1、Embedding技术
现实信息(语义、文本、视图等)是一种非结构化的数据信息,是不可以直接被计算的。
现实信息表示的作用就是将这些非结构化的信息转化为结构化的信息,这样就可以针对现实信息做计算,来完成诸如现实文本信息分类,情感判断等任务。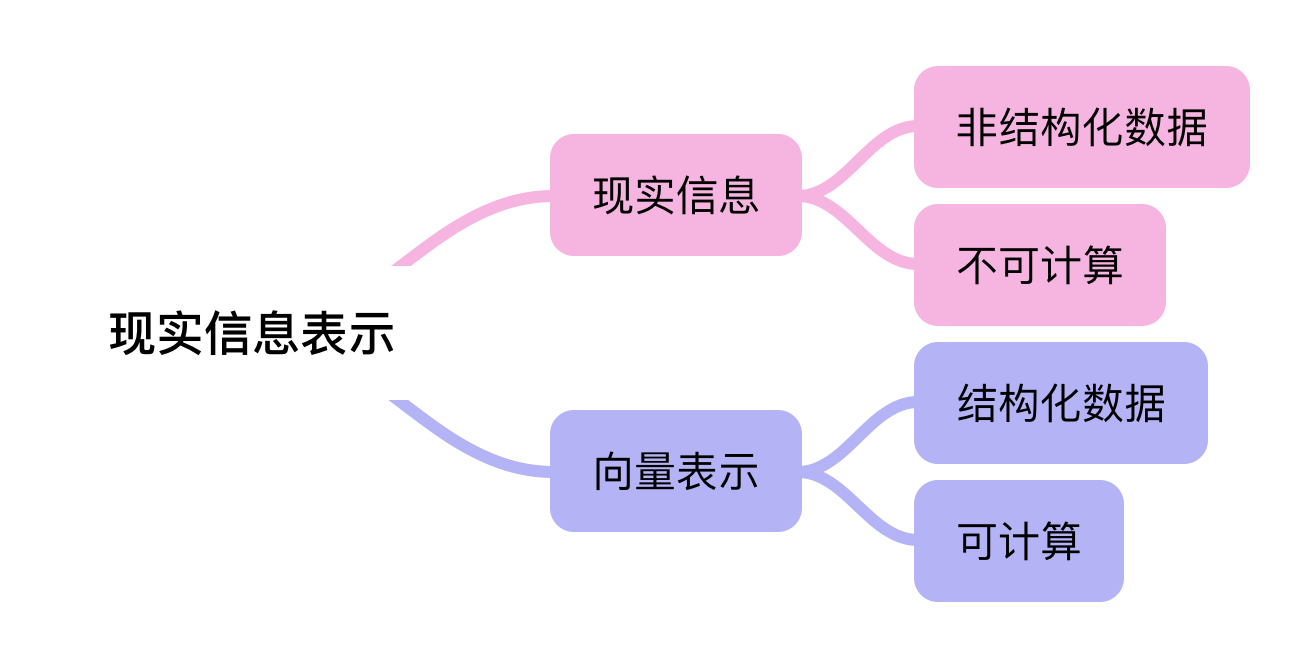
Embedding(嵌入)是拓扑学里面的词,一种把对象 (object) 映射 (map) 为实数域向量 (vector) 的技术。
Embedding 是一个将离散变量转为连续向量表示的一个方式。在神经网络中,Embedding是非常有用的,因为它不光可以减少离散变量的空间维数,同时还可以有意义的表示该变量。
Embedding有以下 3 个主要目的:
在 Embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。作为监督性学习任务的输入。用于可视化不同离散变量之间的关系。
Embedding解决的是”将现实问题转化为数学问题“,是人工智能非常关键的一步。将现实问题转化为数学问题只是第一步,后面还需要求解这个数学问题。所以 Embedding 的模型本身并不重要,重要的是生成出来的结果——信息向量。因为在后续的任务中会直接用到这个信息向量。
2、文本信息表示
文本信息是现实信息的一种,Word Embedding是Embedding的词嵌入技术,文本表示的方法有很多种,Word Embedding只是其中一种。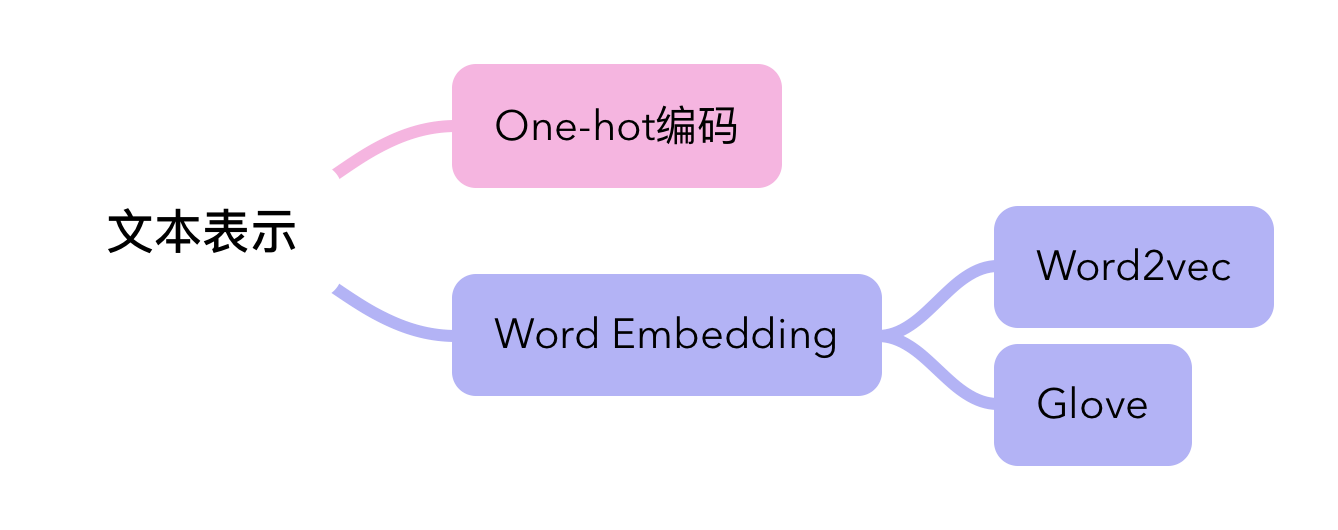
2.1、One-hot编码
假如计算的文本中一共出现了4个字:我、爱、中、华。向量里每一个位置都代表一个字,用 one-hot 来表示就是:
我:[1,0,0,0]爱:[0,1,0,0]中:[0,0,1,0]华:[0,0,0,1]

但是在实际情况中,文本中很可能出现成千上万个不同的词,这时候向量就会非常长。其中99%以上都是 0。
One-hot编码的缺点如下:
对于具有非常多类型的类别变量,变换后的向量维数过于巨大,且过于稀疏。计算和存储的效率都不高。映射之间完全独立,并不能表示出词语之间的关系。
2.2、Word Embedding词嵌入
Word Embedding词嵌入是文本表示的一类方法,目的是获得Word Embedding词向量。
词嵌入百度百科:
词向量(Word embedding),又叫Word嵌入式自然语言处理(NLP)中的一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。 从概念上讲,它涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。
生成这种映射的方法包括神经网络,单词共生矩阵的降维,概率模型,可解释的知识库方法,和术语的显式表示 单词出现的背景。
当用作底层输入表示时,单词和短语嵌入已经被证明可以提高NLP任务的性能,例如语法分析和情感分析。
Word Embedding与One-hot编码方式相比,有几个明显的优势:
可以将文本通过一个低维向量来表达,避免了one-hot那么长。语意相似的词在向量空间上也会比较相近。通用性很强,可以用在不同的任务中。
我、爱、中、华的例子:
3、Word Embedding 算法
Word2vec和GloVe是两种主流的Word Embedding 算法。
3.1、Word2vec
3.1.1、Word2vec
Word2vec 是 Word Embedding 的方法之一,是一种基于统计方法来获得词向量的方法,他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
Word2vec百度百科:
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
3.1.2、CBOW和Skip-gram两种训练模式
CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),是Word2vec 的两种训练模式。下面简单做一下解释:
CBOW
通过上下文来预测当前值。相当于一句话中扣掉一个词,猜这个词是什么。
Skip-gram
用当前词来预测上下文。相当于给一个词,猜前面和后面可能出现什么词。
3.1.3、优缺点
优点:
由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)比之前的 Embedding方法维度更少,所以速度更快通用性很强,可以用在各种 NLP 任务中Word2vec在相似度计算上效果不错
缺点:
由于词和向量是一对一的关系,所以多义词的问题无法解决。Word2vec是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化。
3.2、GloVe
GloVe 是对 Word2vec 方法的扩展,它将全局统计和 Word2vec 的基于上下文的学习结合了起来。
理论上,其他现实信息(语义、视图等)也可以使用类似文本相关的文本信息标识法去处理。

若有收获,就点个赞吧
0 人点赞
