本章概述
- 分布式搜索引擎
- 搜索引擎技术选型
- 什么是Elasticsearch?
- ES可视化插件、IK分词器、词库
- ES快速入门、核心术语、文档结构
- 安装ES、基本操作
- DSL操作
- ES集群原理
- ES与数据库数据同步
- ES与SpringBoo整合实现搜索
- ES的geo坐标搜索
目前搜索弊端
- 空格支持
- 拆词查询
- 搜索内容不能高亮
- 海量数据查库
ES安装

1、es官网下载或github下载
官网:https://www.elastic.co/cn/
github:https://github.com/elastic/elasticsearch/releases
2、上传至Linux中
拷贝到 /usr/local/elasticsearch-x-x-x/ 文件夹下
什么是分布式搜索引擎
搜索引擎
分布式存储与搜索
Luncene vs Solr vs Elasticsearch
倒排序索引
Luncene是类库
Solr基于Lucene
Es基于Lucene
Es核心术语
| 索引 index | 表 |
|---|---|
| 类型 type【较少使用】 | 表逻辑类型 |
| 文档 document | 行 |
| 字段 fields | 列 |
| 映射 mapping | 表结构定义 |
| 近实时 NRT | Near real time |
| 节点 node | 每一个服务器 |
| shard replica | 数据分片与备份 |
倒排索引
分词与内置分词器
DSL搜索
1、查询全部数据
{"query": {"match_all": {}}}query 查询条件match_all 匹配所有
2、只显示对应字段
{"query": {"match_all": {}},"_source": ["id","nickename","age"]}_source 数据源,只返回数组中包含的结果
3、加上分页查询
{"query": {"match_all": {}},"_source": ["id","nickename","age"],"from": 0,"size": 5}from 起始页size 结束页
4、term与match区别
{"query": {"term": {"desc": "慕课网强大"}},"_source": ["id","nickename","age","desc"]}# term 不会进行拆分# match 会根据关键字拆分进行查询{"query": {"match": {"desc": "慕课网强大"}},"_source": ["id","nickename","age","desc"]}# terms 匹配多个字段,包含结果的都会返回{"query": {"terms": {"desc": ["慕课网", "学习"]}},"_source": ["id","nickename","age","desc"]}
5、match
1、match_phrase 短语
{"query": {"match_phrase": {"desc": {"query": "伞兵 准备","slop": 4}}},"_source": ["id","nickename","age","desc"]}match_phrase 短语slop 词汇之间数量
2、minimum_should_match 【最小值匹配】
{"query": {"match": {"desc": {"query": "慕课网学习","minimum_should_match": "40%"}}},"_source": ["id","nickename","age","desc"]}minimum_should_match 最少要匹配40%也可以设置为1
3、multi_match [多条件查询]
{"query": {"multi_match": {"query": "慕课网","fields": ["desc", "nickename"]}},"_source": ["id","nickename","age","desc"]}# ^10 提高当前字段搜索权重"fields": ["desc", "nickename^10"]multi_match 多匹配规则query 查询结果fields 查询多个字段
6、根据ids查询指定数据
{"query": {"ids": {"type": "_doc","values": ["1001", "1002"]}},"_source": ["id","nickename","age","desc"]}ids id字段values 多个对应的值
7、bool 查询
{"query": {"bool": {"must": [{"multi_match": {"query": "慕课网","fields": ["desc","nickename"]}},{"term": {"sex": 1}},{"term": {"birthday": "1989-01-14"}}]}}}must 可以匹配多个条件,must本身是数组,因此可以加入多个查询对象:muti_match\term等等must_not 不相等的多个条件should 查询在mysql中就好比是or或,es中需要搭配must一起使用boost 分值排序往前 分数设置越高,查询结果越往前面{"query": {"bool": {"should": [{"match": {"desc": {"query": "慕课网","boost": 2}}},{"match": {"desc": {"query": "凡人","boost": 10}}}]}}}
8、post_filter 过滤查询出来的数据,不影响查询条件
{"query": {"match": {"desc": "学习"}},"post_filter": {"range": {"money": {"gt": 180,"lt": 200}}}}post_filter 过滤查询条件range 范围 gt lt gte lte 类似mysql中 大于小于 大于等于 小于等于
Elasticsearch 集群
将分片平均分配到多个服务器上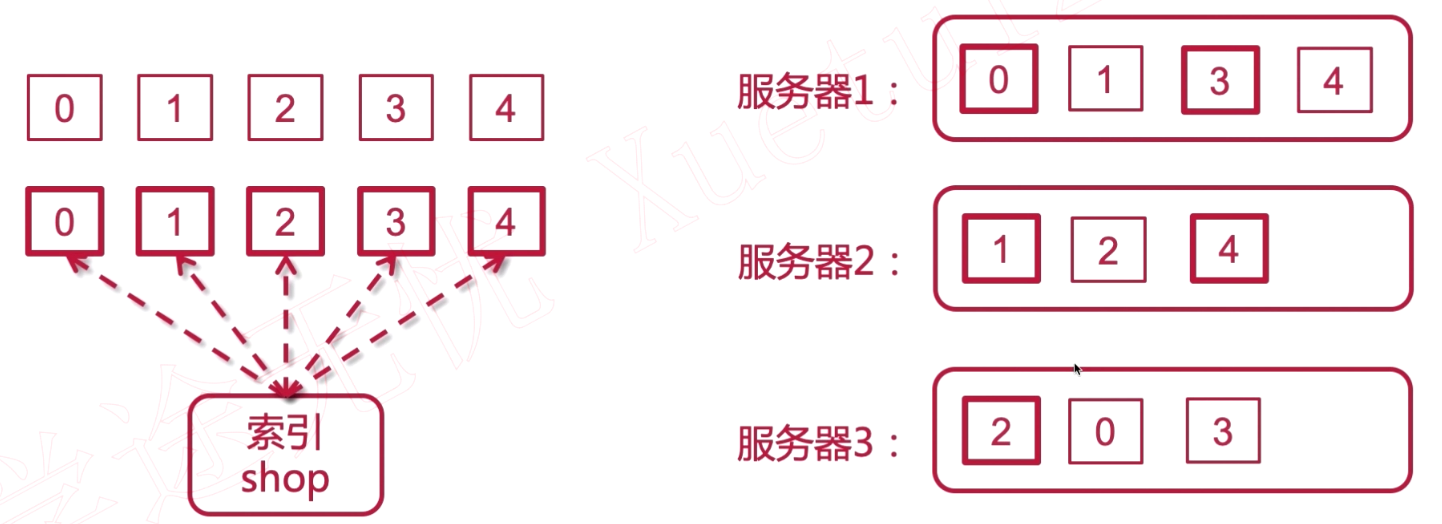
搭建集群前提条件
- 至少需要两台服务器,一主一从,都需要安装 ES 环境
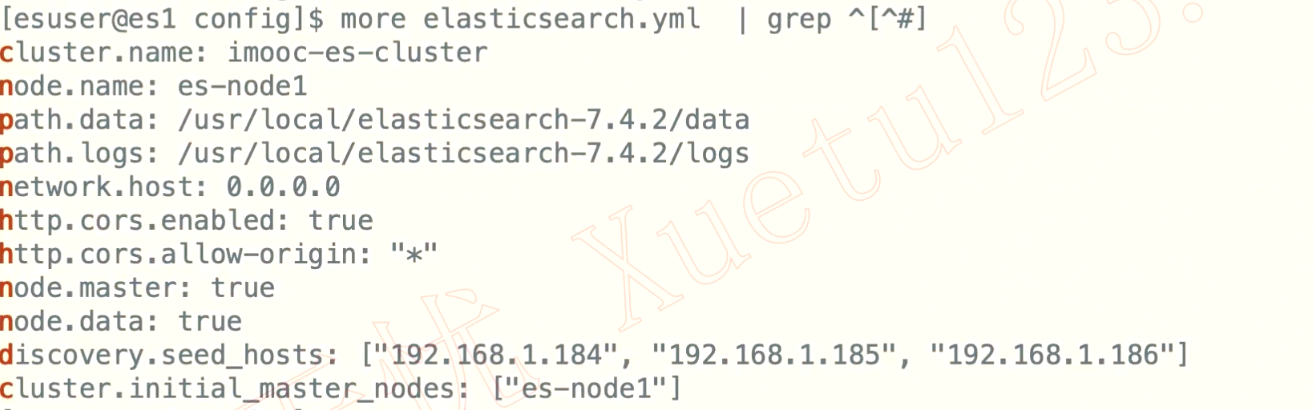
1、更改elasticsearch.yml
cluster.name: imooc-es-clusternode.name: es-node1# 其他master挂掉后,可以竞选为masternode.master: true# 数据处理node.data: true# 发现节点discovery.seed_hossts: ["192.168.128.128", "192.168.128.129", "192.168.128.130"]# 获取文件中没有被注释的配置more elasticsearch.yml | grep ^[^#]
Elasticsearch 文档读写原理
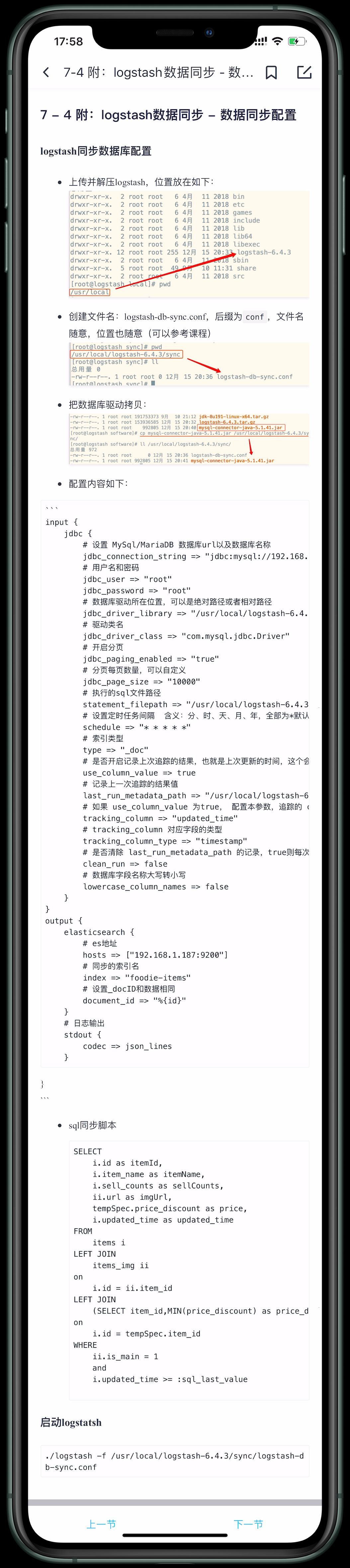
LogStatsh同步
- 数据采集
- 以id或update_time作为同步边界
- logstash-input-jdbc插件
- 预先创建索引
下载地址:https://www.elastic.co/cn/downloads/logstash

{"version": 1,"index_patterns": ["*"],"settings": {"index": {"refresh_interval": "5s"}},"mappings": {"_default_": {"dynamic_templates": [{"message_field": {"path_match": "message","match_mapping_type": "string","mapping": {"type": "text","norms": false}}},{"string_fields": {"match": "*","match_mapping_type": "string","mapping": {"type": "text","norms": false,"analyzer": "ik_max_word","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}],"properties": {"@timestamp": {"type": "date"},"@version": {"type": "keyword"},"geoip": {"dynamic": true,"properties": {"ip": {"type": "ip"},"location": {"type": "geo_point"},"latitude": {"type": "half_float"},"longitude": {"type": "half_float"}}}}}},"aliases": {}}
input {jdbc {# 设置 MySql/MariaDB 数据库url以及数据库名称jdbc_connection_string => "jdbc:mysql://192.168.56.1:3306/foodie-shop?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&useSSL=false"# 用户名和密码jdbc_user => "root"jdbc_password => "5201314"# 数据库驱动所在位置,可以是绝对路径或者相对路径jdbc_driver_library => "/usr/local/logstash-6.4.3/sync/mysql-connector-java-8.0.11.jar"# 驱动类名jdbc_driver_class => "com.mysql.cj.jdbc.Driver"# 开启分页jdbc_paging_enabled => "true"# 分页每页数量,可以自定义jdbc_page_size => "1000"# 执行的sql文件路径statement_filepath => "/usr/local/logstash-6.4.3/sync/foodie-items.sql"# 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务schedule => "* * * * *"# 索引类型type => "_doc"# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件use_column_value => true# 记录上一次追踪的结果值last_run_metadata_path => "/usr/local/logstash-6.4.3/sync/track_time"# 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间tracking_column => "updated_time"# tracking_column 对应字段的类型tracking_column_type => "timestamp"# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录clean_run => false# 数据库字段名称大写转小写lowercase_column_names => false}}output {elasticsearch {# es地址hosts => ["192.168.128.128:9200"]# 同步的索引名index => "foodie-items"# 设置_docID和数据相同# document_id => "%{id}"document_id => "%{itemId}"# 定义模板名称template_name => "myik"# 模板所在位置template => "/usr/local/logstash-6.4.3/sync/logstash-ik.json"# 重写模板template_overwrite => true# 默认为true false 关闭 logstash自动管理模板功能,如果自定义模板,则设置为falsemanage_template => false}# 日志输出stdout {codec => json_lines}}

若有收获,就点个赞吧
0 人点赞
