是什么?
介绍
elasticSearch,简称ES,是一个基于Lucene的搜索服务器,是一个分布式(支持集群)、高扩展、高实时的搜索与数据分析全文检索引擎,基于RESTful web(CRUD请求GET/POST/DELETE/PUT)接口。它能很方便的使大量数据具有搜索、分析和探索的能力(搜索ES、分析Kibana)。充分利用Elasticsearch的水平伸缩性(集群扩容),能使数据在生产环境变得更有价值。
Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为ELK;
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索(还是存在延迟的),并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
{ "name" : "Kx-JjgS","cluster_name" : "elasticsearch","cluster_uuid" : "wl9vCFXJTsiqGsJI6xN0xA","version" : {"number" : "5.6.8","build_hash" : "688ecce","build_date" : "2018-02-16T16:46:30.010Z","build_snapshot" : false,"lucene_version" : "6.6.1"},"tagline" : "You Know, for Search"}
Elasticsearch通过官网下载windows版,解压开箱即用,单机的Elasticsearch本身就是集群(cluster_name)名称为elasticsearch(参考百度百科),cluster代表一个集群,集群有多个节点,其中有一个主节点,主节点通过选举产生,每个主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的;shards代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改;replicas代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复,二是提高es的查询效率,es会自动对搜索请求进行负载均衡;recovery代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复;其他river数据源、gateway索引快照的存储方式、discovery.zen自动发现节点机制,Transport内部节点或集群与客户端的交互方式。
概念
概念1:全文检索Full-text Search(solr/luence/es,建立索引记录出现次数和所在位置)、倒排索引Inverted Index(下图),Elasticsearch能够实现快速、高效的搜索功能,正是基于倒排索引原理。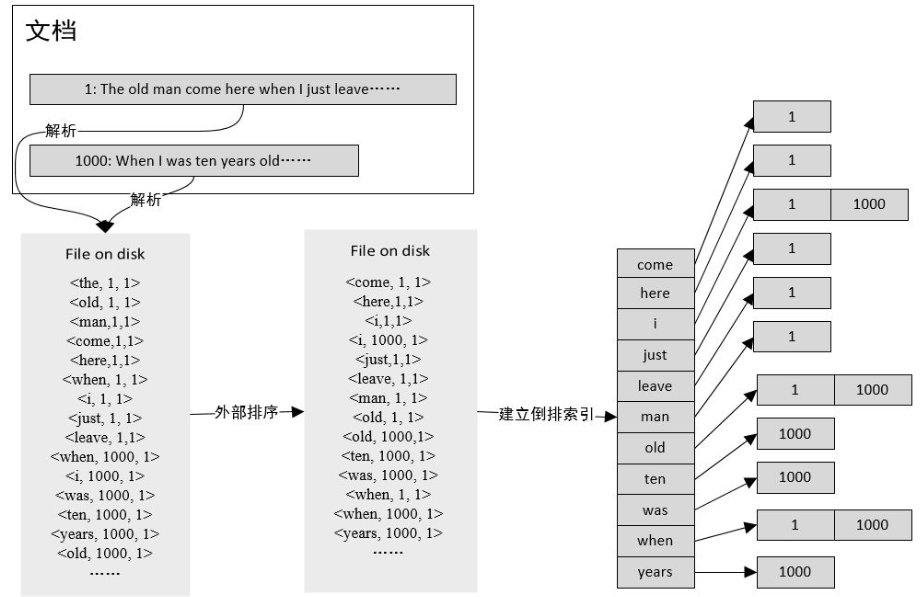
概念2:节点 & 集群Node & Cluster(分布式)、索引Index(库)、文档Document(行,json)、类型Type(表、相似type,默认_doc)、字段Fields(列名),可对比mysql数据库进行理解。
概念3:文档元数据为_index, _type, _id, 这三者可以唯一表示一个文档,_index表示文档在哪存放,_type表示文档的对象类别,_id为文档的唯一标识。
概率4:RESTfulWeb风格API接口通过,HTTP协议JSON请求数据RESTfulWeb风格请求方式来操作数据;”doc”包围住请求参数;POST /test1/type/1/_update{“doc”:{“body”: “here1” }};
| HTTP方法 | 说明 | 其他 |
|---|---|---|
| GET | 获取请求对象的当前状态 | json{query} |
| POST | 改变对象的当前状态 | _search/_update/_delete/_reindex/query script |
| PUT | 创建一个对象 | mapping |
| DELETE | 销毁对象 | delete |
| HEAD | 请求获取对象的基础信息 |
怎么用?
索引类型
类型:Text
特点:支持分词(分词器、可自定义分词、设置权重)、全文检索、支持模糊搜索match分词、精准查询term、不支持聚合排序、无最大存储值限制
场景:地址信息、文字博客
类型:keyword
特点:不进行分词,直接索引、支持模糊查询match、支持精准匹配term、支持聚合和排序、有最大支持长度32766个UTF-8类型的字符(可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果)
查询关键字
{"query": { //查询"bool": {"must": [ //与{"term": {//等于"FIELD": {"value": "VALUE"}}},{"match": {//Like查询"FIELD": "TEXT"}},{"range": {//范围"FIELD": {"gte": 10,"lte": 20}}}],"must_not": [//非{}],"should": [//或{}]}},"aggs": {//聚合"NAME": {"AGG_TYPE": {}}},"size": 20,//分页"sort": [//排序{"FIELD": {"order": "desc"}}]}
Springboot和ES
<!-- spring data elasticsearch --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>
类与方法
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();// 是boolQueryBuilder.must(QueryBuilders.termQuery("key","value"));// 或boolQueryBuilder.should(QueryBuilders.termQuery("key","value"));// 或查询需要命令几个boolQueryBuilder.minimumShouldMatch(1);// 过滤boolQueryBuilder.filter(QueryBuilders.termQuery("key","value"));boolQueryBuilder.mustNot(QueryBuilders.termQuery("key","value"));// agg聚合TermsAggregationBuilder player = AggregationBuilders.terms("player_count ").field("player");TermsAggregationBuilder position = AggregationBuilders.terms("pos_count").field("position");NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();nativeSearchQueryBuilder.addAggregation(player).addAggregation(position);// 分页nativeSearchQueryBuilder.withQuery(boolQueryBuilder);Pageable pageable = PageRequest.of(1, 10);nativeSearchQueryBuilder.withPageable(pageable);// 排序String sort = "hostProductNum";SortOrder sortOrder = SortOrder.DESC;nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort(sort).order(sortOrder));// 执行 ...
<!-- Es 高级客户端--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.9.2</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.9.2</version></dependency>
类与方法
// 创建索引CreateIndexRequest createIndexRequest = new CreateIndexRequest("test_index");// 执行创建索引返回client.indices().create(createIndexRequest, RequestOptions.DEFAULT);// 获取索引GetIndexRequest getIndexRequest = new GetIndexRequest("test_index");// 是否存在该索引返回client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);// 删除索引DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("test_index");// 删除索引结果是否成功client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);// 文档-请求参数JSONObject requestJson = new JSONObject();requestJson.put("key", "value");// 操作文档-添加IndexRequest indexRequest = new IndexRequest();indexRequest.id("1");indexRequest.timeout(TimeValue.timeValueDays(1));indexRequest.source(requestJson);client.index(indexRequest, RequestOptions.DEFAULT);// 操作文档-获取文档GetRequest getRequest = new GetRequest("test_index", "1");// 不返回_source获取上下文getRequest.fetchSourceContext(new FetchSourceContext(false));getRequest.storedFields("_none_");client.exists(getRequest, RequestOptions.DEFAULT);client.get(getRequest, RequestOptions.DEFAULT);// 操作文档-更新文档UpdateRequest updateRequest = new UpdateRequest("test_index", "1");updateRequest.timeout("1s");updateRequest.doc(requestJson);client.update(updateRequest, RequestOptions.DEFAULT);// 操作文档-删除从文档DeleteRequest deleteRequest = new DeleteRequest("test_index", "1");client.delete(deleteRequest, RequestOptions.DEFAULT);
集群
clueter,ES集群可以有多个节点,其中有一个节点是主节点,主节点是通过选举产生的,但是集群对外来说就是无节点的,是一个整体,ES集群时一个P2P类型,使用gossip协议,除了集群管理外,其他所有请求都是可以发送到集群的任意一台节点,也就是说在实际相互开发过程中,连接任意一个节点都是可行的,发送的请求,都会通过ES集群管理发送给各个节点;物理结结构中物理存储单位即是一个Luncene创建的索引库(分片就是一个Luncene实例),同时考虑到集群的高可用和高性能,一般集群节点数量都是3个节点以及以上;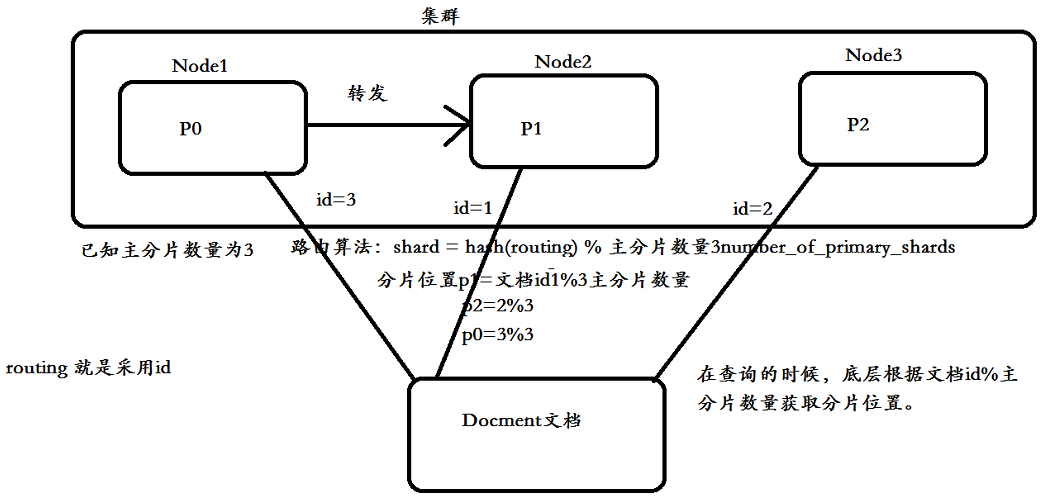
node,节点就是集群的一个服务器,作为集群的一部分,他存储数据,参与集群的索引和搜索功能,和集群类似,一个节点也是由一个唯一的名字来作为标识,通常请求下配置集群名称为es-clueter,节点名称是es-node-1,es-node-2,es-node-3等,在配置文件中三个节点会配置相同集群名称和不同的节点名称,同时会bind绑定自己的IP端口,配置PING其他节点的网络IP和地址;
小点:discovery.zen.minimum_master_nodes设置的不是N/2+1时,会出现脑裂问题,之前宕机的主节点恢复后不会加入到集群,在三个节点请求下,某一非master个节点宕机之后,集群状态会从绿色(所有主要分片和复制分片可用)转换到黄色(所有主要分片可用,但是不是所有复制分片都可用),但是过一段时间后,集群会重新主要分片和复制分片到两个节点上且集群状态恢复到绿色;当非master节点恢复后,重新加入到集群当中,且重新分配了节点信息(分片所在节点);当master节点挂机,集群会进行重新选举,然后集群变成黄色状态,且同样重新分配集群信息,分配完毕后集群恢复到绿色状态;当master节点恢复后,重新加入到集群当中且集群状态为绿色,且重新分配节点信息;这个模拟场景可以看出ES在故障下的解决方法和机器扩展情况下的工作原理,需要注意discovery.zen.minimum_master_nodes的配置需要是N/2+1的情况下;
#集群名称,保证唯一cluster.name: es-clueter#节点名称,必须不一样node.name: es-node-1#该节点是否有资格选举为master,如果上面设了两个mater_node 2,也就是最少两个master节点node.master: true#存储索引数据node.data: truepath.data: /data/elasticsearch/datapath.logs: /data/elasticsearch/logs#锁住物理内存,不使用swap内存,有swap内存的可以开启此项bootstrap.memory_lock: truebootstrap.system_call_filter: falsenetwork.host: 0.0.0.0#服务端口号http.port: 9200#集群间通信端口号transport.tcp.port: 9300#表示集群最少的master数,如果集群的最少master数据少于指定的数,将无法启动,官方推荐node master数设置为集群数/2+1discovery.zen.minimum_master_nodes: 2#自动发现拼其他节点超时时间discovery.zen.ping_timeout: 3sdiscovery.zen.ping.unicast.hosts:#设置集群自动发现机器ip集合,设集群互通端口为9300discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
分片shard和复制replicas,一个索引可以存储超出单个节点硬件限制的大量数据,但是太大的数据量(1TB),单个节点不一定有那么大的存储空间而且单节点处理搜索请求,响应太慢了;为了解决这个问题,ES提供了将索引划分成多份的能力(是否意味怎么,一个_mapping索引内容实际存储分布在不同节点上,而且每个document数据是被拆分成到不同对应索引来存储的),这些就叫做分片,当创建索引的时候可以指定分片的数量,每个分片本身也是一个功能完善而且独立的索引,这个索引可以被放置到任何的节点上面,但是在有副本或者说复制replicas情况下,不同副本相同分片号的数据不存储到同一台服务器上(高可用)。在高扩展性这方法,ES复制分片可以支持在新节点上,新增索引的复制数量,而且ES的搜索是可以在所有的复制上面并行运行的(不仅仅是容灾防数据丢失的数据备份),提高了搜索量和吞吐量,但是一但创建索引之后是无法修改分片的数量,只能动态改变复制数量,来提供整体高可用和高吞吐。<br />小点:深颜色的框代表是主分片,负责写入,副本负责读;<br />
踩过的坑
①在docker部署或者是Linux部署,在6.x左右的版本ES的启动无法通过root用户来启动,需要将数据的data文件夹搜索给新的计算机用户来启动ES;
chown -R elasticsearch: /data/elasticsearch;
②ES需要修改虚拟机、docker容器的系统参数;
vm.max_map_count=655360,系统最大打开文件描述符数。
vm.max_map_count=655360,限制一个进程拥有虚拟内存区域的小。
提问:
1.数据插入的过程?
通过shard_num = hash(\routing) % num_primary_shards,计算出文档要分配到的分片,在从集群元数据中找出对应主分片的位置,请求接着会发送给Primary Shard,在Primary Shard上执行成功后,从Primary Shard上将请求同时发送给多个Replica Shard,请求在多个Replica Shard上执行成功并返回给Primary Shard后,写入请求执行成功返回结果给客户端。
Elasticsearch为了减少磁盘IO保证读写性能,一般是每隔一段时间(比如5分钟)才会把Lucene的Segment写入磁盘持久化。为了保证写入Lucene内存的数据不丢失,引入Translog在每一个Shard中,写入流程分为两部分,先写入Lucene,再写入TransLog。写入请求到达Shard后,先写Lucene文件,创建好索引,此时索引还在内存里面,接着去写TransLog,写完TransLog后,刷新TransLog数据到磁盘上,写磁盘成功后,请求返回给用户。关于TranseLog两个点: 先写内存,最后才写TransLog,每隔一段比较长的时间,比如30分钟后,Lucene会把内存中生成的新Segment刷新到磁盘上,刷新后索引文件已经持久化了,历史的TransLog就没用了,会清空掉旧的TransLog。
- 数据查询流程?
协调节点将检索请求广播到每个分片上,每个分片本地执行检索请求,构建检索匹配的优先队列(返回数据ID),协调节点整合全局搜索结果集数据ID,协调节点通过数据ID,提交多个获取数据的请求,每个节点将数据返回给协调节点,协调节点返回给客户端;

若有收获,就点个赞吧
0 人点赞
