Canvas
保存为图片
toDataUrl(type='image/png', encoderOptions=0.92)
生成该图片的一个DataUrl
Data URLs是一种前缀为data:协议的URL,其允许内容的创建者在文档中嵌入小文档。 url中可以使用base64编码,url中包括了这个小文件的所有信息。 详情见:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/Data_URIs
canvas.toBlob(callback: (blob) => {}, type='image/png', encoderOptions)
文件/网络请求
Blob和File
blob就是一个二进制存储体,构造时需要传入一个可迭代。
file在其之上构建了一个文件需要的额外信息,如
TCP
三次握手四次挥手
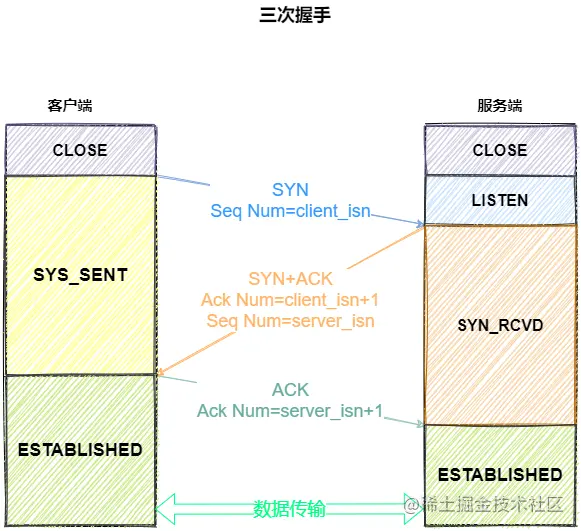
三次握手第一次是服务端确保客户端发送和服务端接收能力,第二次是客户端确保服务端发送和接收能力,第三次是服务端确保自己发送能力和客户端接收能力
四次挥手是客户端先请求关闭,然后服务端收到关闭请求并返回。
之后服务端仍可单方向发送未发完的数据,发送之后,客户端回复收到即关闭。
最后等待2MSL的原因是,如果服务端没有收到最后的ACK,会重传第三个报文。等待可以应对这种情况。
两端均可主动断开链接
传文件所需时间
一来一回的时间称为一个RTT
首先客户端需要建立TCP三次握手,会一来一回再来,然后服务器会将文件发给客户端。这个过程还需要额外加入一个准备文件以发送的处理时间。
直到文件内容到达,至少2个RTT。后面还会四次挥手,这个不计了。
http1.1
http协议使用TCP进行信息的传输,通过三次握手连接后,发送相应的信息,然后立马四次挥手断掉TCP。是无状态的协议。
http的一些特性,如缓存等等是通过http字段的情况达成的。
nodejs 的 http 是使用的 http1.1 协议。此外还有 http2 和 https 两个模块。
- URL
https://juejin.cn/post/6844904100035821575#heading-9
格式:协议://ip:host或域名/路径?query(传参)#fragment(页内定位)
实际上,URL的值就是用户在浏览器中输入的地址。
query表示查询参数,为key=val这种形式,多个键值对之间用&隔开。
url路径和传参一般是一个webapp需要编程操作的。
注意url只能使用ascii,所以不在其中的字符(如汉字)会转为十六进制字节值变成%xx这种东西。
- 请求方法
对于请求来说,该部分是get等请求方法;对于响应来说,该部分是200等响应状态码。该值不仅只是一个语义标识,确实对浏览器的行为产生影响。
注意:
你想要修改http的报文来实现特定的逻辑的功能,本质上确实是设置头部和返回体。
但是涉及到功能整体性和各方面性质的考虑,你还要进行二次封装和一些全局化的功能设置。
像express等框架是给你做好了一些二次封装的。
在具体进行http通信时,一般具有这些特点:
- 大多数时候(有例外吗?例外如何?)是客户端请求,服务端响应。
客户端不会响应服务器请求,反之服务端也不会请求客户端。 -
DNS
DNS服务器解析域名的过程:
首先会在浏览器的缓存中查找对应的IP地址,如果查找到直接返回,若找不到继续下一步
- 将请求发送给本地DNS服务器,在本地域名服务器缓存中查询,如果查找到,就直接将查找结果返回,若找不到继续下一步(递归查询)
- 本地DNS服务器向根域名服务器发送请求,根域名服务器会返回一个所查询域的顶级域名服务器地址(迭代查询)
- 然后本地DNS服务器向顶级域名服务器发送请求,接受请求的服务器查询自己的缓存,如果有记录,就返回查询结果,如果没有就返回相关的下一级的权威域名服务器的地址
- 本地DNS服务器向授权域名服务器发送请求,域名服务器返回对应的结果,此外将返回结果保存在缓存中,便于下次使用
- 本地DNS服务器将返回结果返回给浏览器
关于递归查询和迭代查询:
浏览器->本地DNS->rootDNS,本地DNS找不着会接着去查root,不是让用户浏览器去查,这个是递归本地DNS->rootDNS->本地DNS->顶级域名服务器,root不是访问顶级域名服务器往下查,只是给本地DNS地址,让他自己干,这是迭代
本地DNS服务器
是你在电脑上配置的要去查找的DNS服务器,一般是指你电脑上网时IPv4或者IPv6设置中填写的那个DNS,可能是局域网DHCP指定的也可能是自己分配的
根域名服务器
分ipv4和ipv6的根域名服务器,存储.com .org .edu等顶级域名服务器的地址。
ipv4的根域名服务器全球13台,具体可以搜
通用头字段
主要包括Date``Cache-Control``Connection
Cache-control(缓存及控制)
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Caching
https://juejin.cn/post/6960988505816186894
https://juejin.cn/post/6844903512946507790
响应需要满足基本条件才有可能被缓存。
缓存一般分为两种,保存在浏览器中的私有缓存,和保存在代理服务器中的公共缓存。
除此之外还有网关缓存、CDN、反向代理缓存和负载均衡器等部署在服务器上的缓存方式
在遇到get请求的时候,如果能够找到缓存会直接返回结果并拦截该请求。
对浏览器缓存进行设置,分为客户端的请求,和服务器的响应。
请求头里的Cache-Control影响的是当前这一次请求,响应头里的Cache-Control是告诉浏览器这样存储,下次依照这样来。影响的是下一次请求。
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Cache-Control
分为这几个模块
- 可以被谁缓存:
public都可以private只能被浏览器缓存no-store不能有no-cache在发布缓存副本之前,强制要求缓存把请求提交给原始服务器进行验证(协商缓存验证)。 - 过期时间:
max-age=<seconds>过期时间,共享缓存可以用s-maxage覆盖该设置。
缓存过期之后会变成陈旧的。过期不意味着无效,只是优先被清理,如果不设置must-revalidate浏览器会直接用过期的缓存顶上去,且不给服务器发http请求。 - 重新验证:
must-revalidate在过期后必须向服务器重新验证,验证有效可以继续使用。proxy-revalidate效果一样但应用于代理服务器。
注意:maxage=0, must-revalidate与no-cache等价Content-Type(数据内容类型)
设定发送的数据mime类型。
在请求头中是post类请求发送的数据的类型,
在响应头中是响应体数据的类型。Content-Type: text/html; charset=utf-8Content-Type: multipart/form-data; boundary=somethingconnection
早期的 HTTP 协议使用短连接,多个请求响应每一个都要TCP三握四挥,效率很低;
HTTP/1.1 默认启用长连接(Connection: keep-alive),多个请求响应使用一个TCP连接,不过这样也需要连接及时关闭;
无论是请求还是响应,报文头里如果有Connection: close就意味着长连接即将关闭;
过多的长连接会占用服务器资源,所以服务器会用一些策略有选择地关闭长连接;
“队头阻塞”问题会导致性能下降,可以用“并发连接”和“域名分片”的方式缓解。chunk transfer
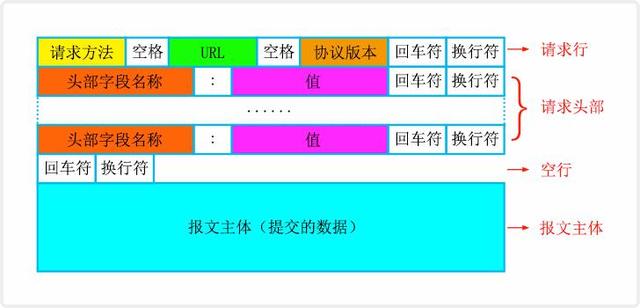
HTTP/1.1 通过引入 Chunk transfer 机制来解决这个问题,服务器会将数据分割成若干个任意大小的数据块,每个数据块发送时会附上上个数据块的长度,最后使用一个零长度的块作为发送数据完成的标志。这样就提供了对动态内容的支持。请求/请求头字段
实质上请求就是发信息,你要干的事情肯定都包括在报文里边儿。
定义请求类型实际上是一个约定性的玩意儿,对怎样的请求做出怎样的相应。实际上你在写代码的时候并不一定完全遵守。
请求的类型,或者说方法method的语义作用:
| 类型 | 语义作用 | 实际与其它类型的区别 |
|---|---|---|
| GET | 请求得到url的资源 |
相同请求结果相同且被缓存,且只能通过url传参 |
| POST | 给url发送data,具体干啥随意 |
不被缓存,可以传别的比如文件 |
| PUT | 用data覆盖掉url处资源 |
|
| PATCH | 使用data增量更新url处资源 |
|
| DELETE | 删除url处资源 |
|
| HEAD | 稀少,没见过用法 | |
| DELETE | 稀少,没见过用法 | |
| OPTIONS | 稀少,没见过用法 | |
| TRACE | 稀少,没见过用法 |
请求幂等特性:某个请求发一次和发多次在影响层面上没有区别。get随便
时机:直接请求网站是get请求,一般提交表单,文件等是post请求(可以设置)。
get和post的区别
请求需要一个url。但是可以不跳转。
请求的方式除了表单提交之外,还有ajax。目前专门通过fetch来做ajax。
user-agent
User-Agent: <product> / <product-version> <comment>
可以提供浏览器的信息。但是该字段可以被伪造。
如果担心该字段被伪造,可以使用对客户端进行能力检测来确定(红宝书第13章有讲到)
accept
accept系列头,用于处理接受怎样的响应,如果响应不对,会发生目前未知的意外情况accept头表示接受怎样的mime类型,可通过分隔符/多选
响应/响应头字段
200:成功
30x:重定向
40x:客户端错误,常见的400:Bad Request,403:无权限,404:找不着
50x:服务器错误,你webapp写的有问题,去扒你的代码!
- 返回的状态码一定程度上是编程时可以设置的
状态码本身不仅有语义,还会影响到浏览器的行为。而且这种影响比较复杂,难以configure。 涉及到的:
- 浏览器缓存
cookies/localstorage/sessionstorage
这三个信息都是保存在浏览器中的。
- cookie
服务器可以通过http头中包括set-cookie,设置cookie值
客户端每次请求都会把cookie放到http头中发出去
cookie最大4kB
cookie有过期时间。不设置默认是关闭浏览器就过期。
- localstorage
- sessionstorage
Set-Cookie
Set-Cookie: <cookie-name>=<cookie-value>[; options]
客户端每次请求都会把cookie放到http头中发出去。
而且,在一些情况下,即使是跨域请求的cookie也会存!
max-age(有效时间)expires(过期时间) |
关于何时过期,如果不设置认为是会话期cookie,在客户端关闭时被移除。 |
|---|---|
secure |
为true意味着只能在 https 中有效 |
HttpOnly |
不允许Document.cookie``XMLHttpRequest``Request APIs等前端方式访问cookie |
path |
受影响的路径,如果有值则必须路径匹配(在该路径下/该路径子路径下)的cookie键值对才会发入 |
跨域相关/CORS
用户访问的url,会放在origin字段,之后从html通过脚本/link等发送资源请求时,不一定会请求哪里,但是确实是从origin来做请求。
只要协议、域名、端口有任何一个不同,都被当作是不同的域。
跨域情况下,浏览器允许发请求,服务端也能响应。但是返回的响应,如果没字段会被浏览器截胡,不能应用(不是不允许发)
涉及到的字段:
响应头Access-Control-Allow-Origin:允许怎样的域名给我发跨域请求,*为全部ok
以下是解决方案:
- jsonp
script 标签 src 属性中的链接却可以访问跨域的 js 脚本,利用这个特性,服务端不再返回 JSON 格式的数据,而是返回一段调用某个函数的 js 代码,在 src 中进行了调用,这样实现了跨域。 - CORS
服务器设置Access-Control-Allow-Origin HTTP响应头之后,浏览器将会允许对应站点的跨域请求 - document.domain
基础域名相同 子域名不同 - window.name
利用在一个浏览器窗口内,载入所有的域名都是共享一个window.name nginx反向代理,常用
反向代理就相当于是,访问一个分布式集群做服务器的网站,访问这个网站,是哪个服务器给它服务呢?
nginx这样的反向代理就相当于是这个网络的entry,将用户的请求派发到对应的集群服务器上。https
由于http是明文传输,所以需要在tcp和http层之间加入安全层次(ssl/tls)来使得传输层次以下都是密文传输。
证书
证书申请
如何申请数字证书我们先来看看如何向 CA 申请证书。
比如极客时间需要向某个 CA 去申请数字证书,通常的申请流程分以下几步:首先极客时间需要准备一套私钥和公钥,私钥留着自己使用;
- 然后极客时间向 CA 机构提交公钥、公司、站点等信息并等待认证,这个认证过程可能是收费的;
- CA 通过线上、线下等多种渠道来验证极客时间所提供信息的真实性,如公司是否存在、企业是否合法、域名是否归属该企业等;
- 如信息审核通过,CA 会向极客时间签发认证的数字证书,包含了极客时间的公钥、组织信息、CA 的信息、有效时间、证书序列号等,这些信息都是明文的,同时包含一个 CA 生成的签名。
这样我们就完成了极客时间数字证书的申请过程。前面几步都很好理解,不过最后一步数字签名的过程还需要解释下:首先 CA 使用 Hash 函数来计算极客时间提交的明文信息,并得出信息摘要;然后 CA 再使用它的私钥对信息摘要进行加密,加密后的密文就是 CA 颁给极客时间的数字签名。这就相当于房管局在房产证上盖的章,这个章是可以去验证的,同样我们也可以通过数字签名来验证是否是该 CA 颁发的。
浏览器验证ca证书:
有了 CA 签名过的数字证书,当浏览器向极客时间服务器发出请求时,服务器会返回数字证书给浏览器。
浏览器接收到数字证书之后,会对数字证书进行验证。
首先浏览器读取证书中相关的明文信息,采用 CA 签名时相同的 Hash 函数来计算并得到信息摘要 A;
然后再利用对应 CA 的公钥解密签名数据,得到信息摘要 B;
对比信息摘要 A 和信息摘要 B,如果一致,则可以确认证书是合法的,即证明了这个服务器是极客时间的;
同时浏览器还会验证证书相关的域名信息、有效时间等信息。
这时候相当于验证了 CA 是谁,但是这个 CA 可能比较小众,浏览器不知道该不该信任它,然后浏览器会继续查找给这个 CA 颁发证书的 CA,再以同样的方式验证它上级 CA 的可靠性。
通常情况下,操作系统中会内置信任的顶级 CA 的证书信息(包含公钥),如果这个 CA 链中没有找到浏览器内置的顶级的 CA,证书也会被判定非法。
另外,在申请和使用证书的过程中,还需要注意以下三点:
- 申请数字证书是不需要提供私钥的,要确保私钥永远只能由服务器掌握;
- 数字证书最核心的是 CA 使用它的私钥生成的数字签名;
内置 CA 对应的证书称为根证书,根证书是最权威的机构,它们自己为自己签名,我们把这称为自签名证书。
websocket
实践
实践分为三层:
http报文->fetch/xhr->封装请求库(axios等)每一层封装都是在怎样的层次?
- 这三个层次哪一些特性或设计是相通的?
axios
axios是一个请求库,浏览器环境下是xhr的封装,nodejs环境下是http的封装。
devtools 网络
restful api
是一种api设计风格,自然应用了http协议的features。
比较适合简单的业务
graphQL
具体业务
页面跳转
触发页面跳转主要是以下的情况:
1. 超链接跳转
2. 提交表单跳转
3. ajax的post类请求,响应中通过重定向跳转,get类请求是不会跳转的(?)
大文件上传
Web RTC 协议
前端安全
csrf
csrf 攻击是用户点击陌生链接起作用的。
比如,用户登录了一个网站,浏览器保存了他的登录信息,这时浏览器向网站服务器发送各种权限操作的请求均可以。
例如/转账?目标=转账人。
如果黑客的陌生网页,会执行一个ajax请求,是对应目标网站的/转账?目标=黑客路径,
那么当被害人点进去了之后,这个请求就会执行,然后被害人就无了
防治方式:
- cookie samesite
- 检验 referer 和 origin 头(没大有用,毕竟请求可以伪造,必须得有不能被知道的信息)
referer 头是完整的,指引到当然网站的 url,origin 头是源域名 - csrf token
在浏览器发出权限请求时,后端生成一个csrf token给到网页上响应。
这样客户端就知道了,后面的权限请求需要有这个csrf token才能执行
常识列表(之后在分类)
Base64
是用64个可打印字符,来表示二进制数值。是平常字符和二进制码的一种转换方式。
这个格式的存在就只是可以文本解码,但是损失信息空间。

若有收获,就点个赞吧
0 人点赞
