什么是图像的纹理?
先来看下面一组图片:
上面每一行图片的共同点有:有一定规则的局部图案+大量局部的不断重复+整个区域大致为均匀的统一体

图像纹理定义:具有一定结构的模式或图像,以缓慢变化或者周期性变化组织近似规则的排列。
纹理单元(texton):
- 纹理中有周期性纹理的基本单元;
- 由局部显著特征组成,如拐角、圆点、端点和交叉等;
- 对于非周期纹理,很难确定其 texton;
- 可能有多种尺度的结构纹理。
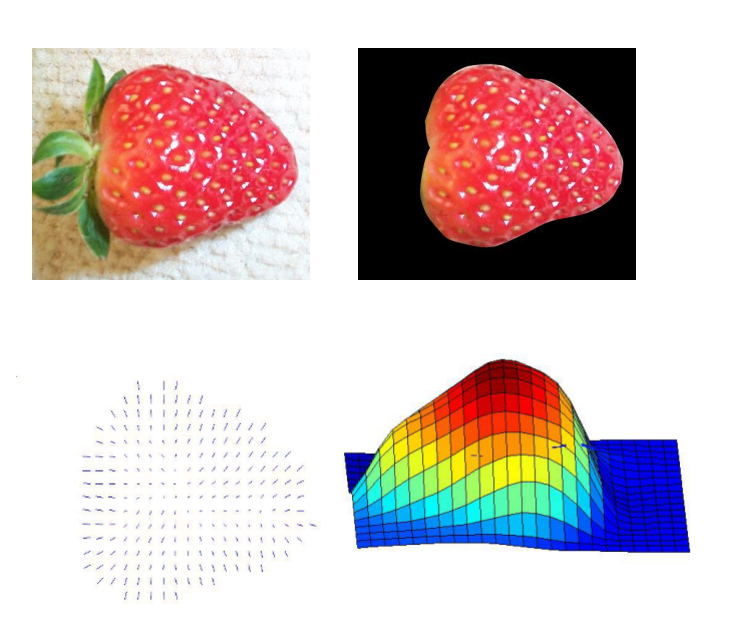
图像纹理应用:
| 分类识别 | 区域分割 | 纹理合成 | 空间信息估计 (利用纹理对应区域的变形估计曲面形状 ) |
|---|---|---|---|
 |
 |
 |
 |
纹理分析

LBP算法
概述
(Local Binary Pattern,局部二值模式)
- 简介:用来描述图像局部纹理特征的算子
- 优点:旋转不变性+灰度不变性
- 由T. Ojala, M.Pietikäinen, 和 D. Harwood 在1994年提出,用于局部纹理特征提取。
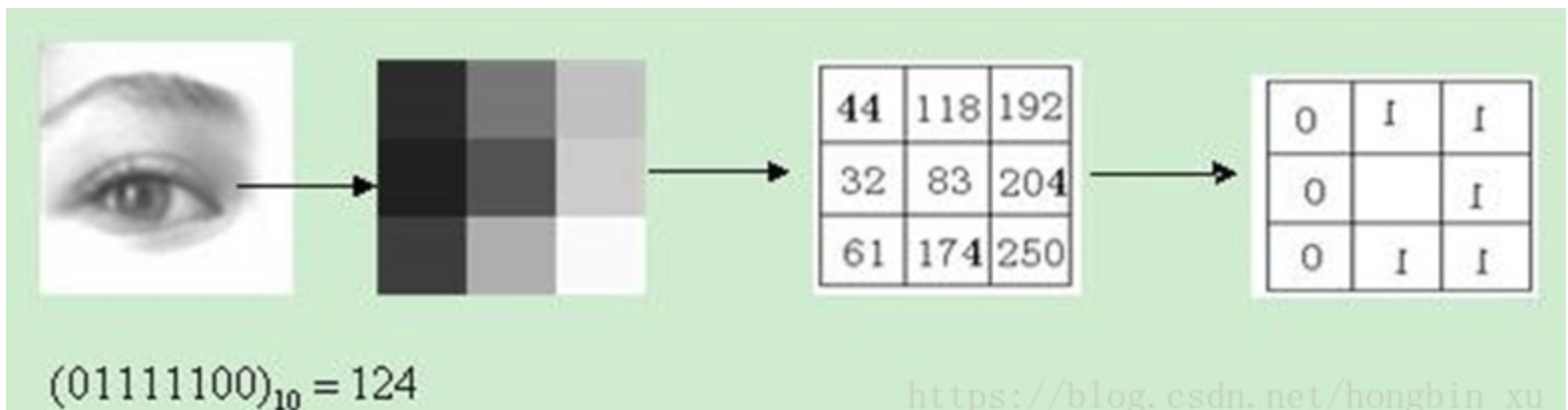
原始的LBP算子定义在一个3×3的窗口内,以窗口中心像素为阈值,与相邻的8个像素的灰度值比较,若周围的像素值大于中心像素值,则该位置被标记为1;,否则标记为0。
如此可以得到一个8位二进制数(通常还要转换为10进制,即LBP码,共256种),将这个值作为窗口中心像素点的LBP值,以此来反应这个3×3区域的纹理信息。 示意图如下:
代码实现
import numpy as npimport cv2def LBP(src):''':param src:灰度图像:return:'''height = src.shape[0]width = src.shape[1]dst = src.copy()lbp_value = np.zeros((1,8), dtype=np.uint8)neighbours = np.zeros((1,8), dtype=np.uint8)for x in range(1, width-1):for y in range(1, height-1):neighbours[0, 0] = src[y - 1, x - 1]neighbours[0, 1] = src[y - 1, x]neighbours[0, 2] = src[y - 1, x + 1]neighbours[0, 3] = src[y, x - 1]neighbours[0, 4] = src[y, x + 1]neighbours[0, 5] = src[y + 1, x - 1]neighbours[0, 6] = src[y + 1, x]neighbours[0, 7] = src[y + 1, x + 1]center = src[y, x]for i in range(8):if neighbours[0, i] > center:lbp_value[0, i] = 1else:lbp_value[0, i] = 0lbp = lbp_value[0, 0] * 1 + lbp_value[0, 1] * 2 + lbp_value[0, 2] * 4 + lbp_value[0, 3] * 8 \+ lbp_value[0, 4] * 16 + lbp_value[0, 5] * 32 + lbp_value[0, 6] * 64 + lbp_value[0, 0] * 128dst[y, x] = lbpreturn dstsrc = cv2.imread("/Users/longfeifei/PycharmProjects/ngmachine/pic/2.png")gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)cv2.imshow("original.jpg", src)cv2.imshow("gray.jpg", gray)dst = LBP(gray)cv2.imshow("result.jpg", dst)cv2.waitKey(0)cv2.destroyAllWindows()
课堂作业
1.求一幅图的纹理特征图(LBP)
| 输入图片 | 纹理图 |
|---|---|
 |
 |
 |
 |
2.比较三纹理图篇纹理图相似程度(LBP)
**
解决这一个问题的思路是:得出图片的纹理图(LBP),然后比较纹理图的均值感知哈希值。
代码如下:
import numpy as npimport cv2def aHash(img):#缩放为8*8img = cv2.resize(img, (8, 8), interpolation=cv2.INTER_CUBIC)#转换为灰度图#s为像素和初值为0,hash_str为hash值初值为''s = 0hash_str = ''#遍历累加求像素和for i in range(8):for j in range(8):s = s+img[i, j]#求平均灰度avg = s/64#灰度大于平均值为1相反为0生成图片的hash值for i in range(8):for j in range(8):if img[i,j]>avg:hash_str=hash_str+'1'else:hash_str=hash_str+'0'return hash_strdef LBP(src):''':param src:灰度图像:return:'''height = src.shape[0]width = src.shape[1]dst = src.copy()lbp_value = np.zeros((1,8), dtype=np.uint8)neighbours = np.zeros((1,8), dtype=np.uint8)for x in range(1, width-1):for y in range(1, height-1):neighbours[0, 0] = src[y - 1, x - 1]neighbours[0, 1] = src[y - 1, x]neighbours[0, 2] = src[y - 1, x + 1]neighbours[0, 3] = src[y, x - 1]neighbours[0, 4] = src[y, x + 1]neighbours[0, 5] = src[y + 1, x - 1]neighbours[0, 6] = src[y + 1, x]neighbours[0, 7] = src[y + 1, x + 1]center = src[y, x]for i in range(8):if neighbours[0, i] > center:lbp_value[0, i] = 1else:lbp_value[0, i] = 0lbp = lbp_value[0, 0] * 1 + lbp_value[0, 1] * 2 + lbp_value[0, 2] * 4 + lbp_value[0, 3] * 8 \+ lbp_value[0, 4] * 16 + lbp_value[0, 5] * 32 + lbp_value[0, 6] * 64 + lbp_value[0, 0] * 128dst[y, x] = lbpreturn dstdef cmpHash(hash1,hash2):n=0#hash长度不同则返回-1代表传参出错if len(hash1)!=len(hash2):return -1#遍历判断for i in range(len(hash1)):#不相等则n计数+1,n最终为相似度if hash1[i]!=hash2[i]:n=n+1return nsrc1 = cv2.imread("/Users/longfeifei/PycharmProjects/ngmachine/pic/pic1.png")src2 = cv2.imread("/Users/longfeifei/PycharmProjects/ngmachine/pic/pic2.png")src3 = cv2.imread("/Users/longfeifei/PycharmProjects/ngmachine/pic/pic3.png")gray1 = cv2.cvtColor(src1, cv2.COLOR_BGR2GRAY)dst1 = LBP(gray1)gray2 = cv2.cvtColor(src2, cv2.COLOR_BGR2GRAY)dst2 = LBP(gray2)gray3 = cv2.cvtColor(src3, cv2.COLOR_BGR2GRAY)dst3 = LBP(gray3)hash1=aHash(dst1)hash2=aHash(dst2)hash3=aHash(dst3)n=cmpHash(hash1,hash2)print('第一张第二张均值哈希算法相似度:'+ str(n))n=cmpHash(hash2,hash3)print('第二张第三张均值哈希算法相似度:'+ str(n))n=cmpHash(hash1,hash3)print('第一张第三张均值哈希算法相似度:'+ str(n))cv2.waitKey(0)cv2.destroyAllWindows()
实验结果:**
第一张图片与第三张图片的相似度较高。

若有收获,就点个赞吧
0 人点赞
