BERT 文本分类/匹配采用BERT类模型训练模型,输出分类标签,如下所示: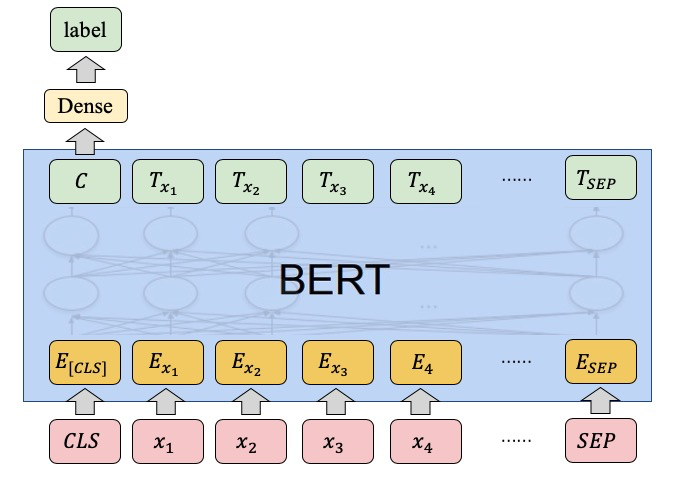
在easytexminer 命令中选择 text_classify 即可调用这个模型。
PAI模型训练和评估
ODPS数据准备
首先可以下载 训练集 和 评估集,其中 train.csv , dev.csv 是用\t 分隔的 .csv 文件。
我们定义这五个字段为 label,sid1,sid2,sent1,sent2。
我们对各数据创建表,并将相应的数据上传到 ODPS 上:
drop table if exists modelzoo_example_train;create table modelzoo_example_train(label STRING, sid1 STRING, sid2 STRING, sent1 STRING,sent2 STRING);tunnel upload train.tsv modelzoo_example_train -fd '\t';drop table if exists modelzoo_example_dev;create table modelzoo_example_dev(label STRING, sid1 STRING, sid2 STRING, sent1 STRING,sent2 STRING);tunnel upload dev.tsv modelzoo_example_dev -fd '\t';
模型训练
配置一些环境参数:
export train_table=odps://${project_name}/tables/your_train_table_name
export dev_table=odps://${project_name}/tables/your_dev_table_name
export saved_model_dir=oss://path/to/your_model/
export oss_bucket_name=your_bucket_name
export access_key_id=your_access_id
export access_key_secret=your_access_key_secret
export host=your_host
模型训练的PAI命令如下:
pai -name easytexminer
-project algo_platform_dev
-Dmode=train
-DinputTable=${train_table},${dev_table}
-DfirstSequence=sent1
-DsecondSequence=sent2
-DlabelName=label
-DlabelEnumerateValues=0,1
-DsequenceLength=64
-DappName=text_classify
-DcheckpointDir=${saved_model_dir}
-DlearningRate=3e-5
-DnumEpochs=3
-DsaveCheckpointSteps=50
-DbatchSize=32
-DworkerCount=1
-DworkerGPU=1
-DuserDefinedParameters=' pretrain_model_name_or_path=bert-base-uncased'
-Dbuckets="oss://${oss_bucket_name}?access_key_id=${access_key_id}&access_key_secret=${access_key_secret}&host=${host}";
本地数据准备和预测
首先可以下载 训练集 和 评估集,其中 train.csv , dev.csv 是用\t 分隔的 .csv 文件。
模型训练
easytexminer \
--mode=train \
--worker_gpu=1 \
--tables=train.tsv,dev.tsv \
--input_schema=label:str:1,sid1:str:1,sid2:str:1,sent1:str:1,sent2:str:1 \
--first_sequence=sent1 \
--second_sequence=sent2 \
--label_name=label \
--label_enumerate_values=0,1 \
--pretrain_model_name_or_path=bert-base-uncased \
--checkpoint_dir=./classification_model \
--learning_rate=3e-5 \
--epoch_num=3 \
--seed=42 \
--save_checkpoint_steps=50 \
--sequence_length=128 \
--micro_batch_size=32 \
--app_name=text_classify
模型评估
easytexminer \
--mode=evaluate \
--worker_gpu=1 \
--tables=dev.tsv \
--input_schema=label:str:1,sid1:str:1,sid2:str:1,sent1:str:1,sent2:str:1 \
--first_sequence=sent1 \
--second_sequence=sent2 \
--label_name=label \
--label_enumerate_values=0,1 \
--checkpoint_path=./classification_model \
--micro_batch_size=32 \
--sequence_length=128 \
--app_name=text_classify
模型预测
easytexminer \
--mode=predict \
--worker_gpu=1 \
--tables=dev.tsv \
--outputs=dev.pred.tsv \
--input_schema=label:str:1,sid1:str:1,sid2:str:1,sent1:str:1,sent2:str:1 \
--output_schema=predictions,probabilities,logits,output \
--append_cols=label \
--first_sequence=sent1 \
--second_sequence=sent2 \
--checkpoint_path=./classification_model \
--micro_batch_size=32 \
--sequence_length=128 \
--app_name=text_classify
参数说明:
- output_schema:需要输出的结果类型,默认有四种:predictions(预测结果),probabilities(预测的概率),logits(预测的logits,即softmax之前的值),output(输出值)
- append_cols:需要append的输入数据的column,多个column可以用逗号分隔

若有收获,就点个赞吧
0 人点赞
