虽然其他语言也实现了async/await,但 Rust 采用了一种独特的方法。Rust 的异步操作主要是 **惰性(lazy)**的。这导致了与其他语言不同的运行时语义
什么是 future
大多数异步库和语言都基于 future,这是一种处理在未来返回结果的任务的设计模式(因此得名)。当我们执行异步操作时,该操作的结果是未来的,而不是直接返回操作本身的值。虽然 future 是一种方便的抽象,但是程序员需要做更多的工作才能正确处理它们。Async 在 Rust 中使用基于轮询的方法,其中异步任务将有三个阶段
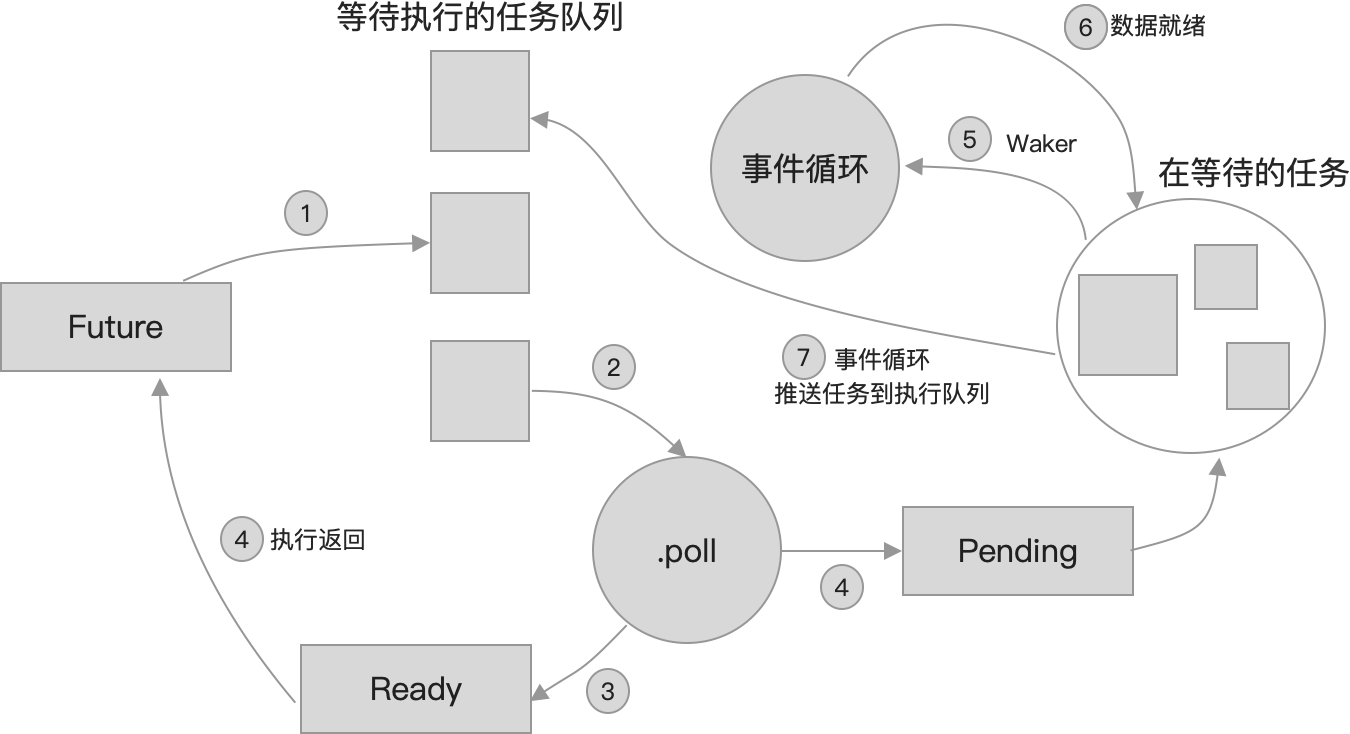
- The poll phase(轮询阶段):对 Future 进行轮询,导致任务继续执行,直到无法继续执行为止。我们经常把运行时轮询 Future 的部分称为 执行器(executor)
- The wait phase(等待阶段):事件源通常被称为反应堆(reactor),它记录 Future 正在等待事件发生,并确保在事件就绪时唤醒 Future
- The wake phase(唤醒阶段):事件发生了,Future 被唤醒了。现在轮到第1步中轮询 Future 的执行器安排对 Future 进行再次轮询,并取得进一步进展,直到轮询完成或到达一个新的点,无法再取得进一步进展,这样循环往复
Leaf futures
运行时创建的 leaf future,它表示一个资源,如套接字(socket)
let mut stream = tokio::net::TcpStream::connect("127.0.0.1:3000");
对这些资源的操作,例如从套接字读取,将是非阻塞的,并返回一个 future,我们称之为 leaf future,它是我们实际等待的 future
Non-leaf futures
Non-leaf futures 是我们作为运行时用户使用 **async** 关键字自己编写的 future,它创建了一个可以在 执行器(executor)上运行的任务。我们编写的异步程序的主体由 non-leaf futures 组成,这是一种可暂停的计算。这是一个重要的区别,因为这些 future 表示一组操作。通常,这样的任务会等待(await)一个 leaf future 作为完成该任务的众多操作之一
let non_leaf = async {let mut stream = TcpStream::connect("127.0.0.1:3000").await.unwrap();println!("connected!");let result = stream.write(b"hello world\n").await;println!("message sent!");...};
突出显示的两行表示暂停执行,将控制权交给运行时,并最终恢复执行。与 leaf future 相比,这类 future 本身并不表示 I/O 资源。当我们轮询它们时,它们会一直运行,直到它们到达一个 leaf future 且该 leaf future 返回 Pending,然后将控制权交给调度器
异步运行时的心智模型
引入运行时的概念,它将推动我们的 futures 完成。在这里创建的思维模型并不是推动 future 完成的唯一方法,Rust 的 future 不会对你实际完成这项任务的方式施加任何限制。Rust 中一个完整的异步系统可以分为三个部分
- Reactor (responsible for notifying about I/O events):反应器(负责通知I/O事件)
- Executor (scheduler):执行器(调度)
- Future (a task that can stop and resume at specific points):Future (可以在特定点停止和恢复的任务)
这三个部分是如何协同工作的呢?让我们看一张图,它展示了一个异步运行时的简化概述
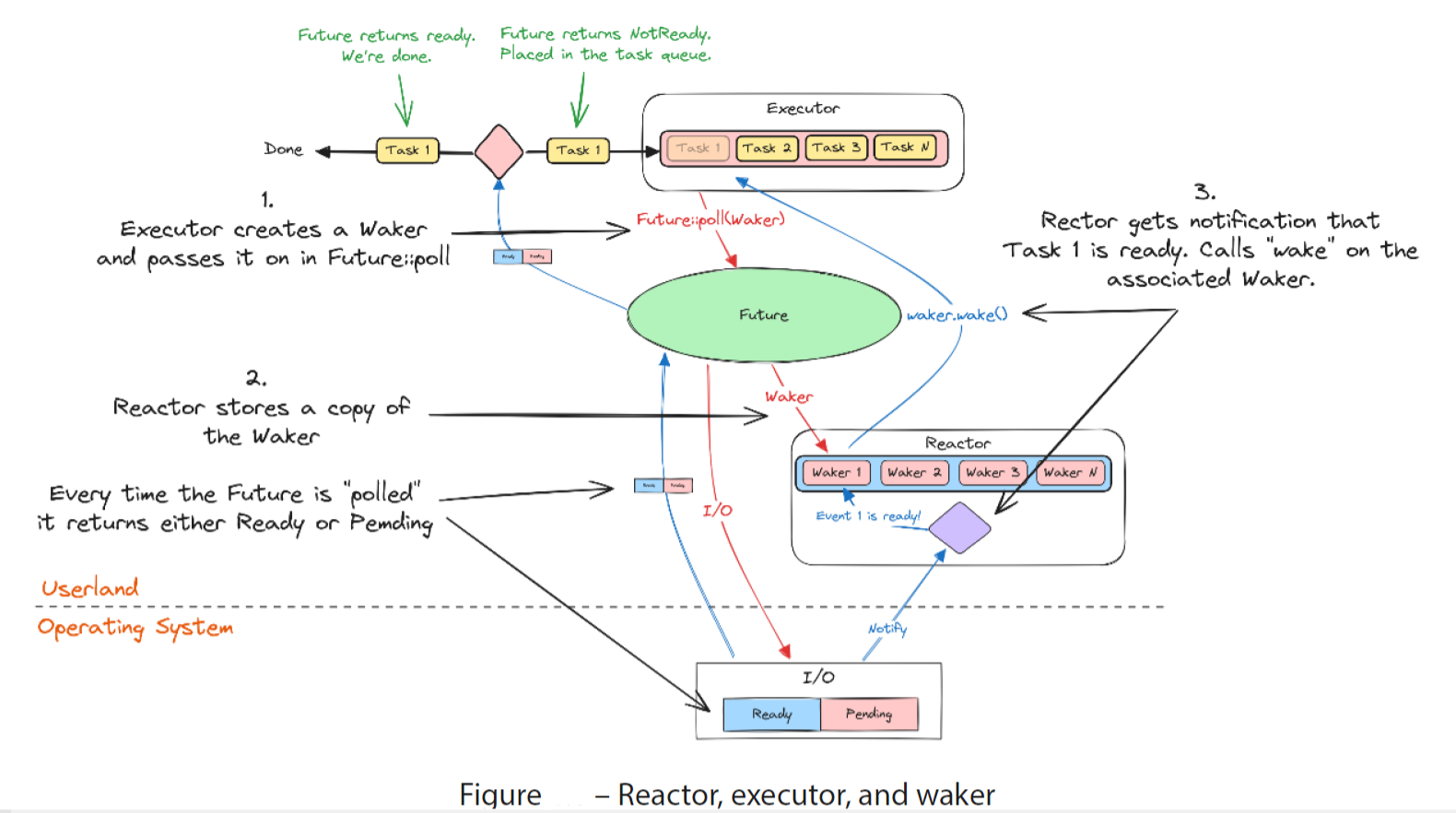
- 在图中的第一步中,一个执行者持有一个 future 的列表。它将尝试通过轮询(轮询阶段)来运行 future,当它这样做时,它会给 future 一个唤醒器。future 要么返回 Poll:Ready (意味着已经完成),要么返回 Poll::Pending (意味着还没有完成,但目前无法继续)。当执行器收到这些结果之一时,它就知道可以开始轮询另一个 future 了。我们把这些控制权转移回执行器节点的点称为让步点(yield point)
- 在第二步中,反应器存储了一个 Waker 的副本,当执行器轮询 Waker 时,它会传递给 future。反应器跟踪该 I/O 源上的事件,通常也是一种事件队列
- 在步骤3中,当反应器收到一个被跟踪源发生事件的通知时,它会定位与该源相关联的唤醒器,并对其调用 Waker::wake。这将通知执行器,future 已经准备好继续执行,以便它可以再次轮询
如果我们用伪代码写一个简短的异步程序,它看起来像这样
async fn foo() {println!("Start!");let txt = io::read_to_string().await.unwrap();println!("{txt}");}
我们写 await 的那行代码将把控制权返回给调度器。这通常被称为让步点 (yield point),因为它要么返回 Poll::Pending,要么返回Poll::Ready。因为所有的执行器进程都使用相同的唤醒器,所以理论上,反应器可以完全不知道执行器进程的类型,反之亦然。执行器节点和反应器节点从来不需要直接通信。这种设计赋予了 futures 框架强大的功能和灵活性,并允许 Rust 标准库提供符合人体工程学的零成本抽象供我们使用
Rust 语言和标准库负责的事情
Rust 只提供了语言中建模异步操作所需的内容。基本上,它提供了以下内容
- 表示操作的公共接口,该操作将在未来通过 future trait 完成
- 一种符合人体工程学的创建任务的方法(准确地说,是无堆栈的协程),可以通过 async 和 await 关键字暂停和恢复
- 通过 Waker 类型唤醒挂起任务的接口
这正是 Rust 的标准库所做的。正如你所看到的
- 没有非阻塞 I/O 的定义
- 也没有这些任务是如何创建或运行的
- 标准库没有非阻塞版本(因为用的是 OS 级别的阻塞线程),所以要真正运行异步程序,你必须创建或决定使用一个运行时
I/O vs CPU-intensive(密集型) tasks
(分析如何引入运行时的必要,比如运行时的**执行器、反应器**)如你所知,你通常写的是 non-leaf futures(调度到就执行)。让我们以伪 rust 为例来看看这个异步代码块
let non_leaf = async {let mut stream = TcpStream::connect("127.0.0.1:3000").await.unwrap();// request a large datasetlet result = stream.write(get_dataset_request).await.unwrap();// wait for the datasetlet mut response = vec![];stream.read(&mut response).await.unwrap();// do some CPU-intensive analysis on the datasetlet report = analyzer::analyze_data(response).unwrap();// send the results backstream.write(report).await.unwrap();}
我已经强调了将控制权交给运行时执行器的要点。需要注意的是,我们在 yield 点之间编写的代码与执行器在同一个线程上运行
这意味着当分析器(analyzer)处理数据集时,执行器忙于进行计算,而不是处理新请求。幸运的是,有几种方法可以解决这个问题,而且并不难,但你必须了解这一点
- 我们可以创建一个新的 leaf future,它将我们的任务发送到另一个线程,并在任务完成时解析。我们可以像等待其他 future 一样等待这个 leaf future
- 运行时可以有某种管理器来监控不同任务所花费的时间,并将执行器本身移动到不同的线程,这样即使我们的分析器任务阻塞了原始执行器线程,它也可以继续运行
- (Rust 做的)你可以自己创建一个与运行时兼容的反应器,它会以你认为合适的任何方式进行分析,并返回一个可以等待的 future
第一种方式是通常的处理方式,但有些执行器进程也会实现第二种方式。第2点的问题是,如果你切换运行时,你需要确保它也支持这种监督,否则最终会阻塞执行器进程。第三种方法更具有理论意义,通常,您很乐意将任务发送到大多数运行时提供的线程池。大多数执行器进程都可以通过类似 spawn_blocking 的方法来实现第1条。这些方法将任务发送到运行时创建的线程池中,您可以在其中执行运行时不支持的 cpu 密集型任务或阻塞任务

若有收获,就点个赞吧
0 人点赞
