基本
libuv:https://zhuanlan.zhihu.com/p/50497450
v8专栏:https://www.zhihu.com/column/v8core
EventEmitter
通过发布订阅模式进行事件处理。
主要功能:链式调用on/once/prependListener/prependOnceListener(name, listener):
给name事件加listener。其中:
once事件发生时会先移除在调用listener,只发生一次prepend是将listener放在数组开头
off(name, listener)/removeAllListeners(...listeners):
移除name事件添加的这个listener函数。
- 对
off,如果该listener有多个重复的只删一个,想全删就多调用
emit(name[,...args]):给该名称的事件监听器派发事件,返回是否有监听器
具有两个事件:newListener(eventName, listener)和removeListener(eventName, listener)
Stream
http://nodejs.cn/api/stream.html
https://juejin.cn/post/7077511716564631566
说实话,流这个东西,叫管道更好理解。
它的意义,主要是进行多个过程操作的时候,每个过程都是一段管道,前面流出一点,后面就收一点然后继续往下流。说实话可以整成一个有向无环图(误)
一般使用四种管道类型:Readable只能出不能入,类似水源。Writeable只能入不能出,类似水桶。Duplex能入,且能出。但是不同数据源。类似于水源和水桶捆起来。Transform将写入转换后作为输出,就是实现转换的Duplex,类似滤水器。
缓冲区
所有流除了链接到真正的源/目标(如:底层文件系统)之外,在外部接口之间还有一个缓冲区。
readable
构造函数选项:read([size]):真正从源(可能是文件系统)读入数据的过程。这里面需要调用push(chunk)将数据块压入缓冲区。
两种模式/三种状态
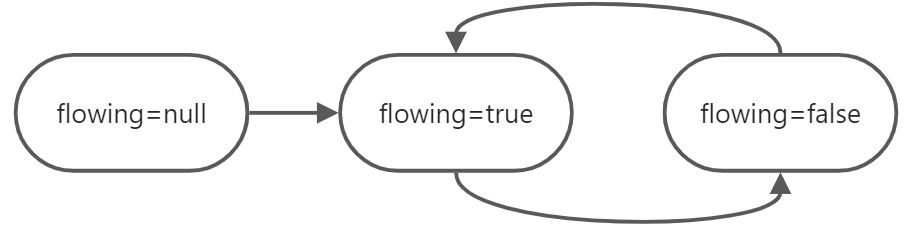
readableFlowing为null/false时,处于暂停状态。
可以通过resume()、pipe(writeable)使之流动。
此外在初始null状态时,挂载data事件也可以启动为
true时,处于流动状态,数据会自动流出(此时应该有可写流接入了或者有事件接收了)
可以通过pause()、unpipe()移除所有接入的写管道,或者背压,改为false数据消费机制
可选的有这几种:
on('data')、on('readable')、pipe()或异步迭代器。使用一种即可,尽量不要混用,不然非常confusing。不想纠结优先级相关。具体而言:挂载
data,然后数据自动流动,从data的listener中拿数据。
通过pause()``resume()控制是否暂停,通过end事件确定数据读取完成。- 挂载
readable,手动一次次read()读取数据,直到读到的为null优先 pipe(writeable),自动管理流速防止背压问题。注:这个是由stream的api实现的
事件:readable表明流有新的数据可以读取。end事件表明流已经榨干了,没新数据可读了
readable.read([size])从可读流读入。如果没有数据可读,会返回null并触发end事件readable.[pipe](http://nodejs.cn/api/stream.html#readablepipedestination-options)(writable[,options])可读流灌入可写流,并返回可写流。然后可读流数据会自动持续的加入可写流。如果写入的是双工流,可以链式调用
writable
事件
pipe(readable)``unpipe(readable)指明哪个可读流灌入或移出drain()是把缓冲区数据写入底层后触发的事件,这个触发之后可以再写了finish()是所有数据已写入底层,结束写入后触发
writeable.write(content)写入writeable.end(content)写完content之后结束写入。注意写流的结束是程序员主动结束的。
transform
转换流没有了“底层”,不用实现_read``_write,主要实现_transform(chunk, encoding, callback)(转换并通过push加入)和_flush(callback)(即将结束之前通过push额外写入一段数据)
全局变量
路径
__dirname:返回被执行的Js所在文件夹的目录__filename:返回被执行的Js的绝对路径process.cwd():返回运行node命令时所在的文件夹的绝对路径./:在require()中跟__dirname效果相同,在其他地方跟process.cwd()相同
框架(express=>koa=>egg)
https://www.yuque.com/lipengzhou/nodejs-tutorial
nodejs的框架确实是一脉相承的。从express到Koa到egg,都是非常类似的思路。
express确实是一个非常轻量级的框架,源代码只有4000行左右,比我写的一些项目都小,很不错了。
但是Koa源码更少,才600行左右,瞬间有了一种我上我也行的错觉。
基本业务逻辑说明
url解析
直接从ctx拿变量:
对于[http://localhost:3000/json?a=1&b=2#abc](http://localhost:3000/json?a=1&b=2#abc),结果如下:
{"href": "http://localhost:3000/json?a=1&b=2","path": "/json","url": "/json?a=1&b=2","query": {"a": "1","b": "2"},"querystring": "a=1&b=2","search": "?a=1&b=2","host": "localhost:3000","hostname": "localhost","protocol": "http","secure": false,"subdomains": [],"origin": "http://localhost:3000"}
设置cookie
直接通过ctx.cookies.get/set(name, opt)设置cookie,简单粗暴
获取具名参数
路由条件字符串中写入/:id/..,就可以将这一段的值赋给ctx.params.id
解析body
需要根据
Content-Type对POST等类型的报文的 body 进行解析,从而进行操作。 GET是没有请求体的
使用koa-bodyparser等enhance中间件,可以从req.request.body获取解析过的body内容。
如果使用koa-bodyparser还需要注意,参数要设置好可用类型:
app.use(bodyparser({enableTypes: ['json', 'form', 'text']}))
表单处理
提交表单必然意味着页面的跳转。但是ajax请求不会跳转
request
response
中间件
Koa的中间件以回环的模式(洋葱圈模型)运作。函数参数ctx和next。没有next的是最内层。
| 名称 | 类型 | 作用 |
|---|---|---|
| cookie-session | enhance |
通过cookie来运行c-s之间的会话 |
| cookie-parser | enhance |
运行常见的cookie功能,比如写入,清除,读取,加密等 |
中间件类型定义:
enhance:对ctx赋予新属性,重写方法等方式进行增强,供后面用。一定有nextwork:进行一些辅助的工作,一定有next。如日志等final:条件性或必然作为拐点节点,这时可以无next。比如拦截器、路由等。
对于中间件需要注意的事项(个人理解):
eggjs
基本使用
测试
测试有两个显著的问题:
test.js的断点位置会在测试后被偏移test.js报非断言错误的test.js的堆栈行不正确。package.json
egg框架使用的字段列表:eggts problem
虽然egg提供了框架本身的ts支持,但这似乎也只是杯水车薪:ctx = this.ctx后,ctx就没有了Context的ts支持。网络安全
最基本的几个问题:
XSS攻击:要对用户输入的内容,以及上传文件的内容进行严格的识别和转义,防止里面出现脚本文件
CSRF:需要CSRF Token
SQL注入:一般写程序搜索的时候,都是直接在代码里面拼接,这会使得sql注入这类问题出现,直接窃取服务器数据。
反爬:限制频率,请求次数和请求带宽,尤其是疯狂请求大文件

若有收获,就点个赞吧
0 人点赞
