变量声明的几种方式
主要有两种,这里还使用了类型推断
// Onevar name stringname = "hello world"// orvar name = "hello world"// Two 短变量声明name := "hello world"
类型推断带来的好处
示例代码
package mainimport ("flag""fmt")func main() {var name = getTheFlag()flag.Parse()fmt.Printf("Hello, %v!\n", *name)}func getTheFlag() *string {return flag.String("name", "everyone", "The greeting object.")}
用getTheFlag函数包裹(或者说包装)对flag.String函数的调用,并把其结果直接作为getTheFlag函数的结果,结果的类型是*string。这样一来,var name = 右边的表达式,可以变为针对getTheFlag函数的调用表达式了。这实际上是对“声明并赋值name变量的那行代码”的重构。
可以随意改变getTheFlag函数的内部实现,及其返回结果的类型,而不用修改main函数中的任何代码。通过这种类型推断,你可以体验到动态类型编程语言所带来的一部分优势,即程序灵活性的明显提升。
Go 语言的类型推断可以明显提升程序的灵活性,使得代码重构变得更加容易,同时又不会给代码的维护带来额外负担(实际上,它恰恰可以避免散弹式的代码修改),更不会损失程序的运行效率。
变量重声明
代码块 在 Go 语言中,代码块一般就是一个由花括号括起来的区域,里面可以包含表达式和语句。Go 语言本身以及我们编写的代码共同形成了一个非常大的代码块,也叫全域代码块。这主要体现在,只要是公开的全局变量,都可以被任何代码所使用。相对小一些的代码块是代码包,一个代码包可以包含许多子代码包,所以这样的代码块也可以很大。接下来,每个源码文件也都是一个代码块,每个函数也是一个代码块,每个if语句、for语句、switch语句和select语句都是一个代码块。甚至,switch或select语句中的case子句也都是独立的代码块。
重声明规则
- 变量的类型在其初始化时就已经确定,所以对它再次声明时赋予的类型必须与其原本的类型相同,否则会产生编译错误。
- 变量的重声明只可能发生在某一个代码块中。如果与当前的变量重名的是外层代码块中的变量,那么就是变量”屏蔽”。
- 变量的重声明只有在使用短变量声明时才会发生,否则也无法通过编译。如果要在此处声明全新的变量,那么就应该使用包含关键字var的声明语句,但是这时就不能与同一个代码块中的任何变量有重名了。
- 被“声明并赋值”的变量必须是多个,并且其中至少有一个是新的变量。这时才可以说对其中的旧变量进行了重声明。
变量重声明其实算是一个语法糖(或者叫便利措施)。它允许我们在使用短变量声明时不用理会被赋值的多个变量中是否包含旧变量。
可重名变量
不同代码块中的重名变量叫做“可重名变量”。
在同一个代码块中不允许出现重名的变量,这违背了 Go 语言的语法。
- 变量重声明中的变量一定是在某一个代码块内的。注意,这里的“某一个代码块内”并不包含它的任何子代码块,否则就变成了“多个代码块之间”。而可重名变量指的正是在多个代码块之间由相同的标识符代表的变量。
- 变量重声明是对同一个变量的多次声明,这里的变量只有一个。可重名变量中涉及的变量肯定是有多个。
- 不论对变量重声明多少次,其类型必须始终一致,具体遵从它第一次被声明时给定的类型。而可重名变量之间不存在类似的限制,它们的类型可以是任意的。
- 如果可重名变量所在的代码块之间,存在直接或间接的嵌套关系,那么它们之间一定会存在“屏蔽”的现象。但是这种现象绝对不会在变量重声明的场景下出现。
判断变量类型
通过类型断言实现判断类型
package mainimport ("fmt""os")var container = []string{"zero", "one", "two"}func main() {container := map[int]string{0: "zero", 1: "one", 2: "two"}fmt.Printf("The element is %q.\n", container[1])value, ok := interface{}(container).(map[int]string)if ok {fmt.Printf("%v", value)os.Exit(1)}fmt.Errorf("It's not map[int]string")}
类型断言表达式是用来把container变量的值转换为空接口值的interface{}(container)。这个表达式的结果可以被赋给两个变量,在这里由value和ok代表。变量ok是布尔(bool)类型的,它将代表类型判断的结果,true或false。
如果是true,那么被判断的值将会被自动转换为[]string类型的值,并赋给变量value,否则value将被赋予nil(即“空”)。
当这里的container变量类型不是任何的接口类型时,就需要先把它转成某个接口类型的值。如果container是某个接口类型的,那么这个类型断言表达式就可以是container.([]string)。
一对不包裹任何东西的花括号,除了可以代表空的代码块之外,还可以用于表示不包含任何内容的数据结构(或者说数据类型)。空接口interface{}则代表了不包含任何方法定义的、空的接口类型。

注意
类型转换表达式的语法形式是T(x)。
x可以是一个变量,也可以是一个代表值的字面量(比如1.23和struct{}{}),还可以是一个表达式。
如果是表达式,那么该表达式的结果只能是一个值,而不能是多个值。在这个上下文中,x可以被叫做源值,它的类型就是源类型,而那个T代表的类型就是目标类型。
对于整数类型值、整数常量之间的类型转换,原则上只要源值在目标类型的可表示范围内就是合法的。
比如,之所以uint8(255)可以把无类型的常量255转换为uint8类型的值,是因为255在[0, 255]的范围内。
特别注意的是,源整数类型的可表示范围较大,而目标类型的可表示范围较小的情况,比如把值的类型从int16转换为int8。请看下面这段代码:
var srcInt = int16(-255)dstInt := int8(srcInt)
变量srcInt的值是int16类型的-255,而变量dstInt的值是由前者转换而来的,类型是int8。int16类型的可表示范围可比int8类型大了不少。dstInt的值是多少?首先,整数在 Go 语言以及计算机中都是以补码的形式存储的。这主要是为了简化计算机对整数的运算过程。补码其实就是原码各位求反再加 1。比如,int16类型的值-255的补码是1111111100000001。如果我们把该值转换为int8类型的值,那么 Go 语言会把在较高位置(或者说最左边位置)上的 8 位二进制数直接截掉,从而得到00000001。又由于其最左边一位是0,表示它是个正整数,以及正整数的补码就等于其原码,所以dstInt的值就是1。
虽然直接把一个整数值转换为一个string类型的值是可行的,但值得关注的是,被转换的整数值应该可以代表一个有效的 Unicode 代码点,否则转换的结果将会是”�”(仅由高亮的问号组成的字符串值)
字符’�’的 Unicode 代码点是U+FFFD。它是 Unicode 标准中定义的 Replacement Character,专用于替换那些未知的、不被认可的以及无法展示的字符。string(-1)就会造成�。
string类型与各种切片类型之间的互转
一个值在从string类型向[]byte类型转换时代表着以 UTF-8 编码的字符串会被拆分成零散、独立的字节。除了与 ASCII 编码兼容的那部分字符集,以 UTF-8 编码的某个单一字节是无法代表一个字符的。比如中文要三个字节才能代表一个字符。
类型别名
声明类型别名
type MyString = string
别名类型与其源类型的区别恐怕只是在名称上,它们是完全相同的。
Go 语言内建的基本类型中就存在两个别名类型。byte是uint8的别名类型,而rune是int32的别名类型。
类型再定义
type MyString2 string // 注意,这里没有等号。
MyString2和string就是两个不同的类型了。这里的MyString2是一个新的类型,不同于其他任何类型。
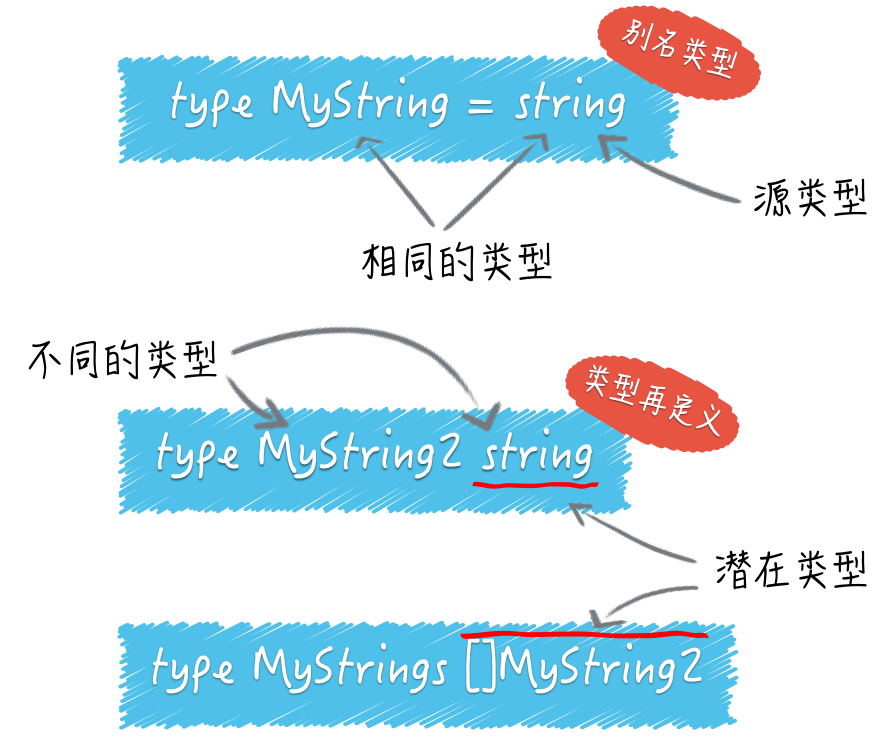
对类型再定义来说,string可以被称为MyString2的潜在类型。潜在类型的含义是,某个类型在本质上是哪个类型。
即使两个不同类型的潜在类型相同,它们的值之间也不能进行判等或比较,它们的变量之间也不能赋值。

若有收获,就点个赞吧
0 人点赞
