定义
索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间。其中MySQL中的索引的存储类型有两种:BTREE、HASH。 也就是用树或者Hash值来存储该字段。
优点
- 索引大大减小了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机IO变成顺序IO
- 索引对于InnoDB(对索引支持行级锁)非常重要,因为它可以让查询锁更少的元组。在MySQL5.1和更新的版本中,InnoDB可以在服务器端过滤掉行后就释放锁,但在早期的MySQL版本中,InnoDB直到事务提交时才会解锁。对不需要的元组的加锁,会增加锁的开销,降低并发性。 InnoDB仅对需要访问的元组加锁,而索引能够减少InnoDB访问的元组数。但是只有在存储引擎层过滤掉那些不需要的数据才能达到这种目的。一旦索引不允许InnoDB那样做(即索引达不到过滤的目的),MySQL服务器只能对InnoDB返回的数据进行WHERE操作,此时,已经无法避免对那些元组加锁了。如果查询不能使用索引,MySQL会进行全表扫描,并锁住每一个元组,不管是否真正需要。
关于InnoDB、索引和锁:InnoDB在二级索引上使用共享锁(读锁),但访问主键索引需要排他锁(写锁)
缺点
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存索引文件。
- 建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
- 如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
- 对于非常小的表,大部分情况下简单的全表扫描更高效
类型
- 常规索引
常规索引,也叫普通索引(index或key),它可以常规地提高查询效率。一张数据表中可以有多个常规索引。常规索引是使用最普遍的索引类型,如果没有明确指明索引的类型,我们所说的索引都是指常规索引。
- 主键索引
主键索引(Primary Key),也简称主键。它可以提高查询效率,并提供唯一性约束。一张表中只能有一个主键。被标志为自动增长的字段一定是主键,但主键不一定是自动增长。一般把主键定义在无意义的字段上(如:编号),主键的数据类型最好是数值。
- 唯一索引
唯一索引(Unique Key),可以提高查询效率,并提供唯一性约束。一张表中可以有多个唯一索引。
- 全文索引
全文索引(Full Text),可以提高全文搜索的查询效率,一般使用Sphinx替代。但Sphinx不支持中文检索,Coreseek是支持中文的全文检索引擎,也称作具有中文分词功能的Sphinx。实际项目中,我们用到的是Coreseek。
- 外键索引
外键索引(Foreign Key),简称外键,它可以提高查询效率,外键会自动和对应的其他表的主键关联。外键的主要作用是保证记录的一致性和完整性。只有InnoDB存储引擎的表才支持外键。外键字段如果没有指定索引名称,会自动生成。如果要删除父表(如分类表)中的记录,必须先删除子表(带外键的表,如文章表)中的相应记录,否则会出错。 创建表的时候,可以给字段设置外键,如 foreign key(cate_id) references cms_cate(id),由于外键的效率并不是很好,因此并不推荐使用外键,但我们要使用外键的思想来保证数据的一致性和完整性。
索引的方法
在MySQL中,索引是在存储引擎层实现的,而不是在服务器层。MySQL支持的索引方法,也可以说成是索引的类型(这是广义层面上的),主要有以下几种:
- B-Tree 索引
如果没有特别指明类型,那多半说的就是B-Tree 索引。不同的存储引擎以不同的方式使用B-Tree索引,性能也各不相同。例如:MyISAM使用前缀压缩技术使得索引更小,但InnoDB则按照原始的数据格式存储索引。再如MyISAM通过数据的物理位置引用被索引的行,而InnoDB则根据主键引用被索引的行。B-Tree 对索引列是顺序存储的,因此很适合查找范围数据。它能够加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取需要的数据。
如果一个索引中包括多个字段(列)的值,那它就是一个复合索引。复合索引对多个字段值进行排序的依据是创建索引时列的顺序。如下:
create table people (id int unsigned not null auto_increment primary key comment '主键id',last_name varchar(20) not null default '' comment '姓',first_name varchar(20) not null default '' comment '名',birthday date not null default '1970-01-01' comment '出生日期',gender tinyint unsigned not null default 3 comment '性别:1男,2女,3未知',key(last_name, first_name, birthday)) engine=innodb default charset=utf8;
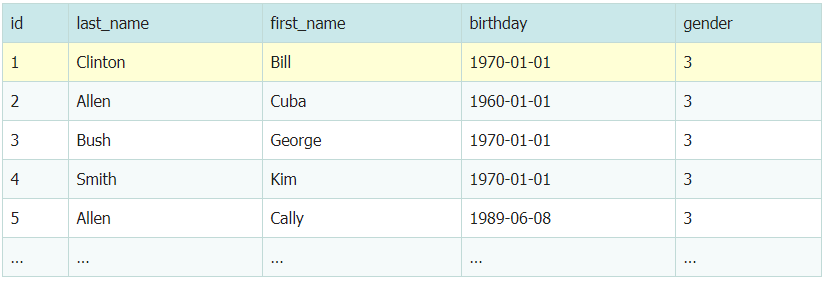
我们创建了一个复合索引 key(last_name, first_name, birthday),对于表中的每一行数据,该索引中都包含了姓、名和出生日期这三列的值。索引也是根据这个顺序来排序存储的,如果某两个人的姓和名都一样,就会根据他们的出生日期来对索引排序存储。
B-Tree 索引适用于全键值、键值范围或键前缀查找,其中键前缀查找只适用于根据最左前缀查找。
全键值查找
select id,last_name,first_name,birthday from people where last_name='Allen' and first_name='Cuba' and birthday='1960-01-01';
匹配最左前缀
select id,last_name,first_name,birthday from people where last_name='Allen';
匹配列前缀
select id,last_name,first_name,birthday from people where last_name like 'A%';
匹配范围值
select id,last_name,first_name,birthday from people where last_name BETWEEN 'Allen' And 'Clinton';
精确匹配第一列并范围匹配后面的列
select id,last_name,first_name,birthday from people where last_name = 'Allen' and first_name like'C%';
B-Tree索引是最常用的索引类型,后面,如果没有特别说明,都是指的B-Tree索引。
高效的索引策略
独立的列
我们通常会看到一些查询不当地使用索引,或者使得MySQL无法使用已有的索引,如果SQL查询语句中的列不是独立的,则MySQL就不会使用到索引。“独立的列”是指索引列不能是表达式的一部分,也不能是函数的参数。
例如:下面这条SQL查询语句,就无法使用主键索引id:
select id,last_name,first_name,birthday from people where id+1=3;
面的where表达式其实可以简写为 where id=2,但是MySQL无法自动解析这个表达式。我们应该养成简化where条件的习惯,始终将索引列单独放在比较运算符的一侧。故要想使用到主键索引,正确地写法为:
select id,last_name,first_name,birthday from people where id=2;
前缀索引和索引的选择性
有时候,我们需要索引很长的字符列,这会让索引变得大且慢。通常的解决方法是,只索引列的前面几个字符,这样可以大大节约索引空间,从而提高索引的效率。但是,也会降低索引的选择性。索引的选择性是指,不重复的索引值的数目(也称为基数)与数据表中的记录总数的比值,取值范围是0到1。
唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
添加前缀索引的方法如下:
alter table people add key(address(8)); // 只索引address字段的前8个字符
多列索引
多列索引是指一个索引中包含多个列,必须要注意多个列的顺序。多列索引也叫复合索引,如前面的 key(last_name, first_name, birthday) 就是一个复合索引。一个常见的错误就是,为每个列创建单独的索引,或者,按照错误的顺序创建了多列索引。
为每个列创建单独的索引,如下:
create table t (c1 int,c2 int,c3 int,key(c1),key(c2),key(c3));
在多个列上创建独立的单列索引大部分情况下并不能提高MySQL的查询性能。在MySQL 5.0及以后的版本中,引入了一种叫索引合并(index merge)的策略,它在一定程度上可以使用表上的多个单列索引来定位指定的行。但效率还是比复合索引差很多。
select film_id,actor_id from film_actor where actor_id=1 or film_id=1;
当出现对多个索引做相交操作时(通常有多个and条件),通常意味着需要一个包含所有相关列的复合索引,而不是多个独立的单列索引。
当出现对多个索引做联合操作时(通常有多个or条件),通常需要消耗大量的CPU和内存资源在算法的缓存、排序和合并操作上。此时,可以将查询改写成两个查询Union的方式:
select film_id,actor_id from film_actor where actor_id=1union allselect film_id,actor_id from film_actor where film_id=1 and actor_id<>1;
最容易引起困惑的就是复合索引中列的顺序。在复合索引中,正确地列顺序依赖于使用该索引的查询,并且同时需要考虑如何更好地满足排序和分组的需要。索引列的顺序意味着索引首先按照最左列进行排序,其次是第二列,第三列…。所以,索引可以按照升序或者降序进行扫描,以满足精确符合列顺序的order by、group by和distinct等子句的查询需求。当不需要考虑排序和分组时,将选择性最高的列放到复合索引的最左侧(最前列)通常是很好的。这时,索引的作用只是用于优化where条件的查找。但是,可能我们也需要根据那些运行频率最高的查询来调整索引列的顺序,让这种情况下索引的选择性最高。
以下面的查询为例:
select * from payment where staff_id=2 and customer_id=500;
是应该创建一个 key(staff_id, customer_id) 的索引还是 key(customer_id, staff_id) 的索引?可以跑一些查询来确定表中值的分布情况,并确定哪个列的选择性更高。比如:可以用下面的查询来预测一下:
select sum(staff_id=2), sum(customer_id=500) from payment\G
假如,结果显示:sum(staff_id=2)的值为7000,而sum(customer_id=500)的值为60。由此可知,在上面的查询中,customer_id的选择性更高,应该将其放在索引的最前面,也就是使用key(customer_id, staff_id) 。
尽管,关于选择性和全局基数的经验法则值得去研究和分析,但一定别忘了order by、group by 等因素的影响,这些因素可能对查询的性能造成非常大的影响。

若有收获,就点个赞吧
0 人点赞
