1、为什么要注意力机制
在Attention诞生之前,已经有CNN和RNN及其变体模型了,那为什么还要引入attention机制?主要有两个方面的原因,如下:
(1)计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
(2)优化算法的限制:LSTM只能在一定程度上缓解RNN中的长距离依赖问题,且信息“记忆”能力并不高。
2、什么是注意力机制
在介绍什么是注意力机制之前,先让大家看一张图片。当大家看到下面图片,会首先看到什么内容?当过载信息映入眼帘时,我们的大脑会把注意力放在主要的信息上,这就是大脑的注意力机制。
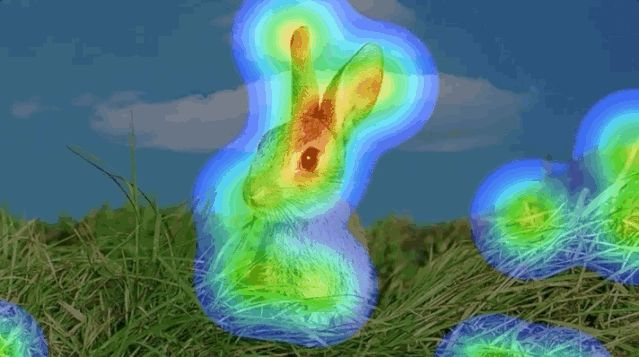
同样,当我们读一句话时,大脑也会首先记住重要的词汇,这样就可以把注意力机制应用到自然语言处理任务中,于是人们就通过借助人脑处理信息过载的方式,提出了Attention机制。
3、注意力机制模型
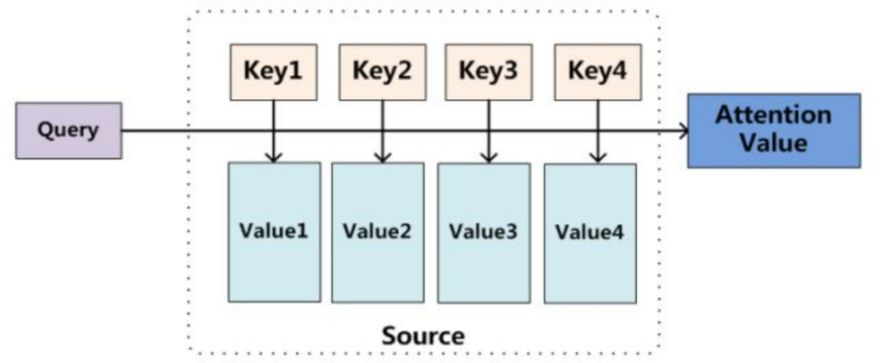
从本质上理解,Attention是从大量信息中有筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如图展示的三个阶段。
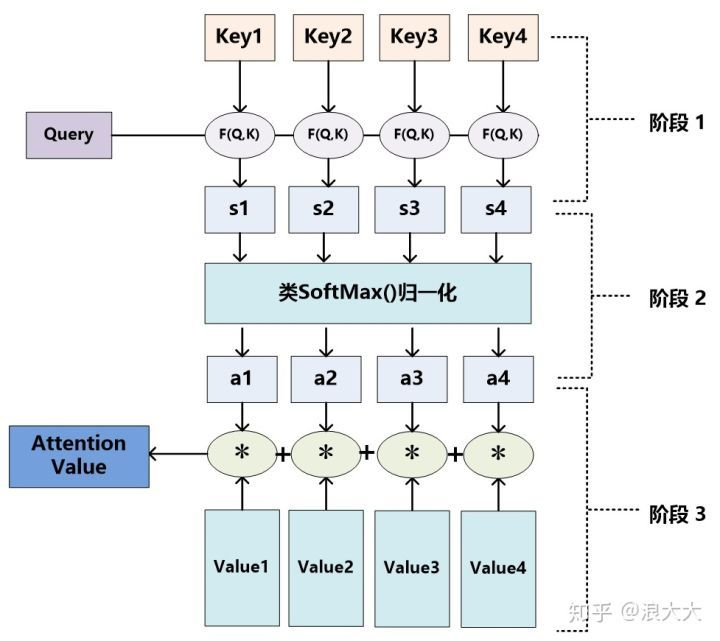
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个 Keyi ,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算: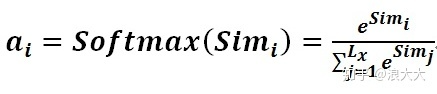
第二阶段的计算结果 ai 即为 Valuei 对应的权重系数,然后进行加权求和即可得到Attention数值:
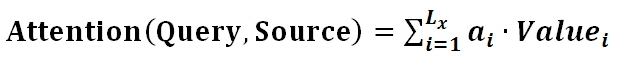
通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
4、Self-attention自注意力机制
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
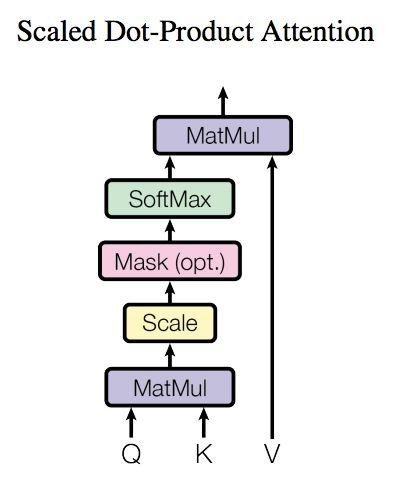
自注意力机制的计算过程:
1.将输入单词转化成嵌入向量; 2.根据嵌入向量得到q,k,v三个向量; 3.为每个向量计算一个score:score =q . k ; 4.为了梯度的稳定,Transformer使用了score归一化,即除以
; 5.对score施以softmax激活函数; 6.softmax点乘Value值v,得到加权的每个输入向量的评分v; 7.相加之后得到最终的输出结果z :z=
v。
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵 Q(查询), K(键值), V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量 x组成的矩阵 X) 或者上一个 Encoder block 的输出。而 Q, K, V 正是通过 Self-Attention 的输入进行线性变换得到的。
3.1 Q, K, V 的计算
计算自注意力的第一步就是从每个编码器的输入向量X(每个单词的词向量)中生成三个向量Q, K, V。也就是说对于每个单词,创造一个查询向量Q、一个键向量K和一个值向量V。
Self-Attention 的输入用矩阵 X进行表示,则可以使用线性变阵矩阵 WQ, WK, WV(这个矩阵是随机初始化的,注意第二个维度需要和embedding的维度一样,其值在BP的过程中会一直进行更新)计算得到 Q, K, V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。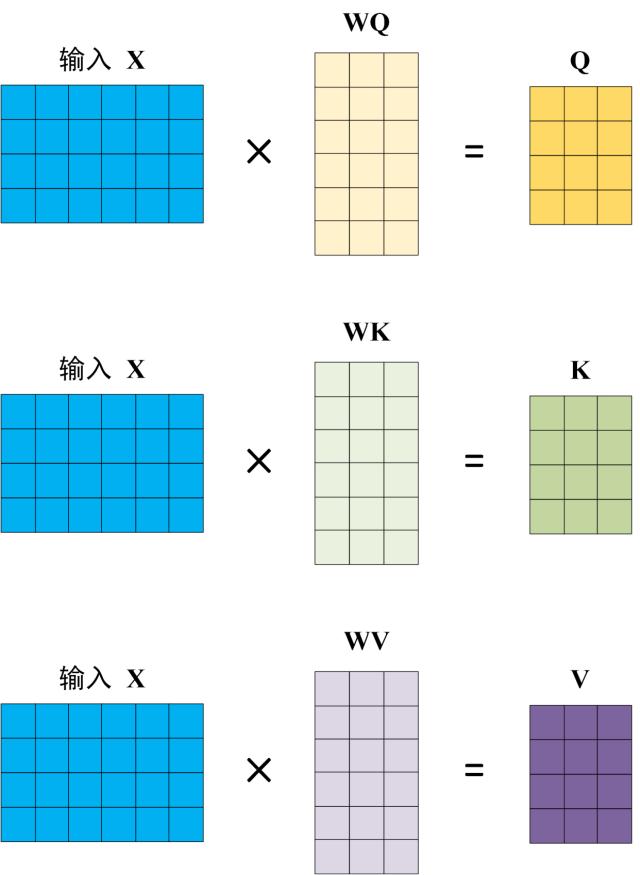
Q, K, V 的计算
3.2 Self-Attention 的输出
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下。

公式中计算矩阵 Q和 K 每一行向量的内积,为了防止内积过大,因此除以 dk 的平方根。Q 乘以 K 的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为 Q 乘以 K 的转置,1234 表示的是句子中的单词。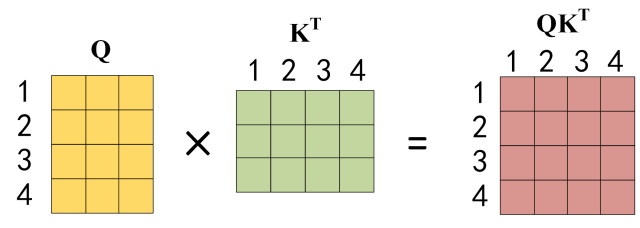
QKT 的计算
得到 QKT 之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1。
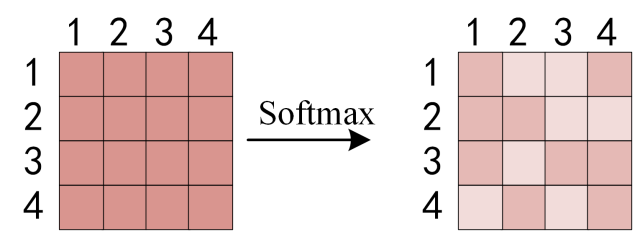
对矩阵的每一行进行 Softmax
得到 Softmax 矩阵之后可以和 V相乘,得到最终的输出 Z。
Self-Attention 输出
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出 Z1 等于所有单词 i 的值 Vi 根据 attention 系数的比例加在一起得到,如下图所示: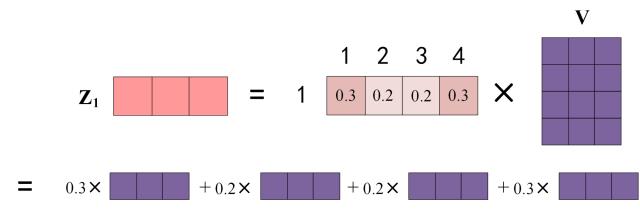
Zi 的计算方法
4.注意力机制的优缺点
attention的优点
1.参数少:相比于 CNN、RNN ,其复杂度更小,参数也更少。所以对算力的要求也就更小。
2.速度快:Attention 解决了 RNN及其变体模型 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
3.效果好:在Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。

若有收获,就点个赞吧
0 人点赞
