业务场景
传统的数据库(mysql)很难应对数据操作的“三高”需求,“三高”指的是,high performance(高性能)对数据库并发读写的需求,huge storage (数据量巨大)对海量数据的高效率和访问的需求,high scalability && high availability(高扩展和高可用),而MongoDB可应对“三高”需求。
具体的应用场景如何:
1)社交场景,使用MongoDB用来存储用户信息,以及用户发表的朋友圈信息,通过地理位置搜索附近的人、地点等功能;
2)游戏场景,使用MongoDB存储游戏用户信息,用户的装备,积分等直接以内嵌文档的形式存储,方便查询、高效率存储和访问;
3)物流场景,使用MongoDB存储订单信息,订单状态在运送过程中会不断更新,以及对MongoDB内嵌数组的形式来存储,一次查询就能够将订单所有的变更读取出来;
4)物联网场景,使用MongoDB存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析;
5)视频直播,使用MongBD存储用户信息,点赞互动信息等;
这些应用场景中,数据量操作方面的共同特点是:
(1)数据量大;
(2)写入频繁,读写都很频繁;
(3)价值较低,对事务性要去不高;
对于这样的数据,更适合MongoDB来实现数据的存储。
什么时候选择MongoDB?
在架构选型上,除了上述的三个特点外,如果你还犹豫是否要选择它?如果有1个符合,可用考虑MongoDB,如考虑以下的一些问题:
- 应用不需要事务以及复制join支持;
- 新应用,需求会变更,数据模型无法确定,想快速迭代开发;
- 应用需要2000-3000以上的读写QPS;
- 应用需要TB甚至PB级别数据存储;
- 应用发展迅速,需要能快速水平扩展;
- 应用存储需求的数据不丢失;
- 应用需要99.999%高可用;
- 应用需要大量地理位置查询,文本查询;
对比Mysql,如果使用Mysql呢?相对mysql,可用以更低的成本解决问题
MongoDB简介
MongoDB是一个开源、高性能、无模式的文档数据库,当初设计就是用于简化开发和方便扩展,是NoSQL数据库产品中的一种,是最像关系型数据库的非关系型数据库。
MongoDB中记录的是一个文档,它是一个由字段和值对组成的数据结构,MongoDB文档类似于JSON对象,即一个文档认为就是一个对象。字段的数据类型是字符型,它的值除了使用基本的一些类型外,还可以包含其他文档,普通数组和文档数组。
体系结构
- 数据库database《》数据库database;
- 表table《》Collection;
- 行row《》Document;
- 字段column《》field;
- 索引index《》index;
在链接查询中,mongoDB是内嵌文档,而mysql是关联查询;
数据类型
数组、32位整数、64整数、64位浮点数、null({“x”:null})、undefined、符号、正则表达式、代码(js代码)、二进制数据、最大值和最小值
MongoDB特点
高性能(内嵌)、高可用性(副本集)、高扩展(集群扩容)、丰富的查询支持(CRUD、聚合)、灵活文档模型
基本常用命令
数据库操作
use database(创建db,存储在内存中,当show database的时候未加载到磁盘,当创建集合且存在文档会加载到磁盘持久化)
show database(查询db)
db(展示当前db)
默认库:admin用户权限/local本地集合/config集群分片配置
集合操作
- db.dropDatabase() 删除数据库
- db.createCollection(“my”) 创建集合
- show collections 展示集合
-
文档CRUD操作
show collections
- db.comment.insert({“articleId”:”10000”,”content”:”今天天气好”}) 注意插入会隐式创建集合,并且添加_id主键字段
db.comment.insertMany([{“articleId”:”10001”,”content”:”今天天气好1”,{“articleId”:”10002”,”content”:”今天天气好2”])
db.comment.find()
- db.comment.find({articleId:”10001”})
- db.comment.findOne({articleId:”10001”})
- db.comment.find({articleId:”10001”},{articleId:1,_id:0}) 第二个参数,主要是过滤fIeld字段
插入失败会终止插入,mongodb没有事务性,没办法回滚,批量插入可以使用try{}catch(e){print(e)}
- db.collection.update(query,update,options)
- db.comment.update({_id:”1”},{articleId:”10010”})覆盖修改
- db.comment.update({_id:”1”},{$set:{articleId:”10010”}})局部更新
- db.comment.update({articleId:”10010”},{$set:{content:”今天天气好1”}},{multi:true}) 批量更新
db.comment.update({_id:”1”},{$inc:{likenum:NumberInt(1)}}) 列值增长的修改
db.collection.remove(条件)
- db.comment.find()
- db.comment.remove({_id:”1”})
- db.comment.remove({articleId:”10010”})
-
文档分页查询
db.collection.coount(query);
- db.collection.count({userId:”123”})
- db.collection.find(query).limit(number).skip(number) 限制条数pageSize,跳过条数(pageNO - 1)* pageSize
db.collection.find().sort({key:1,key1:-1})
其他查询
db.collection.find({field:/正则表达式/})
- db.collection.find({“field”:{$gt:Number(value)}})
- db.collection.find(field:{$in:[“1”,”2”]})
- db.comment.find({$and:[{price:{$gt:NumberInt(100)}},{price:{$lt:NumberInt(200)}}]}) 多条件查询:$and:[{},{}],$or:[{},{}]
索引Index
索引支持在MongoDB中高效地执行查询,如果没有索引,MongoDB必须执行全表集合扫描,即扫描集合中的每个文档,以选择与查询语句匹配的文档。这种扫描集合的效率是非常低的,特别是在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
如果查询存在适当的索引,MongoDB可以使用该索引限制必须检查的文档数。
索引是特殊的数据结构,它以易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按照字段值排序。索引项的排序支持有效的相等匹配和基于范围的查询操作。此外,MongoDB还可以使用索引中的排序返回排序结果。
MongoDB索引使用B树数据结构,确切的说是B-Tree树,Mysql是B+Tree树。具体结构?区别?单字段索引
MongoDB支持在文档的单个字段上创建用户定义的升序和降序索引,称为单字段索引。对于单个字段索引和排序操作,索引键的排序顺序并不重要,因为MongoDB可以在任何方向上遍历索引。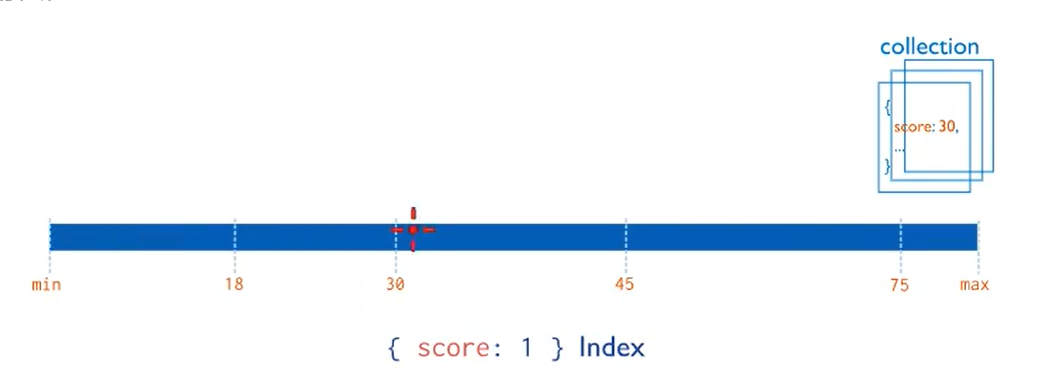
复合索引
MongoDB支持多个字段的用户定义索引,即复合索引,复合索引中列出字段顺序具有重要意义,例如复合索引由{userid:1,score:-1}组成,则索引首先按userId正序排序,然后在每个userId的值内,再按score倒序排序。
其他索引
地理空间索引、文本索引(es优质)、哈希索引
索引管理操作
查询:db.colletion.getIndexes() 存在默认创建的主键索引 v 索引版本 key 字段 name 索引名称 ns 存储命名空间下
创建:db.colletion.createIndex(keys,options) key -> {userid:1,socre:-1} option -> unique 唯一索引 name 索引名称 weight 权重
移除:db.collection.dropIndex(index) ①db.collection.dropIndex({userid:1}) ②db.collection.dropIndex(“indexName”) ③db.collection.dropIndexes() 删除所有索引,不包含主键索引
索引使用-执行计划
db.conllection.find(query,options).explain(option) 分析查询扫描文档数,是否走索引等
涵盖的查询(覆盖查询)
当查询条件和查询的投影仅包含索引字段时,MongoDB直接从索引返回结果,而不扫描任何文档或将文档带入内存。
db.conllection.find({score:{“$lt”:30}},{score:1,_id:0})
聚合
- db.conllection.aggregate(option) $sum/$avg/$min/$max
db.article.aggregate([{$group : {_id : “$by”, sum_count : {$sum : 1}}}])
实例
文章以及文章评论和子评论,点赞等;
文章表(文章ID,标题,内容,点赞数,评论数)
评论表Comment(ID,内容,发布人,日期,点赞数,回复数,文章ID,状态,上级评论ID)
@Id 主键,@Indexed 索引,@Compom.. 复合索引 JPA集成
点赞功能:inc mongoTemplate 对象MongDB集群
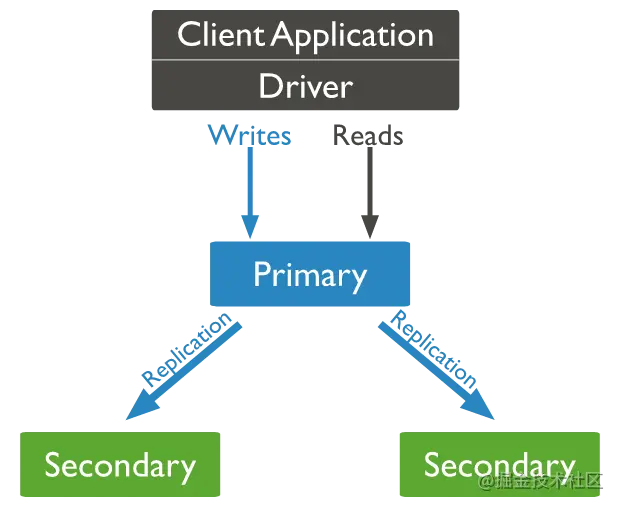
副本集,副本集是一组相同数据集的MongoDB实例,同时在多个节点存储数据,提高了可用性。主节点负责写入,从节点负责读取,提高整体性能;(redis哨兵?)
副本集由下面的组件构成:主节点Primary:主节点接收所有的写操作。
- 从节点Secondaries:从节点会从主节点进行数据的复制,维护跟主节点相同的数据。用户查询操作。
- 仲裁Arbbiter:仲裁节点本身不存储数据,只能参与选举。
分片是MongoDB绝对的亮点,将数据水平拆分到多个节点。MongoDB的分片是全自动的,我们只需要配置好分片的规则,它就能自动维护数据并存储到不同节点。MongoDB使用分片来支持大数据量的存储 和高吞吐量的操作;(ES集群?对宕机某个节点,依然可以支持)
分片集群由以下组件构成:
分片节点Shard:每个Shard的数据都是独立完整的一份。并且可以作为副本集部署。
路由器mongos:mongos是查询路由器,在客户端和服务端中间的一层,请求会直接连接到mongos,有mongos路由到具体的Shard;
配置服务Config Servers:存储集群所有节点,分片数据路由信息;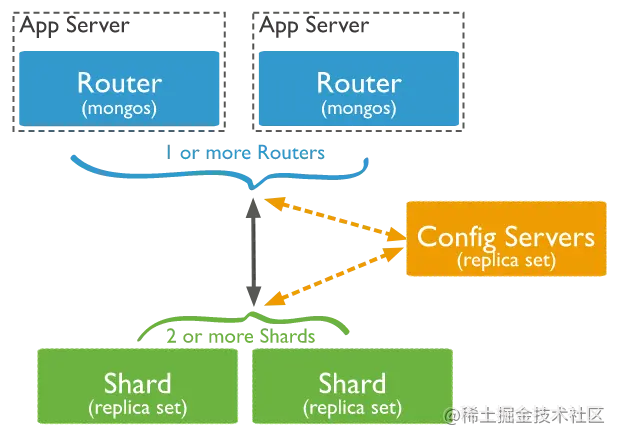
GridFS,是MongoDB的一个子模块,主要用于在MongDB存存储文件,相当于MongoDB内置的一个分布式文件系统。本质上还是讲文件的数据分块存储在集合中,默认的文件集合分别为fs.files和fs.chunks。fs.files是存储文件的基本信息,比如文件名,大小,上传时间,md5等。fs.chunks是存储文件真正数据的地方,一个文件会被分割成多个chunk块进行存储,一般为256k/个。
参考地址:https://juejin.cn/post/6844904047330213902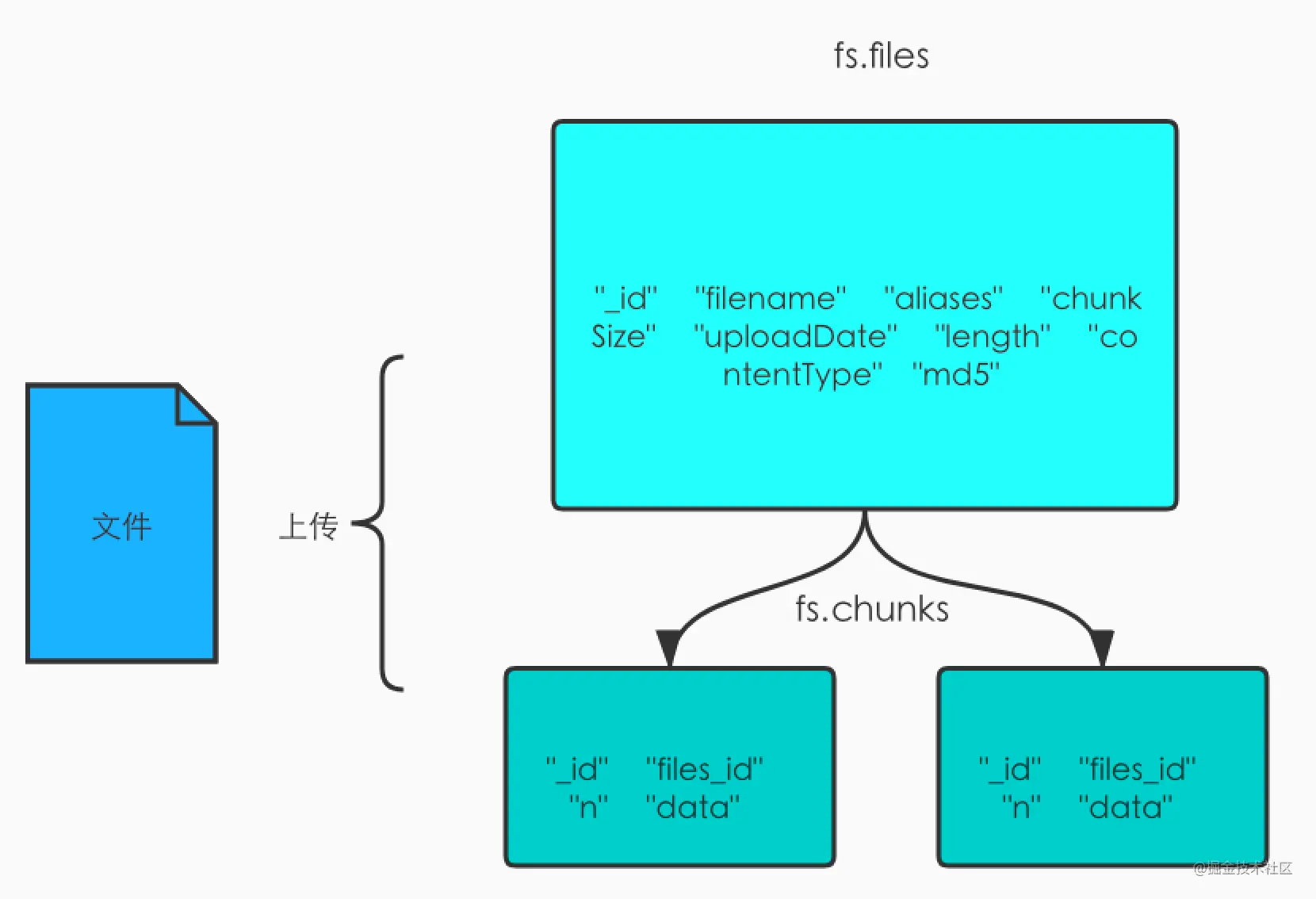

若有收获,就点个赞吧
0 人点赞
