开卷有益
在阅读文章之前,你可以先想想自己是否了解以下内容,如果不了解希望此文章可以帮助你解除疑惑:
- 解释 docker 原理
- 简述 namespace 可以对哪些资源做隔离?
- 简述 cgroups 的作用和可以限制的资源类型?
- 在 linux 如何实操检验 cgroups 对资源的限制?
- Docker 默认会为容器启用哪些 namespace?
- 简述 虚拟机 和 docker 两者的技术缺陷?
简介 docker 原理
docker 项目核心原理实际上就是未待创建的用户进程:
- 启用 Linux Namespace 配置,实现资源隔离
- 设置指定的 Cgroups 参数,实现资源限制
- 切换进程的根目录(change rootfs)
Namespace
它实际上修改了容器内的应用程序看待整个计算机的“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些特定的内容,但是对于宿主机来说,这些被“隔离”的进程和其他进程没有什么区别(与其他进程之间存在平台竞争关系),所以 docker container 的本质其实就是被操作系统加了一些限定参数的进程。
namespace 分别可以对以下资源做隔离:
- pid —- 默认
- network —- 默认
- user
- mount
- IPC
- cgroup
- UTS
架构图
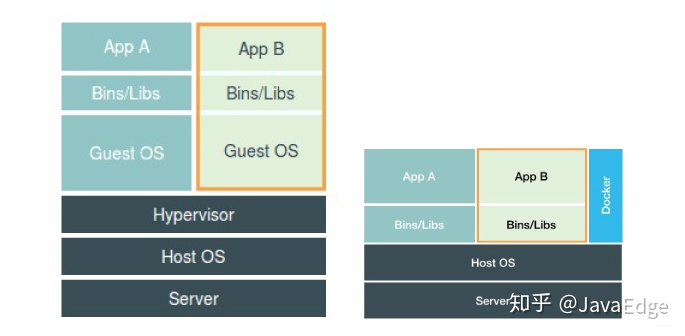
从架构图上也可以看出,docker 并没有使用虚拟化出一个操作系统,它在应用的最右侧,表示对进程只起到辅助管理作用,而这些进程还是运行在宿主的操作系统上,都由宿主机统一管理,只不过这些被 “隔离” 的进程额外设置了一些参数。
我们可以通过如下方式验证
# 启动一个容器,在容器内运行一个 tail -f 进程$ docker run -d --name busybox-1 busybox tail -f02b76c8187392754beda2e185c7bea54bebb41ad3568df442425cd2a41577b12# 检查启动的 container ,可以看到宿主机内的 pid 也就是30323$ docker inspect busybox-1..."State": {"Status": "running","Running": true,"Paused": false,"Restarting": false,"OOMKilled": false,"Dead": false,"Pid": 30323,"ExitCode": 0,"Error": "","StartedAt": "2020-09-08T02:49:29.686196828Z","FinishedAt": "0001-01-01T00:00:00Z"},...# 查看容器内此进程IP,发现被“隔离”的容器内部,此进程为1,并且看不到宿主机其他进程,满足上问说的情况$ docker exec -it busybox-1 topMem: 3850900K used, 4233960K free, 2448K shrd, 628068K buff, 2067452K cachedCPU: 13.1% usr 0.0% sys 0.0% nic 86.8% idle 0.0% io 0.0% irq 0.0% sirqLoad average: 0.13 0.45 0.45 6/512 16PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND12 0 root R 1308 0.0 2 0.0 top1 0 root S 1300 0.0 1 0.0 tail -f
了解了 docker container 的本质之后,我们可以比较下 docker 和 虚拟机 的技术特点:
- 虚拟机缺点:
- 体积较大:首先虚拟机需要在宿主机上虚拟化出一个操作系统,然后在虚拟化的操作系统上部署应用和依赖等,这里操作系统本身就会占用一定的内存
- 性能较低:虚拟机上的应用如果要操作宿主机操作系统,则需要通过虚拟化软件的拦截和处理,从而造成性能的浪费。
- docker 缺点
- 隔离不彻底
- 因为 container 只是运行在宿主上的一个特殊的进程,所以所有 container 都还是使用同一个宿主机的系统内核,如果修改内核参数,则会全局生效。
- namespace 对部分资源和对象无法隔离,例如时间(在 container 内修改时间,会导致宿主机的时间也会一起改变) —- kernel 5.6已经支持time namespace
- 隔离不彻底
CGroups(linux controller groups)
docker 使用了 linux 的 CGroups 实现了对进程资源的限制,通过以下命令可以看到可以被限制的资源都有哪些:
# 查看都可以限制哪些资源,每一个文件夹都表示一种可以被限制的资源种类$ mount -t cgroupcgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)# 或者这样,每一个文件夹都表示一种可以被限制的资源种类$ ls /sys/fs/cgroupblkio cpu cpuacct cpu,cpuacct cpuset devices freezer hugetlb memory net_cls net_cls,net_prio net_prio perf_event pids rdma systemd unified
首先我们先通过代码了解如何进行其中一种资源的限制(CPU),再运行一个 docker container 来进行验证。
# 首先启动一个死循环进程,查看 top 数据,我们会发现此进程会消耗100%的CPU,而我们的目标就是对此进行的资源进行限定$ while : ; do : ; done &[1] 24899$ toptop - 08:17:30 up 2 days, 19:46, 2 users, load average: 0.89, 0.49, 0.41Tasks: 164 total, 2 running, 106 sleeping, 0 stopped, 0 zombie%Cpu(s): 1.9 us, 8.4 sy, 17.8 ni, 71.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 8084860 total, 4431220 free, 904984 used, 2748656 buff/cacheKiB Swap: 0 total, 0 free, 0 used. 7004876 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24899 root 25 5 54116 3676 0 R 99.7 0.0 1:03.48 zsh# 首先创建一个资源组$ cd /sys/fs/cgroup/cpu# 文件夹创建后,操作系统会自动在此文件夹下创建资源限制文件$ mkdir container$ ll-rw-r--r-- 1 root root 0 Sep 7 06:45 cgroup.clone_children-rw-r--r-- 1 root root 0 Sep 7 06:45 cgroup.procs-r--r--r-- 1 root root 0 Sep 7 06:45 cpuacct.stat-rw-r--r-- 1 root root 0 Sep 7 06:45 cpuacct.usage-r--r--r-- 1 root root 0 Sep 7 06:45 cpuacct.usage_all-r--r--r-- 1 root root 0 Sep 7 06:45 cpuacct.usage_percpu-r--r--r-- 1 root root 0 Sep 7 06:45 cpuacct.usage_percpu_sys-r--r--r-- 1 root root 0 Sep 7 06:45 cpuacct.usage_percpu_user-r--r--r-- 1 root root 0 Sep 7 06:45 cpuacct.usage_sys-r--r--r-- 1 root root 0 Sep 7 06:45 cpuacct.usage_user-rw-r--r-- 1 root root 0 Sep 7 06:45 cpu.cfs_period_us-rw-r--r-- 1 root root 0 Sep 7 07:00 cpu.cfs_quota_us-rw-r--r-- 1 root root 0 Sep 7 06:45 cpu.shares-r--r--r-- 1 root root 0 Sep 7 06:45 cpu.stat-rw-r--r-- 1 root root 0 Sep 7 06:45 notify_on_release-rwxrwxrwx 1 root root 0 Sep 7 07:00 tasks
部分资源限制文件详解
# 资源显示间隔时间10000 us$ cat cpu.cfs_period_us100000# 资源限制大小,默认为 -1 不限制$ cat cpu.cfs_quota_us-1
修改限制资源,在限制条件中设定一个满的CPU是 1000 ms,如果我们设置了 200,则为在指定时间内提供单核的20%的算力
# 修改 CPU 限制为 20%$ echo 20000 > cpu.cfs_quota_us# 添加需要限制的 PID$ chmod 777 tasks$ echo 24899>tasks# 在查看资源,发现已经为20%$ toptop - 08:25:48 up 2 days, 19:55, 2 users, load average: 1.61, 1.09, 0.75Tasks: 160 total, 2 running, 106 sleeping, 0 stopped, 0 zombie%Cpu(s): 3.9 us, 2.8 sy, 3.9 ni, 89.3 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 8084860 total, 4431508 free, 903404 used, 2749948 buff/cacheKiB Swap: 0 total, 0 free, 0 used. 7006456 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24899 root 25 5 54116 3676 0 R 20.5 0.0 9:00.67 zsh
通过以上我们已经了解到了 linus 如何进行 CPU 资源限制,为了验证 Docker 是否也是运用此方法,我们可以通过以下方式验证
# 创建容器,并且限制使用 CPU 资源$ docker run -d --cpu-quota=20000 --cpu-period 100000 --name busybox-1 busybox tail -f167e90b8a2f1598fc6f4084ef8845650c1456de58509c55829fd4ffd403ab4ec# 查看资源限制,发现与预期设置一致$ cd /sys/fs/cgroup/cpu/docker/167e90b8a2f1598fc6f4084ef8845650c1456de58509c55829fd4ffd403ab4ec$ cat cpu.cfs_quota_us20000$ cat cpu.cfs_period_us100000# 进入容器,进行压力测试,验证CPU资源$ docker exec -it 167e90b8a2f1598fc6f4084ef8845650c1456de58509c55829fd4ffd403ab4ec sh$ while : ; do : ; done &$ exit# 发现与预期结果一致,在这里也可以看发现 container 也只是宿主机内一个进程而已$ top - 08:33:27 up 2 days, 20:02, 2 users, load average: 0.61, 0.64, 0.65Tasks: 164 total, 2 running, 106 sleeping, 0 stopped, 0 zombie%Cpu(s): 8.0 us, 1.7 sy, 0.0 ni, 90.0 id, 0.1 wa, 0.0 hi, 0.2 si, 0.0 stKiB Mem : 8084860 total, 4427444 free, 904860 used, 2752556 buff/cacheKiB Swap: 0 total, 0 free, 0 used. 7005040 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1265 root 20 0 1316 68 4 R 19.9 0.0 0:10.73 sh
以上只是对 CGroups 中对 CPU 限制了详细的操作和解释,除此之外它还能对以下资源做限制:
- memory 内存
- blkio 磁盘读写
- …
docker 支持的资源限制方法,发现 CGroups 支持的,docker 都支持:
- —memory-swappiness int Tune container memory swappiness (0 to 100) (default -1)
- —memory bytes Memory limit
- —blkio-weight uint16 Block IO (relative weight), between 10 and 1000, or 0 to disable (default 0)
- —blkio-weight-device list Block IO weight (relative device weight) (default [])
到这里已经将 docker 中 namespace 资源隔离,CGroup 资源限制做了详细的解释

若有收获,就点个赞吧
0 人点赞
