断言作业答案
# 接口地址 http://49.233.108.117:28019/swagger-ui.html#/import requests# 导入已经编写好的生成手机号码的函数from common.utils import generate_phoneimport randombase_url = "http://49.233.108.117:28019"# 注册,登录使用的是同一个手机号码 定义变量phone = generate_phone()testdata ={"token":"", # token,"gid": 0 # 商品id}def test_user_register():"""用户注册:return:"""url = base_url+"/api/v1/user/register"body_data = {"loginName": phone,"password": "123456"}# 发送请求r = requests.post(url,json=body_data)print(r.json())# 添加断言# code为200assert r.status_code == 200assert r.json()['resultCode'] == 200# msgassert r.json()['message'] == 'SUCCESS'def test_user_login():"""用户登录。 登录使用的手机号跟注册是同一个号码:return:"""url = base_url+"/api/v1/user/login"body_data = {"loginName": phone,"passwordMd5": "E10ADC3949BA59ABBE56E057F20F883E"}r = requests.post(url,json=body_data)print(r.json())# 断言# code 断言assert r.status_code == 200assert r.json()['resultCode'] == 200# msgassert r.json()['message'] == 'SUCCESS'# 提取变量值 tokentestdata["token"] = r.json()["data"]def test_search():"""搜索商品 需要token:return:"""url = base_url+'/api/v1/search'query_data = {"keyword":"iphone"}header={"token":testdata["token"]}# 搜索条件为 iphoner = requests.get(url,params=query_data,headers=header)# 断言# 所有搜索结果中都包含iphone# 拿到所有的商品信息allgoods = r.json()["data"]["list"]# 循环所有商品的时候for good in allgoods:# 拿到每个商品的名称goodname = good["goodsName"]print('商品的名称',goodname) # 因为返回结果中有大小写字母混合的场景。使用字符串转换大写方法assert 'iphone'.upper() in goodname.upper() # upper 将字符串转为大写# 将价格大于 5500 的商品id 随机抽取一个作为变量# 将所有价格大于5500 的商品id放在一个列表中gids = []for good in allgoods:if good["sellingPrice"] > 5500:gids.append(good["goodsId"])print("所有商品价格大于5500的商品id",gids)testdata["gid"] = random.choice(gids)def test_add_cart():"""添加购物车:return:"""url = base_url+"/api/v1/shop-cart"body_data = {"goodsCount": 1,"goodsId": testdata["gid"] # 商品id}header = {"token":testdata["token"]}r = requests.post(url,json=body_data,headers=header)print(r.json())# 断言 添加成功assert r.status_code == 200assert r.json()['resultCode'] == 200# msgassert r.json()['message'] == 'SUCCESS'
参数化
在接口测试,测试单接口时,需要针对接口的 不同场景来进行测试。场景有正常场景,异常场景,不同的场景测试的数据不一样,结果也不一样。·比如登录接口,除了使用正确的用户名和密码进行登录测试,错误的用户名和密码也需要测试。测试数据比较多,所以可以将将数据保存在文件中进行测试 。
pytest 参数的基本样例
import pytest@pytest.mark.parametrize("n",[0,10,20])def test_n(n):print("n的值",n)
上面代码运行的时候, 会自动生成3个测试用例。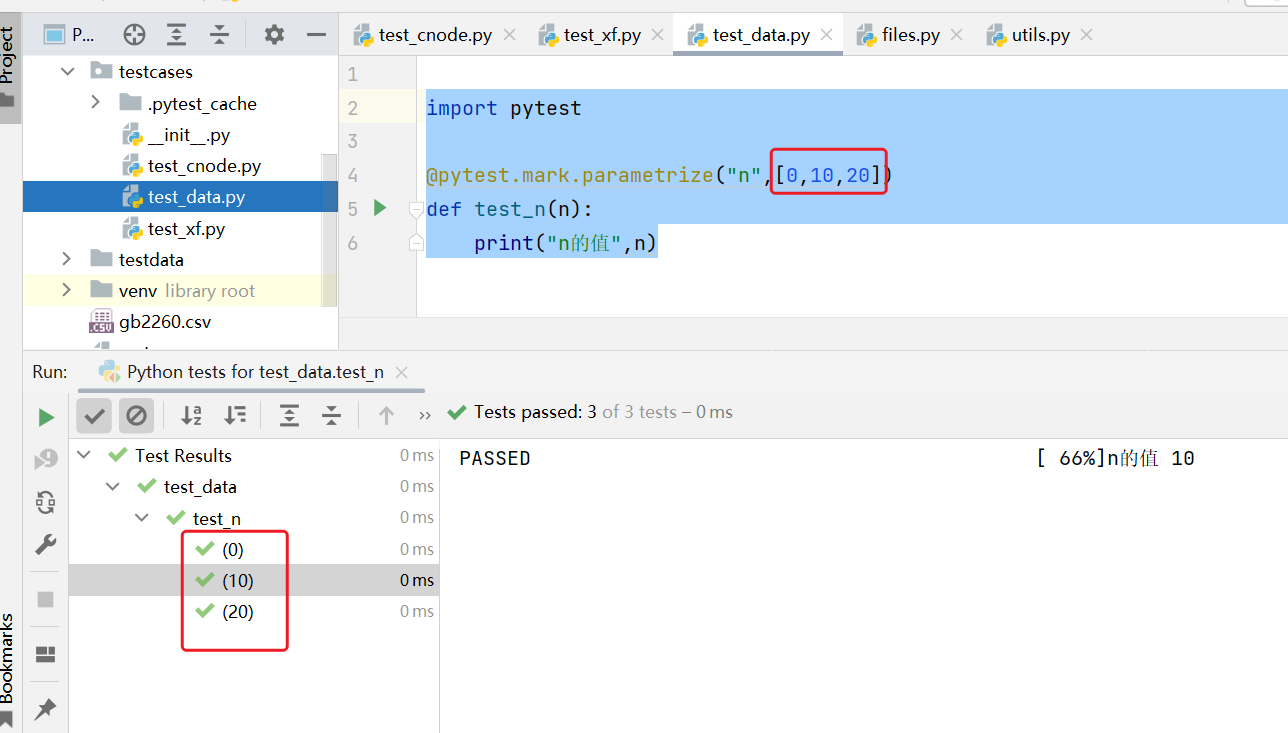
- @pytest.mark.parametrize 这个是固定写法 表示参数化,
- “n” n可以随意命名。 但是要跟下面 测试用例中的参数 n保持一致
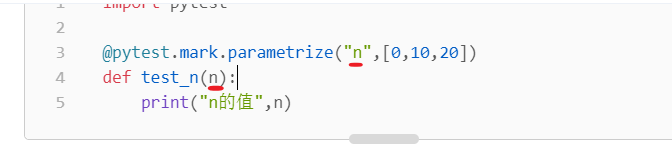
- [0,10,20] 这个是测试数据,必须将测试数据放在一个list中,有多少条数据,执行的时候会自动执行多少次,执行的时候会从list中去取每一条数据。
多个参数进行参数化
测试接口的时候,请求的数据有多个字段。也可以进行参数化。
将测试数据放到 列表中。
# 测试登录,需要用户名和密码两个参数@pytest.mark.parametrize("name,passwd",[("xiaming","123456"),("","123456"),("xiaoming",""),("","")])def test_login(name,passwd):print("用户名",name )print('密码',passwd)
运行,可以看到执行结果。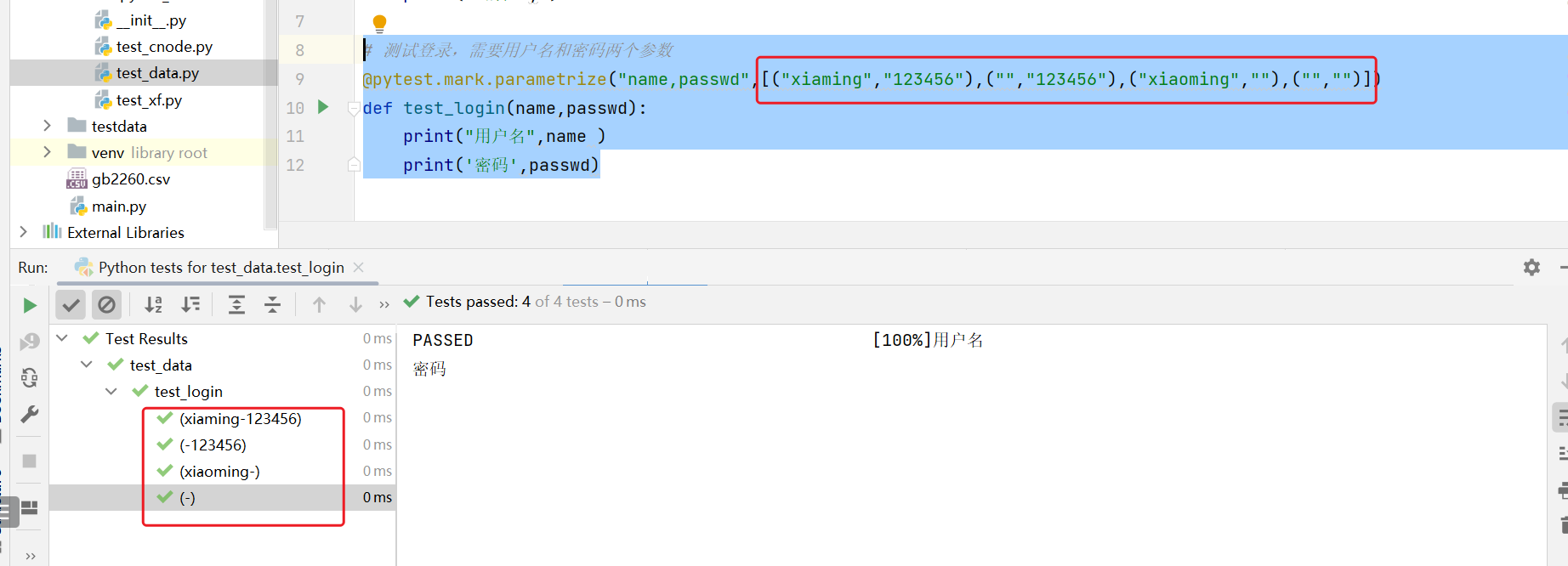
在进行测试数据参数化的时候,因为数据直接写在代码中,数据比较多的时候。也可以将数据直接定义在函数外边,直接运行。
import pytestdata = [("zhangsan","123456"),("lisi","123456"),("wangwu","123456")]@pytest.mark.parametrize("username,passwd",data)def test_login_data(username,passwd):print("用户名",username)print("密码",passwd)
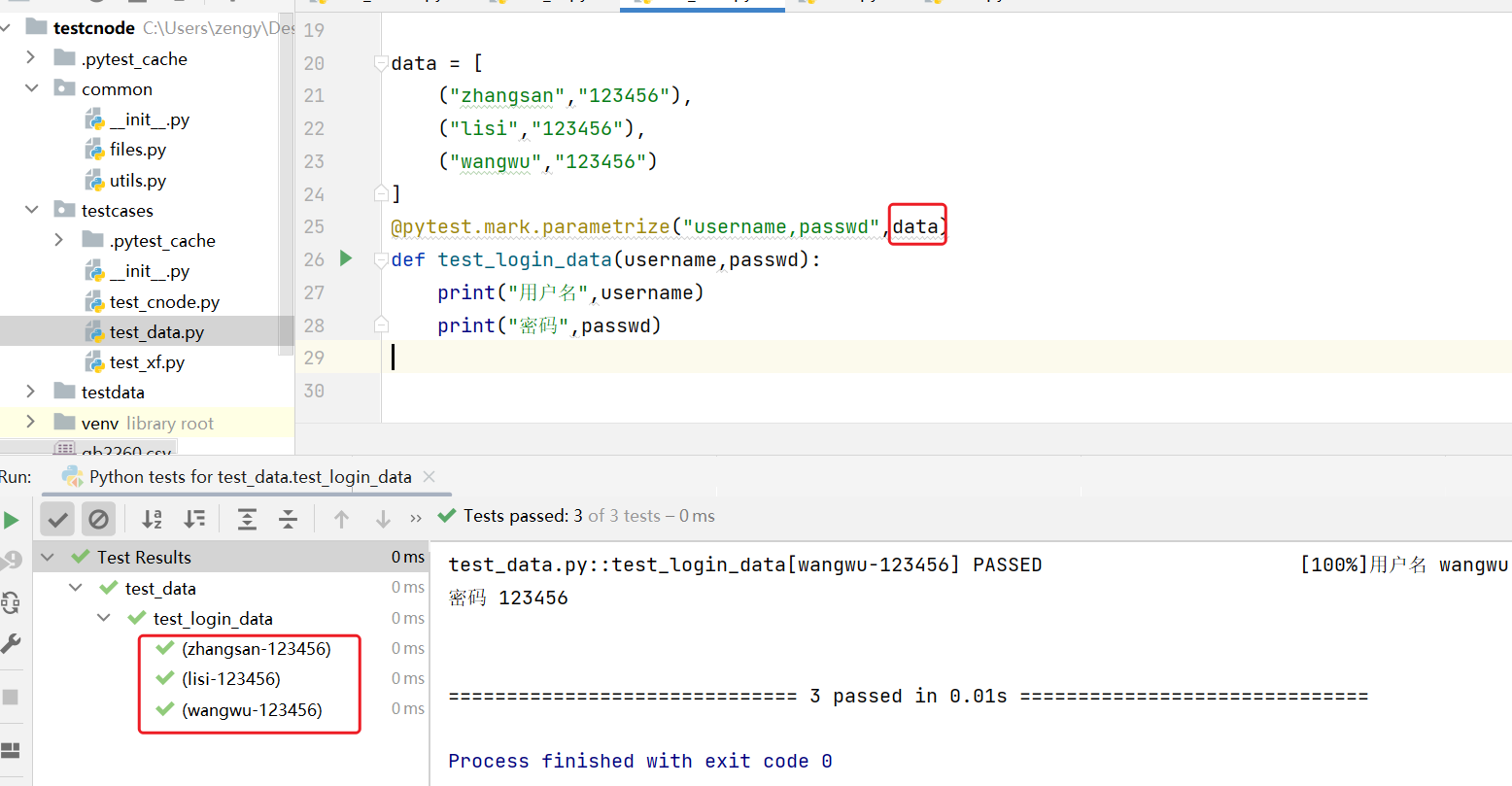
接口中应用
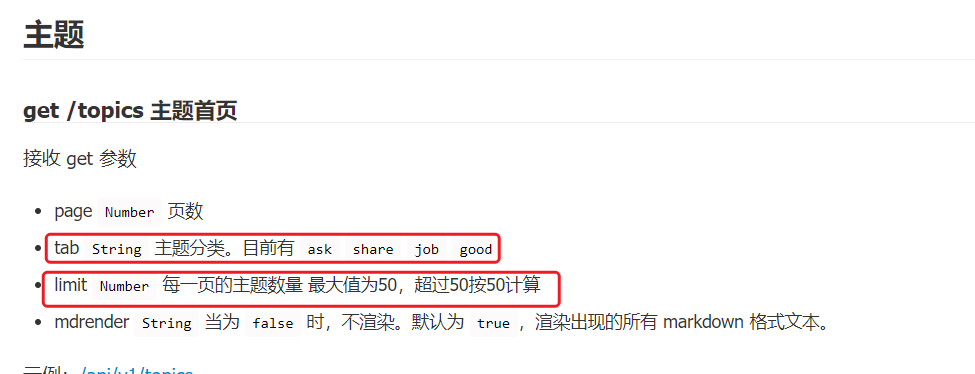
在cnode 社区 主题首页接口测试中。
测试点:
- tab的值 分别可以是 ask, share ,job, good
当tab的值分别为这四种中的一种时,服务器返回的结果所有内容的标题跟上面选择的保持一致。
- limit 最大值为 50,最小值为1,超过50按照50计算
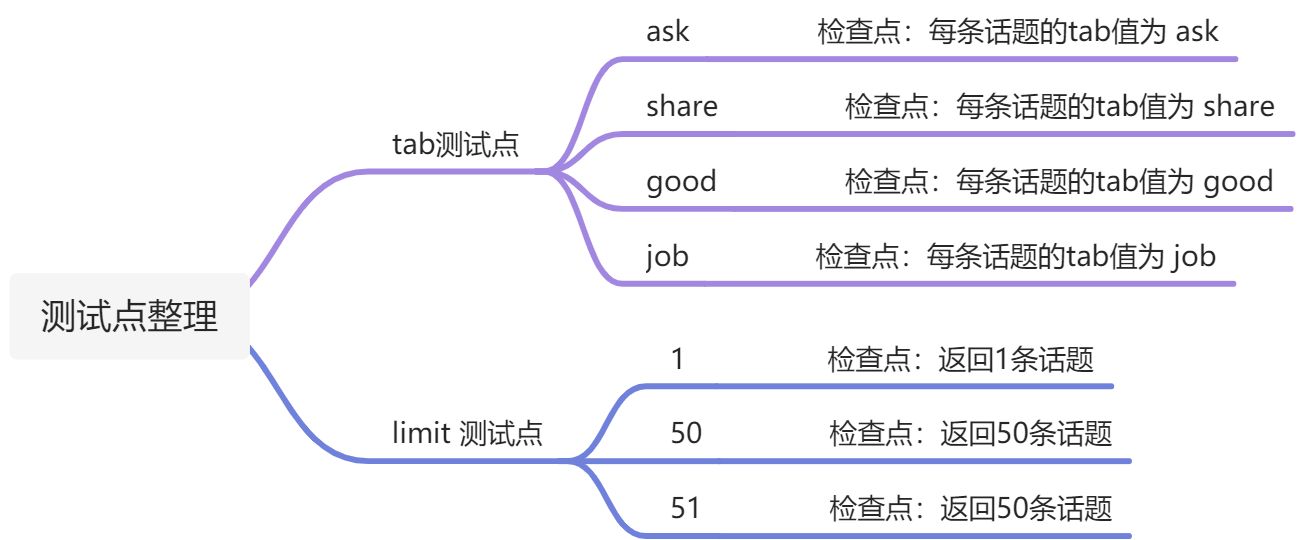
针对limit的测试点 编写测试代码
import requestsimport pytestlimitdata = [(1,1), # 当limit值为1 返回结果中只有1条数据(50,50), # 当limit值为50 返回结果中只有50条数据(51,50), # 当limit值为51 返回结果中只有50条数据]@pytest.mark.parametrize("limit,expect_len",limitdata)def test_topic_index(limit,expect_len):print(f'当limit字段值为{limit}时,期望结果为服务器返回结果数据长度为{expect_len}')url = "http://47.100.175.62:3000/api/v1/topics"querydata = {"limit": limit}r = requests.get(url,params=querydata)print(r.json())# 添加断言,不同请求数据返回结果不同assert len(r.json()["data"]) == expect_len
执行结果
针对 tab 值设置测试用例
import requestsimport pytesttabdata = ["ask","good","job","share"]@pytest.mark.parametrize("tab",tabdata)def test_page_tabdata(tab):print(f'当tab字段值为{tab}时,期望结果为服务器返回结果tab值都是{tab}')url = "http://47.100.175.62:3000/api/v1/topics"querydata = {"tab": tab}r = requests.get(url, params=querydata)print(r.json())# 添加断言,不同请求数据返回结果不同for topic in r.json()["data"]:assert topic["tab"] == tab
上面的代码 将 tab 和 limit 分开来测试,在实际的业务场景中,有些接口要测试的字段笔记多,拆开来做,用例的量也会很大。所以在测试过程中最好放在一个里面,统一来测试。
- 当 tab 的值 为 ask的时候, limit 可以取的值为 1,50,51
- 当 tab 的值 为 share的时候, limit 可以取的值为 1,50,51
- 当 tab 的值 为 job的时候, limit 可以取的值为 1,50,51
- 当 tab 的值 为 good的时候, limit 可以取的值为 1,50,51
就有不同的排列组合,如果人工来测试,这个工作量是比较大的,但是如果用自动化代码来测,这个就是分分钟就可以搞定的事情。
tab_v = ["ask","share","job","good"]limit_v = [1,50,51]# 将数据排列组合一下test_tab_limit_data = []for tab in tab_v:for limit in limit_v:print(f'当 tab 的值 为 {tab}的时候, limit 可以取的值为 {limit}')test_tab_limit_data.append((tab,limit)) # (tab,limit) 表示元组print("生成测试数据为",test_tab_limit_data)
使用for循环 生成可能测试数据。
上面的代码只是生成测试数据中请求参数的不同组合,在做自动化的时候,还需要生成对应的断言结果。
比如 当tab值为 ask 断言 返回结果中tab值为 ask,当limit的值为1的时候,断言结果为1。
期望最终生成的数据
testdata = [("ask",1,"ask",1), # 输入 ask,1 期望结果 ask 1]
生成测试数据
编写代码 生成多条测试数据,并根据条件添加对应的断言。
tab_v = ["ask","share","job","good"]limit_v = [1,50,51]# 将数据排列组合一下test_tab_limit_data = []for tab in tab_v:for limit in limit_v:expect_tab = tab # 期望的tab值# 需要注意: 当limit = 51, 期望的结果是50if limit >= 51: # limit为51 时候expect_limit = 50 # 设置为50else: # 其他场景expect_limit = limit # 期望的limit 值test_tab_limit_data.append((tab,limit,expect_tab,expect_limit)) # (tab,limit) 元组数据类型print(f'当tab的值为{tab}的时候, limit值为 {limit}, 期望结果中的tab值{expect_tab},期望结果中的limit{expect_limit}')print("生成测试数据为",test_tab_limit_data)
上面的代码中 可以将所有的测试场景数据生成。下一步利用测试数据来进行自动化测试。
tab_v = ["ask","share","job","good"]limit_v = [1,50,51]# 将数据排列组合一下test_tab_limit_data = []for tab in tab_v:for limit in limit_v:expect_tab = tab # 期望的tab值# 需要注意: 当limit = 51, 期望的结果是50if limit >= 51: # limit为51 时候expect_limit = 50 # 设置为50else: # 其他场景expect_limit = limit # 期望的limit 值test_tab_limit_data.append((tab,limit,expect_tab,expect_limit)) # (tab,limit) 元组数据类型print(f'当tab的值为{tab}的时候, limit值为 {limit}, 期望结果中的tab值{expect_tab},期望结果中的limit{expect_limit}')@pytest.mark.parametrize("tab,limit,expect_tab,expect_limit",test_tab_limit_data)def test_home_page(tab,limit,expect_tab,expect_limit):url = "http://47.100.175.62:3000/api/v1/topics"querydata = {"tab":tab,"limit":limit}r = requests.get(url,params=querydata)#断言tab值for topic in r.json()["data"]:assert topic["tab"] == expect_tab# 断言limitassert len(r.json()["data"]) == expect_limit
执行,可以看到执行结果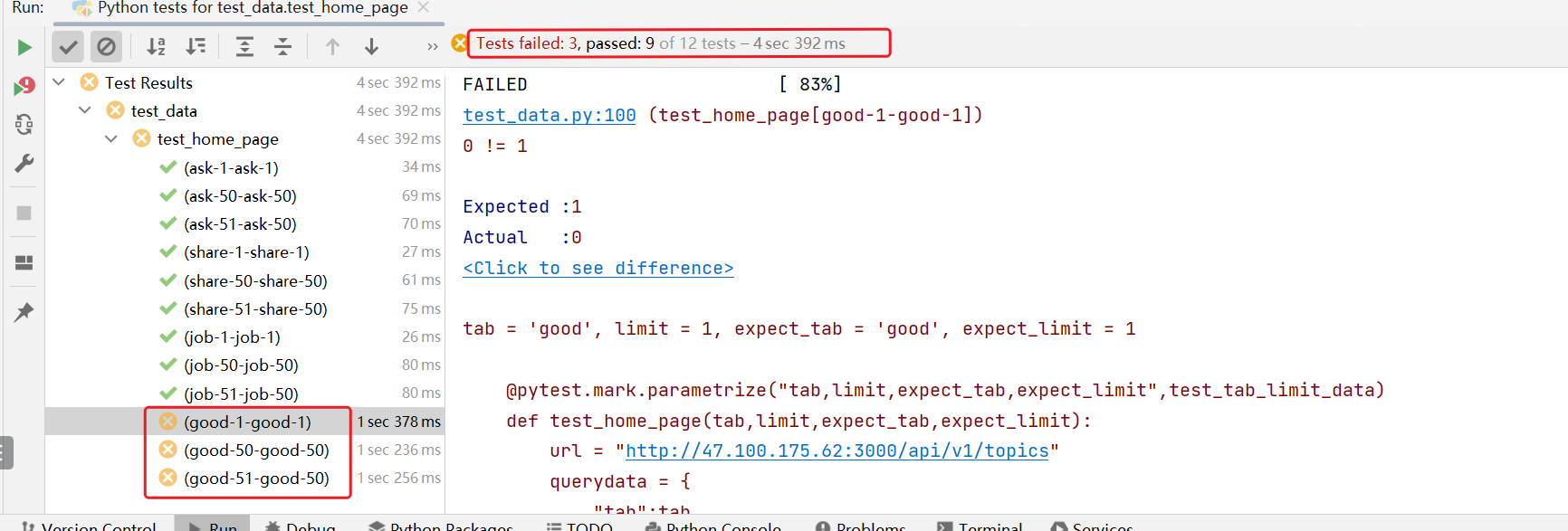
并且,还发现其中有三组数据 有问题。
经过分析: 发现系统中没有精华话题,所有这三个用例失败,通过这样的方式也可以发现被测系统的数据不完整。
csv数据
上面的代码可以生成对应的数据文件,如果你在公司没有使用Python做接口自动化,也可以使用Python代码生成测试数据保存到csv文件中,也可以使用其他工具做自动化,比如Postman,JMeter。
tab_v = ["ask","share","job","good"]limit_v = [1,50,51]# 将数据排列组合一下test_tab_limit_data = []for tab in tab_v:for limit in limit_v:expect_tab = tab # 期望的tab值# 需要注意: 当limit = 51, 期望的结果是50if limit >= 51: # limit为51 时候expect_limit = 50 # 设置为50else: # 其他场景expect_limit = limit # 期望的limit 值test_tab_limit_data.append((tab,limit,expect_tab,expect_limit)) # (tab,limit) 元组数据类型print(f'当tab的值为{tab}的时候, limit值为 {limit}, 期望结果中的tab值{expect_tab},期望结果中的limit')print("生成测试数据为",test_tab_limit_data)# 写入到 csv 文件中import csvwith open('home_topics.csv',mode='w',encoding='utf8',newline='') as file:w = csv.writer(file)# 写入标题w.writerow(["tab","limit","expect_tab","expect_limit"])# 写入数据for line in test_tab_limit_data:#每一种测试场景写入一行数据w.writerow(line)
运行成功之后,可以看到在项目根目录下生成对用 csv文件。
将项目整理合理的规划一下, 生成的测试数据可以放在专门的文件中。
添加common/datatool.py
在做参数化测试的时候,生成对应的测试数据方法 都放在 datatool.py文件中。
对应的文件目录
"""针对不同的接口 生成对应的测试数据提供测试数据"""def home_page_data():tab_v = ["ask", "share", "job", "good"]limit_v = [1, 50, 51]# 将数据排列组合一下test_tab_limit_data = []for tab in tab_v:for limit in limit_v:expect_tab = tab # 期望的tab值# 需要注意: 当limit = 51, 期望的结果是50if limit >= 51: # limit为51 时候expect_limit = 50 # 设置为50else: # 其他场景expect_limit = limit # 期望的limit 值test_tab_limit_data.append((tab, limit, expect_tab, expect_limit)) # (tab,limit) 元组数据类型# print(f'当tab的值为{tab}的时候, limit值为 {limit}, 期望结果中的tab值{expect_tab},期望结果中的limit')# print("生成测试数据为", test_tab_limit_data)return test_tab_limit_data
在测试用例直接通过调用 函数生成的数据来进行测试
"""定义所有的单接口测试"""import pytestimport requestsfrom common.datatool import home_page_datahome_data = home_page_data()@pytest.mark.parametrize("tab,limit,expect_tab,expect_limit",home_data)def test_home_page(tab,limit,expect_tab,expect_limit):url = "http://47.100.175.62:3000/api/v1/topics"querydata = {"tab":tab,"limit":limit}r = requests.get(url,params=querydata)#断言tab值for topic in r.json()["data"]:assert topic["tab"] == expect_tab# 断言limitassert len(r.json()["data"]) == expect_limit
作业
测试新建主题的不同场景。
def create_topic_data():pass
def test_create_topics():pass
作业分析
分析每个参数可能的场景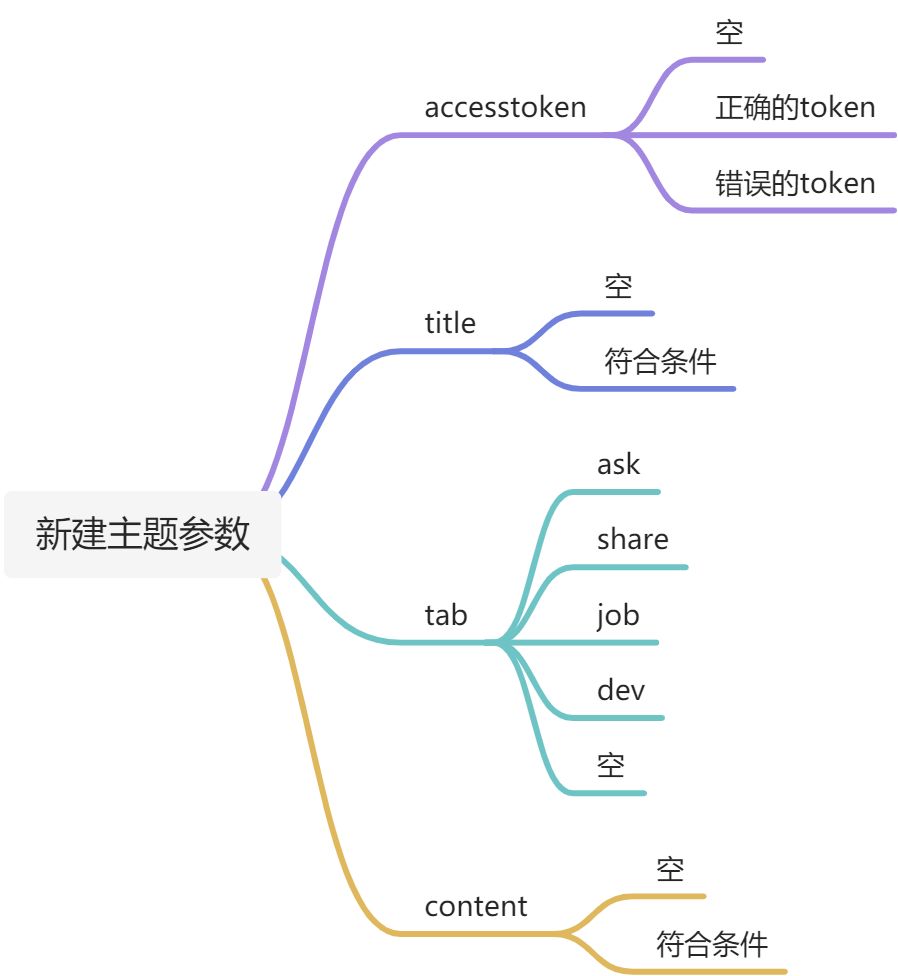
不同的数据 需要不同相应结果。
| 前提 | 条件 | 成功/失败 | 检查点 |
|---|---|---|---|
| 无 | accesstoken 值为”” | 失败 | errormsg:错误的accesstoken |
| 无 | accesstoken 值为错误 | 失败 | errormsg:错误的accesstoken |
| accesstoken值正常 | title空 | 失败 | errormsg:标题不能为空 |
| accesstoken值正常 title值正常 | ask 为空 | 失败 | errormsg:必须选择一个版块 |
| accesstoken值正常 title值正常 tab值正常 | content为空 | 失败 | errormsg:内容不可为空 |
| 所有值都符合条件 | 成功 | success:true |
生成对应的测试数据。
def create_topic_data():tokens = ["","xxxxxxyyyy","e18de36f-d9ce-47e6-a2aa-1cf6508ec10b"]titles = ["","helloworld"]tabs = ["ask","share","job","dev",""]contents = ["","helloworld"]testdata = []# 组合数据for token in tokens:for title in titles:for tab in tabs:for content in contents:# 设置对应的断言expect_success = Falseif not token == "e18de36f-d9ce-47e6-a2aa-1cf6508ec10b":expect_err_msg = "错误的accessToken"elif title == "":expect_err_msg ="标题不能为空"elif tab == "":expect_err_msg = "必须选择一个版块"elif content == "":expect_err_msg = "内容不可为空"else:#只有当发帖成功的时候 success 的结果才会 Trueexpect_success = True# 发帖成功的时候,返回结果的数据类型跟失败的类型不一样,只对success 进行断言即可expect_err_msg = ""testdata.append((token,title,tab,content,expect_success,expect_err_msg))return testdataif __name__ == '__main__':data = create_topic_data()print(data)
编写测试用例
topic_data=create_topic_data()#数据的格式为 (token,title,tab,content,expect_success,expect_err_msg)@pytest.mark.parametrize('token,title,tab,content,expect_success,expect_err_msg',topic_data)def test_create_topics(token,title,tab,content,expect_success,expect_err_msg):url = "http://47.100.175.62:3000/api/v1/topics"body_data = {"accesstoken":token,"title":title,"tab": tab,"content":content}r = requests.post(url,json=body_data)# 进行断言# 1. success 结果断言assert r.json()["success"] == expect_success# 只有当 发帖失败的时候才会对错误提示信息进行断言if expect_success == False:assert r.json()["error_msg"] == expect_err_msg
运行接口。
可以发现接口中 还有两个 bug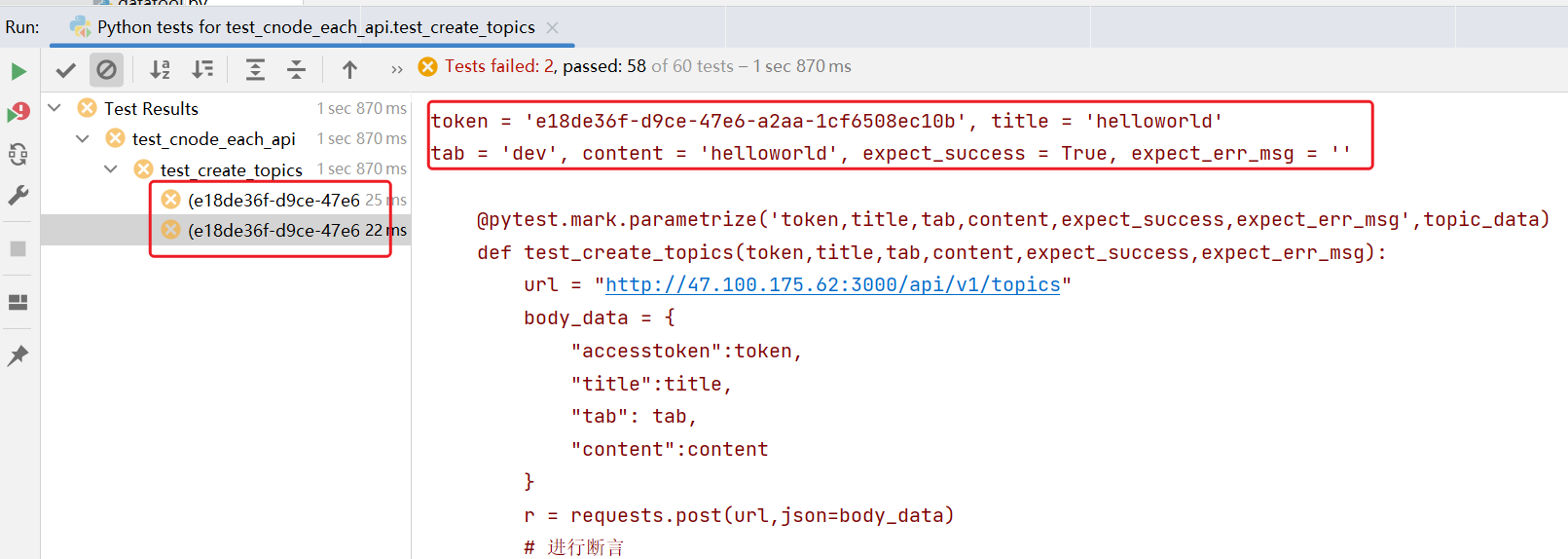

若有收获,就点个赞吧
0 人点赞
