项目相关问题
- postman,jmeter 都可以做接口测试, 以及接口的自动化,为什么还要使用Python来做?
使用这些工具来做接口测试,会受到工具本身的限制, 比如在Postaman 在做接口的时候不能连接数据库,在JMeter中可以连接数据库,是因为JMeter中提供了jdbc的操作。如果工具没有提供这些功能,我们就不能使用。
但是使用Python代码,如果想要实现什么功能,都可以通过代码的方式来实现,比如做接口的参数化功能,在Postman和JMeter 中只能通过CSV文件来进行,但是你使用 代码就可以支持更多的格式。比如可以使用json格式,yaml,Excel格式,也可以直接通过数据库的方式来实现。
- 在使用Python的时候,如何处理Windows文件路径中的\问题?
两种方法:
- 使用双 \
- 字符串 前添加 r
- 列表和元组的区别是什么?
定义的方式不同: 列表使用 [] 元组使用 ()
列表中的数据可以进行修改, 但是元组中定义好的数据不能进行修改。
相同的地方:
都可以通过使用索引值来访问里面的数据。
nums = [1,2,3,10,9] # 列表n = (1,2,3,10) # 元组# 通过索引值来访问元素中的字段值。print(n[-1]) # 10print(len(nums)) # 5print(len(n)) # 4# -1 表示最后一个print(nums[-1]) # 9# [1] 表示第2个 [0] 表示第一个print(nums[1]) # 2# 修改列表中元素值nums[3] = 100print(f"修改之后的列表值:{nums}") # 修改之后的列表值:[1, 2, 3, 100, 9]# 修改元组中的元素 下面这句会报错。n[3] = 100
- python中基本数据类型有哪些?
字符串 str 数字(int,float) 布尔(True,False),None 空值
列表list 元组 tuple 集合 set 字典 dict
- 字典和集合的区别是什么?
集合类型为set, 字典类型为 dict。
集合都是以值的形式保存,集合中的值无序,并且会自动去重。
字典中是以 key(键):value(值)对的形式保存。 字典中 key(键) 是不重复的。
访问字典中的值是以[key]的方式来访问。
- 如何给别人介绍自己的python编码能力?
参考:
了解python的基本语法,能够看到基础代码,知道python的基本数据类型,熟悉python的循环 以及一些常用模块 比如 csv, random,能写基本的代码,比如我们在接口测试注册接口,每次需要生成一个手机号,通过python编写函数使用random模块以及循环 实现了这样的功能。也可以使用Python来做实现生成随机身份证号码的功能, 也可以编写代码生成随机的姓名满足测试过程中一些数据的需要。
熟悉 接口自动化测试的一般流程,能够基本使用 requests+pytest+git+csv+Jenkins+pytest-html 进行接口的自动化测试工作。使用requests库模拟发送请求,pytest用来管理自动化测试用例,csv存放测试数据,pytest-html 生成测试报告。Jenkins做自动化的持续集成。
项目的代码基本目录
- common 包 存放一些常用的函数,比如生成测试数据,生成随机的手机号
- testcases 包 存放自动化测试用例,用例分开来写
- 流程测试 接口串联 都是用正常场景 单独放在一起
- 单接口 每个接口单独测试 需要做参数化 单独放在一起
- reports 存放测试报告
- testdata 存放测试数据,比较将数据放在csv文件,统一都放在这里。
- main.py 项目Jenkins中运行的时候 通过这个文件定义的代码执行所有的用例。
- 在python接口测试中,怎么处理带有Cookie的接口?
如果接口中需要传入cookie,将cookie 值放到放到 字典中,发送请求的时候 ,将这个 带有cookie的字典传给 headers 参数中即可。也就是放在信息头中发送出去即可。
- 在接口自动化测试过程中。如何进行上下游传参?(如何进行接口的串联?)
根据业务,先确定上下游接口之间的关系,找到它们之间关联的参数。在python中,可以通过
- return返回值, 将上游接口操作定义到一个函数中,将结果作为返回值,使用的时候通过调用函数,拿到对应的返回值进行传参。这种使用的时候 每次使用都需要调用。
- 通过global 关键字,将局部变量设置为全局变量。下游接口中引用这个变量。这种方式 如果项目比较大, 变量比较多,引用的时候没有代码提示 容易出错。
- 通过将要传参的值写入到 文件中,通过读取文件来获取值,进行上下游传参,这种方式需要频繁读取文件,性能上不是很高,引用变量的时候也没有代码提示。
- 使用字典数据类型,上游中将对应的数据更新到字典相应的字段里面,下游通过引用字典中字段的数据进行传参。
我在我们项目中 主要使用字典这种方式。
- 接口中的断言都有哪些?
python 中直接使用 assert 添加断言。断言的数据主要内容有:
- 常见的有状态码断言
- 服务器返回结果的主要字段进行断言
- 接口之间有串联关系的时候,也会在下游接口中断言上游的结果。 举个例子:电商中生成订单 接口服务器会返回一个订单的id,这个id的值是不固定,每次都是唯一。 查看订单接口会返回所有的订单,在查看订单接口中需要对返回的结果进行断言,有一个非常重要的断言: 查看订单接口②返回的所有订单号中一定包含 生成订单接口①,
这类接口添加断言的主要思路:
1. 使用上下游传参的方式 将上游接口①返回的结果定义 字典中对应字段的值。1. 下游接口② 使用for循环先将所有的id存放在列表ids,然后 上游传递过来的订单号 通过 in 来判断在 ids中.
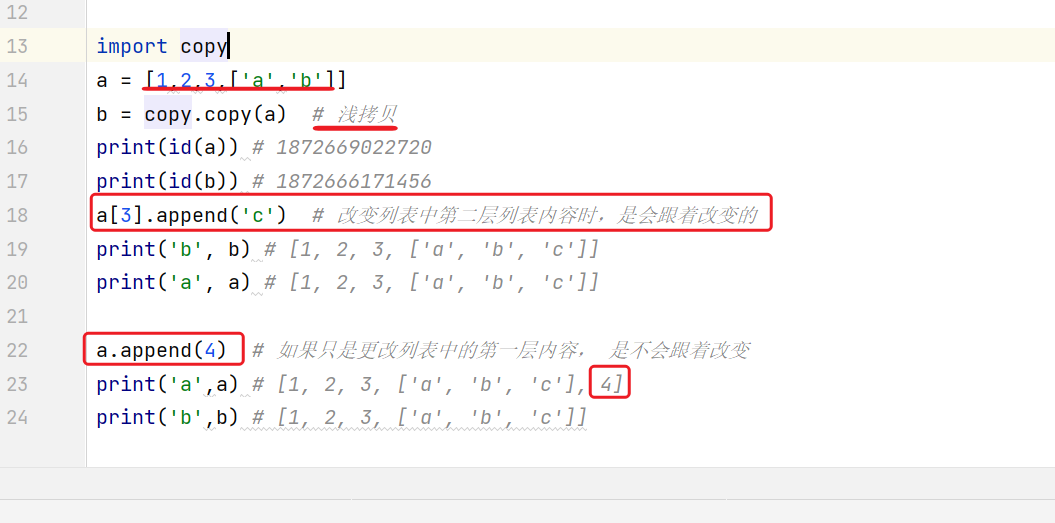
- 深拷贝和浅拷贝的区别?(面自动化岗位)
- 深拷贝 的两个值 内存地址不一样,两个值之间不会相互影响,他们是相互独立的。
- 浅拷贝 的两个值内存地址不一样,只能将第一层数据拷贝过去,第一层数据是相互独立的,但是第二层数据是相互一致的。比如在列表中嵌套的还有列表,更改第二层(列表中的列表)时,数据是一样的。
- 直接赋值,直接赋值的话,数据是会跟着改变的。
- 深拷贝 的两个值 内存地址不一样,两个值之间不会相互影响,他们是相互独立的。
如何做接口的参数化?
使用pytest的参数化功能
pytest内置的装饰器 @pytest.mark.parametrize
给装饰器传入对应的测试数据
测试数据可以
使用自定义的函数 自动生成
将数据保存到csv文件中,通过读取csv文件内容来做参数化



若有收获,就点个赞吧
0 人点赞
