具体来说,我们将研究在编程语言和库中建模和处理**并发性的不同方法。重要的是要记住,threads、futures、fibers、goroutines、promises 等都是抽象,它们为我们提供了一种建模异步程序流的方法。它们有不同的优点和缺点,但它们都有一个共同的目标,即为程序员提供一种易于使用(而且重要的是,难以误用)、高效和富有表现力的方式来创建一个以非顺序的、通常是不可预测的顺序处理任务的程序。这里也普遍缺乏精确的定义:许多术语的名称源于某个时间点的具体实现,但后来具有更一般的含义,包括同一事物的不同实现和变体。在讨论每个抽象的优缺点之前,我们将首先通过一种 基于相似性对不同抽象进行分组 **的方法
Cooperative 和 Non-cooperative
可以将并发操作的抽象大致分为两类
- Cooperative(协作的,互相谦让):这些任务(可以简单理解为你写的代码进程程序)可以通过 显式地让步(yield)或 调用一个函数来自愿让步(yield voluntarily),当任务在另一个操作完成之前(例如进行网络调用)无法继续进行时,该函数会挂起任务(即:我们程序要执行网络调用,网络执行不完成,我们程序没法继续执行,因为需要网络调用的结果返回,所以相当于我们程序任务被网络执行的函数挂起)。大多数情况下,这些任务由某种调度器完成。Rust 和 JavaScript 中的 async/await 生成的任务就是这样的例子
- Non-cooperative(非协作的,那只能抢占):那些不一定会 自愿让步(yield voluntarily)的任务。在这样的系统中,调度器必须能够 抢占(pre-empt)正在运行的任务,这意味着调度器可以停止任务并控制 CPU,即使任务已经能够完成工作和进度。这方面的例子是操作系统线程 和 Goroutines** **(GO版本1.14之后)
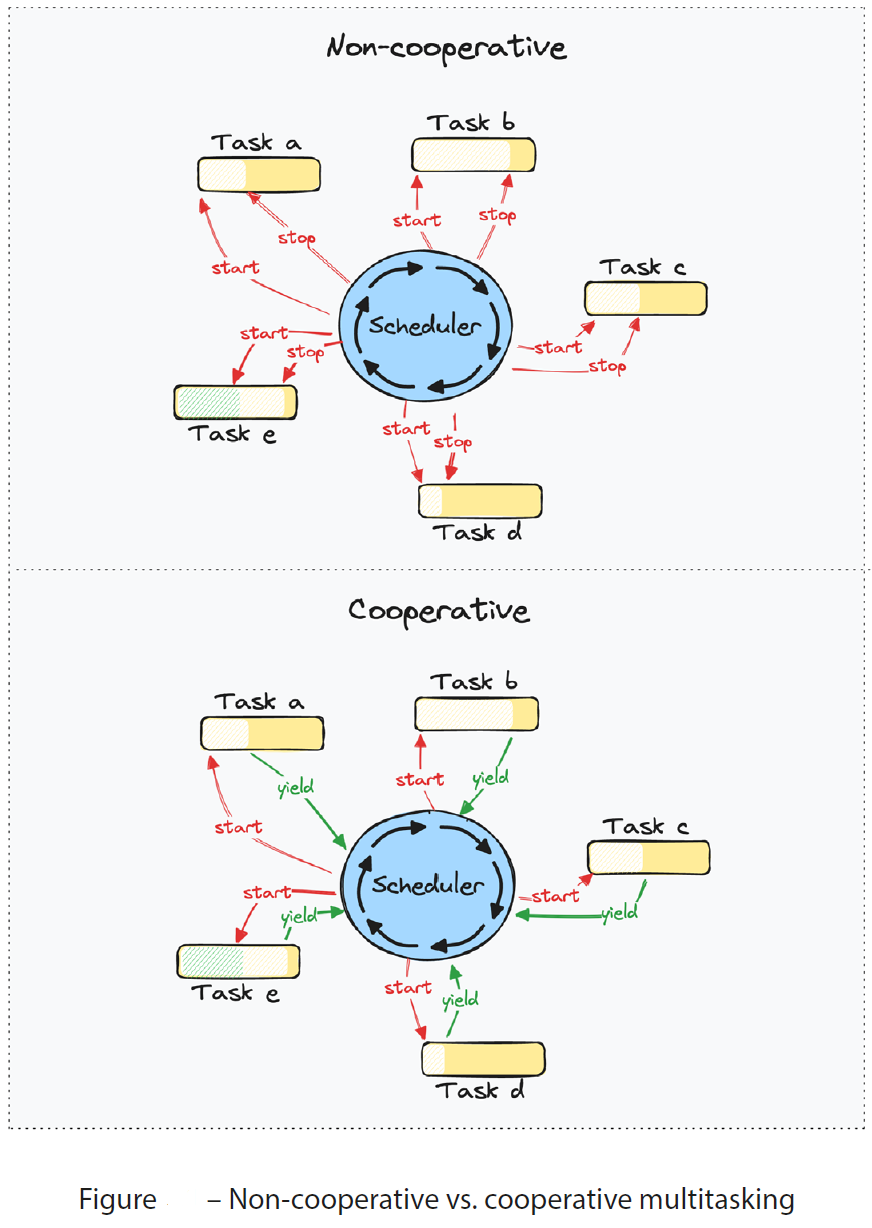
在调度程序可以抢占正在运行的任务的系统中,任务也可以像在协作系统中那样自愿让步,而这在只依赖于抢占的系统中是很少见的
Stackful 和 Stackless
可以根据其实现的特征进一步将这些抽象(并发操作的抽象)分为两大类
- Stackful(有栈的、有栈协(合作的)程、绿线程、Fibers):每个任务都有自己的调用堆栈。这通常被实现为一个堆栈,类似于操作系统为其线程使用的堆栈。堆栈任务可以在程序中的任何点暂停执行,因为整个堆栈被保留。在这种模型中,协程可以像线程一样被调度到内核线程上执行,但它们通常更轻量级,因为它们由运行时环境管理,而非操作系统直接管理。Go 语言的并发模型就是典型的 Stackful 调度模型,其中每个协程(goroutine)都有自己的栈,并且由 Go 的运行时环境调度到操作系统线程上执行
- Stackless(无栈的、无栈协(合作的)程):不是每个任务都有一个单独的堆栈,它们都共享同一个调用堆栈运行。任务不能在堆栈帧的中间挂起,这限制了运行时抢占任务的能力。然而,在任务之间切换时,它们需要存储/恢复的信息更少,因此它们可以更高效。在Rust 中,这种模型主要通过 Future 和 异步编程 实现。Future 是一个 Rust 中用于表示异步操作的结构,它并不直接管理自己的栈空间。当异步函数(由 async 关键字修饰)执行时,它们不会立即执行完成,而是返回一个 Future 对象。这个 Future 对象随后被调度器(executor)轮询(poll),以推进异步操作的执行。这种方式下,协程的上下文(如局部变量)被存储在栈帧或结构中,而不是独立的栈空间中
比较两者的异同点
- 相同点
- 两者都是并发编程的重要工具,旨在提高程序的执行效率和响应能力
- 它们都允许开发者以更自然的方式编写异步或并发代码,而无需深入了解底层的线程管理
- 不同点
- 内存使用:Stackful 调度模型为每个协程分配独立的栈空间,这可能导致较高的内存使用,尤其是当协程数量较多时。相比之下,Stackless 调度模型通过复用现有栈空间(如调用栈或专门的内存结构)来减少内存消耗
- 实现复杂性:Stackful 调度模型通常更复杂,因为需要管理每个协程的栈空间。而 Stackless 调度模型则相对简单,因为它不需要为每个协程维护独立的栈
- 性能影响:Stackful 调度模型可能由于栈的创建和销毁以及上下文切换而引入额外的性能开销。然而,在某些情况下(如大量轻量级任务),这种开销可能被并发执行的优势所抵消。Stackless 调度模型则可能由于减少了内存使用和上下文切换而具有更好的性能
AI 比较两者的异同点
| Stackful(有栈)协程 | Stackless(无栈)协程 | |
|---|---|---|
| 栈内存处理 | 需要分配一个固定的栈内存空间(如4KB或64KB),用于存储协程的参数、局部变量和返回地址等 | 栈内存位置不固定,通过编译器生成的代码(如闭包)来管理协程的状态,无需固定的栈内存空间 |
| 继续执行逻辑 | 协程切换时,直接从原栈的位置继续执行,依赖CPU的跳转位置来实现中断返回 | 需要编译器生成代码(如闭包)来自定义继续执行逻辑,不涉及CPU的直接跳转 |
| 性能影响 | 中断返回需要依赖CPU的跳转位置,可能会略微影响CPU的分支预测,但影响通常不大 | 对CPU分支预测无影响,理论上性能更优(但具体性能取决于实现细节和编译器优化) |
| 内存占用 | 需要分配固定大小的栈内存,内存占用较大 | 内存占用较低,只需创建带状态号变量的状态机 |
| 易用性 | 实现简单,可以轻松实现完全一致的递归/异常处理等 | 实现复杂,需要编译器作者高超的技艺,与已有组件结合较麻烦 |
| 使用场景 | 适用于需要固定栈内存管理的场景,如 Go 语言的 goroutine | 适用于对内存利用率有较高要求的场景,如 C# 的异步编程模型 |
选择哪种调度模型的建议
对于 Rust 编程者来说,选择哪种调度模型主要取决于具体的应用场景和需求- 如果应用需要处理大量轻量级的并发任务,并且内存使用是一个考虑因素,那么 Stackless 调度模型(通过 Rust 的 Future 和 异步编程)可能是一个更好的选择。它允许开发者以简洁的方式编写异步代码,同时减少内存消耗和性能开销
- 如果应用需要更复杂的并发控制,或者需要每个任务都有自己的独立栈空间以便于管理,那么可以考虑使用支持 Stackful 调度模型的运行时(尽管 Rust 本身不直接提供这样的运行时)。然而,这种情况下可能需要引入额外的库或框架来支持这种模型
Threads 定义扫盲区分
在最一般的意义上,线程指的是执行线程,意味着一组需要按顺序执行的指令。我们在“并发与并行”小节中提供了几个定义,那么执行线程类似于我们定义的具有多个步骤的任务**,这些步骤需要资源来进行。**这个定义的概括性可能会引起一些混淆。对一个人来说,线程显然可以指操作系统线程,而对另一个人来说,它可以简单地指表示系统上执行线程的任何抽象。线程通常分为两大类
- OS threads:这些线程由操作系统创建,并由操作系统调度器管理。在 Linux 上,这被称为内核线程
- User-level threads:这些线程是由我们作为程序员创建和管理的,而操作系统并不知道它们
从最广泛的意义上讲,用户级线程可以指创建和调度任务的系统(运行时)的任何实现,您不能像对操作系统线程那样做出相同的假设。它们可以通过为每个任务使用单独的堆栈来与操作系统线程非常相似,当我们讨论 fiber/green threads 的例子时,或者它们可以在本质上完全不同,就像我们将在本书的中讨论 Rust 如何建模并发操作时看到的那样
无论定义是什么,一组任务都需要一些东西来管理它们,并决定谁可以获得哪些资源来推进。在计算机系统中,所有任务都需要进行的最明显的资源是 CPU 时间。当有人在没有添加额外上下文的情况下提到“线程”时,他们指的是操作 系统线程(OS thread)/内核线程(kernel thread),所以这就是我们将要做的。我继续将执行线程简单地称为任务。如果我们尽可能根据上下文限制使用具有不同假设的术语,那么异步编程的主题就更容易理解了
- 我们敲的程序代码,执行的函数线程称为任务
- 没什么特别说明,直接说线程就是系统线程/内核线程
有了这些,让我们来看看操作系统线程的一些定义特征,同时强调它们的局限性。定义会根据你读的书或文章而有所不同。例如,如果您阅读特定操作系统的工作原理,您可能会看到进程或线程是表示“任务”的抽象,这似乎与我们在这里使用的定义相矛盾。正如我前面提到的,参考框架**(作为程序员的您 和 您的代码(您的进程) 作为 参考框架)**的选择是很重要的,这也是为什么我们在全书中遇到术语时要如此小心地彻底定义它们的原因
线程的定义也可能因操作系统而异,尽管目前大多数流行的系统都有类似的定义。最值得注意的是,Solaris (2002 年发布的 Solaris 9 之前的版本)曾经有一个两级线程系统,用于区分应用程序线程(程序执行流)、轻量级进程(用户态线程)和 内核线程。这是我们所说的 M:N 线程的实现
Threads provided by the operating system
注意:**We call this 1:1 threading. Each task is assigned one OS thread**
操作系统线程很容易实现,也很容易使用。我们只是让操作系统为我们照顾一切。我们通过为我们想要完成的每个任务生成一个新的操作系统线程来实现这一点,并像往常一样编写代码。我们用来处理并发性的**运行时**是操作系统本身。除了这些优点之外,您还可以免费获得并行性(自己搞运行时会有额外的运行时开销,需要权衡,比如 Rust 的 Tokio 异步运行时)。直接管理并行性和共享资源也有一些缺点和复杂性
- Creating new threads takes time:创建一个新的 OS 线程涉及到一些初始化开销,因此,虽然在同一进程中的两个现有线程之间切换非常快,但创建新线程并丢弃不再使用的线程则需要花费时间。如果系统需要创建和丢弃大量的线程,那么所有额外的工作都将限制吞吐量。如果您有大量需要并发处理的小任务,这可能是一个问题,在处理大量 I/O 时经常出现这种情况
- Each thread has its own stack:将在本书后面详细介绍堆栈,但是现在,知道它们占用固定大小的内存就足够了。每个操作系统线程都有自己的堆栈,尽管许多系统允许配置这个大小,但它们的大小仍然是固定的,不能增长或缩小。毕竟,它们是堆栈溢出的原因,如果您将它们配置为对于正在运行的任务来说太小,这将是一个问题。如果我们有许多只需要少量堆栈空间的小任务,但我们保留的内存比我们需要的要多得多,我们将占用大量内存并可能耗尽内存
- Context switching:线程和调度器是紧密相连的。上下文切换发生在 CPU 停止执行一个线程并继续执行另一个线程时。尽管这个过程是高度优化的,但它仍然涉及存储和恢复寄存器状态,这需要时间。每次您向操作系统调度器屈服时,它都可以选择从该 CPU 上的不同进程调度一个线程。你看,这些系统创建的线程属于一个进程。当你启动一个程序时,它启动了一个进程,这个进程创建了至少一个初始线程,它在这个线程中执行你所编写的程序。每个进程可以产生多个共享相同地址空间的线程。这意味着同一进程中的线程可以访问共享内存并访问相同的资源,例如文件和文件句柄。这样做的一个后果是,当操作系统通过停止一个线程并在同一进程中恢复另一个线程来切换上下文时,它不必保存和恢复与该进程相关的所有状态,只需保存和恢复特定于该线程的状态。另一方面,当操作系统从与一个进程关联的线程切换到与另一个进程关联的线程时,新进程将使用不同的地址空间,操作系统需要采取措施确保进程 A 不会访问属于进程 B 的数据或资源。如果没有,系统就不安全。其结果是可能需要刷新缓存,并且可能需要保存和恢复更多状态。在负载下的高度并发系统中,这些上下文切换可能会花费额外的时间,因此如果它们发生得足够频繁,就会以某种不可预测的方式限制吞吐量
- Scheduling(调度):操作系统对任务的调度可能与您期望的不同,并且每次您向操作系统屈服让步(yield)时,您都会与系统上的所有其他线程和进程放在同一个队列中。此外,由于不能保证线程会在中断的同一个 CPU 核心上恢复执行,也不能保证两个任务不会并行运行并尝试访问相同的数据,因此需要同步数据访问,以防止数据竞争和与多核编程相关的其他缺陷。Rust 作为一种语言将帮助您避免许多这些缺陷,但是同步数据访问将需要额外的工作,并增加此类程序的复杂性。我们经常说,使用操作系统线程来处理并发性可以免费提供并行性,但就增加复杂性和需要适当的数据访问**同步**而言,这并不是免费的
- 将异步操作与操作系统线程解耦的优点:将异步操作与线程的概念解耦有很多好处。首先,使用操作系统线程作为处理并发的手段要求我们使用本质上是操作系统抽象的东西来表示我们的任务。拥有一个单独的抽象层来表示并发任务,可以让我们自由选择如何处理并发操作。如果我们在并发操作上创建一个抽象,比如 Rust 中的 future, JavaScript 中的 promise,或者 GO 中的 goroutine,那么这些并发任务是由运行时实现者决定如何处理的。运行时可以简单地将每个并发操作映射到一个操作系统线程,它们可以使用 fibers/green threads(stackful 有栈) 或 状态机(stackless 无栈) 来表示任务。如果底层实现发生变化,编写异步代码的程序员不必更改代码中的任何内容。理论上讲,相同的异步代码可以用于处理没有操作系统的微控制器上的并发操作,如果它只有一个运行时
- 总而言之,使用操作系统提供的线程来处理并发性具有以下 优点
- Simple to understand
- Easy to use
- Switching between tasks is reasonably fast
- You get parallelism for free (免费从操作系统获得并行性)
- 然而,它们也有一些 缺点
- 操作系统级别的线程有一个相当大的堆栈。如果你有许多任务同时等待 (就像你在一个负载很重的 web 服务器上一样),你很快就会耗尽内存
- 上下文切换可能代价高昂,而且由于让操作系统执行所有调度,您可能会获得不可预测的性能
- 操作系统需要处理很多事情。它可能不会像您希望的那样快速切换回您的线程
- 它与操作系统抽象紧密耦合。这在某些系统上可能不是一个选项
- 总而言之,使用操作系统提供的线程来处理并发性具有以下 优点
搞个“操作系统线程”例子练习理解下
由于我们不会在本书中花更多的时间讨论操作系统线程,因此我们将通过一个简短的示例来了解它们是如何使用的
use std::thread::{self, sleep};fn main() {println!("So, we start the program here!");let t1 = thread::spawn(|| {sleep(std::time::Duration::from_millis(200));println!("The long running tasks finish last!");});let t2 = thread::spawn(|| {sleep(std::time::Duration::from_millis(100));println!("We can chain callbacks...");let t3 = thread::spawn(|| {sleep(std::time::Duration::from_millis(50));println!("...like this!");});t3.join().unwrap();});println!("The tasks run concurrently!");t1.join().unwrap();t2.join().unwrap();}// 输出如下:So, we start the program here!The tasks run concurrently!We can chain callbacks......like this!The long-running tasks finish last!
在本例中,我们只是生成几个操作系统线程并使它们处于睡眠状态。休眠本质上等同于向操作系统调度器屈服让步(yield),请求在一段时间后重新调度运行。因此,虽然使用操作系统线程对于许多任务来说都很好,但我们也通过讨论它们的局限性和缺点概述了一些考虑替代方案的好理由。我们要看的第一个替代品是我们所说的 fibers and green threads
Fibers 和 green threads
注意:这是一个 M:N 线程的例子。许多任务可以并发地运行在一个操作系统线程上。Fibers and green threads 通常被称为 stackful coroutines
“绿色线程”这个名称最初源于 Java 中使用的 M:N 线程模型的早期实现,此后与 M:N 线程的不同实现相关联。您将遇到这个术语的不同变体,例如“绿色进程”(在 Erlang 中使用),它与我们在这里讨论的不同。您还将看到一些对绿色线程的定义比这里更广泛。我们在这本书中定义绿色线程的方式使它们与 Fibers 同义,所以这两个术语指的是同样的东西。Fibers and green threads 的实现意味着存在一个带有调度程序的运行时,该调度程序负责调度哪些任务(M)有时间在OS线程(N)上运行。任务比 OS 线程要多得多,这样的系统只使用一个 OS 线程就可以运行得很好。后一种情况通常被称为 M:1 线程
Goroutines 是堆栈协同程序(stackful 协程)的一个具体实现示例,但它有一些细微的差别。术语“协程”通常意味着它们在本质上是协作的,但是调度程序可以预先抢占协程(至少从1.14版本开始),因此使用我们在这里介绍的类别,将它们置于某种灰色地带
Fibers and green threads 使用与操作系统相同的机制,为每个任务设置堆栈,保存 CPU 的状态,并通过上下文切换从一个任务(用户代码程序线程)跳转到另一个任务(用户代码程序线程)。我们将控制权交给调度器(它是此类系统中运行时的中心部分),然后调度器继续运行不同的任务。执行状态**存储在每个堆栈中,因此在这样的解决方案中,不需要 async、await、Future 或 Pin。在许多方面,绿色线程模仿操作系统如何促进并发性,实现它们是一个很好的学习经验。使用 Fibers and green threads 执行并发任务的运行时具有高度的灵活性。例如,任务可以在执行过程中的任何时间和任何点被抢占和上下文切换,因此一个占用 CPU 的长时间运行的任务理论上可以被运行时抢占,作为一种保护措施,防止由于边缘情况或程序员错误而导致任务阻塞整个系统。这为运行时调度器提供了与操作系统调度器几乎相同的功能,这是使用 Fibers and green threads **的系统的最大优点之一
典型的流程如下
- You run some non-blocking code
- You make a blocking call to some external resource
- The CPU jumps to the main thread, which schedules a different thread to run and jumps to that stack
- You run some non-blocking code on the new thread until a new blocking call or the task is finished
- The CPU jumps back to the main thread, schedules a new thread that is ready to make progress, and jumps to that thread
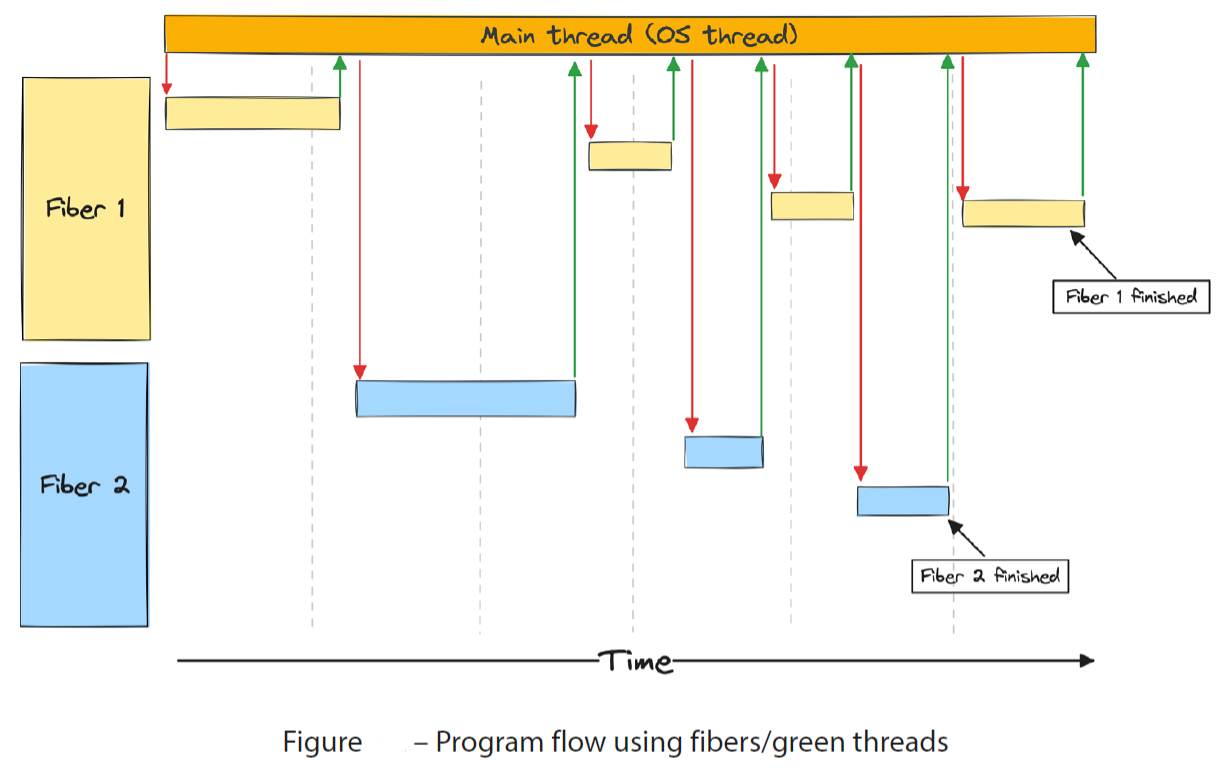
Each stack has a fixed space 每个堆栈都有一个固定的空间
由于 Fibers and green threads 类似于操作系统线程,它们也有一些相同的缺点。每个任务都设置了一个固定大小的堆栈,因此您仍然需要保留比实际使用更多的空间。然而,这些堆栈可以是可增长的,这意味着一旦堆栈满了,运行时就可以增长堆栈。虽然这听起来很简单,但这是一个相当复杂的问题。我们不能像种树那样简单地增加堆栈。实际需要发生的是如下两件事之一
- 您分配了一块新的连续内存,并处理堆栈分布在两个不相连的内存段上的事实
- 第一个解决方案听起来很简单,因为您可以保持原始堆栈不变,并且可以在需要时上下文切换到新堆栈并从那里继续。然而,由于缓存和预测下一个指令将要处理的数据的能力,如果现代 CPU 能够在连续的内存上工作,那么它们的工作速度就会非常快。将堆栈分散到两个不相连的内存中会影响性能。当您的循环恰好位于堆栈边界时,这一点尤其明显,因此您最终会为循环的每次迭代进行最多两次上下文切换
- 您分配一个新的更大的堆栈(例如,是前一个堆栈大小的两倍),将所有数据移动到新堆栈,并从那里继续
- 第二种解决方案通过将堆栈作为一个连续的内存块来解决第一种解决方案的问题,但它也有一些问题
- 首先,您需要分配一个新堆栈并将所有数据移动到新堆栈。但是,当所有指针和引用都移动到一个新位置时,指向堆栈上某个位置的指针和引用会发生什么呢?您猜对了:每个指向堆栈上任何东西的指针和引用都需要更新,以便它们指向新的位置。这既复杂又耗时,但是如果您的运行时已经包含了一个垃圾收集器,那么您已经有了跟踪所有指针和引用的开销,因此与非垃圾收集程序相比,这可能是一个更小的问题。但是,每次堆栈增长时都需要在垃圾收集器和运行时之间进行大量集成,因此实现这种类型的运行时可能会变得非常复杂
- 其次,如果您有很多长时间运行的任务,这些任务只在很短的一段时间内需要大量的堆栈空间(例如,如果它在任务开始时涉及大量递归),但其余时间大多是 I/O 受限,那么您必须考虑会发生什么。最终,仅针对该任务的一个特定部分,您就会多次增加堆栈,并且您必须做出决定,是接受任务占用的空间超过其所需的空间,还是在某个时候将其移回更小的堆栈。这将对您的程序产生的影响当然会根据您所做的工作类型而有很大的不同,但这仍然是需要注意的
- 第二种解决方案通过将堆栈作为一个连续的内存块来解决第一种解决方案的问题,但它也有一些问题
Context switching
尽管与OS线程相比,这些 Fibers/绿色线程 是轻量级的,但您仍然需要在每次上下文切换时保存和恢复寄存器。大多数情况下,这可能不是问题,但是与不需要上下文切换的替代方案相比,它的效率可能会降低
Scheduling
当一个 Fibers/绿色线程 向运行时调度器屈服让步时,调度器可以简单地在准备运行的新任务上恢复执行。这意味着您可以避免每次屈服让步于调度器时与系统中的所有其他任务被放在同一个运行队列中的问题。从操作系统的角度来看,您的线程一直在忙着做工作,因此如果可以的话,它将尽量避免抢占它们。这样做的一个意想不到的缺点是,大多数操作系统调度器通过给每个操作系统线程一个时间片来确保所有线程都有时间运行,在操作系统预先清空线程并在该 CPU 上调度一个新线程之前,它可以在该时间片上运行。使用许多操作系统线程的程序可能会比使用较少操作系统线程的程序分配更多的时间片。使用 M:N 线程的程序很可能只使用几个操作系统线程。因此,根据系统上运行的其他内容,您的程序可能会被分配到比使用许多操作系统线程更少的时间片。但是,考虑到大多数现代 CPU 上可用的内核数量以及并发系统上的典型工作负载,由此产生的影响应该是最小的
FFI
由于您创建了自己的堆栈,这些堆栈应该在某些条件下增长/缩小,并且可能有一个调度程序,假设它可以在任何时候抢占正在运行的任务,因此在使用 FFI 时必须采取额外的措施。大多数 FFI 函数将假设一个正常的操作系统提供的 C 堆栈,所以从 Fibers/绿色线程 调用 FFI 函数很可能会有问题。您需要通知运行时调度器,上下文切换到不同的操作系统线程,并以某种方式通知调度器您已经完成,并且 Fibers/绿色线程 可以继续。这自然会给运行时实现者和发起 FFI 调用的用户带来开销和复杂性
优点
- It is simple to use for the user. The code will look like it does when using OS threads
- Context switching is reasonably fast
- 与操作系统线程相比,大量内存使用不是什么问题
- 你完全可以控制任务的安排,如果你想的话,你可以根据自己的需要优先安排任务
- 它很容易合并抢占,这可能是一个强大的功能
缺点
- Stacks need a way to grow when they run out of space creating additional work and complexity
- You still need to save the CPU state on every context switch
- It’s complicated to implement correctly if you intend to support many platforms and/or CPU architectures
- FFI can have a lot of overhead and add unexpected complexity
Callback based approaches
注意:This is another example of M:N threading. Many tasks can run concurrently on one OS thread. Each task consists of a chain of callbacks
你可能已经知道我们接下来要讨论的 JavaScript 内容,我想大多数人都知道。基于回调的方法背后的整个思想是保存一个指针,指向我们稍后要运行的一组指令,以及所需的任何状态。在 Rust 中,这将是一个闭包。在大多数语言中,实现回调都相对容易。它们不需要任何上下文切换,也不需要为每个任务预分配内存。然而,使用回调函数表示并发操作要求你从一开始就以完全不同的方式编写程序。将一个使用普通顺序程序流的程序重写为使用回调函数的程序,意味着大量的重写,反之亦然。基于回调的并发可能很难理解,也可能变得非常复杂。大多数 JavaScript 开发者都熟悉“回调地狱”这个术语。由于每个子任务必须保存它以后需要的所有状态,因此内存使用将随着任务中回调函数的数量线性增长
优点
- Easy to implement in most languages
- No context switching
- Relatively low memory overhead (in most cases)
缺点
- Memory usage grows linearly with the number of callbacks
- Programs and code can be hard to reason about(难以理解)
- 这是一种完全不同的编程方式,几乎会影响程序的所有方面,因为所有的 yield(让步) 操作都需要一个回调函数
- 所有权很难解释清楚。结果是,如果没有垃圾收集器,编写基于回调的程序将变得非常困难
- Sharing state between tasks is difficult due to the complexity of ownership rules
- Debugging callbacks can be difficult
Coroutines: promises and futures
注意:This is another example of M:N threading. Many tasks can run concurrently on one OS thread. Each task is represented as a state machine
JavaScript 中的 promise 和 Rust 中的 future 是基于相同思想的两种不同实现。不同的实现方式之间存在差异,这里不做重点讨论。由于promise 在 JavaScript 中的使用,它已经广为人知,所以有必要对它做一些解释。promise 和 Rust 的 future 也有很多共同之处。首先,许多语言都有 promise 的概念,但在下面的例子中,我将使用 JavaScript 中的一个概念。promise 是一种处理基于回调方法带来的复杂性的方法

后一种方法也称为延续传递风格(the continuation-passing style),每个子任务完成后都会调用一个新任务。回调函数和 promise 对象之间的本质区别更大。promise 返回的状态机有三种状态:pending、fulfilled 或 rejected。当我们在前面的例子中调用 timer(200) 时,我们得到了一个处于 pending 状态的 promise。现在,延续传递风格确实修复了一些与回调相关的问题,但它仍然保留了很多与复杂性和编写程序的不同方式有关的问题。然而,它们使我们能够 利用编译器 来解决许多这些问题,我们将在下一段中讨论
Coroutines and async/await
Coroutines 协程 有两种类型:非对称 asymmetric 和 对称 symmetric。非对称协程优于调度器,它们是我们将重点关注的内容。Symmetric coroutines yield a specific destination;for example, a different coroutine
协程的对称性和非对称性主要体现在协程之间的控制流传递方式上
- 协程对称性(**symmetric**):对称协程是指所有协程在控制流传递上都是对等的,没有特定的调用者或被调用者关系。在对称协程中,通常只有一个操作(如 yield)用于在协程间传递控制权,且这个操作可以显式地指定将控制权传递给哪个协程。对称协程一般需要一个调度器来管理协程之间的切换,按照一定的调度算法选择哪个协程获得控制权。协程之间地位平等,没有固定的调用者或被调用者关系。控制权传递通过显式的操作(如yield)进行,并可以指定目标协程。需要调度器来管理协程的切换
- 例子:考虑一个生产者-消费者模型,其中生产者和消费者都是协程。在对称协程模型中,生产者和消费者协程可以平等地通过yield操作将控制权传递给对方。例如,生产者协程在填充队列后yield,将控制权交给消费者协程;消费者协程在处理完队列中的元素后yield,将控制权交还给生产者协程。这种模型中,生产者和消费者之间没有固定的调用者或被调用者关系,它们通过调度器平等地交换控制权
- 协程非对称性(**asymmetric** ):非对称协程是指协程之间存在特定的调用者或被调用者关系。在非对称协程中,协程让出CPU时,通常只能将控制权返回给其调用者(或启动者)。这种模型中的协程调用(resume)和返回(yield)操作在地位上是不对等的。协程之间存在特定的调用者或被调用者关系。控制权通常只能返回给调用者协程。可能不需要显式的调度器来管理协程的切换(但某些实现中仍然可能需要)
- 例子:考虑一个生成器函数作为非对称协程的例子。在 Python 中,生成器函数通过 yield 语句可以暂停执行并返回一个值给调用者,同时保存当前执行状态以便后续恢复。当调用者再次请求生成器的下一个值时(通过 next() 函数或 send() 方法),生成器从上次 yield 的位置恢复执行。在这个过程中,生成器作为被调用者协程,其控制权只能在 yield 时返回给调用者,并在调用者请求下一个值时恢复。这种模型体现了非对称协程的特点,即协程之间的调用和返回操作在地位上是不对等的
虽然协程是一个非常广泛的概念,但在编程语言中引入协程作为对象,才是真正使这种处理并发的方法匹敌操作系统线程和 fiber/绿色线程 的易用性的原因。你可以看到,当你在 Rust 或JavaScript 中编写 async 时,编译器会重写看起来像对 future 的普通函数调用(在 Rust 中)或 promise (在 JavaScript 中)。另一方面, Await 将控制权交给运行时调度器,任务会被挂起,直到你 awaiting(等待、期待) 的 future/promise 完成。通过这种方式,我们可以用几乎相同的方式编写处理并发操作的程序
async function run() {await timer(200);await timer(100);await timer(50);console.log("I'm the last one");}
你可以把 run 函数看作由**多个子任务**组成的暂停任务。在每个 **await** 点上,它将控制权交给调度器(在本例中,它是众所周知的 JavaScript 事件循环 Event loop)。一旦其中一个子任务的状态变为 fulfilled 或 rejected,该任务将按计划继续进行下一步。当使用 Rust 时,当您编写类似这样的代码时,您可以看到相同的转换发生在函数签名上
async fn run() -> () { … }
下面这个函数包装了返回对象,返回一个输出类型为 ( ) 的 Future 对象,而不是返回 type( )
Fn run() -> impl Future<Output = ()>
从语法上讲,Rust 的 futures 0.1 很像我们刚才展示的 promise 示例,而且我们今天使用的 Rust futures 与 JavaScript 中的 async/await 的工作方式有很多共同点。这种重写看起来像普通函数和代码的方式有很多好处,但也不是没有缺点。与任何无堆栈的协程实现一样,完全抢占可能很难或不可能实现。这些函数必须在特定的点上屈服让步(yield),并且与 fibers/green threads 相比,没有办法在堆栈帧的中间暂停执行。例如,通过让运行时或编译器在每次函数调用时插入抢占点,可以实现某种程度的抢占,但这与能够在任务执行期间的任何一点抢占任务是不一样的
Pre-emption points(抢占点)
抢占点可以认为是插入代码,调用调度器,询问调度器是否希望抢占该进程。例如,这些点可以由编译器或你使用的库在每次新函数调用之前插入
此外,你需要编译器的支持来充分利用它。具有元编程能力的语言(例如宏)可以模拟大部分相同的内容,但当编译器意识到这些特殊的异步任务时,仍然没有那么无缝。调试是实现 future/promise 时必须小心的另一个领域。由于代码被重写为状态机(或生成器),因此不会像使用普通函数那样拥有相同的堆栈跟踪。对于 future 和 promise 来说,可能是运行时调用了状态机中的函数,所以在调用失败的函数之前,可能没有很好的回溯可以用来查看发生了什么。有一些方法可以解决这个问题,但大多数方法都会产生一些开销
优点
- You can write code and model programs the same way you normally would
- No context switching
- It can be implemented in a very memory-efficient way
- It’s easy to implement for various platforms
缺点
- Pre-emption(抢占) can be hard, or impossible, to fully implement, as the tasks can’t be stopped in the middle of a stack frame
- It needs compiler support to leverage(利用) its full advantages
- Debugging can be difficult both due to the non-sequential program flow and the limitations on the information you get from the backtraces
状态机和堆栈的区别
| 状态机 | 堆栈 | |
|---|---|---|
| 定义 | 描述系统行为的数学模型,由状态、事件和转换规则组成 | 运算受限的线性表,只允许在栈顶进行插入和删除操作 |
| 核心要素 | 状态、事件、转换规则 | 栈顶、插入(push)、删除(pop) |
| 操作原则 | 根据输入事件和当前状态进行状态转换 | 后进先出(LIFO) |
| 应用场景 | 需要明确不同状态行为和事件处理的系统,如网络协议、游戏开发、用户界面设计等 | 函数调用、表达式求值、页面替换算法等 |
| 数据结构类型 | 逻辑模型 | 线性表的一种特殊形式 |

若有收获,就点个赞吧
0 人点赞
