参考文章:https://redisbook.readthedocs.io/en/latest/internal-datastruct/skiplist.html
跳跃列表(也称跳表)是一种随机化的数据, 由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出, 跳表以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— 查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说, 跳表的实现要简单直观得多。
以下是个典型的跳表例子(图片来自维基百科):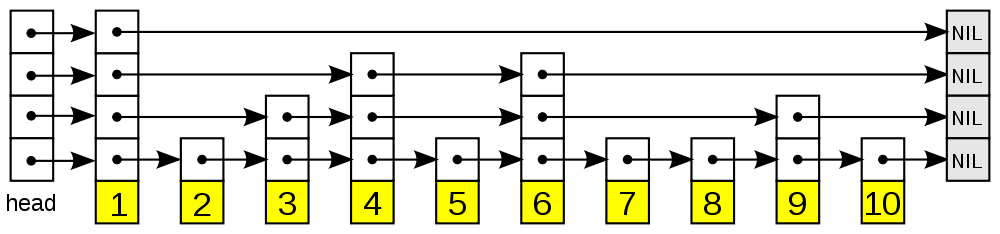
从图中可以看到, 跳表主要由以下部分构成:
- 表头(head):负责维护跳表的节点指针。
- 跳表节点:保存着元素值,以及多个索引层。
- 索引层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。
- 表尾(tail):全部由
NULL组成,表示跳表的末尾。
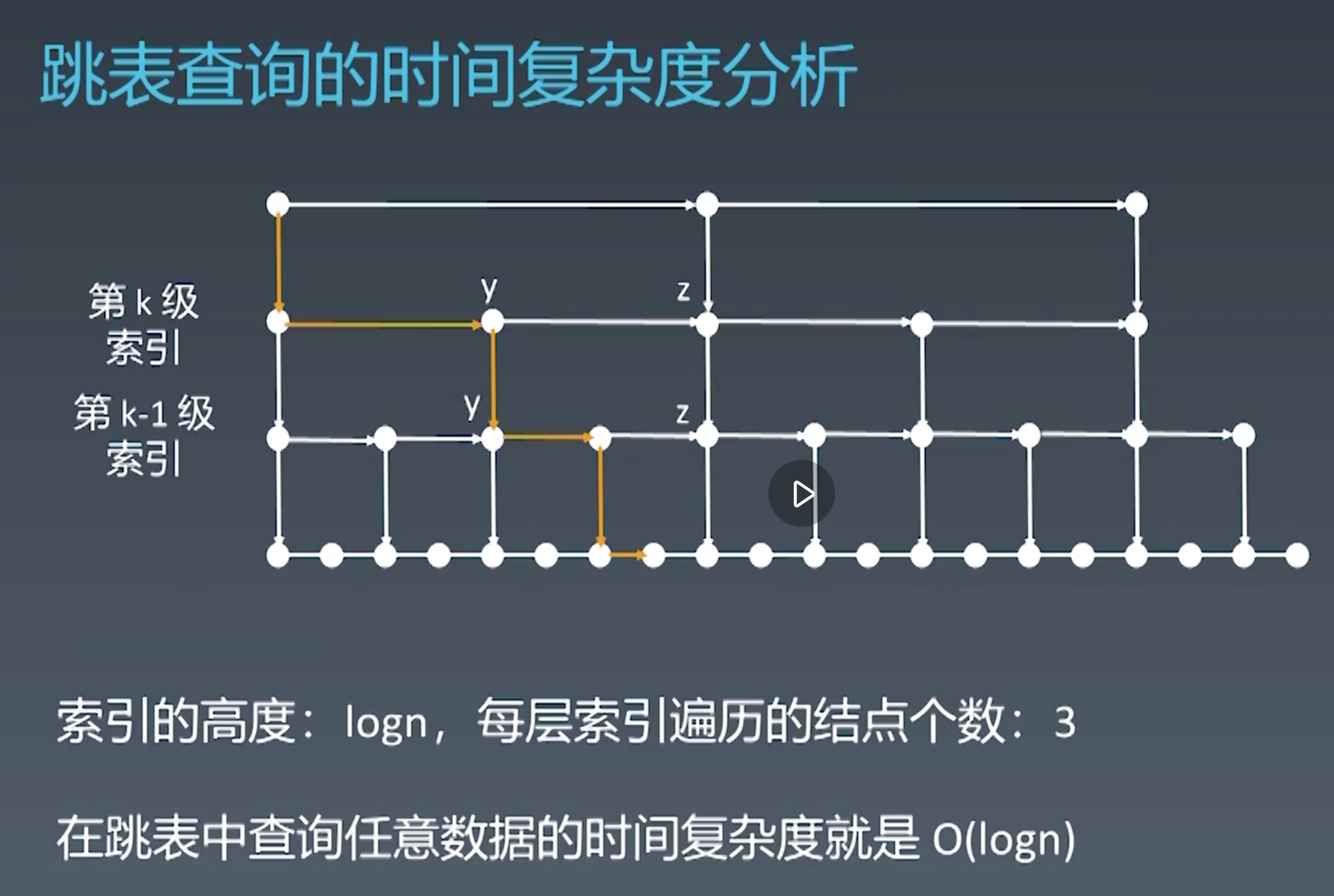
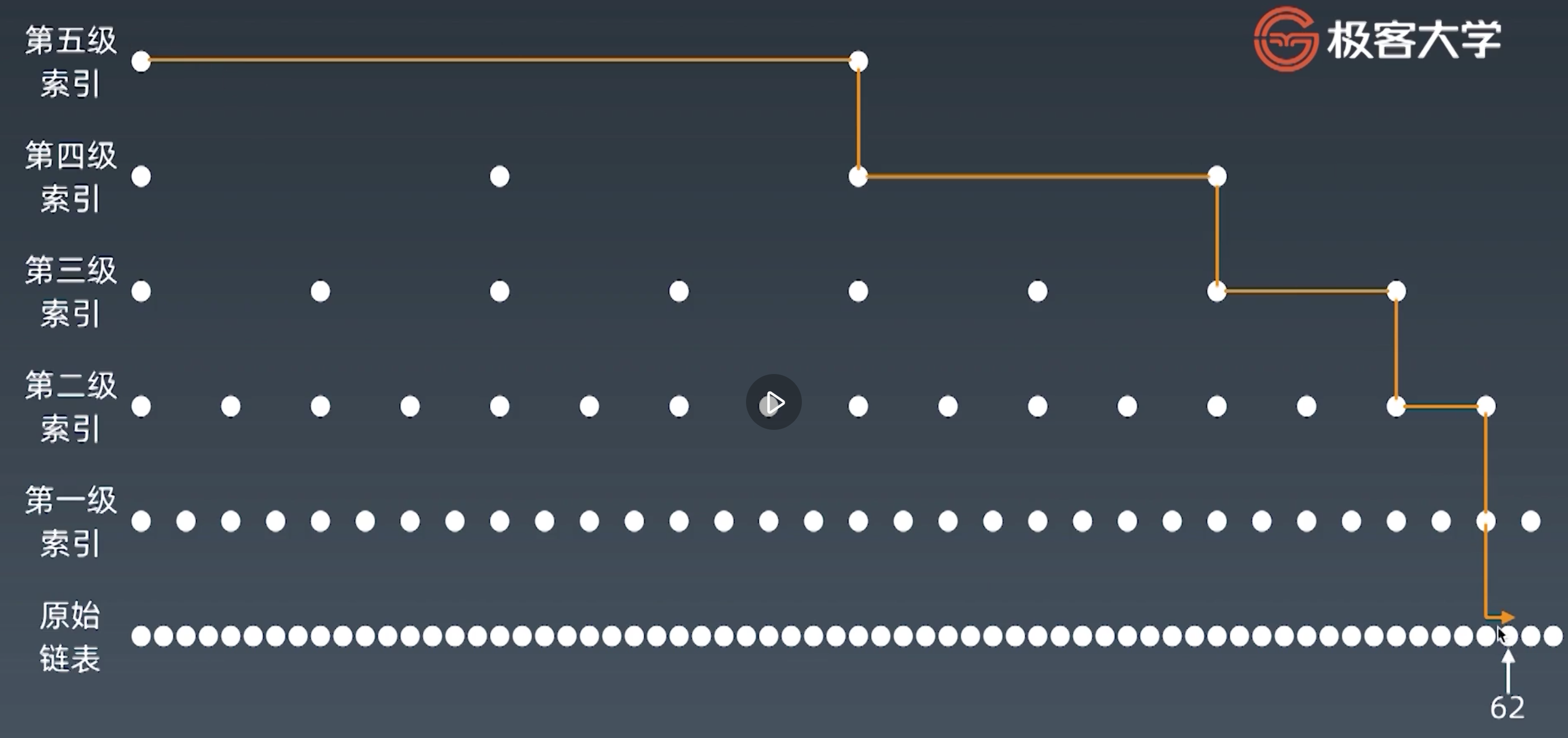
其他例子:往跳跃列表中插入一个元素
:::info
备注:以下截图来自极客时间,覃超老师的《算法训练营课程》
:::


若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}