官网资源
本书官网链接
课后答案链接(左侧边栏
国内同学写的较为全面的课后答案链接
类库链接
书上各种经典算法的代码实现链接
数据结构和算法动态可视化链接
基础编程模型
数组起别名P12
将一个 数组变量 赋予另一个变量 —-> 两个变量指向同一个数组 在这种情况叫做起别名
用于将数组复制一份
int[] a = new int[N];a[i] = 1234;int[] b = a;b[i] = 4567; //a[i]的值也会变成4567,因为ab数组指向同一个空间
初始化
数值类型 —-> 0
布尔型 —-> false
对二维数组更有用 节约更多代码
类库
API P16
模块化编程的一个重要组成部分:记录库方法的用法 并供其他人参考的文档。
统一使用应用程序编接口(API)的方式列出本书中使用的每个库方法名称
目的:将调用和实现分离
🍋命令行输入输出

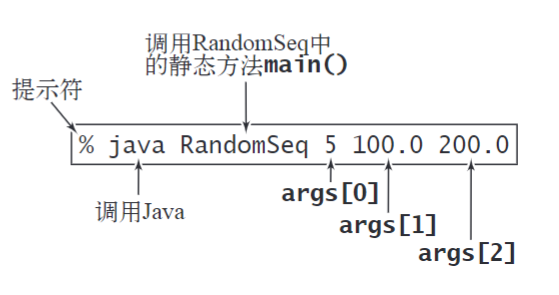
🍌重定向与管道
% java RandomSeq 1000 100.0 200.0 > data.txt
这条命令指明标准输出流不是被打印至终端窗口,而是被写入一个叫做data.txt的文件。
每次调用 StdOut.printf() 或 StdOut.println() 都会向该文件追加一段文本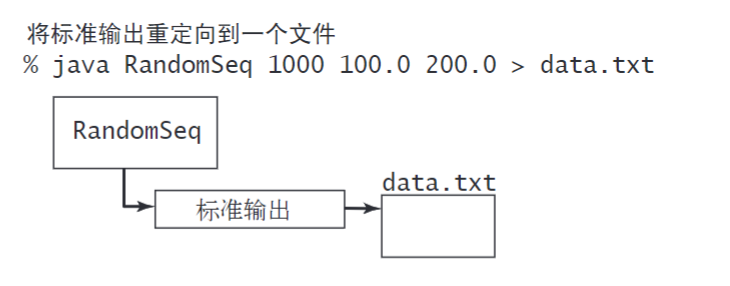
类似的,我们可以重定向标准输入以使StdIn从文件而不是终端应用程序中读取数据:% java Average < data.txt
“<” 是一个提示符,它告诉操作系统读取data文本文件作为输入流而非在终端等待用户输入。当程序调用 StdIn.readDouble() 时,操作系统读取的是文件中的值。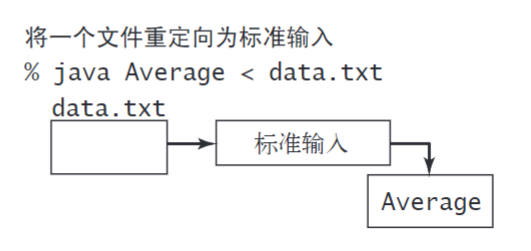
将这些结合起来,将一个程序的输出重定向为另一个程序的输入叫做 管道 % java RandomSeq 1000 100.0 200.0 | java Average
这条命令将RandomSeq的标准输出和Average的标准输入指定为同一个流。
它的效果是在Average运行时RandomSeq将它生成的数字输入了终端。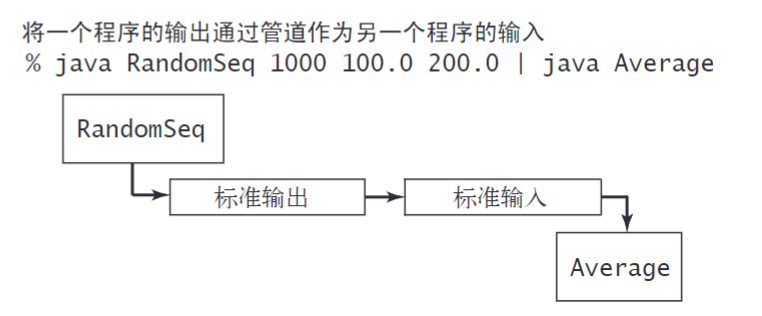
用于读取和写入的API

本书标准库 P19-27
随机数 静态方法库 StdRandom
数据分析 静态方法库 StdStats
类型转换 String 值和数字之间相互转换
Integer.parseInt(String s) 将字符串 s 转换为整数 Integer.toString(int i) 将整数 i 转换为字符串
自动转换 可以通过一个空字符串 “” 将任意数据类型的值转换为字符串值
输出 StdOut
输入 StdIn
读取/写入数组 In / Out
标准绘图库 StdDraw
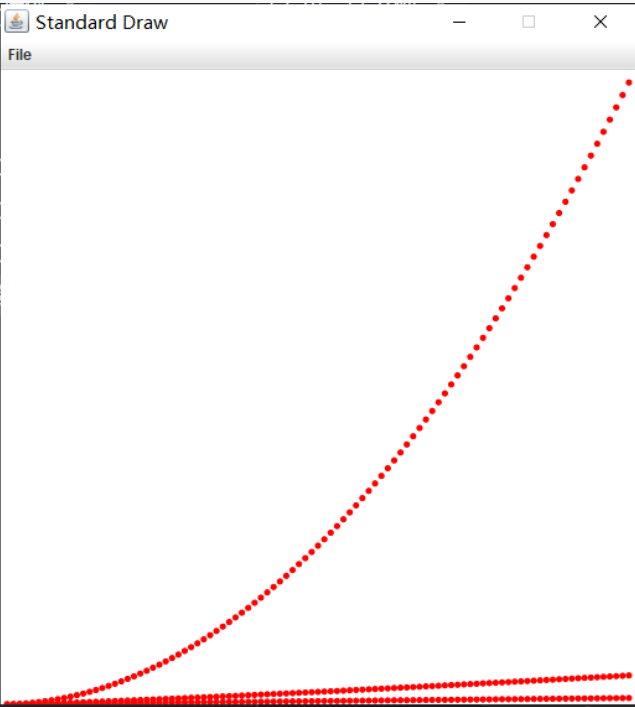
import edu.princeton.cs.algs4.StdDraw;/*** 测试画图类库*/public class Draw01 {public static void main(String[] args) {int N = 100;StdDraw.setXscale(0,N); //将x的范围设为(0,N)StdDraw.setYscale(0,N*N);StdDraw.setPenRadius(.01); // 画笔粗细半径StdDraw.setPenColor(Color.red); //画笔颜色for (int i = 1; i <N ; i++) {StdDraw.point(i,i);StdDraw.point(i,i*i);StdDraw.point(i,i*Math.log(i));}}}
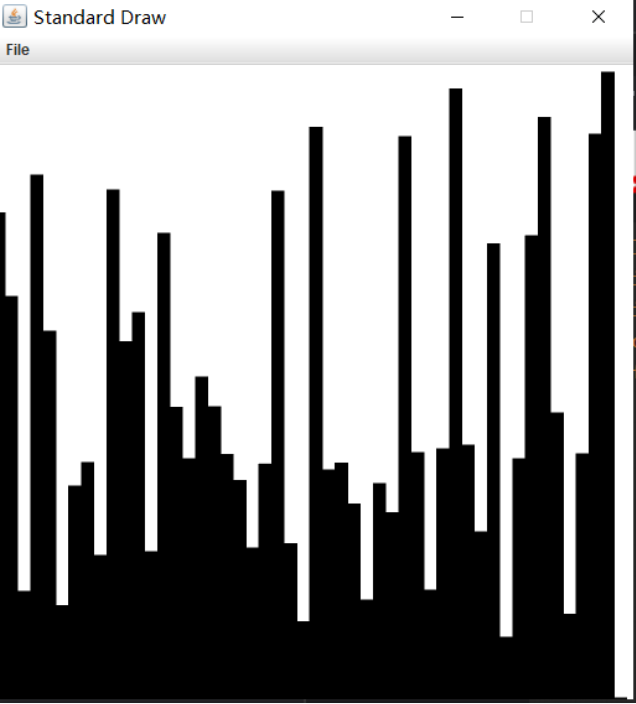
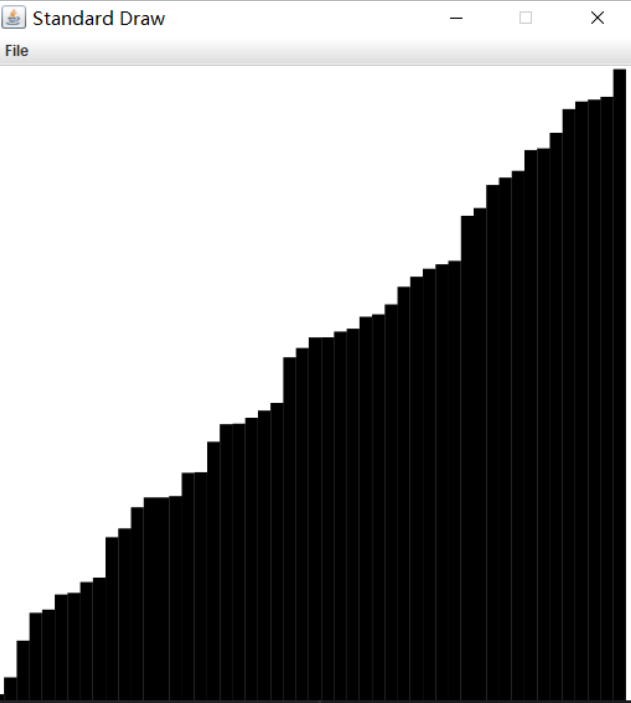
public class Draw03 {public static void main(String[] args) {int N = 50;double[] a = new double[N];for (int i = 0; i < N; i++) {a[i] = StdRandom.random();}//Arrays.sort(a); //测试排序数组和随机数组for (int i = 0; i <N ; i++) {//x,y代表是矩形中心的坐标。 rw, rh分别代表矩形宽的一半,和高的一半double x = 1.0*i/N;double y = a[i]/2.0;double rw = 0.5/N;double rh = a[i]/2.0;StdDraw.filledRectangle(x,y,rw,rh);}}}
二分查找的思维
不断将数组的中间键(索引为mid)和被查找的键比较,查到 键=a[mid],否则范围缩小一半
答疑
负数的/ 和 % 结果?
% 与被除数符号一致 / 不限
为何使用&& 而非& (&&与&的区别
for 与 while 的区别
for 中递增变量一般在循环结束之后不可用,而与它等价的 while 仍可用
int[] a 与 int a[] 声明数组有何不同
后一种是 C 的语法,这两种都等价合法,只是前一种 int[] 更能清楚的说明这是一个整形数组
为何数组起始索引不是 1 而是 0
来源计算机语言,数组是 地址 + 偏移量 这个偏移量就是索引,第一个地址的偏移量是 0(没偏移
如果 a[] 是一个数组,为什么 StdOut.println(a)打印出了 16 进制整数,而非数组中的元素
这是数组的地址,一般不需要它
public class Main{public static void main(String[] args) {int [] a = new int [2];a[1] = 1;a[0] = 2;System.out.println(a);}}结果:[I@1d44bcfa
Java 中一个静态方法能够将另一个静态方法作为参数嘛?
不行!但很多其他语言都能做到
计算 2.0e-6*1000000000.1
2.0e-6 = 2.0*10 的-6 次方
数据抽象
对象
特征:状态 标识 行为 P40
状态:数据类型中的值
标识:将一个对象区别于另一个对象
行为:数据类型的操作
引用
别名
Counter c1 = new Counter();c1.add(); //add方法:+1Counter c2 = c1;c2.add();StdOut.println(c1);结果:2 (而不是1)
使用引用类型的赋值语句将会创建该引用的一个副本。
别名:两个变量同时指向一个对象。
改变一个对象的状态,将会影响到所有和该对象的别名有关的代码
我们习惯于认为两个不同的原始数据类型的变量是相互独立的,这种感觉对于引用类型的变量并不适用
抽象数据类型API P45
更多抽象类型的实现P55
累加器
能够为用例计算一组数据的实时平均值的抽象数据类型。
维护一个int类型的实例变量来记录已经处理过的数据值的数量,以及一个double类型的实例变量来记录所有数据值之和,将和除以数据数量即可得到平均值。
❗:该实现并没有保存数据的值——它可以用于处理大规模的数据
package day01;import edu.princeton.cs.algs4.Accumulator;import edu.princeton.cs.algs4.StdOut;import edu.princeton.cs.algs4.StdRandom;public class TestAccumulator {public static void main(String[] args) {int T = Integer.parseInt(args[0]);Accumulator a = new Accumulator();for(int t = 0 ; t < T ; t++){a.addDataValue(Math.random());}StdOut.println(a.toString());//等价于 StdOut.println(a);}}

Q:一种储存所有数据的实现可能会用光它应用程序的内存。
A:累加器的使用不保留数据的值,用于处理大规模数据(甚至在一个无法全部保存他们的设备上),一个大型设备也可以使用多个累加器。
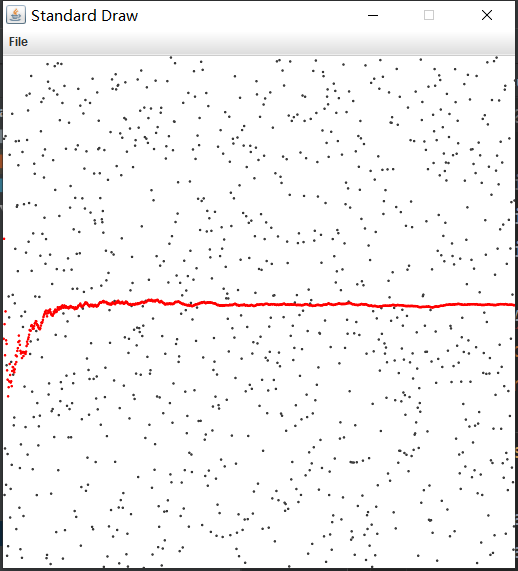
可视化累加器
//package day01;import edu.princeton.cs.algs4.Accumulator;import edu.princeton.cs.algs4.StdOut;import edu.princeton.cs.algs4.StdDraw;class VisualAccumulator {private double total;private int N;public VisualAccumulator(int trials,double max){StdDraw.setXscale(0,trials);StdDraw.setYscale(0,max);StdDraw.setPenRadius(0.005);}public void addDataValue(double val){N++;total+=val;StdDraw.setPenColor(StdDraw.DARK_GRAY);StdDraw.point(N,val);StdDraw.setPenColor(StdDraw.RED);StdDraw.point(N,mean());}public double mean(){return total/N;}}public class TestVisualAccumulator {public static void main(String[] args) {int T = Integer.parseInt(args[0]);VisualAccumulator a = new VisualAccumulator(T,1.0);for(int t = 0 ; t < T ; t++){a.addDataValue(Math.random());}StdOut.println(a.toString());}}

Q&A🧐
Q:为什么使用数据抽象?
帮助我们编写更可靠的代码!
Q:原始数据类型VS引用类型?
原始数据类型更接近计算机硬件所支持的数据类型,使用他们的程序比使用引用类型的程序更快
- 原始类型
- Java中的原始类型是不同于类的基本数据类型
- 包括如下8种基本类型:double、float、byte、short、int、long、char、boolean。
- 这8种 原始类型直接存储在Java的内存栈中,数据本身的值也是存储在栈中,即当声明了一个原始类型时,就在栈中为类型本身申请了存储。
- 同时,Java为每个原始类型提供了对应的封装类型,分别如下:
| 原始类型 | 封装类 |
|---|---|
| double | Double |
| float | Float |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| char | Character |
| boolean | Boolean |
Java中针对原始数据类型提供了对应的封装类,因为在类中可以定义一些必要的方法,用于实现基本数据类型的数值与可打印字符串之间的转换,以及一些其他的实用程序方法; <br /> 另外,有些数据结构库类只能操作对象,而不支持基本数据类型的变量,包装类提供一种便利的方式,能够把基本数据类型转换成等价的对象,从而可以利用数据结构库类进行处理。
- 引用类型
引用类型和原始类型的行为完全不同,分别具有不同的语义,并且具有不同的特征和用法,它们包括:大小和速度问题,使用原始类型无须调用 new,也无须创建对象,这节省了时间和空间。另外,对象引用实例变量的缺省值为 null,而原始类型实例变量的缺省值与它们的类型有关。
下面用一段简单的代码看看原始类型和引用类型在实际编码中的区别:
1. package DataType;2.3. public class Demo1 {4.5. public static void main(String args[]){6. int a = 1; //原始类型7. int b = 2; //原始类型8. Point pOne = new Point(5,5); //引用类型9. Point pTwo = new Point(6,6); //引用类型10.11. System.out.println("Before : a =" + a);12. System.out.println("Before : b =" + b);13. System.out.println("Before : pOne =" + pOne.toString());14. System.out.println("Before : pTwo =" + pTwo.toString());15.16. a = b; //将b赋值给a17. a++; //a自增18. pOne = pTwo; //将pTwo 赋值给pOne19.20. pOne.setX(10); //重置pOne中的值21. pOne.setY(10);22. System.out.println("After : a =" + a);23. System.out.println("After : b =" + b);24. System.out.println("After : pOne =" + pOne.toString());25. System.out.println("After : pTwo =" + pTwo.toString());26. }27.28. }
注:省略了Point类的相关代码,其很简单,就两个int变量,和其对应的set\get方法,以及构造函数等。
首先看看输出结果,如下:
1. Before : a =12. Before : b =23. Before : pOne =Point [x=5, y=5]4. Before : pTwo =Point [x=6, y=6]5. After : a =36. After : b =27. After : pOne =Point [x=10, y=10]8. After : pTwo =Point [x=10, y=10]
从结果中看出,重新赋值后,a和b的值输出结果,在意料之中;而程序中真的pOne和pTwo,仅改变了pOne的值,为什么输出结果中pTwo也改变了,并且跟pOne一致呢?
这就是由于原始类型和引用类型的存储结构不一致导致的,其实,针对“=”本身,对这两种数据类型是没有本质区别的,都是”=”左右的值等于右边的值,但不同的是,针对引用类型,赋值符“=”改变的是对象引用,而不是对象本身,也就是说当程序执行完下面这句之后,
pOne = pTwo;
pOne和pTwo,均指向了同一个对象,因此对pOne的任何操作,同时也会影响到pTwo。

若有收获,就点个赞吧
0 人点赞
