https://ververica.cn/developers/flink-kafka-end-to-end-exactly-once-analysis/
合的,序列化和比较时会委托给对应的 serializers 和 comparators。如下图展示 一个内嵌型的 Tuple3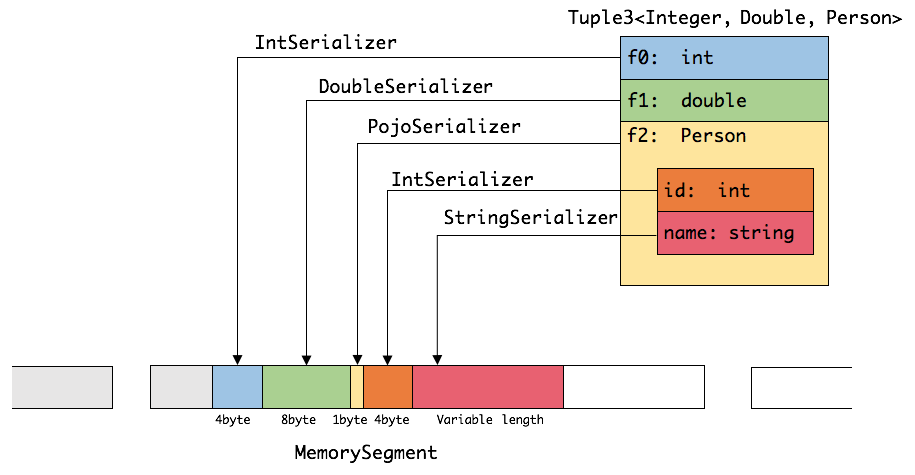
可以看出这种序列化方式存储密度是相当紧凑的。其中 int 占4字节,double 占8字节,POJO 多个一个字节的 header,PojoSerializer 只负责将 header序列化进去,并委托每个字段对应的 serializer 对字段进行序列化。
首先,Flink 会从 MemoryManager 中申请一批 MemorySegment,我们把这批 MemorySegment 称作 sort buffer,用来存放排序的数据。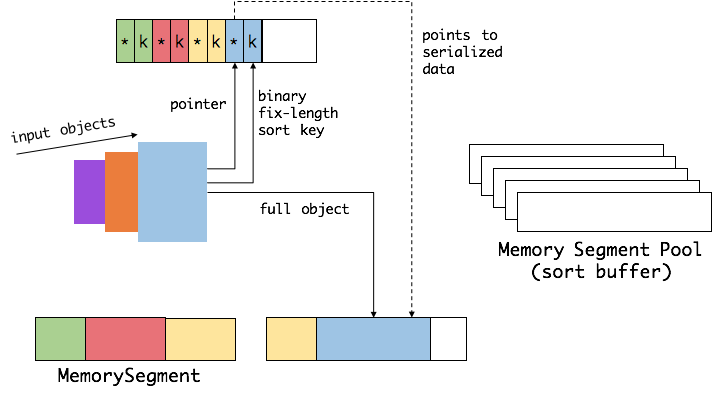
我们会把 sort buffer 分成两块区域。一个区域是用来存放所有对象完整的二进制数据。另一个区域用来存放指向完整二进制数据的指针以及定长的序列化后的key(key+pointer)。如果需要序列化的 key 是个变长类型,如 String,则会取其前缀序列化。如上图所示,当一个对象要加到 sort buffer 中时,它的二进制数据会被加到第一个区域,指针(可能还有 key)会被加到第二个区域。

若有收获,就点个赞吧
0 人点赞
