- 许多基础数据类型 都和对象的 集合 有关 。
- 具体来说,数据类型的值就是一组对象的集合,所有操作都是关于 添加 (bag)、 队列 (Queue)、 栈 (Stack)。
- 不同之处在于: 删除 or 访问对象的顺序
🍅 目标
- 说明我们对集合中的对象的表示方式将直接影响各种操作的效率
- 介绍泛型和迭代
-
API
泛型
集合类的抽象数据类型的一个关键特性:可以用他们 储存任意类型的数据 。
- 一种特别的Java机制可以做到这一点: 泛型 (参数化类型
- Stack
- 某种元素的栈
- 在实现Stack时,我们并不知道Item的具体类型,但用力可以用我们的栈处理任意类型的数据,甚至是在我们的实现之后才出现的数据类型。
创建栈时,用例会提供一种具体的数据类型:我们可以将Item替换为任意引用数据类型。
自动装箱
类型参数必须被实例化为引用类型,Java有一种特殊机制来 使泛型代码能够处理原始数据类型
Java的封装类型都是原始数据类型所对应的引用类型 | 原始类型 | 封装类(引用类型) | | :—- | :—- | | double | Double | | float | Float | | byte | Byte | | short | Short | | int | Integer | | long | Long | | char | Character | | boolean | Boolean |
在处理赋值语句、方法的参数、算数or逻辑表达式时,Java会自动在引用类型和对应的原始数据类型之间进行转换。
这种转换有助于我们同时使用泛型和原始数据类型
Stack<Integer> stack = new Stack<Integer>(); //创建一个空栈stack.push(17); //自动装箱(int->Integer)原始数据类型->封装类型int i = stack.pop(); //自动拆箱(Integer->int)封装类型->原始数据类型
在这里,我们将一个原始类型的值17传递给push()方法时,Java将它的类型自动转换(自动装箱)为Integer。
pop()方法返回了一个Integer类型的值,Java在将它赋予变量i之前将它的类型自动转换(自动拆箱)为了int
可迭代的集合类型
要求只是用某种方式处理集合中的每个元素(迭代访问集合中的所有元素)
Queue<Transaction> collection = new Queue<Transaction>();//如果集合可迭代,用一行语句即可打印出交易的列表for(Transaction t : collection){ //foreach语句遍历STdOut.printf(t);}
背包
一种不支持从中删除元素的集合数据类型
- 目的
- 帮助用例收集元素
- 迭代遍历所有收集到的元素
- 也可检查背包是否为空/获取背包中元素的数量
- 迭代的顺序不确定&&与用例无关


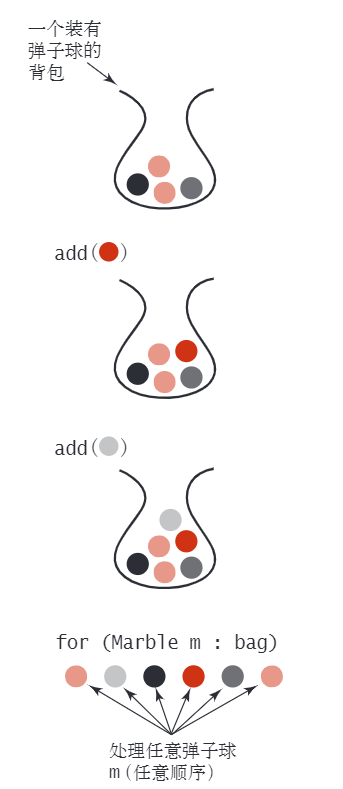
当然啦,用栈和队列也可以完成这种操作,但是使用背包可以说明:元素的处理顺序不重要
🧐举个例子
就是简单的算个平均值和标准差.
因为这些计算中,数的计算顺序和结果无关,所以我们将他们保存在一个bag里面,再foreach一下.
🤔需要注意的是,不需要保存所有的数也可以计算标准差(就像我们在Accumulator中计算平均值一样).用bag对象保存所有数字是更复杂的统计计算所必须的.
package day01;import edu.princeton.cs.algs4.Bag;import edu.princeton.cs.algs4.StdIn;import edu.princeton.cs.algs4.StdOut;public class Stats {public static void main(String[] args) {Bag<Double> numbers = new Bag<Double>();while (!StdIn.isEmpty()){numbers.add(StdIn.readDouble());}int N = numbers.size();double sum = 0.0;for (double x:numbers) {sum += x;}double mean = sum/N;sum=0.0;for (double x:numbers) {sum += (x - mean)*(x - mean);}double std = Math.sqrt(sum/(N-1));StdOut.printf("Mean:%.2f\n",mean);StdOut.printf("Std dev:%.2f\n",std);}}
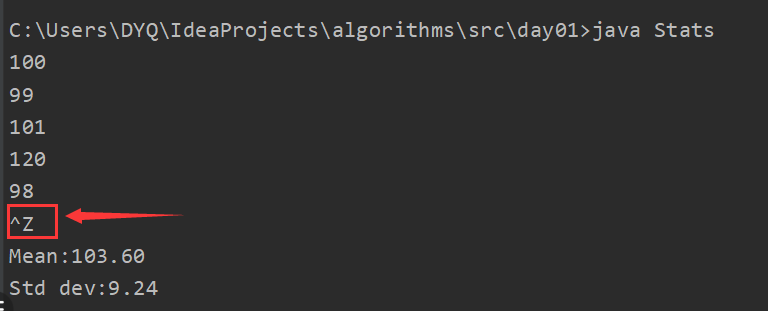
😡这里有一个坑 , 就是这个输入流要在终端测试 , 否则Ctrl+z终止输入无效 , 只能像吃了炫迈口香糖一样永无止境的输入 .
详情可参考P23页的标准输入 (顺便吐槽一下用惯了思源,没有链滴功能真实8太习惯🙃
先进先出队列
🍅 特点
- 在应用程序中使用队列的主要原因是在用集合保存元素的同时保存它们的相对顺序
- 使它们入列顺序和出列顺序 相同

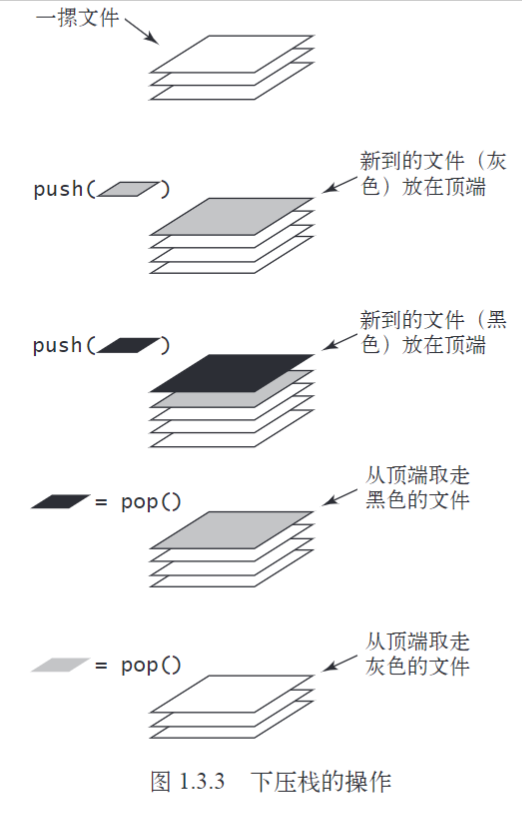
- foreach的时候元素处理顺序和他们被压入的顺序正好 相反 .
-
🧐举个例子
用例将会把标准输入中的所有整数逆序排列输出,它无需预先知道整数的多少.

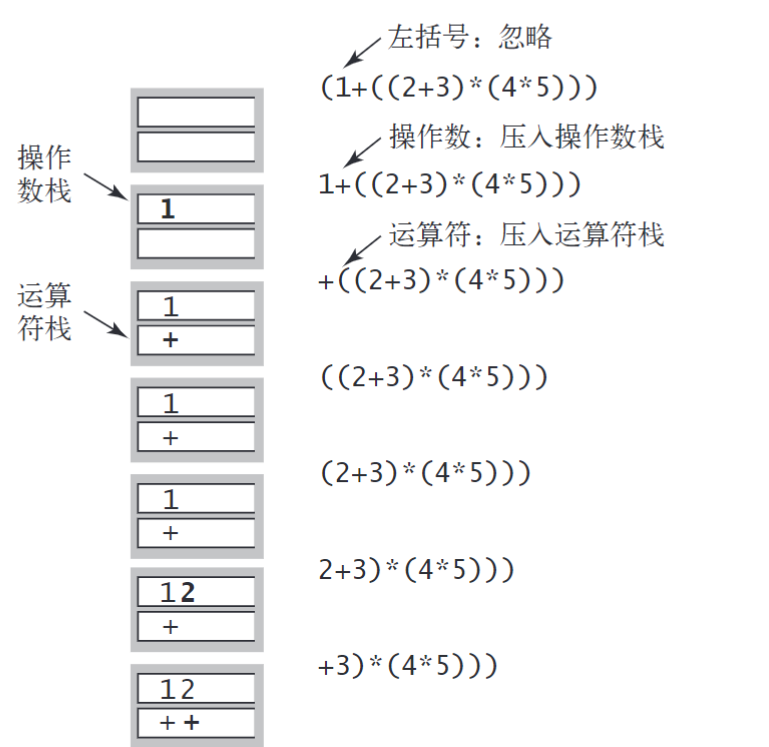
算术表达式求值
( 1 + ( ( 2 + 3 ) ( 4 5 ) ) )
表达式由 括号 运算符 操作数(数字) 组成.
由左到右逐个将这些实体送入栈处理
- 将操作数压入操作数栈;
- 将运算符压入运算符栈;
- 忽略左括号;
- 在遇到右括号时,弹出一个运算符,弹出所需数量的操作数,并将运算符和操作数的运算结果压入操作数栈。
📚 证明
每当算法遇到一个被括号包围并由一个运算符和两个操作数组成的子表达式时,它都将运算符和操作数的计算结果压入操作数栈。
- 这样的结果就好像在输入中用这个值代替了该子表达式,因此用这个值代替子表达式得到的结果和原表
达式相同。我们可以反复应用这个规律并得到一个最终值。例如,用该算法计算以下表达式得到的
结果都是相同的:


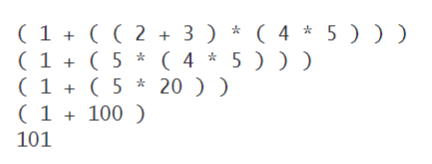
🌵 code
public class Evaluate{public static void main(String[] args){Stack<String> ops = new Stack<String>();Stack<Double> vals = new Stack<Double>();while (!StdIn.isEmpty()){ // 读取字符,如果是运算符则压入栈String s = StdIn.readString();if (s.equals("(")) ;else if (s.equals("+")) ops.push(s);else if (s.equals("-")) ops.push(s);else if (s.equals("*")) ops.push(s);else if (s.equals("/")) ops.push(s);else if (s.equals("sqrt")) ops.push(s);else if (s.equals(")")){ // 如果字符为")",弹出运算符和操作数,计算结果并压入栈String op = ops.pop();double v = vals.pop();if (op.equals("+")) v = vals.pop() + v;else if (op.equals("-")) v = vals.pop() - v;else if (op.equals("*")) v = vals.pop() * v;else if (op.equals("/")) v = vals.pop() / v;else if (op.equals("sqrt")) v = Math.sqrt(v);vals.push(v);} // 如果字符既非运算符也不是括号,将它作为 double 值压入栈else vals.push(Double.parseDouble(s));}StdOut.println(vals.pop());}}

集合类数据类型的实现
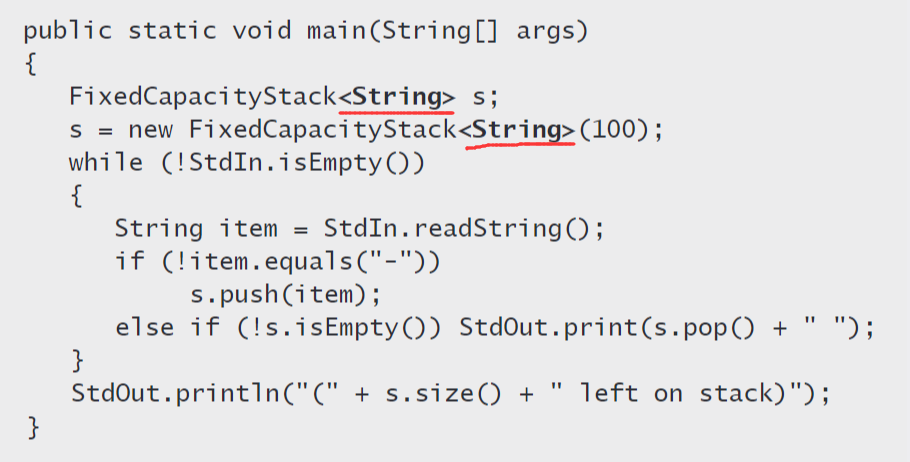
定容栈
🍅 特点
- 它要求用例指定一个容量(容量固定)且不支持迭代。
它只能处理 String 值(缺点:改进用泛型,详见后面一节)
结构声明
数据类型的实现
public class FixedCapacityStackOfStrings{private String[] a; // 保存栈中元素private int N; // 栈中元素数量public FixedCapacityStackOfStrings(int cap) {a = new String[cap];}public boolean isEmpty() {return N == 0;}public int size() {return N;}public void push(String item) { //添加一个元素a[N++] = item; //将a[N]设为新元素并将N加1}public String pop() { //删除一个元素return a[--N]; //将N减1并返回a[N]}}
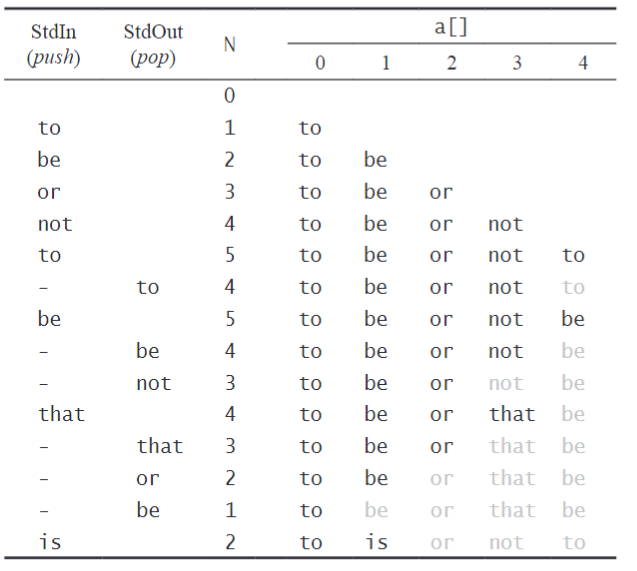
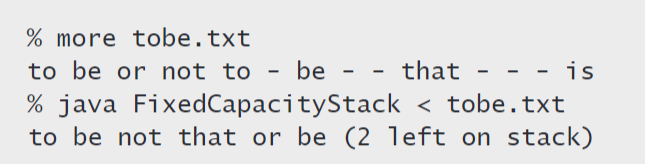
测试用例
public static void main(String[] args){FixedCapacityStackOfStrings s;s = new FixedCapacityStackOfStrings(100);while (!StdIn.isEmpty()){String item = StdIn.readString();if (!item.equals("-"))s.push(item);else if (!s.isEmpty()) StdOut.print(s.pop() + " ");}StdOut.println("(" + s.size() + " left on stack)");}
使用方法
% more tobe.txtto be or not to - be - - that - - - is% java FixedCapacityStackOfStrings < tobe.txtto be not that or be (2 left on stack)
🤢测试用例的轨迹
🤔迷惑:pop命名只是返回一个最新元素,怎么就实现删除(弹出)了?
A:答案其实很简单。不断的pop,只能由右➡左依次返回元素(看轨迹图),实例中遇到“-”依次打印出元素的同时,N本身也被做运算了,一直返回一直返回的同时,N也在逐渐变小,这个时候使用push添加新元素的时候,N++,再次对N做运算,原来的值就被覆盖掉了,相当于没有了指向,直接成了“孤儿”——造成游离问题
当然了,上面这个东西还是漏洞百出的,以下就是对这个定容栈进行各种修补,顺便运用一些Java特性。修补道路慢慢修远兮~~泛型
对于这个FixedCapacityStackOfStrings的第一个缺点就是:丫只能处理String对象,那遇到别的数据类型往里塞,那程序直接就颠儿了啊!
这个时候,就该奉上我们的好兄弟——泛型,来解决这个问题。🍅 特点
-
数据声明 (VS定容栈
数据类型的实现(VS定容栈
测试用例(VS定容栈
使用方法
调整数组大小
选择用数组表示栈,就意味着用例必须预先估计栈的最大容量。
在Java中,数组一旦创建,其大小是无法改变的。因此造成的结果是,要么浪费内存,要么数据溢出
为此,push()方法需要在代码中检测栈是否已满,API中应当有一个isFull()方法,检测栈是否已满
——还有一件事~!动态调整数组a[]的大小。🍅 特点
动态调整空间大小
- 拷贝进更大的空间




- 入栈时检测大小

- 出栈时回收空间

对象游离
🍅 特点
- Java 的垃圾收集策略是回收所有无法被访问的对象的内存
- 被弹出的元素的引用仍然存在于数组中。这个元素实际上已经是一个孤儿了——它永远也不会再被访问了,但 Java 的垃圾收集器没法知道这一点。
- 保存一个不需要的对象的引用,称为游离
避免对象游离方法:
集合类数据类型的基本操作之一就是,能够使用 Java 的 foreach 语句通过迭代遍历并处理集合中的每个元素。
-
🌰 样例1(隐式调用)
能够打印出一个字符串集合中所有元素的代码:
Stack<String> collection = new Stack<String>();...for(String s:collection)StdOut.println(s);...
🌰 样例2 (显式调用)
Iterator<String> i = collection.iterator();while(i.hasNext()){String s = i.next();StdOut.println{s);}
🍅 观察:任意可迭代的集合数据类型中我们都需要实现:
集合数据类型必须实现一个
iterator()方法并返回一个Iterator对象;- Iterator 类必须包含两个方法:
hasNext()(返回一个布尔值)next()(返回集合中的一个泛型元素)
- 🤔(接口指定一个类必须实现的方法,此处就是用Java已定义的接口为Iterator类实现hasNext()和next()方法)
Java中使用接口实现该功能,要使一个类可迭代,分为两步
第一步:就是在它的声明中加入
implements Iterable<Item>,对应的接口(即java.lang.Iterable)为public interface Iterable<Item>{Iterator<Item> iterator();}
第二步:类中添加一个方法
iterator()并返回一个迭代器 `Iteratorpublic Iteractor<Item> iteractor(){return new ReverseArrayIteractor();}
迭代器的定义
迭代器是什么?它是一个实现了
hasNext()和next()方法的 类 的 对象public interface Iteractor<Item>{boolean hasNext();Item next();void remove();}
嵌套类 :
ReverseArrayIterator,嵌套类可以访问包 含它的类的实例变量private class ReverseArrayIterator implements Iterator<Item>{private int i = N;public boolean hasNext(){return i > 0; }public Item next(){ return a[--i]; }public void remove(){}}
补充:
两种情况下抛出异常
- 如果用例调用了
remove()则抛出UnsupportedOperationException - 在调用
next()时 i 为 0 则抛出NoSuchElementException - 因为我们只会在
foreach语法中使用迭代器,这些情况都不会出现,所以我们省略了这部分代码
- 如果用例调用了
- 程序的开头加上下面这条语句
import java.util.Iterator;- 因为(某些历史原因)
Iterator不在java.lang中(尽管Iterable是java.lang的一部分)。
- 因为(某些历史原因)
🍋 下压栈实现(能动态调整数组大小)
这份泛型的可迭代的 Stack API 的实现是所有集合类抽象数据类型实现的 模板 。
几乎达到了任意集合类数组类型的最佳性能
- 每项操作所用时间与集合大小无关
- 空间需求<=集合大小*一个常数
当然啦,他们也有一些缺点:调整数组大小时,其所耗时与数组大小成正比。
import java.util.Iterator;public class ResizingArrayStack<Item> implements Iterable<Item> {private Item[] a = (Item[]) new Object[1]; //栈元素private int N = 0;public boolean isEmpty(){return N == 0;}public int size(){ return N; }private void resize(int max){//将栈移动到一个大小为max的新数组Item[] temp =(Item[]) new Object[max];for (int i = 0; i < N; i++) {temp[i] = a[i];}a = temp;}public void push(Item item){//将元素添加到栈顶if (N==a.length) resize(2*a.length);a[N++] = item;}public Item pop(){//从栈顶删除元素Item item = a[--N];a[N]=null;if (N > 0 && N == a.length/4) resize(a.length/2);return item;}public Iterator<Item> iterator(){return new ReverseArrayIterator();}private class ReverseArrayIterator implements Iterator<Item>{//支持后进先出的迭代private int i = N;@Overridepublic boolean hasNext() {return i > 0;}@Overridepublic Item next() {return a[--i];}@Overridepublic void remove() {}}}
🤕坑

这个类的声明接口 Iterable 千万别忘,这个接口是后期主函数调用foreach方法时候要用到的
具体可以回顾一下之前的迭代知识点(吐槽一下自己的金鱼脑呜呜
链表
- 链表 是一种递归的数据结构。它或者为 空 (null),或者是 指向一个结点的引用
- 该结点:含有一个 泛型 的元素 和 一个 指向另一条链表的引用

若有收获,就点个赞吧
0 人点赞
