C 语言面向对象的封装方式
C语言是面向过程的编程语言,一个程序的运行逻辑就是由一个个函数调用构成,函数里面会操作各种各样的数据结构。
因此,函数和数据结构,是C程序中的两大组成部分。
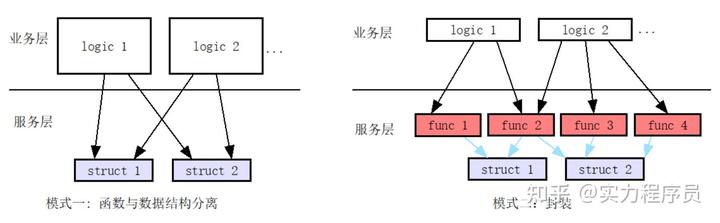
通常,我们接触的大多数C程序,代码的逻辑组织关系就如下图所示: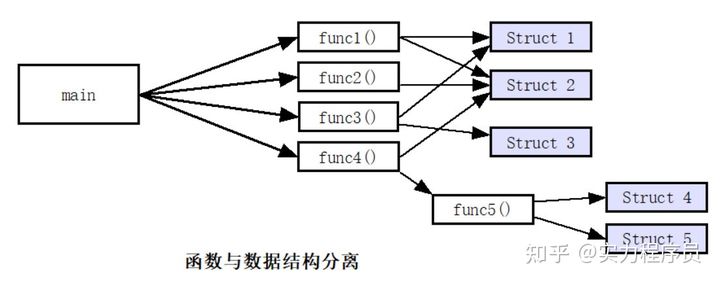
这种设计方式中,数据结构与函数是一种松耦合关系,数据结构的内部成员,对所有函数都是可见的,都是可读写的。一个函数会直接操纵多个数据结构,从而实现特定的业务逻辑。
这种设计的优点是:简单。数据结构和函数可以分开进行设计,适用于小型项目、快速构建原型。
但这种方式最大的问题是:当数据结构需要变化时,访问这个数据结构的大量函数都需要相应改动,工程量太大,在大型项目中几乎无法进行。需求变化时,会出现这类场景,在对历史代码进行重构时,也会出现这种场景。
因此,在大型项目中,更推荐的方式是封装。封装这个术语,常见于面向对象的编程语言中,其核心思想是将数据结构的内部构成、函数逻辑的实现对外界屏蔽,外界仅能通过其提供的接口函数来实现对数据结构的操纵、对特定逻辑的调用。
封装,即包括了对数据结构的封装,也包括了对函数逻辑的封装。
C语言,尽管不是面向对象的编程语言,但依然可以实现优秀的封装能力。
采用封装的设计思想后,C程序的代码逻辑组织关系就变成了: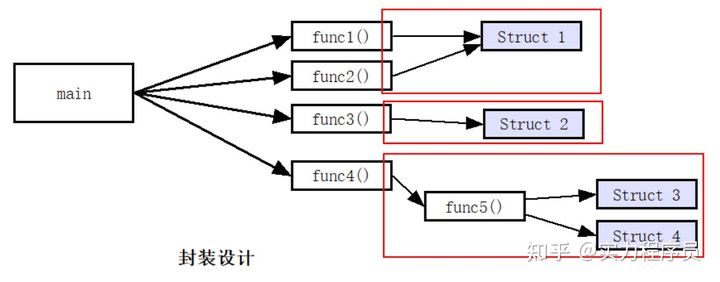
上图中的红色框,就是封装。所有的数据结构,都被对应的函数封装起来了。外界无法直接访问这些数据结构的内部成员,只能通过暴露的接口函数来操纵这些数据结构。
所有的内部实现函数,也都对外界不可见,外界只能通过暴露的接口函数来调用相应的业务逻辑。
封装方式,对大型项目的演进是极度重要的!只要接口函数不变,那么每个子系统、每个模块内部的数据结构和内部实现,可以独立进行重构和演进,对别人没有任何影响!
而前一种方式下,一个数据结构变化了,几乎就是牵一发而动全身,别人都受影响,都得相应进行代码修改!
封装方式,对接口设计提出了更高的要求。如何切分程序的各部分职责,如何高内聚低耦合地设计接口函数,从接口函数名、参数和返回值中都屏蔽掉内部的具体实现,这些都需要高水准的设计。
一个大型项目的生命周期,会持续多年甚至数十年。良好的设计,会使得大型项目可以跟随业务需求而快速演进,最为关键的一点是每个子系统、每个模块可以独立进行演进,而无需各个团队之间任务的互相影响、前置任务等待等各种问题。能让各个团队能够充分并行工作,这对大型项目的进度和质量控制都是极度关键的。
示例
前一篇文章《C 语言面向对象的封装方式》,我介绍了 C 语言编程常见的两种代码组织方式:1)函数和数据结构分离 2)封装,从原理上讲述这两种方式的根本区别。
大型项目中,推荐采用封装的方式,有利于团队协作和每个模块独立演进。
本文,给出一个代码示例,具体展示这两种方式在代码实现上的差别。
业务场景描述如下:
对于数据库、文件系统、存储系统等,数据通常以页 (Page) 为单位,在数据文件中进行组织。服务进程以页为最小 IO 单位从磁盘上读出,并在内存中缓存这个页面。后续业务过程如果读取的数据在这个页中,则直接从内存页获取数据。如果要写入新数据,或者要更改原来的数据,则需要找到剩余空间能满足新写入数据大小的 Page,然后在目标页中进行写入或者数据修改的动作。由于页上可能会有并发读写操作,因此需要注意加锁。
一个数据页 (Page) 的内部结构,示例如下:(PostgreSQL 的数据页)
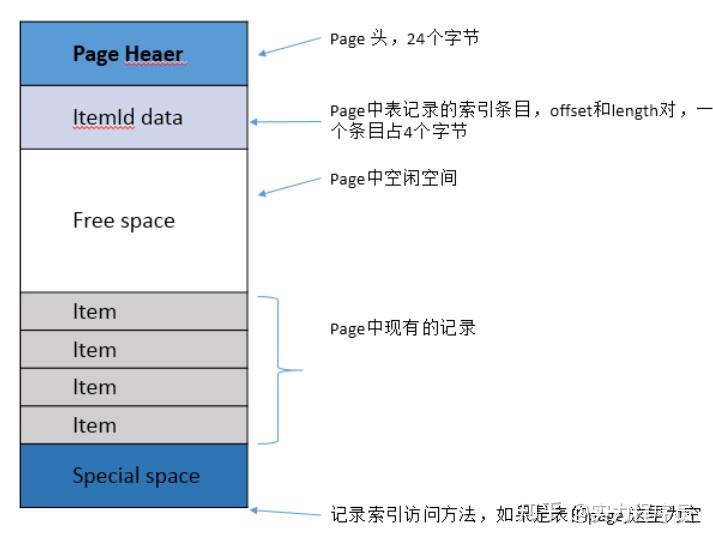
PageHeader 是页头部的控制信息,其结构如下:
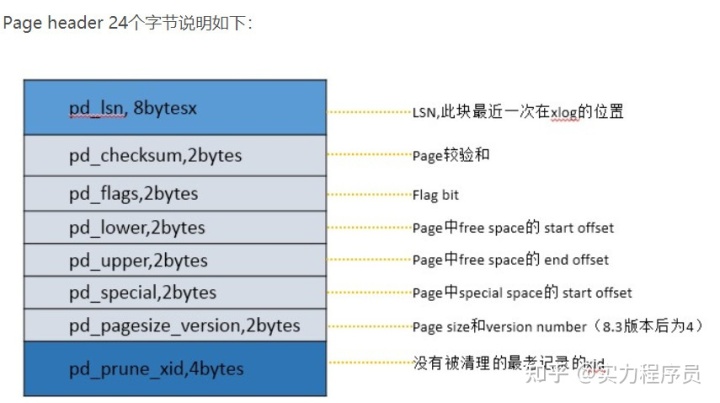
我们实现数据写入 (insert) 和 scan 过滤两种场景,看用两种不同的代码组织方式,在代码实现上的差别(代码进行了简化,不考虑事务等复杂因素)。
(方式一) 函数和数据结构分离
调用者的逻辑:
向 Page 中写入一行数据:
int insert_row(...) {// 计算要写入的行所需的空间大小int row_size = ....;// 找到剩余空间满足这个要求的Pagepage_header_t* phpage = find_page(row_size);// 加锁,避免并发写lock_write(phpage);// 写入row headerchar* pbegin = (char*)phpage + pheader->pd_upper - row_size;row_header_t* phrow = (row_header_t*)pbegin;phrow->len = row_size - sizeof(row_header_t);phrow->xxx = ....;// 写入row的各个列数据char* pcol = (char*)phrow + sizeof(row_header_t);memcpy(pcol, ....);....// 找到空闲的itemid槽位item_id_t* pitemid = (item_id_t*)((char*)phpage + sizeof(page_header_t));while (LP_UNUSED != pitemid->flags) pitemid++;// 写入row对应的槽位信息pitemid->offset = (char*)phrow - (char*)phpage;pitemid->LP_NORMAL;// 解锁unlock_write(phpage);return SUCCESS;}
读取page中的各行记录,根据条件过滤(比如 where id > 2)
int scan_row(page_header_t * phpage, filter...) {// 加读锁lock_read(phpage);// 遍历itemid, 只查找有效行item_id_t* pitemid = (item_id_t*)((char*)phpage + sizeof(page_header_t));while (LP_UNUSED != pitemid->flags) {if (LP_NORMAL == pitemid->flags) { // 有效行row_header_t* phrow = (row_header_t*)((char*)phpage + pitemid->offset);// 判断此行是否满足过滤条件......}pitemid++;}// 解锁unlock_read(phpage);}
从上面的数据读写两个函数,我们可以看出,在函数和数据结构分离的模式下的特点:
1)数据结构的内部成员,对调用者都是可见的,都是可读写的;
上例中,page_header_t, item_id_t, row_header_t 这些数据结构内部的成员,调用者都是知道的,并且可以直接读写的。
2)数据结构之间的关系,调用者也是知道的;
上例中,page_header_t 的后面就是一系列 row_id_t, 这些 row_id_t 的后面是空闲空间,每行数据从 page 后面逐个向前分配空间;
3) 调用者根据 1) 和 2) 的信息,自己来编写自己的业务逻辑,对这些数据结构的成员进行读写控制,最终形成各种业务函数。
4)需要多少个业务函数,是调用者来决定的。调用者可以根据业务需求,随时增减业务函数。
这种模式下,需要数据结构保持长期稳定状态。一旦数据结构发生变化,那么调用者设计的各种业务函数,基本都需要修改,哪怕只是把数据结构的一个成员名字修改了,也会导致大量的函数无法通过编译。
而工程实践中,需求变更是常态,尤其是做有技术竞争力的产品,对底层数据结构、实现逻辑进行大幅度优化改进,也是经常发生的。
因此,我们更希望用封装模式,来组织代码。
这两种方式的根本区别,用下图来展示:
在封装的设计下,代码上有了一些显著的变化:
1)数据结构的成员,对调用者不可见。 调用者无法直接对数据结构的成员变量进行读写,只能通过特定的函数来操作这些数据结构。
这些操作函数,是数据结构的设计者提供的,我们把这些操作函数叫接口函数。
2)接口函数,不仅屏蔽掉数据结构的成员变量,还屏蔽掉数据结构之间的关系,甚至有些数据结构调用者根本就不知道其存在。
3)接口函数,是面向使用者进行设计,而非面向底层数据结构进行设计。 对业务场景进行分析,提取共性,进行接口抽象,最终形成接口函数。
4)接口函数的函数名、参数类型和返回值,都要充分体现业务语义,屏蔽底层数据结构的具体实现细节。
再回到对数据页 (Page) 进行读写操作的例子上,我们用封装的思想,重新设计一下代码:
服务层:
1. 数据结构体 page_header_t,item_data_t, row_header_t 的成员结构无需调整,但我们需要把它们的定义放到. c 文件中,这样调用者就不能直接访问他们的成员了。可以用指针,但不能用指针访问其成员。
2. 设计接口函数,封装业务语义,主要有:
写入行:
1) 为了写入,要获取满足空间的页面,返回已经锁定的页面
page_header_t* find_page_for_write(int row_size);
2) 写入 row 数据
int write_row_to_page(page_header_t phpage, void pdata, int row_size);
3)释放锁定的页面
int release_page_for_write(page_header_t* phpage);
读取 page,返回各个行数据:
1)准备扫描 page(内部加读锁)
page_scan_t page_scan_begin(page_header_t* phpage);
2)扫描下一行, 返回 0 表示找到一个有效行
int page_scan_next(page_scan_t pscan, void** prow, int row_size);
3) 结束扫描 (内部释放锁)
int page_scan_end(page_scan_t* pscan);
业务层:
调用者的代码,重新设计为:
int insert_row(...) {// 计算要写入的行所需的空间大小int row_size = ....;// 找到剩余空间满足这个要求的Pagepage_header_t* phpage = find_page_for_write(row_size);// 写入rowint iret = write_row_to_page(phpage, pdata, row_size);// 释放页面iret = release_page_for_write(phpage);return iret;}int scan_row(page_header_t* phpage, filter...) {page_scan_t scan = page_scan_begin(phpage);void* prow = NULL;int row_size = 0;while (!page_scan_next(&scan, &prow, &row_size)) {// 应用filter,判断此行是否满足条件......}page_scan_end(&scan);return SUCCESS;}
我们看到,通过封装,调用者的代码逻辑更加清晰简洁,并且与底层数据结构充分解耦,各自可以独立演化,互相不影响。
因此,大型项目,强烈推荐采用封装的方式进行代码组织设计。

若有收获,就点个赞吧
0 人点赞
