概述
ElasticSearch概述
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
历史
多年前,一个叫做Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便lava程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过Elasticsearch将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索…..
谁在使用
1、维基百科,类似百度百科,全文检索,高亮,搜索推荐
2、The Guardian (国外新闻网站) ,类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论) +社交网络数据(对某某新闻的相关看法) ,数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
3、Stack Overflow (国外的程序异常讨论论坛) , IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
4、GitHub (开源代码管理),搜索 上千亿行代码
5、电商网站,检索商品
6、日志数据分析, logstash采集日志, ES进行复杂的数据分析, ELK技术, elasticsearch+logstash+kibana
7、商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
安装
ElasticSearch安装
安装前准备
ES基于java开发,必须先安装jdk(1.8及以上),配置java环境变量。
以下为windows版本安装,liunx上安装可以参照这个文档
http://192.168.0.211/FZSYBCPK/10产品研发/90组件框架工具/04资源文件/java组件/Elasticsearch集群部署
- 1.下载
下载地址:https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/ - 2.解压
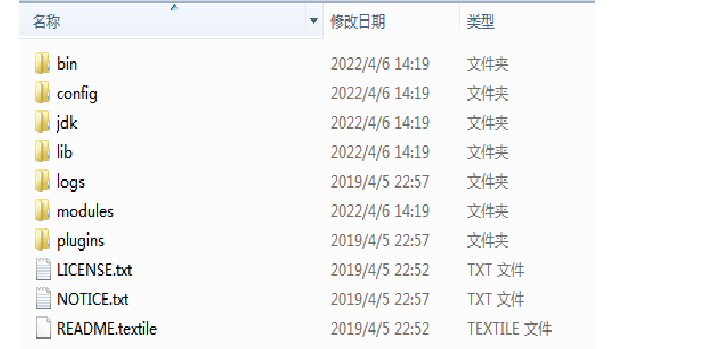
目录说明
bin 启动文件目录config 配置文件目录1og4j2 日志配置文件jvm.options java 虚拟机相关的配置(默认启动占1g内存,内容不够需要自己调整)elasticsearch.ym1 elasticsearch 的配置文件! 默认9200端口!跨域!1ib相关jar包modules 功能模块目录plugins 插件目录ik分词器
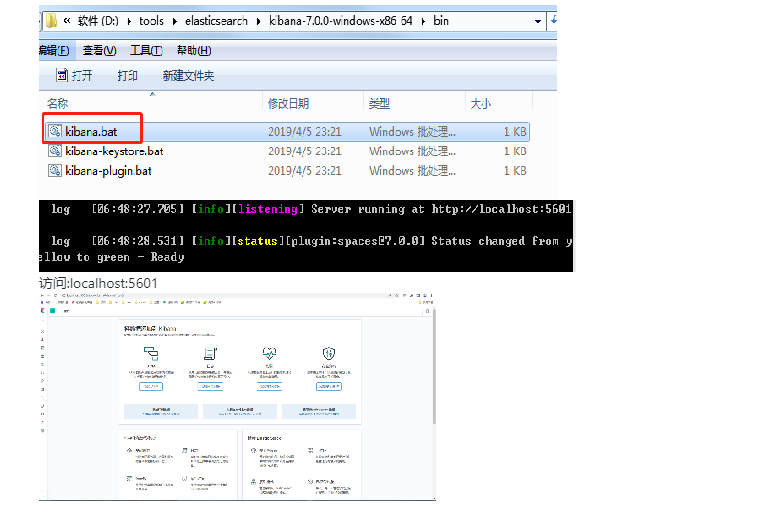
- 3.启动
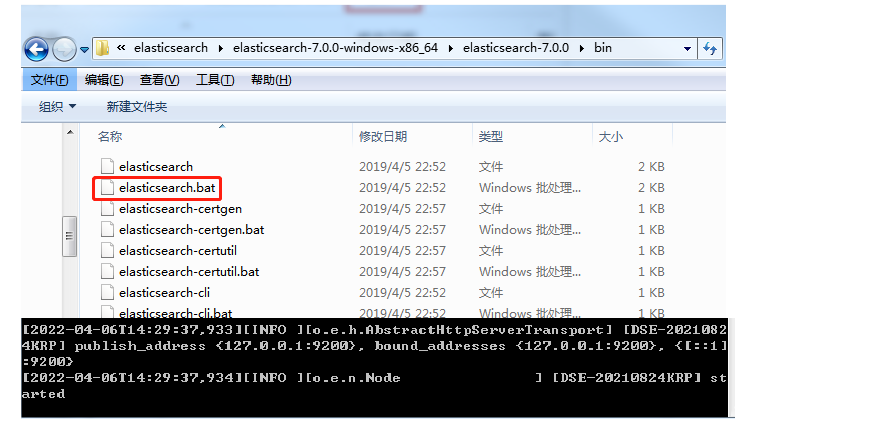
访问:localhost:9200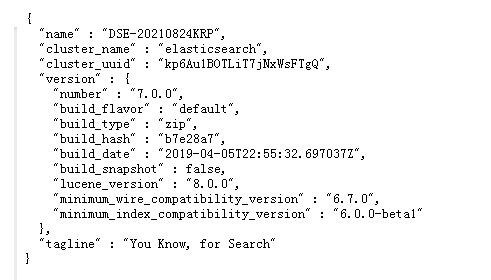
kibana安装
- 1.下载
下载的版本需要与ElasticSearch版本对应
下载地址:https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/ - 2.解压
- 3.修改配置
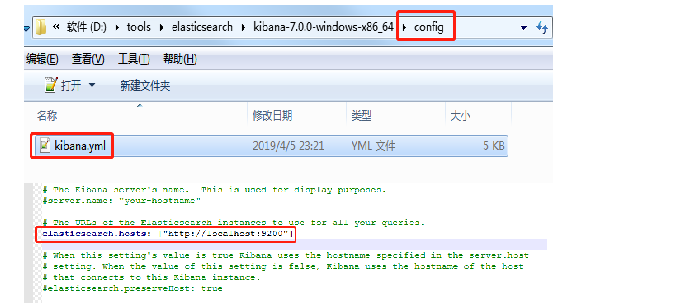
- 4.启动
核心概念
索引(Index)
ES将数据存储于一个或多个索引中。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识。一个ES集群中可以按需创建任意数目的索引。
类型(Type)
类型是索引内部的逻辑分区(category/partition),一个索引内部可定义一个或多个类型(type)。类比传统的关系型数据库领域来说,类型相当于“表”。
文档(Document)
文档是索引和搜索的原子单位,它是包含了一个或多个域(Field)的容器,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”,文档基于JSON格式进行表示。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。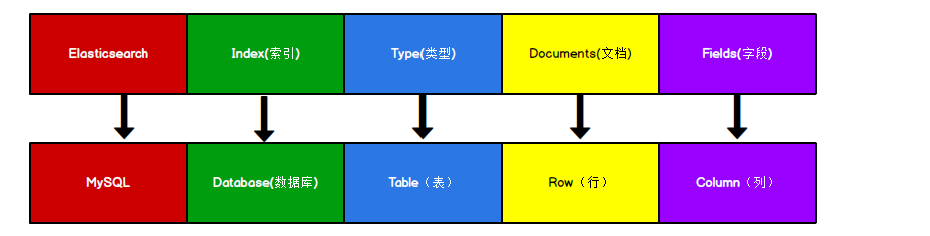
倒排索引
按(关键字,对应的文档<0个或多个>)形式建立索引,根据关键字就可直接查询对应的文档(含关键字的),无需查询每一个文档。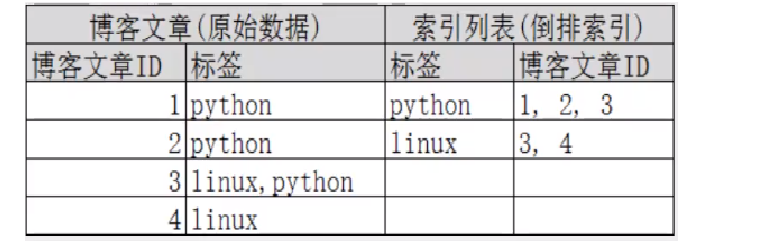
分词器
把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一一个匹配操作,默认的中文分词是standard将每个字看成一个词,比如“好好学习”会被分为”好”,”好”,”学”,”习” ,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题
GET _analyze
{
"analyzer": "standard",
"text": "好好学习"
}

IK分词器安装
- 1.下载
版本要与ElasticSearch版本对应
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases - 2.安装
ik文件夹是自己创建的
解压即可(但是我们需要解压到ElasticSearch的plugins目录ik文件夹下)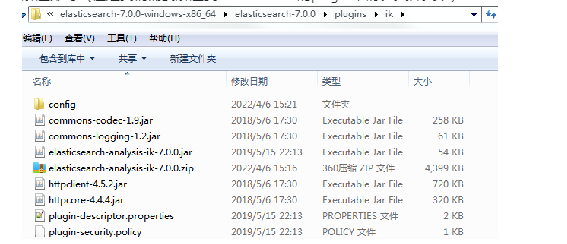
- 3.重启ElasticSearch
IK分词器测试
- ik_smart:最少切分
GET _analyze
{
"analyzer": "ik_smart",
"text": "好好学习"
}

- ik_max_word:最细粒度划分
GET _analyze
{
"analyzer": "ik_max_word",
"text": "好好学习"
}

入门实战
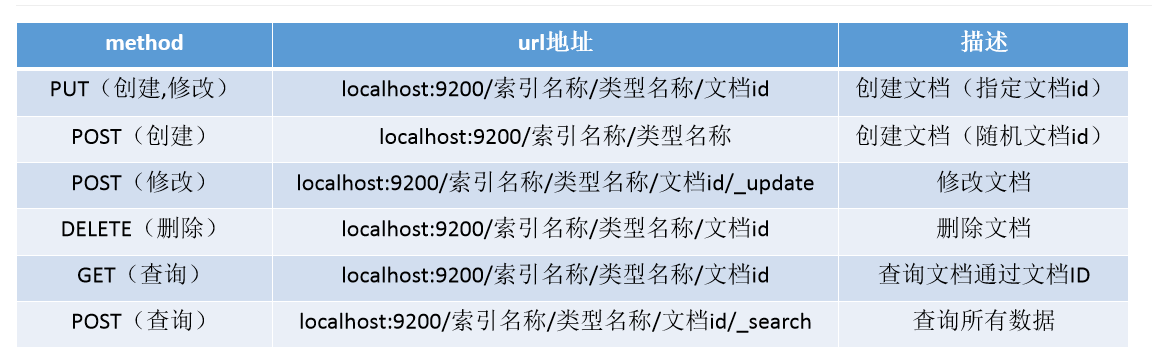
Rest命令
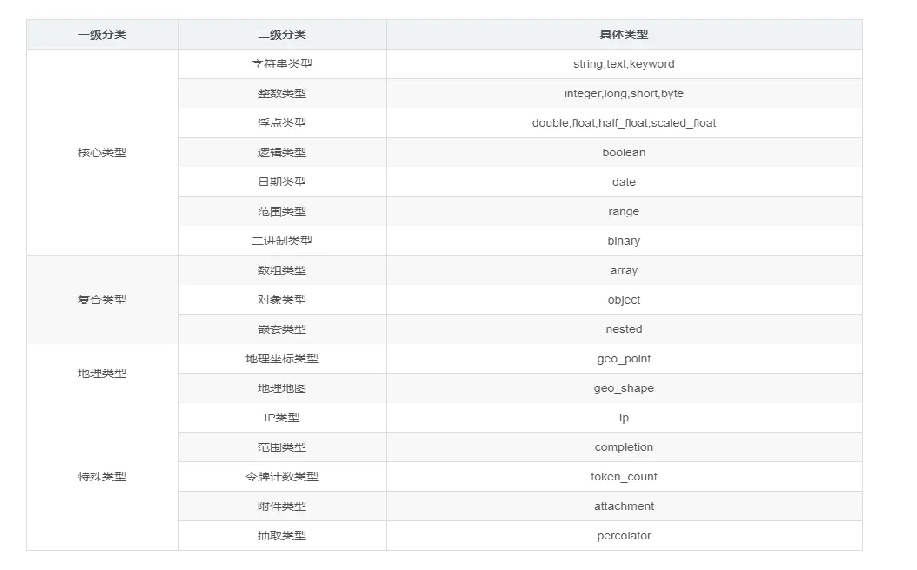
字段类型
创建索引
方式一
PUT /test1/_doc/1
{
"name" : "王小二",
"age" : 18
}
方式二
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
插入数据
PUT /test2/_doc/1
{
"name" : "王小二",
"age" : 18,
"birthday" : "1999-10-10"
}
修改数据
方式一
PUT /test2/_doc/1
{
"name" : "王小三"
}
方式二
POST /test2/_update/1
{
"doc":{
"name" : "王小四"
}
}
版本号查看
GET test2/_doc/1
方式一,版本号每次都会修改
方式二,数据有更新版本号才会修改
删除索引
DELETE /test1
查询
简单查询
GET /test2/_search?q=age:18
复杂查询
match:分词匹配(会使用分词器解析(先分析文档,然后进行查询))
term:精确匹配,适合查询 number、date、keyword ,不适合text
wildcard:模糊匹配
_source:过滤字段
sort:排序
form、size 分页
…
GET /test2/_search
{
"query":{
"match":{
"name":"小"
}
}
,
"_source": ["name","age"]
,
"sort": [
{
"age": {
"order": "asc"
}
}
],
"from": 0,
"size": 10
}
多条件查询
must 相当于 and
should 相当于 or
must_not 相当于 not (… and …)
filter 过滤
GET /test2/_search
{
"query":{
"bool": {
"must": [
{
"match":{
"age":22
}
},
{
"match": {
"name": "小"
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}
}
}

若有收获,就点个赞吧
0 人点赞
