity?
- Add some artificial noise to inputs to D (Arjovsky et. al., Huszar, 2016)
- adding gaussian noise to every layer of generator (Zhao et. al. EBGAN)
14。【not sure】多训练D,特别是加噪声的时候。
15。【not sure】batch D,感觉貌似是和pix2pix中的patchGAN有点像?
16。CGAN,我一直觉得CGAN这种才符合人类学习的思路。原始的GAN就太粗暴了,就好像什么都不知道,然后两个人D与G讨论交流对抗,产生的都是一些前人没有做过的工作,开篇的工作,所以比较困难一些,但是CGAN的话就有了一定的前提,也就是技术积累,所以比较简单一些。有点类似科研中的大牛挖坑,开辟新方向(GAN)。小牛填坑(CGAN)。
17。在G中的几层中用dropout(50%)。这个有一篇论文,还没看。

若有收获,就点个赞吧
0 人点赞
